文章目录
- 1. MVCC多版本并发控制机制
- 2. BufferPool缓存机制
1. MVCC多版本并发控制机制
Mysql可以在可重复读隔离级别下可以保证事务较高的隔离性,这个隔离性是由MVCC机制来保证的,对一行数据的读和写两个操作默认是不会通过加锁互斥来保证隔离性,避免了频繁加锁互斥,而在Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。
undo日志版本链与read view机制详解
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且用两个隐藏字段trx_id(事务ID)和roll_pointer(会滚指针)把这些undo日志串联起来形成一个历史记录版本链。
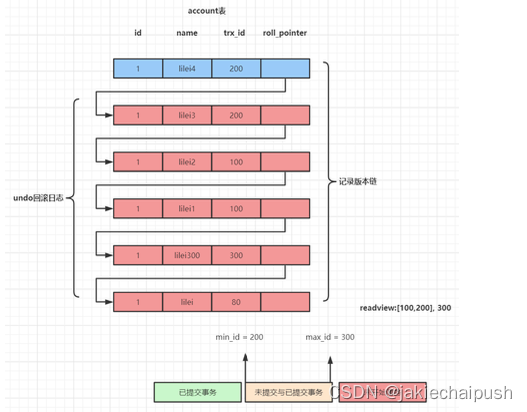
trx_id:表示对数据修改的事务的ID
roll_pointer:指向被修改数据的上一个版本
在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事 id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
注意:begin/start transaction命令并不是一个事务的起点,在执行到它们之后的第一个修改操作InnoDB表的语句时事务才算是真正的启动,此时事务会向Mysql申请事务ID,mysql内部是严格按照事务的启动顺序来分配事务ID的

版本链比对规则:
- 如果 row 的 trx_id 落在绿色部分( trx_id<min_id ),表示这个版本是已提交的事务生成的,这个数据是可见的;
- 如果 row 的 trx_id 落在红色部分( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是不可见的(若 row 的 trx_id 就是当前自己的事务是可见的);
- 如果 row 的 trx_id 落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况
a. 若 row 的 trx_id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自
己的事务是可见的);
b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
read-view执行原理案例分析
这里首先列出了五个事务的sql语句执行情况,如下:
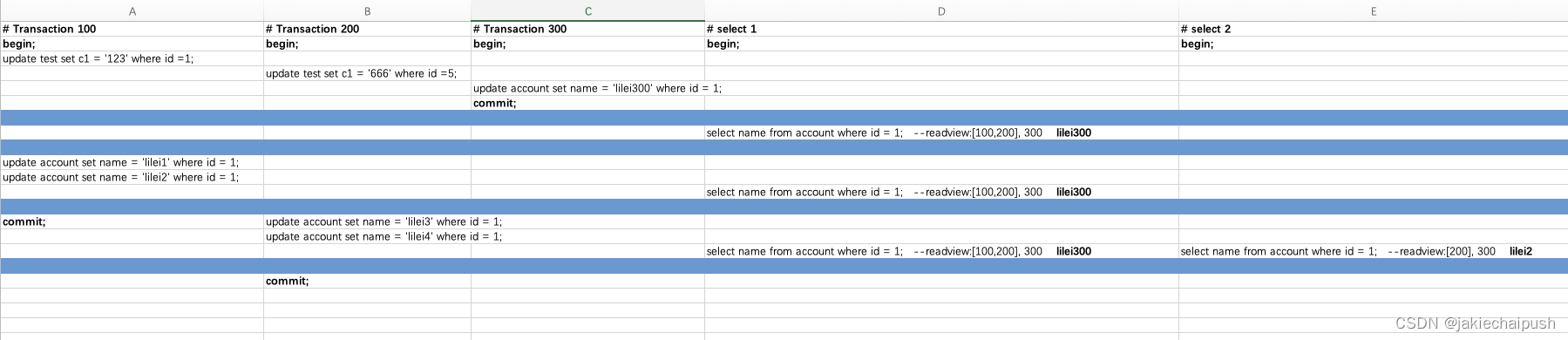
由上图可见,总共有五个事务,事务的id为
100,200,300,1,2,下面我们就来逐步分析:
- 首先事务300执行
update account set name = 'lilei300' where id = 1;然后提交。接着事务ID为1的事务执行select name from account where id = 1;
