增加LLM上下文长度可以提升大语言模型在一些任务上的表现,这包括多轮长对话、长文本摘要、视觉-语言Transformer模型的高分辨4k模型的理解力以及代码生成、图像以及音频生成等。
对长上下文场景,在解码阶段,缓存先前token的Key和Value(KV)需要巨大的内存开销,其次主流的LLM模型在推理的时候上下文长度都小于等于训练时的上下文长度。为了约束长文本时缓存先前KV的内存和计算量,很容易想到的方法是对KV进行加窗选择,这样可以限制参与当前token计算的KV历史数量,将内存和计算量约束在可控的范围内。
Llama 2官方支持的标准版模型(下称基座模型)上下文长度是是4k,而Chinese-LLaMA-Alpaca-2基于支持16K上下文,并可通过NTK方法进一步扩展至24K+,在大语言模型之十一 Transformer后继者Retentive Networks (RetNet)博客中知道随着上下文长度的增加,基座模型在训练和推理时Attention模块的内存和算力需求按照文本长度的平方倍增加。
EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS,观察到一个有趣的现象,该论文称之为attention sink,即初始token的KV对于加窗Attention方法的得到的模型性能较为重要(尽管从语义上来看,对于长文本而言初始的token并不重要),StreamingLLM是根据这一思想(保留有限数量的最近KV以及初始的Attention sink)开源的不限上下文长度方法(论文中给的上下文token可长达4百万)。
LongLoRA的paper以Llama-2中给出了文本增加的算力需求增加情况,当上下文长度从2k变为8k的时,模型的自注意力模块计算量将增加16倍。
想要减少长上下文的内存和算力需求,可以从改变Transformer的Attention结构以及优化GPU计算单元这两个方面出发,在充分利用GPU算力基础上(FlashAttention结构),优化Transformer的Attention计算和推理结构(如LongLoRA),此外还有在大语言模型之十一 Transformer后继者Retentive Networks (RetNet)博客中提及微软的RetNet,其将并行计算的Attention改成了RNN结构的Attention结构,既可以在训练时并行又可以在推理的时RNN计算,这使得算力并不会随着上下文长度增加而显著上升,几乎可以做到不限上下文长度。
本篇介绍的基座模型Llama-2 7B将上下文长度从4k扩充到100k,基于FlashAttention和LongLoRA技术,二者利用了GPU和Transformer的Attention结构改进两方面的技术。此外通过finetune来扩展上下文长度还有以下一些方法:
- Position Interpolation: 增强版的RoPE将Llama扩展到32K
- Focused Transformer使用contrastive learning 训练得到 LongLLaMA
- Landmark attention计算量比1和2更高,但是精度损失较大,将长文本压缩成了retrieved tokens
- NTK-aware
- Yarn
- positional Skipping
- out-of-distribution related method
StreamingLLM
该方法利用attention sink现象,采用缓存头尾KV的方式,并不需要额外重新训练模型,只需要改变Attention模块的forward计算使用到的历史信息即可,即在基座模型上修改Attention的前向推理即可。该方法的对比原理图如下:
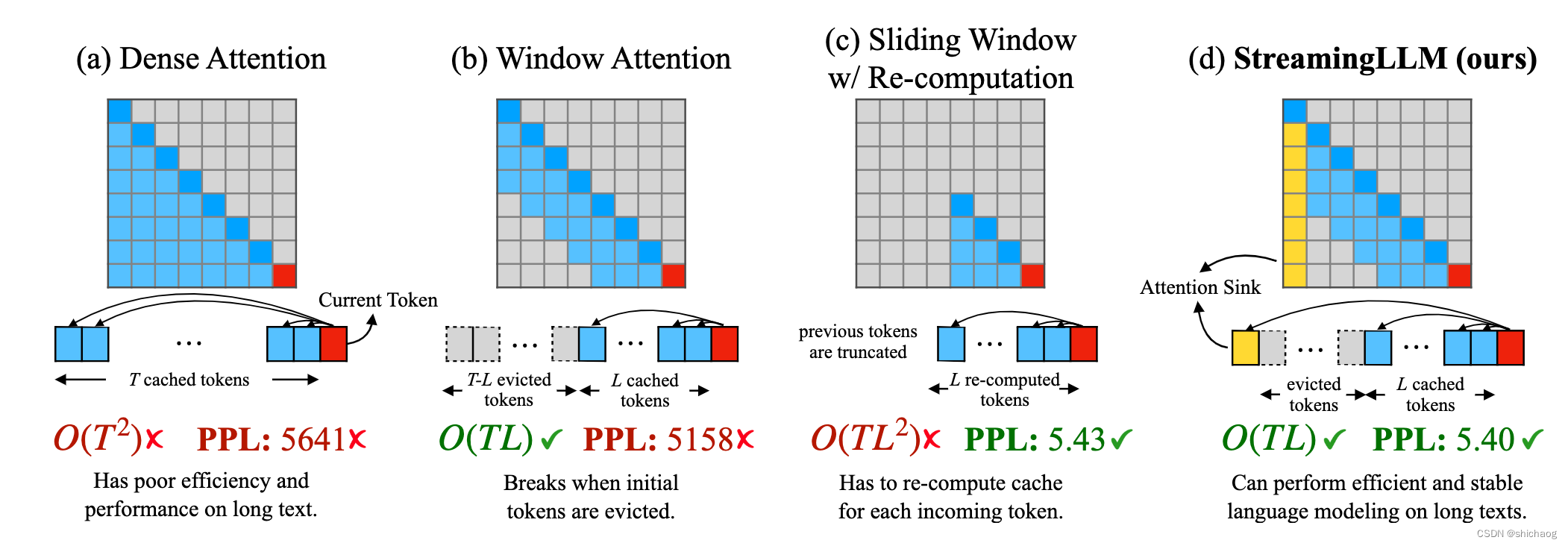
