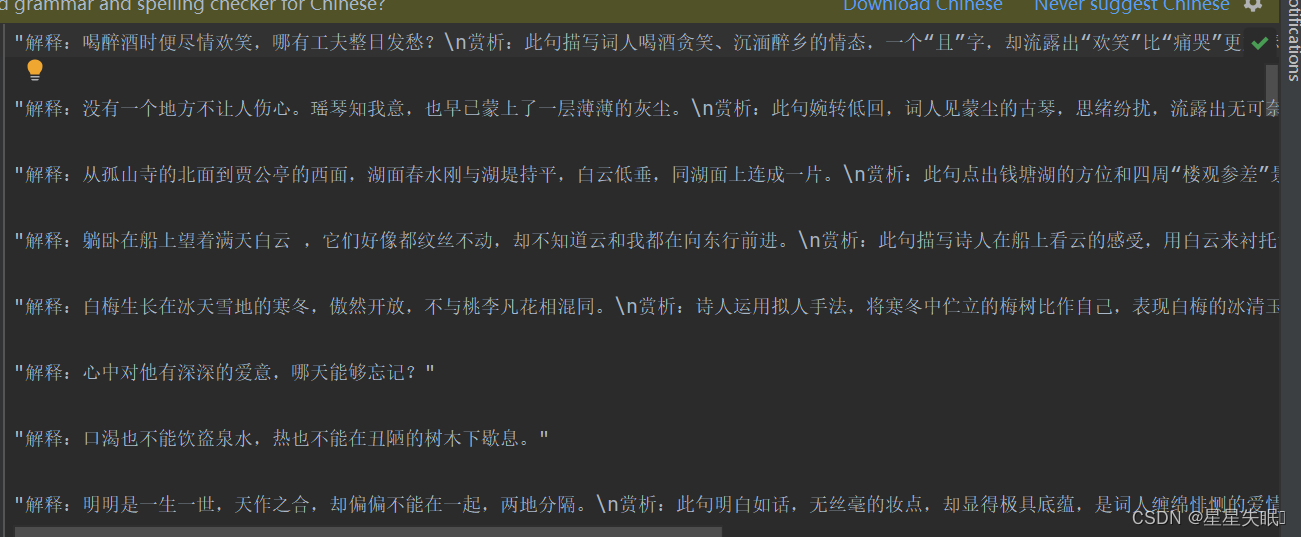
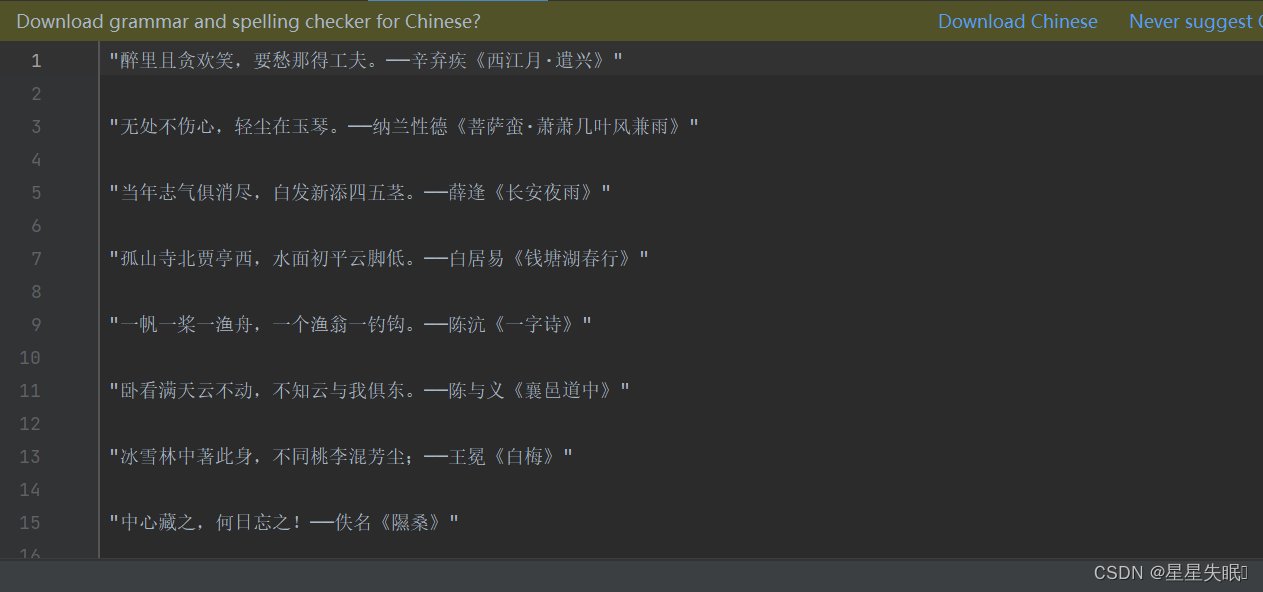
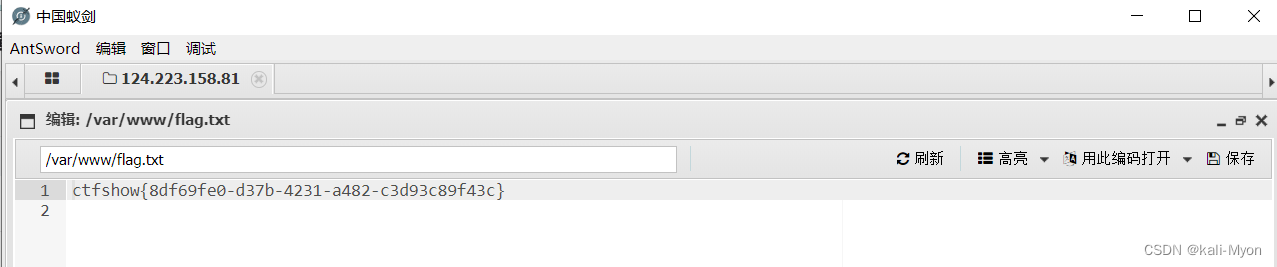
访问古诗文网站(https://so.gushiwen.org/mingju/)
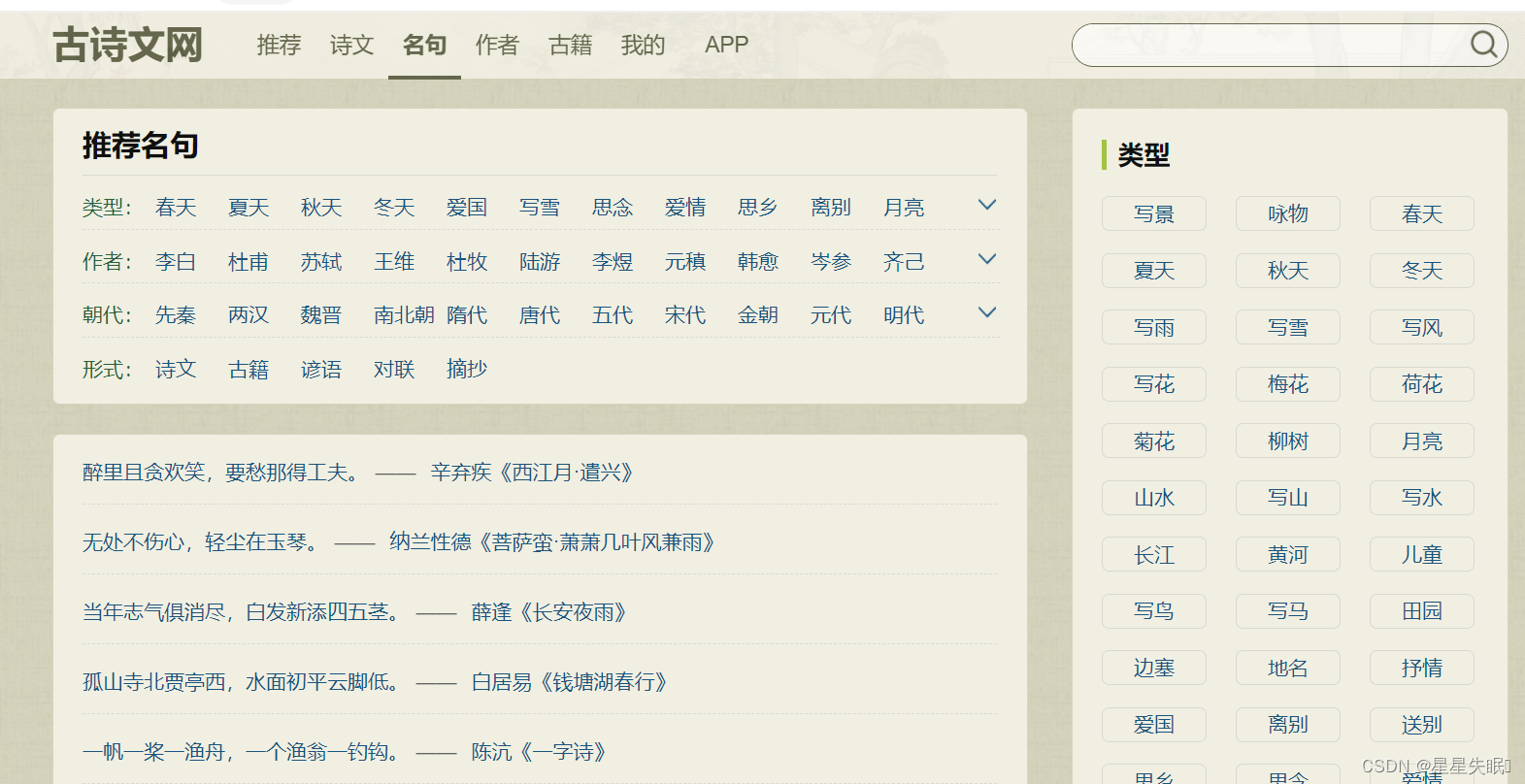
会显示出这个页面,里面包含了很多的名句,点击某一个名句(比如点击无处不伤心,轻尘在玉琴)就会出现完整的古诗
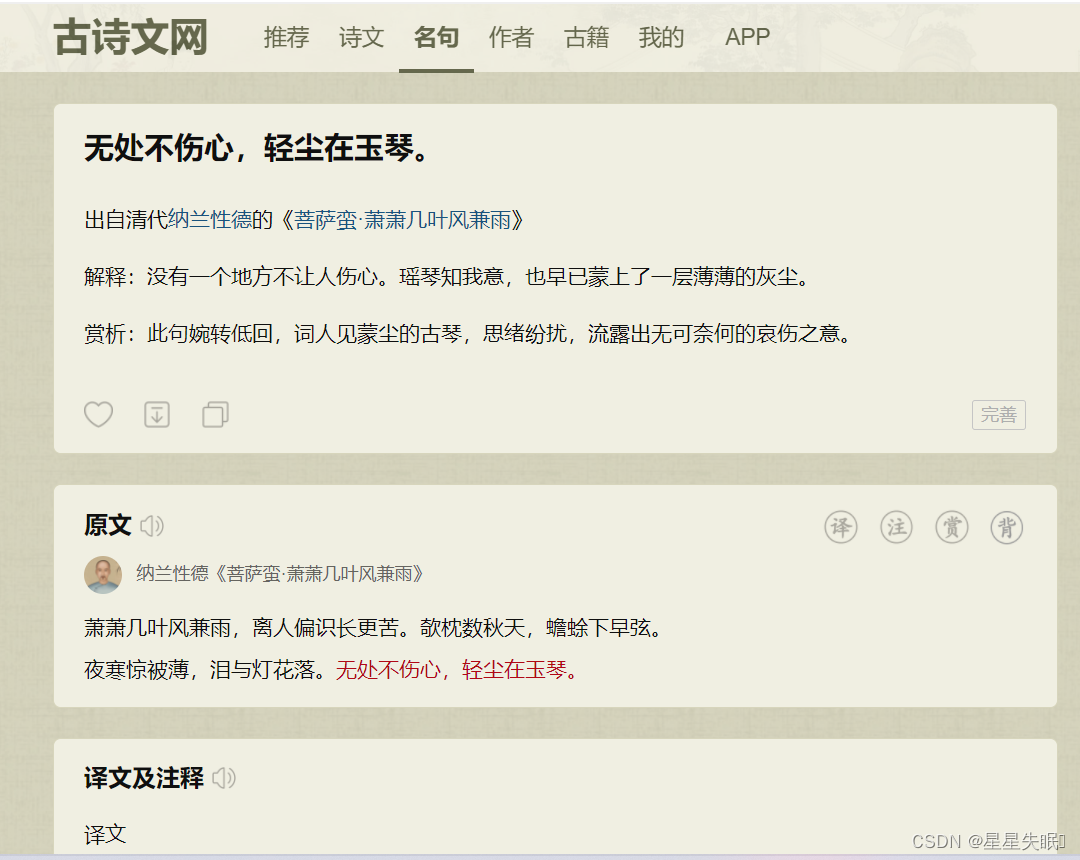

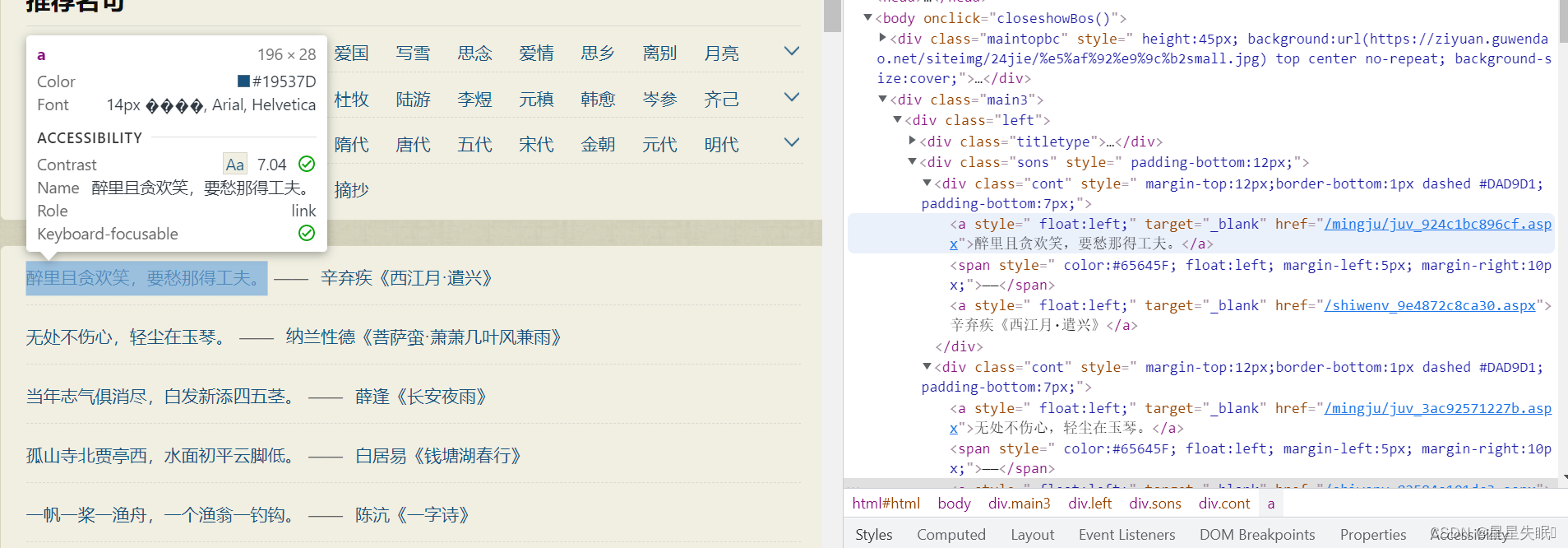
我们点击鼠标右键,点击检查
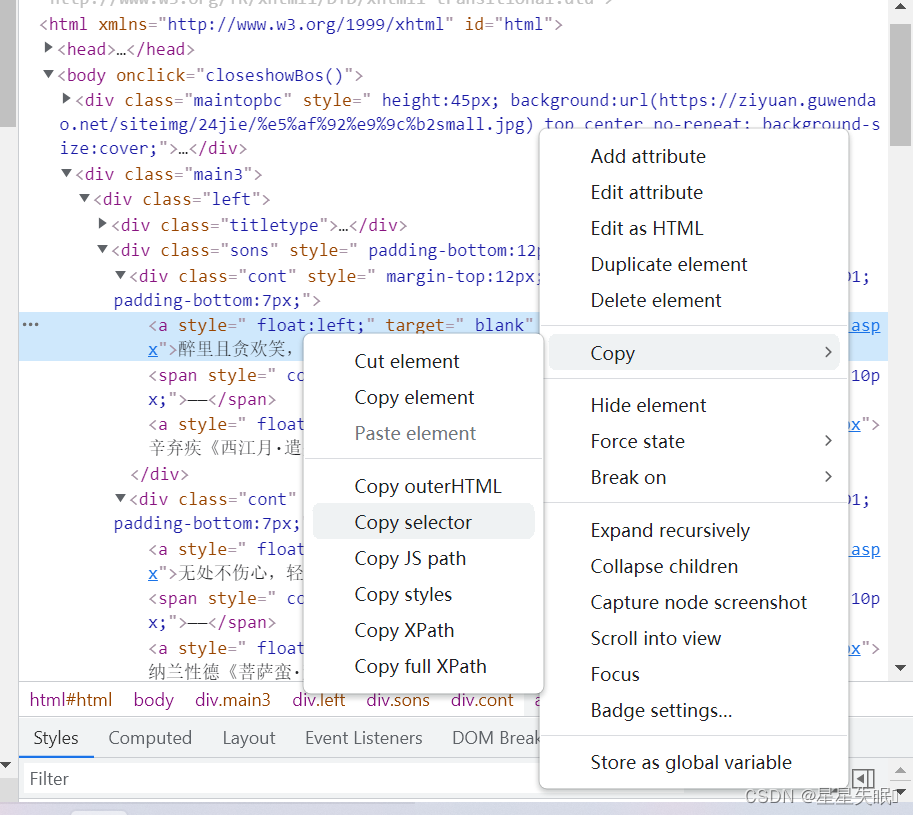
点击copy selector
右击对应标签,选择Copy -> Copy selector,即可获得对应元素的CSS选择器。
body > div.main3 > div.left > div.sons > div:nth-child(1)
我们就会得到大致的路径,
将复制得到的CSS选择器粘贴在soup.select()中即可。
import requests
from bs4 import BeautifulSoup
import time# 函数1:请求网页
def page_request(url, ua):#user-agent就是请求头,否则不给出请求头网站是没有办法爬取的response = requests.get(url, headers=ua)#请求头就是我们传进来的ua,我们调用的时候就会把ua传进来html = response.content.decode('utf-8')#解码,用utf-8进行解码return html#请求网站,这个函数会把html代码返回回来,作为这个函数的结果值返回回来,返回回来的结果作为第二个函数的输入# 函数2:解析网页
