openpyxl是Python下的Word库,它能够很容易的对Word文档进行读取
- 安装方法:
pip install python-docx - 国内镜像安装:
pip install -i https://mirrors.aliyun.com/pypi/simple/ python-docx(推荐,安装更快) - 中文文档:https://www.osgeo.cn/python-docx/index.html#
- 文档、段落、文字块之间的关系:
- 一个Word文档(document)由若干个段落(paragraph)组成;
- 一个段落(paragraph)可以由若干个文字块(run)组成;
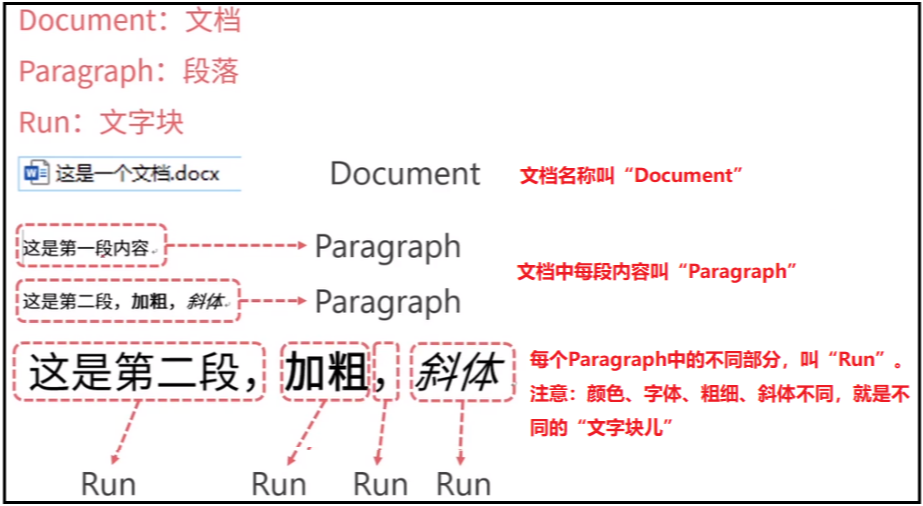
文档对象 - Document
- add_heading(text=‘’, level=1):添加标题
- add_paragraph(text=‘’, style=None):添加段落
- add_page_break():添加换页符
- add_table(rows, cols, style=None):添加表格
- add_picture(image_path_or_stream, width=None, height=None):添加图片
- paragraphs:获取文档内所有段落集合
- tables:获取文档内所有表格集合
- styles:获取文档内所有可用样式集合
- save(path_or_stream):保存文档
段落对象 - paragraph
- add_run(text=None, style=None):添加标题
- insert_paragraph_before(text=None, style=None):添加段落
- alignment:获取或设置段落对齐方式
- text:获取或设置段落文本
- runs:获取段落内所有文字块集合
- style:获取或设置段落样式
文字块对象 - run
- text:获取或设置文字块文本
- bold:获取或设置加粗
- italic:获取或设置倾斜
表格对象 - table
- add_row(text=None, style=None):添加行
- rows:获取所有行
- columns:获取所有列
- cell(row_idx, col_idx):根据行列索引获取指定单元格,其中(0,0)是最左上角的单元格
写入文件
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Cm, RGBColor, Ptdoc = Document()
"""添加标题"""
para_head = doc.add_heading("正文一级标题",level=1) # level代表标题级别
para_head.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 标题居中
"""添加正文段落"""
p1 = doc.add_paragraph("我是正文第一段")
p1.text += ",第一段追加文本"
p2 = doc.add_paragraph("我是正文第二段")
p2.insert_paragraph_before("我在第二段之前")
# doc.add_page_break() # 添加分页符
"""添加带文字块的段落"""
p3 = doc.add_paragraph("我是带样式的段落——")
p3.add_run("加粗").bold = True
p3.add_run("倾斜").italic = True
p3.add_run("正常")
red_run = p3.add_run("20,加粗,红色")
red_run.font.size = Pt(20)
red_run.font.bold = True
red_run.font.color.rgb = RGBColor(255,0,0)
"""添加有序和无序列表"""
opts = ['选项1','选项2', '选项3']
for opt in opts: # 有序列表doc.add_paragraph(opt, style='List Number')
for opt in opts: # 无序列表doc.add_paragraph(opt, style='List Bullet')
"""添加表格"""
list1 = [["姓名","性别","家庭地址"],["唐僧","男","湖北省"],["孙悟空","男","北京市"],["猪八戒","男","广东省"]]
table = doc.add_table(rows=4,cols=3) # 创建指定行列的表格
for row_index in range(4):row_cells = table.rows[row_index].cellsfor cell_index in range(3):row_cells[cell_index].text = str(list1[row_index][cell_index])
row_cells = table.add_row().cells # 添加一行
row_cells[0].text = "沙和尚"
row_cells[1].text = "男"
row_cells[2].text = "湖南省"
"""添加图片"""
doc.add_picture(r"resource/python.png") # 默认大小
doc.add_picture(r"resource/word.png",width=Cm(5),height=Cm(5)) # 指定宽高
"""保存文档"""
doc.save(r"resource/Test.docx")

