Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。
Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。
本文将向你详细介绍什么是倒排索引、以及 Elasticsearch 数据存储、数据更新和数据删除的原理
文章目录
- 1、倒排索引
- 1.1、为什么需要倒排索引
- 1.2、为什么叫倒排索引
- 1.3、倒排索引的结构
- 2、数据存储原理
- 2.1、数据存储过程
- 2.2、创建倒排索引的过程
- 2.3、分词
- 2.4、生成词项
- 2.5、分词器
- 2.6、创建倒排列表
- 2.7、数据压缩
- 3、数据更新原理
- 3.1、数据更新过程
- 3.2、更新倒排列表
- 3.3、版本控制
- 3.4、数据复制
- 4、数据删除原理
- 4.1、数据删除原理
- 4.2、删除数据的恢复
1、倒排索引
1.1、为什么需要倒排索引
倒排索引,也是索引。索引,初衷都是为了快速检索到你要的数据。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch 和 Lucene 来说,是倒排索引。
Elasticsearch 是建立在全文搜索引擎库 Lucene 基础上的搜索引擎,它隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,不过掩盖不了它底层也是 Lucene 的事实。Elasticsearch 的倒排索引,其实就是 Lucene 的倒排索引。
1.2、为什么叫倒排索引
“倒排索引”(Inverted Index)的概念是从"正向索引"(Forward Index)中衍生出来的。
在"正向索引"中,我们从文档出发,记录下每个文档中出现的词项,这样就可以知道每个文档包含哪些词项。而在"倒排索引"中,我们从词项出发,记录下每个词项出现在哪些文档中,这样就可以知道每个词项被哪些文档包含。
正向索引:document -> to -> words
倒排索引:word -> to -> documents
因此,“倒排索引"可以看作是"正向索引"的逆操作,所以被称为"倒排”。在全文搜索中,"倒排索引"是非常重要的数据结构,因为它可以让我们快速找到包含特定词项的所有文档。
1.3、倒排索引的结构
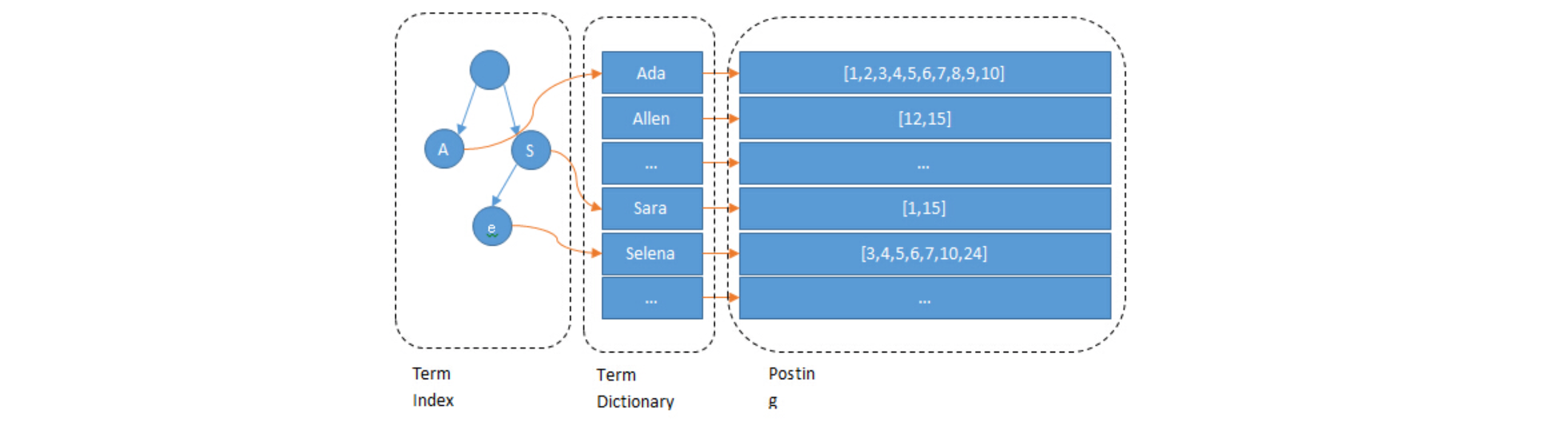
倒排索引作为一种数据结构,用于存储一种映射关系,即从词项到出现该词项的文档的映射。它是全文搜索引擎的核心组成部分,如 Elasticsearch、Lucene 等。
在倒排索引中,每个唯一的词项都有一个相关的倒排列表,这个列表中包含了所有包含该词项的文档的 ID。这样,当我们搜索一个词项时,搜索引擎只需要查找倒排索引,就可以快速找到所有包含这个词项的文档。
例如,假设我们有以下三个文档:
1. 文档1:I love coding
2. 文档2:I love reading
3. 文档3:I love both
对这些文档建立倒排索引后,我们会得到以下的映射关系:
- I:文档1,文档2,文档3
- love:文档1,文档2,文档3
- coding:文档1
- reading:文档2
- both:文档3