我们可以很简单的看出查询结果为lilei300,那为什么会是lilei300。首先我们可以看出此时的undo.log的日志版本链的情况是这样的:

其中蓝色为最新的数据,红色为老数据。然后mysql会维护一个事务集,如下:
然后mysql会从日志版本链的最新的数据开始向下遍历,这个例子先从上面第一个蓝色的开始,取出其事务ID为300,到事务集合中去比对,发现位于黄色的区域(即有可能还是未提交),然后判断是否在事务ID的read-view数组中(该数组前面说过是由活跃事务的ID数组以及最大已提交事务组成),目前由第一张事务的执行情况图我们可以看出,目前事务ID为1的read-view为
[100,200],300构成,而300没在read-view的活跃数组中,所以300对数据进行的更改对事务1是可见的,所以日志版本链就不需要向下遍历了,查询的结果即为lilei300。
- 然后ID为100的事务又执行了两条更新语句,分别为
update account set name = 'lilei1' where id = 1;和update account set name = 'lilei2' where id = 1;,接着ID为1的事务再次执行了查询select name from account where id = 1;
同样从会滚日子链开始分析,蓝色同样为最新的数据,红色为老数据,目前的日子版本链的情况如下所示:
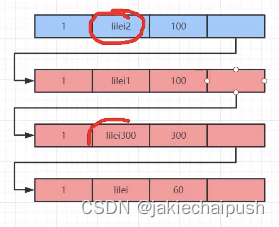
首先从最新的数据开始便利日志版本链,首先拿到ID为100的数据,比对事务集合,其同样落在黄色区域,然后事务ID1比较其readview,发现其落在了活跃数组[100,200]中(注意除非一些特殊情况ID为1的事务对数据进行了一些修改,其readview在整个过程中一般是不变的,虽然每次执行一次查询语句都会重新生成read-view),所以其对ID为1的事务是不可见的。然后接着向下遍历,知道遍历到ID为300的事务,发现其是可见的,所以查询到的数据同样是lilei300。后面的过程同样是按照这个过程分析。
mysql通过这个机制在RR隔离级别下实现了事务的可重复读而不用加锁。而在读已提交的情况下Mysql同样实现了MVCC机制,不同于RR级别,在读已提交的隔离级别下,每当一个事务被提交,其它事务相应的read-view会及时更新。
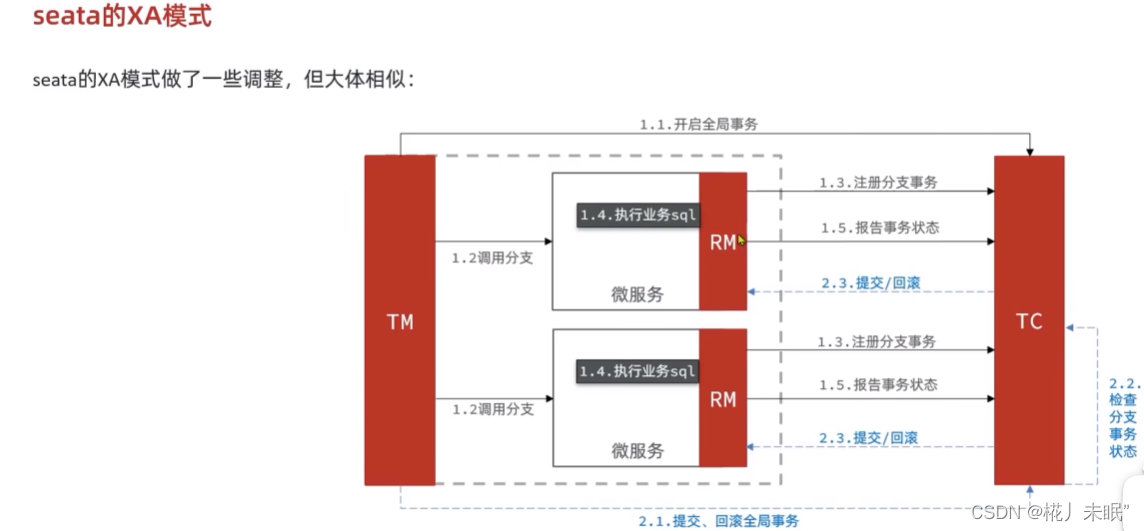
2. BufferPool缓存机制
InnoDB引擎SQL执行的BufferPool缓存机制如下所示:
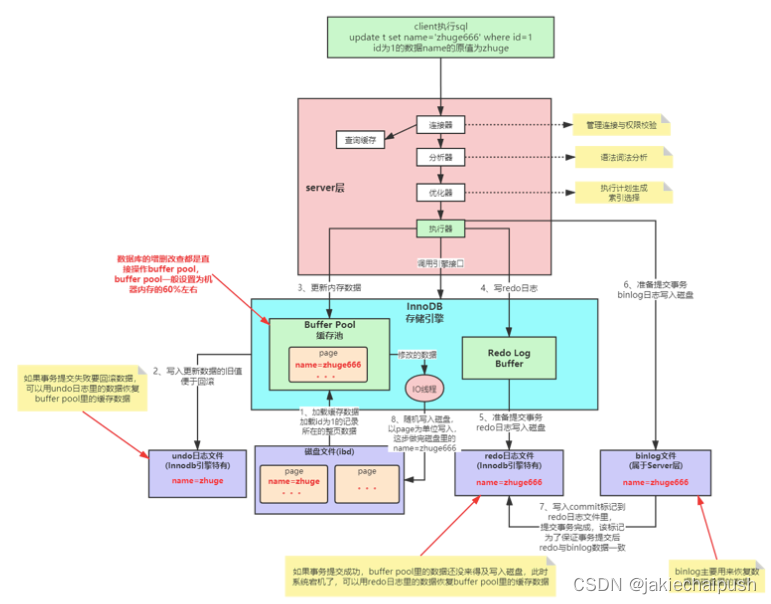
对上图进行分析:
- 首先客户端执行sql语句
update t set name='zhuge666' where id=1 - 然后经过连接器进行客户端的权限验证(判断该客户端是否有修改该条数据的权限)
- 然后通过分析器对sql语句进行词法分析
