作业数据是所有数据都有标签的版本。
李宏毅 2022机器学习 HW3 boss baseline 上分记录
- 1. 训练数据增强
- 2. cross validation&ensemble
- 3. test dataset augmentation
- 4. resnet
1. 训练数据增强
结论:训练数据增强、更长时间的训练、dropout都证明很有效果,实验效果提升至接近strong baseline
增强1:crop + geometry
增强2:crop + geometry + gray
另外epochs数目增加到100,patience增加到10个epochs,FC层增加 dropout(0.3)
增强代码如下
#训练数据增强代码train_tfm = transforms.Compose([# Resize the image into a fixed shape (height = width = 128)# transforms.Resize((128, 128)),transforms.RandomResizedCrop(size=(128, 128), scale=(0.8, 1)),# 几何变换transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomRotation(degrees=180),transforms.RandomAffine(degrees=30),#像素变换transforms.RandomGrayscale(p=0.2), # You may add some transforms here.# ToTensor() should be the last one of the transforms.transforms.ToTensor(),
])
具体实验结果如下:

2. cross validation&ensemble
使用5-fold cross validation,划分的时候使用分层抽样,
2.1)epochs=100, patience=10
训练时发现通常在60 epochs左右就early stop了,最终public score不如之前,但private score有提升,说明cross validation在过拟合上还是有效果的。

2.2)epochs=100, patience=16,再看看效果
patience增大后,效果有了一个非常明显的提升,超过strong baseline。具体看实验过程,会发现之前patience=10的时候,基本60epochs就停了,而现在patience=100的时候,early stop没有起作用,都是训练满100个epochs。猜测应该是使用5-fold的cross validation时,对比默认的train/valid,一方面训练数据更多,另一方面valid数据变少波动性更大,所以应该给更多的时间训练。

3. test dataset augmentation
结论:此方式有效,分数进一步提升

测试数据的具体增强方式如下:
在步骤2的基础上,对test数据集使用了train数据集的数据增强方式,生成5张图片预测,对预测结果值平均,然后再用这个结果与原预测结果平均。以下为作业PPT相关部分。

4. resnet
使用torchvision自带的resnet模型(按照作业要求,pretrained=False),尝试了resnet18和resnet50,效果进一步有了明显提升。public榜上超过bossline,但是从private榜上,可以看出存在一定过拟合。 另外resnet50的效果并没有比resnet18好,可能是小数据集的原因。这里均使用epochs=200,patience=16, lr=0.0003, weight_decay=1e-5。
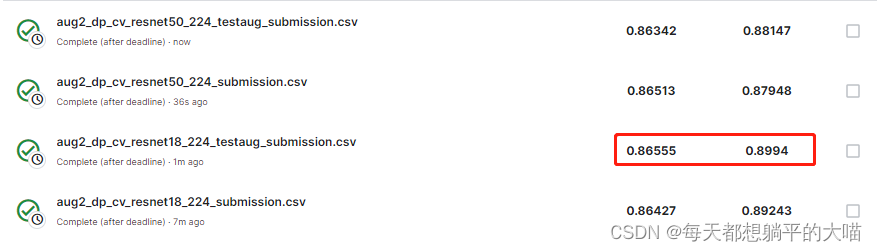

两个注意点:
1,图片size设成224x224(论文中使用的图片尺寸),对比了128和224,两者差别很大。
2,resnet中的全连接层需要从原来的1000改成此次任务预测的类别数目11,代码如下:
def model_resnet():resnet = resnet18(pretrained=False)resnet.fc = nn.Sequential(nn.Linear(resnet.fc.in_features, 512),nn.ReLU(),nn.Dropout(0.3),nn.Linear(512, 11))return resnet