所以,当我们搜索"love"时,搜索引擎会在倒排索引中找到"love",然后返回所有包含"love"的文档,即文档1,文档2 和文档3。
2、数据存储原理
2.1、数据存储过程
创建或更新倒排索引是 Elasticsearch 数据存储过程的核心部分之一,Elasticsearch 的数据存储过程也确实包括创建倒排索引的过程,但并不仅限于此。
Elasticsearch 的数据存储过程主要包括以下多个步骤:
- 接收数据:Elasticsearch 首先接收到用户通过 HTTP 请求发送的数据,数据通常是 JSON 格式的文档。
- 分配文档 ID:如果用户没有指定文档 ID,Elasticsearch 会为新文档自动生成一个唯一的 ID。
- 选择分片:Elasticsearch 会根据文档ID和索引的分片策略,选择一个分片来存储这个文档。
- 创建和更新倒排索引:Elasticsearch 会对文档的内容进行分词,生成词项,并为这些词项创建或更新倒排索引。这样,新的文档就可以被搜索到了。
- 存储文档:Elasticsearch 会将文档的原始内容和元数据(如版本号、修改时间等)存储在分片中。原始内容存储在 _source 字段中,用于在获取文档时使用。
- 复制文档:为了提高数据的可用性和搜索性能,Elasticsearch 会将文档复制到其他节点的副本分片中。
- 确认写入:当文档被成功写入主分片和所有副本分片后,Elasticsearch 会向用户发送一个确认响应。
本篇接下来内容,我们将重点关注在创建和更新倒排索引的过程之中,我们将详细研究的是创建倒排索引的过程,这是因为倒排索引是 Elasticsearch 实现快速全文搜索的关键数据结构。
2.2、创建倒排索引的过程
创建倒排索引的过程主要包括以下步骤:
-
分词:这是第一步,将一段文本分解成一个个的词项(Tokens)。这个过程由分词器(Tokenizer)完成,可以根据不同的语言和需求选择不同的分词器。
-
生成词项:对分词后的结果进行处理,生成最终的词项。这个过程可能包括转换为小写、去除停用词、词干提取等操作。
-
创建倒排列表:对于每个词项,都创建一个倒排列表,记录包含这个词项的所有文档的 ID。
-
更新倒排索引:将新的倒排列表添加到倒排索引中。如果倒排索引中已经存在这个词项,就将新的文档 ID 添加到对应的倒排列表中。
以上就是创建倒排索引的主要步骤。需要注意的是,这个过程在每次插入新的文档,或者更新已有的文档时都会进行。
2.3、分词
分词是将一段文本分解成一个个的词项(Tokens)的过程。这是全文搜索和文本分析的第一步,因为只有将文本分解成词项,才能对其进行进一步的处理和分析。
分词的过程通常由分词器(Tokenizer)完成,分词器可以根据不同的语言和需求,采用不同的分词策略。
分词策略决定了如何将文本分解成词项。以下是一些常见的分词策略:
-
空格分词:这是最简单的分词策略,只是简单地将文本按空格分解成词项。这种方式简单快速,但可能无法处理复杂的语言特性。
-
基于语法的分词:这种分词策略会考虑语言的语法规则,例如英语的复数形式、过去式等。这种方式可以提高搜索的准确性,但处理起来更复杂。
-
基于词典的分词:这种分词策略会使用一个词典来分解文本,可以处理一些特殊的词组和短语。这种方式可以提高搜索的相关性,但需要一个高质量的词典。
-
N-gram 分词:这种分词策略会将文本分解成连续的 n 个字符的序列。这种方式可以处理任何语言,但可能会生成大量的词项,影响搜索的效率和准确性。