def page_parse(html):#从里面解析出相关诗句的内容,上一个函数把html代码返回来,这个函数就可以对它进行解析soup = BeautifulSoup(html, 'lxml')#html是传过来的源代码,lxml你使用的是lxml解析器title = soup('title')#网页有title我们可以把title这个头拿出来# 诗句内容:诗句+出处+链接info = soup.select('body > div.main3 > div.left > div.sons > div.cont')#用select方法去获得标签,属性用.表示,如果查找id用#表示,我们得到了很多标签,返回的是一个列表,因为其中很多元素符合要求#通过这行语句你获得了许多div标签# 诗句链接sentence = soup.select('div.left > div.sons > div.cont > a:nth-of-type(1)')#div.cont下面的子标签a,并且要求这个子标签a是div.cont第一个子标签a,这行包括了href我们可以通过索引值把href取出来,就可以得到网页的链接地址#第一个链接就会有href,就是诗词的链接地址sentence_list = []href_list = []for i in range(len(info)):curInfo = info[i]#从info[0]开始获得第一个poemInfo = ''poemInfo = poemInfo.join(curInfo.get_text().split('\n'))#.join是进行字符串的链接操作的 .get_text方法会把当前div中的文本都提取出来,我们会提取出来很多行,用split用换行符进行拆分,就会拆分出三个字符串,把三个字符串拼接起来sentence_list.append(poemInfo)#把刚才得到的一行加到列表里面去,每次遍历一遍就会加一个,列表中就会有许多诗句的基本信息href = sentence[i].get('href')#sentence是以列表的形式返回的,sentence[0]href_list.append("https://so.gushiwen.org" + href)#还需要加上网站的域名前缀,href不带有域名前缀,得到完整的地址# todo sentence 和 poet数量可能不符# sentence = soup.select('div.left > div.sons > div.cont > a:nth-of-type(1)')# poet = soup.select('div.left > div.sons > div.cont > a:nth-of-type(2)')# for i in range(len(sentence)):# temp = sentence[i].get_text() + "---" + poet[i].get_text()# sentence_list.append(temp)# href = sentence[i].get('href')# href_list.append("https://so.gushiwen.org" + href)return [href_list, sentence_list]#把两个结构返回去,herf包含了一个又一个的链接,而sentence,会把一个句子一个句子返回def