这是基于LLama-2-13B的测试数据情况,图a是密集注意力模型,即计算当前token时,会缓存先前T个token的KV值,缓存的长度是大于训练时上下文长度的,图b是加窗注意力模型,T-L个token状态将不再缓存,只缓存最近的L个KV值,这使得计算量大大减少,但是PPL却并不是很理想。图c的滑窗方法会重新计算最近L个token缓存的KV值,但是计算复杂度高,耗时长,图d是StreamingLLM中给出的方法,始终保留Attention sink(初始几个token的KV),然后在同保留的最近L个token的KV值一起计算当前token的Attention值,其在计算效率和混淆度上取得了不错的收益。
官方给出了前向推理llama的示例方法,enable_streaming_llm,这一方法并不一定在所有LLM上都能取得该表现,我个人觉得采取这一方法需要较为谨慎。这里分析主要是为了梳理其中的思想方法。
如果对图中每行的意义不是很理解,那么可以参考《大语言模型之四-LlaMA-2从模型到应用》中图三第一个Linear层的“你好!”为例,
- 第一次输入是你,对应第一行,因为是第一个token,因而先前的缓存的KV没有;
- 第二次输入是好,对应于第二行,因为是第二个token(深色),浅蓝色则是缓存的“你”输入是的KV,可以依次类推,
- 第三次输入是!,对应于第三行,两个浅蓝色块是“你好”,从这个下三角可以看出模型是因果的(即当前的输入token只能看到历史的KV)。
替换Attention模块的forward方法如下:
def enable_llama_pos_shift_attention(model):for name, module in reversed(model._modules.items()):if len(list(module.children())) > 0:enable_llama_pos_shift_attention(module,)if isinstance(module, LlamaAttention):model._modules[name].forward = types.MethodType(llama_pos_shift_attention_forward, model._modules[name])
启用LLAMA模型中的位置偏移注意力机制。它遍历了给定模型的所有模块,如果模块是LlamaAttention类型,则将其前向传递函数替换为llama_pos_shift_attention_forward函数。该函数实现了位置偏移注意力机制,它可以在LLAMA模型中提高性能。
parser.add_argument("--start_size", type=int, default=4)parser.add_argument("--recent_size", type=int, default=2000)
默认缓存前四个token的KV值,并且缓存最近2000个KV值。
LongLoRA
LongLoRA的paper以Llama-2为实验对象,LongLoRA在Attention层和权重层都节约了算力资源。论文中主要引入了shifted short attention,这个结构和Flash-Attention是兼容的,并且在推理的时候并不需要,论文中将Llama-2的7B模型上下文从4K扩充到了100K,13B基座模型扩充到了64K,70B基座模型上下文扩充到了32K。
LoRA通过低秩矩阵将self-Attention矩阵进行了线性投影(矩阵的低秩分解),即将一个参数量为NxN的矩阵分解为Nxd和dxN的两个矩阵,而这2xd却远小于N,如d取64,而N取4096,这就使得需要训练的参数量大大减少。LoRA方法可行的前提是假设基座模型在迁移的时候本质上是一个低秩(low intrinsic rank)问题,但是这种方法对长上下文情况,单单采用LoRA会导致混淆度(perplexity)较高。在经典的Transformer架构中,LoRA方法通常只改变Attention层权重。