在 Elasticsearch 中,可以通过配置分词器来控制分词的策略,以适应不同的语言和搜索需求。
2.4、生成词项
生成词项是分词过程的一部分,它是将分词后的结果进行处理,生成最终用于创建倒排索引的词项。
在生成词项的过程中,可能会进行以下一些操作:
-
转换为小写:为了使搜索不区分大小写,通常会将所有的词项转换为小写。
-
去除停用词:停用词是一些常见的、没有太多实际意义的词,如英语中的 “the”、“is”、“at” 等。去除停用词可以减少倒排索引的大小,提高搜索的效率。
-
词干提取:词干提取是将词项转换为其基本形式(或词干)的过程。例如,英语中的 “running”、“runs”、“ran” 都会被转换为 “run”。这样可以使搜索不受词形变化的影响。
-
词形还原:词形还原是将词项转换为其原始形式的过程。例如,英语中的 “better” 会被转换为 “good”。这样可以使搜索更准确。
以上就是生成词项的一些常见操作。需要注意的是,这些操作的具体实现可能会依赖于特定的语言和分词器。
2.5、分词器
在 Elasticsearch 中,生成词项的设置主要通过配置分词器(Analyzer)来实现。分词器由一个分词器(Tokenizer)和多个过滤器(Filter)组成,分词器负责将文本分解成词项,过滤器负责对词项进行处理。
以下是一个简单的分词器配置示例:
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","filter": ["lowercase", "my_stemmer"]}},"filter": {"my_stemmer": {"type": "stemmer","name": "english"}}}}
}
在这个示例中,我们定义了一个名为 “my_analyzer” 的分词器,它使用 “standard” 分词器和两个过滤器: “lowercase” 和 “my_stemmer”。 “lowercase” 过滤器会将所有词项转换为小写, “my_stemmer” 过滤器会对英语词项进行词干提取。
你可以根据需要,选择不同的分词器和过滤器,以实现不同的生成词项策略。例如,如果你不想启用词干提取,可以去掉 “my_stemmer” 过滤器;如果你想启用词形还原,可以添加一个词形还原过滤器。
需要注意的是,Elasticsearch 的分词器和过滤器都是插件形式提供的,不同的插件支持不同的语言和功能。在使用前,你需要确保你的 Elasticsearch 安装了相应的插件。
2.6、创建倒排列表
创建倒排列表是创建倒排索引过程的一部分。对于每个词项,都会创建一个倒排列表,记录包含这个词项的所有文档的 ID。
以下是创建倒排列表的基本步骤:
- 初始化倒排列表:对于一个新的词项,首先创建一个空的倒排列表。
- 添加文档 ID:当一个文档被分词并生成词项后,将这个文档的 ID 添加到对应词项的倒排列表中。
- 排序:为了提高搜索效率,倒排列表通常会按照文档 ID 的顺序进行排序。
- 压缩:为了节省存储空间,倒排列表通常会进行压缩。常见的压缩方法包括变长编码、游程编码等。
2.7、数据压缩
对于 Elasticsearch 的压缩问题,假设有这样一个数组:
[73, 300, 302, 332, 343, 372]
如何把它进行尽可能的压缩?