save_txt(info_list):#把得到的文本文件保存起来,我们要得到sentence.txtimport jsonwith open(r'sentence.txt', 'a', encoding='utf-8') as txt_file:#python基本打开文件的模式a代表追加for element in info_list[1]:#infolist是整个列表的两个,它包含了两个子列表,infolist【1】就代表sentencelist,它会把sentence——list中每个元素遍历一遍txt_file.write(json.dumps(element, ensure_ascii=False) + '\n\n')
#遍历一遍,把每一行句子都用.dumps写到文本文件里面去
# 子网页处理函数:进入并解析子网页/请求子网页
def sub_page_request(info_list):#我们访问古诗文网站,还要点进去,info_list包含两个列表,第一个是链接的列表,第二个是诗句的列表subpage_urls = info_list[0]#这个包含了所有的链接地址ua = {#有请求头才可以顺利的爬取'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36'}sub_html = []for url in subpage_urls:html = page_request(url, ua)#page_requests的功能给出请求的地址他会把html的代码返回回来,给出url地址返回htmlsub_html.append(html)#sub_html包含了一个又一个元素,每个元素都是一段html代码,html代码是具体点到某个诗句的网页的代码return sub_html#是个列表,包含了很多元素,每个元素都是一个子网页的html代码# 子网页处理函数:解析子网页,爬取诗句内容