读取文件
获取段落
from docx import Document
path = r"resource/Test.docx"
"""获取段落"""
doc = Document(path) # 读取的doc可通过save方法保存
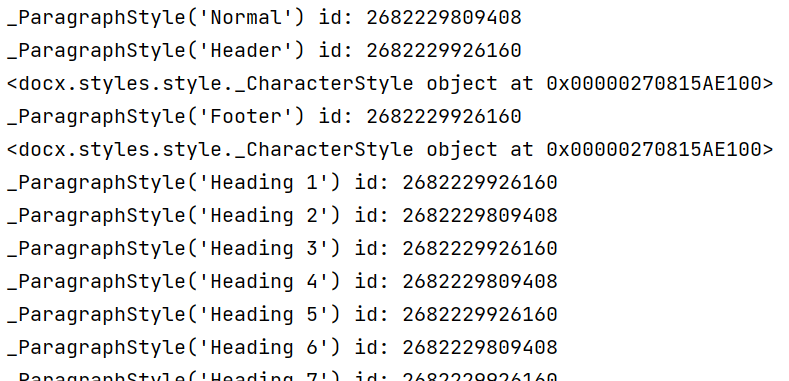
for paragraph in doc.paragraphs:print(paragraph.text,paragraph.style.name) # 段落text可修改,文字块、表格同样
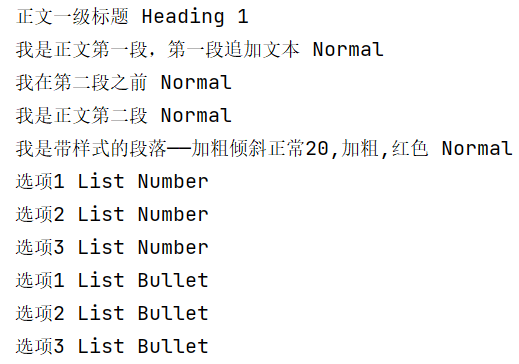
获取文字块
from docx import Document
path = r"resource/Test.docx"
"""获取文字块"""
p5 = doc.paragraphs[4]
for run in p5.runs:print(run.text,run.bold,run.italic)

获取表格
from docx import Document
path = r"resource/Test.docx"
"""获取表格"""
table0 = doc.tables[0]
for row in table0.rows: # 获取表格所有行for cell in row.cells: # 获取表格行的所有单元格print(cell.text,end=" ")print()
print(table0.cell(2,0).text) # 根据行列索引获取指定单元格

获取图片
import os
from docx import Document
path = r"resource/Test.docx"
"""获取图片"""
for rel in doc.part.rels: # 获取所有part对象的id(rel→str,例如rId3)rel = doc.part.rels[rel] # 根据id获取文件对象if "image" in rel.target_ref: # 根据part对象的名称判断是否是图片(例如media/image1.jpeg)with open("resource/"+os.path.basename(rel.target_ref), "wb") as f:f.write(rel.target_part.blob) # 将图片以二进制格式写入
获取所有可用样式
for style in doc.styles:print(style)