Elasticsearch 中的数据压缩主要通过以下三个步骤实现:
-
增量编码(Delta-encode):只记录元素与元素之间的增量,例如数组 [73, 300, 302, 332, 343, 372] 经过增量编码后变为 [73, 227, 2, 30, 11, 29]。
-
分割成块(Split into blocks):在 Lucene 中,每个块包含 256 个文档 ID,这样可以保证每个块增量编码后,每个元素都不会超过 256(1 byte)。例如,我们可以将上述数组分割为两个块:[73, 227, 2] 和 [30, 11, 29]。
-
按需分配空间(Bit packing):根据每个块中最大元素的大小,按需分配空间。例如,对于第一个块 [73, 227, 2],最大元素是 227,需要 8 bits,所以为这个块的每个元素分配 8 bits 的空间。对于第二个块 [30, 11, 29],最大元素是 30,只需要 5 bits,所以为这个块的每个元素分配 5 bits 的空间。
这三个步骤共同组成了一种编码技术,称为 Frame Of Reference(FOR)。

这种技术可以有效地压缩数据,降低存储空间的需求。
3、数据更新原理
3.1、数据更新过程
Elasticsearch 的数据更新是不是就是 Elasticsearch 更新倒排列表?Elasticsearch 的数据更新过程确实包括更新倒排索引,但并不仅限于此。
当一个已存在的文档在 Elasticsearch 中被更新时,以下步骤会被执行:
- 版本控制:Elasticsearch 会检查更新请求中的版本信息,如果版本信息与当前文档的版本不匹配,更新操作会被拒绝。
- 删除旧文档:Elasticsearch 会将旧文档标记为删除,但不会立即从磁盘中删除。
- 插入新文档:Elasticsearch 会将新文档插入到索引中,这包括存储新文档的原始内容和元数据,以及更新倒排索引。
- 复制更新:为了提高数据的可用性和搜索性能,Elasticsearch 会将更新操作复制到其他节点的副本分片中。
- 确认更新:当更新操作被成功应用到主分片和所有副本分片后,Elasticsearch 会向用户发送一个确认响应。
所以,虽然更新倒排索引是 Elasticsearch 数据更新过程的重要部分,但并不是全部。Elasticsearch 还会进行一些其他处理,如版本控制、数据复制等。
3.2、更新倒排列表
更新倒排列表是在插入新的文档或更新已有文档时,对应词项的倒排列表需要进行更新。
以下是更新倒排列表的基本步骤:
- 查找词项:首先,根据词项查找对应的倒排列表。
- 添加文档 ID:如果是插入新的文档,将新文档的 ID 添加到倒排列表中。
- 删除文档 ID:如果是更新已有的文档,首先从倒排列表中删除旧文档的 ID,然后添加新文档的 ID。
- 排序:为了提高搜索效率,每次更新后都需要重新对倒排列表进行排序。
- 压缩:为了节省存储空间,每次更新后都需要重新对倒排列表进行压缩。
3.3、版本控制
在 Elasticsearch 中,版本控制主要有以下两个目的:
- 确保数据一致性:在分布式系统中,同一份数据可能会被多个节点同时操作,如果没有合适的控制机制,就可能导致数据不一致。通过版本控制,Elasticsearch 可以确保即使在并发操作的情况下,数据的一致性也能得到保证。
- 防止更新丢失:在并发更新的情况下,如果没有版本控制,较晚发出的更新请求可能会覆盖较早发出的更新请求的结果,导致更新丢失。通过版本控制,Elasticsearch 可以确保每个更新请求都会被正确地应用,防止更新丢失。
在 Elasticsearch 中,每个文档都有一个与之关联的版本号。当一个文档被更新时,Elasticsearch 会检查更新请求中的版本号,只有当版本号匹配时,才会执行更新操作。这样,就可以防止由于并发更新导致的数据不一致和更新丢失。
以下是版本控制的基本步骤:
-