def sub_page_parse(sub_html):#返回的是一大堆,我只想要赏析代码poem_list = []for html in sub_html:#把每个html代码进行遍历,赋值给htmlsoup = BeautifulSoup(html, 'lxml')#用lxml解析器对html代码进行解析poem = soup.select('div.left > div.sons > div.cont > div.contson')if len(poem) == 0:continuepoem = poem[0].get_text()#poem是列表poem_list.append(poem.strip())#去掉空格return poem_list# 子网页处理函数:保存诗句到txt
def sub_page_save(poem_list):#poem_list得到的是个列表,每个元素都是一行import jsonwith open(r'poems.txt', 'a', encoding='utf-8') as txt_file:for element in poem_list:#poem_是个列表txt_file.write(json.dumps(element, ensure_ascii=False) + '\n\n')if __name__ == '__main__':print("**************开始爬取古诗文网站********************")ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36'}poemCount = 0for i in range(1, 5):#依次执行# todo 链接错误# url = 'https://so.gushiwen.org/mingju/default.aspx?p=%d&c=&t=' % (i)url = 'https://so.gushiwen.cn/mingjus/default.aspx?page=%d' % iprint(url)# time.sleep(1)html = page_request(url, ua)#把url传进去,请求头传进去,获取html代码,这是传入的初始网页info_list = page_parse(html)#我们把html代码传进去,就可以对代码进行解析save_txt(info_list)# 开始处理子网页---------------------上面处理的都是主网页,下面要处理子网页,也就是点进去之后的网页print("开始解析第%d" % i + "页")# 开始解析名句子网页sub_html = sub_page_request(info_list)#info-list是经过page_list解析过得,就是把子网页的链接传进来了poem_list = sub_page_parse(sub_html)#对子网页html代码进行解析,解析出每个诗词的句子,它的解释赏析,放到poem_list里面sub_page_save(poem_list)poemCount += len(info_list[0])#爬取了多少行print("****************爬取完成***********************")print("共爬取%d" % poemCount + "个古诗词名句")print("共爬取%d" % poemCount + "个古诗词")