LongLoRA相比LoRA有两点改进,第一点是:类似Attention层一样,embedding和normalization层参数也会参与微调训练调整;第二点是:S2(shift short) Attention机制,这两点的修改显示在paper图中:
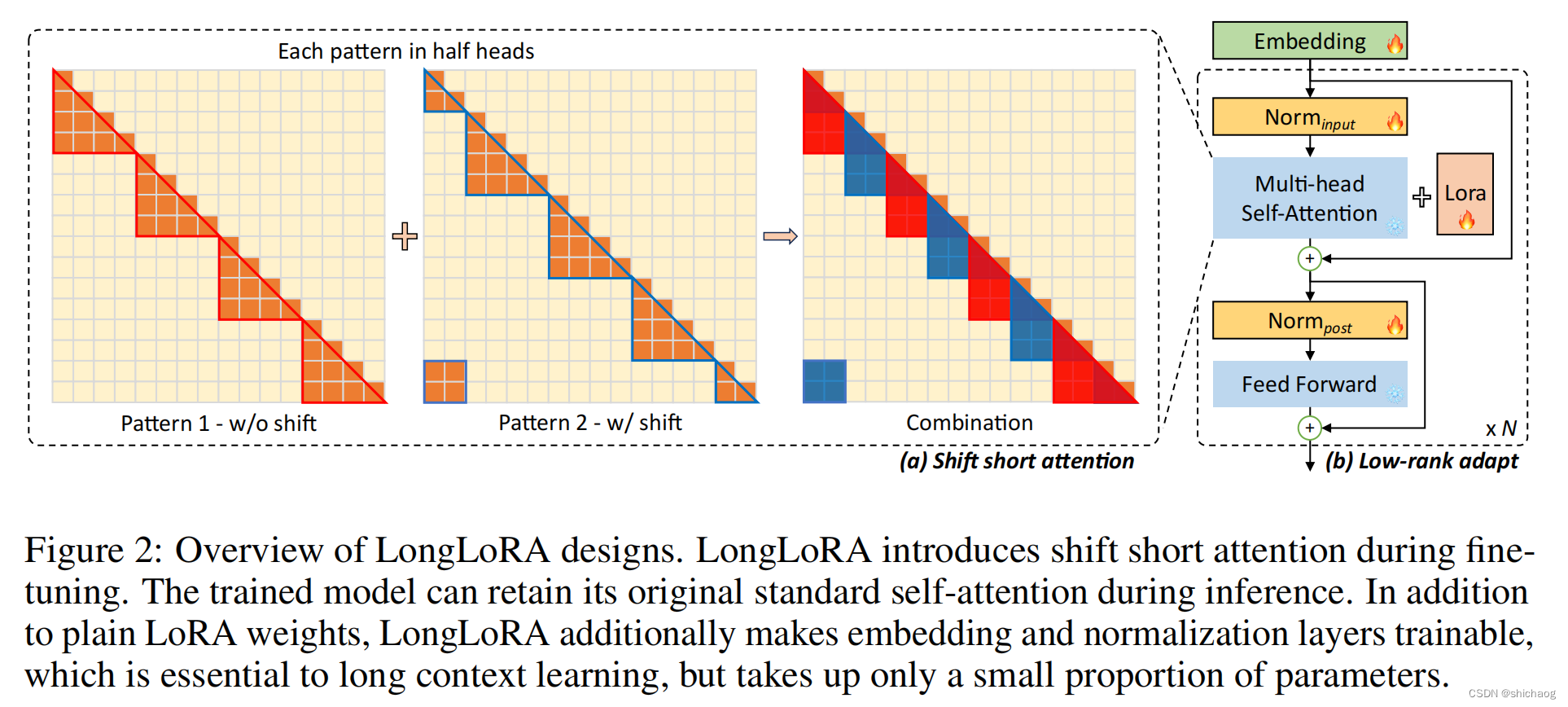
从右边可以看到LoRA是Self-Attention而言的,而LongLoRA除了有红色的LoRA部分,对Embedding和Norm层都进行参数调整(图中有🔥的部分都是调整的对象),对于算力以及内存的需求对比这里不展示了,有兴趣可以进一步参考论文。
有必要对shift short进行展开一下,假设LLM训练的时候是按照2k上下文进行的,对于一个长度为8k的输入文本token,记为[1,2,…,8192],则在训练的时候会被分为4个组,每个组上下文长度是2k,即:
[1,2,…,2048],[2049,2050,…,4096],[4097,4098,…,6144],[6145,6146,…,8192],这四个组在训练的时候是分开进行的,每个组之间Attention模块并没有进行信息交互,如果按照传统的方式分为n(8192)个组[1,2,…,2048],[2,3,…,2049]…,这样训练的时间又会非常多,S2-Attention就是在这个方式下提出的,方法是按照目标上下文长度的1/2循环移动上下文token,对于上面的8192个token,shift之后为[1025,1026,…,3072],[3073,3074,…,5120],[5121,5122,…,7168],[7169,7170,…,1023,1024],这使得每个shift之后的每个分组有一半是前一个分组,一半是后一个分组,如[1025,1026,…,3072],各有一半在[1,2,…,2048]和[2049,2050,…,4096]。
Deep Vison lab开源了longLoRA的fine-tune代码,fine-tune.py
首先加载模型和tokenizer,这在前几篇博客中反复提及了的,使用的是Huggingface提供的接口。
# Load model and tokenizermodel = transformers.AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path,config=config,cache_dir=training_args.cache_dir,torch_dtype=torch.bfloat16,)tokenizer = transformers.AutoTokenizer.from_pretrained(model_args.model_name_or_path,cache_dir=training_args.cache_dir,model_max_length=training_args.model_max_length,padding_side="right",use_fast=True,)
多线程加载训练数据集
rank = int(os.environ.get('RANK', -1))if rank > 0:barrier()dataset = load_dataset("togethercomputer/RedPajama-Data-1T-Sample", cache_dir=training_args.cache_dir)dataset = dataset.map(partial(tokenize_fn,tokenizer),batched=True, num_proc=128, remove_columns=["text", "meta"])if rank == 0:barrier()
接来下是loRA参数配置
config = LoraConfig(r=8,lora_alpha=16,target_modules=targets,lora_dropout=0,bias="none",task_type="CAUSAL_LM",)model = get_peft_model(model, config)