检查版本号:当接收到一个更新请求时,Elasticsearch 会检查请求中的版本号。如果请求中的版本号与当前文档的版本号不匹配,Elasticsearch 会拒绝这个更新请求。
-
更新文档:如果版本号匹配,Elasticsearch 会进行更新操作,包括更新倒排列表、存储新的文档内容和元数据等。
-
更新版本号:完成更新操作后,Elasticsearch 会将文档的版本号加一。新的版本号会被存储在文档的元数据中,也会被返回给用户。
-
复制更新:为了保持数据的一致性,Elasticsearch 会将包含新的版本号的更新操作复制到所有的副本分片。
3.4、数据复制
在 Elasticsearch 中,为了提高数据的可用性和搜索性能,每个文档都会被复制到一个或多个副本分片中。因此,当更新倒排列表时,也需要将这个更新操作复制到所有的副本分片。
以下是数据复制的基本步骤:
-
发送复制请求:当主分片完成了更新操作后,它会将这个更新操作以请求的形式发送给所有的副本分片。
-
应用更新操作:副本分片收到复制请求后,会按照相同的步骤应用这个更新操作,包括更新倒排列表、存储新的文档内容和元数据等。
-
确认更新:副本分片完成更新操作后,会向主分片发送一个确认响应。
-
等待所有确认:主分片会等待所有副本分片的确认响应。当所有副本分片都确认更新操作成功后,主分片才会向用户发送一个确认响应。
以上就是 Elasticsearch 更新倒排列表时的数据复制过程。需要注意的是,这个过程可能会受到网络条件、副本分片的状态、集群的配置等因素的影响。
4、数据删除原理
4.1、数据删除原理
在 Elasticsearch 中,数据的删除并不是立即从磁盘中移除数据,而是通过标记的方式来实现的。
以下是 Elasticsearch 数据删除的基本步骤:
- 标记删除:当接收到一个删除请求时,Elasticsearch 不会立即删除数据,而是将对应的文档标记为已删除。
- 更新倒排索引:虽然文档被标记为已删除,但是它的词项仍然存在于倒排索引中。因此,Elasticsearch 会更新倒排索引,将已删除文档的词项从倒排索引中移除。
- 复制删除:为了保持数据的一致性,Elasticsearch 会将删除操作复制到所有的副本分片。
- 确认删除:当删除操作被成功应用到主分片和所有副本分片后,Elasticsearch 会向用户发送一个确认响应。
- 物理删除:被标记为已删除的文档在一段时间后,会在后台的合并(Segment Merging)过程中被物理删除。
以上就是 Elasticsearch 数据删除的基本原理。需要注意的是,这个过程可能会受到网络条件、副本分片的状态、集群的配置等因素的影响。
4.2、删除数据的恢复
在 Elasticsearch 中,一旦数据被删除,就无法直接恢复。这是因为 Elasticsearch 的删除操作是不可逆的,一旦一个文档被标记为已删除,就无法取消这个标记。
然而,你可以通过以下方式来尽可能地恢复被删除的数据:
-
备份和恢复:如果你有定期备份 Elasticsearch 数据,你可以从备份中恢复被删除的数据。Elasticsearch 提供了 Snapshot 和 Restore 功能,可以用来备份和恢复整个集群的数据。
-
重新索引:如果被删除的数据仍然存在于原始数据源中,你可以重新索引这些数据。这需要你有一个完整的数据源,并且知道如何从数据源中提取和索引数据。
-
使用软删除:在某些情况下,你可能希望保留被删除的数据,以便于以后恢复。这时,你可以使用软删除(Soft Delete)功能。软删除并不会真正删除数据,而是将数据标记为已删除。你可以在需要时取消这个标记,从而恢复数据。
需要注意的是,以上方法都有一定的限制,并不能保证100%恢复被删除的数据。因此,最好的策略还是定期备份数据,以防止数据丢失。




![buuctf-[GXYCTF2019]禁止套娃 git泄露,无参数rce](https://img-blog.csdnimg.cn/99adbfe03e804e4399282a047f043873.png)