- 接着经过优化器来生成sql执行计划以及选择合适的索引
- 最后来到执行器开始真正执行sql(InnoDB层)
- 首先InnoDB会将id为1的数据所在的页加载到BufferPool中
- 然后将要更新的那条数据旧的值写入到undo日志中(用于后期会滚)
- 然后更新BufferPool中的缓存数据
- 然后将更新情况写入到redo日志缓存中
- 客户端准备提交事务
- 首先redo日志写入到磁盘
- binlog(主要用于回复数据库磁盘中的数据)日志写入磁盘
- 写入commit标记到redo日志文件中,提交事务完成,该标记为了保证事务提交后redo于binlog日志的一致性。
- Mysql后台IO线程随机以page为单位将更新后的数据写入到磁盘
以上便是该sql语句执行的整个过程,但对于上面的过程可能还会存在下面这些问题:
- InnoDB体系结构是什么样子的?
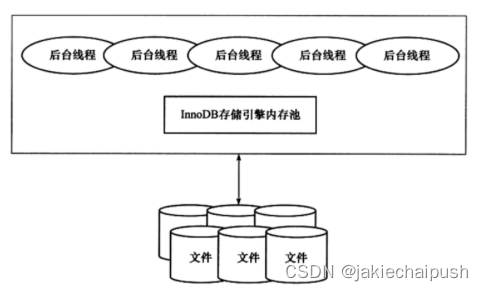
InnoDB存储引擎有多个内存块,可以认为这些内存块共同组成了一个大的内存池,负责如下工作:
- 维护所有进程/线程需要访问多个内部数据结构
- 缓冲磁盘上的数据,方便快速读取(bufferPool),同时在对磁盘文件的数据修改之前在这里缓存
- 重做日志缓存(redo.log)
…
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存是最近的数据。此外将修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下InnoDB能够恢复到正常运行的状态。
- Mysql的bufferpool的组成?
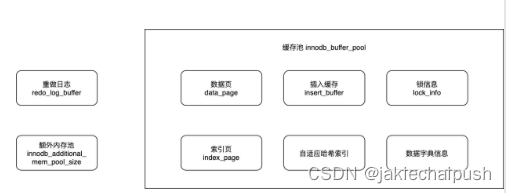
3. Mysql是如何对缓冲池进行管理?
通常来说数据库中的缓冲池是通过LRU算法来进行管理的,即最频繁使用的页在LRU列表的前端,而最少使用的页在LRU列表的尾端。但InnoDB使用的并不是朴素的LRU算法,而是在LRU列表中加入了midpoint的位置,midpoint将LRU列表的数据页分为热数据和冷数据两部分。(这部分还是比较复杂的)
- rode日志的刷新时机?
- Master Thread每一秒将重做日志缓存刷新到重做日志文件
- 每个事务提交时会将重做日志缓存刷新到重做日志文件
- 当重做日志缓存剩余空间下雨1/2时,重做日志缓存刷新到重做日志文件
- 为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。 Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。 更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。 正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几千的读写请求。