train是常规的train过程
trainer = Trainer(model=model, tokenizer=tokenizer, args=training_args, train_dataset=dataset["train"],eval_dataset=None,data_collator=data_collator)trainer.train()
S2-Attention的实现和StreamingLLM的方法类似,都是更改基座模型Attention的forward方法。
def replace_llama_attn(use_flash_attn=True, use_full=False, inference=False):if use_flash_attn:cuda_major, cuda_minor = torch.cuda.get_device_capability()if cuda_major < 8:warnings.warn("Flash attention is only supported on A100 or H100 GPU during training due to head dim > 64 backward.""ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593")if inference:transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = _prepare_decoder_attention_mask_inferencetransformers.models.llama.modeling_llama.LlamaAttention.forward = forward_flashattn_inferenceelse:transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (_prepare_decoder_attention_mask)transformers.models.llama.modeling_llama.LlamaAttention.forward = forward_flashattn_full if use_full else forward_flashattnelse:transformers.models.llama.modeling_llama.LlamaAttention.forward = forward_noflashattn
其自身实现的方法添加了flashattn方法,这里可以忽略,在计算atten时,多了一个shift操作,修改(就是增加了几行代码)的代码行数并不多。
# shiftdef shift(qkv, bsz, q_len, group_size, num_heads, head_dim):qkv[:, num_heads // 2:] = qkv[:, num_heads // 2:].roll(-group_size // 2, dims=2)qkv = qkv.transpose(1, 2).reshape(bsz * (q_len // group_size), group_size, num_heads, head_dim).transpose(1, 2)return qkvquery_states = shift(query_states, bsz, q_len, group_size, self.num_heads, self.head_dim)key_states = shift(key_states, bsz, q_len, group_size, self.num_heads, self.head_dim)value_states = shift(value_states, bsz, q_len, group_size, self.num_heads, self.head_dim)