参考
sklearn中SVC中的参数说明与常用函数_sklearn svc参数-CSDN博客![]() https://blog.csdn.net/transformed/article/details/90437821
https://blog.csdn.net/transformed/article/details/90437821
参考PYthon 教你怎么选择SVM的核函数kernel及案例分析_clf=svm.svc(kernel=)-CSDN博客![]() https://blog.csdn.net/c1z2w3456789/article/details/105247565
https://blog.csdn.net/c1z2w3456789/article/details/105247565
四种核函数

四种核函数在四种不同分布数据上的表现
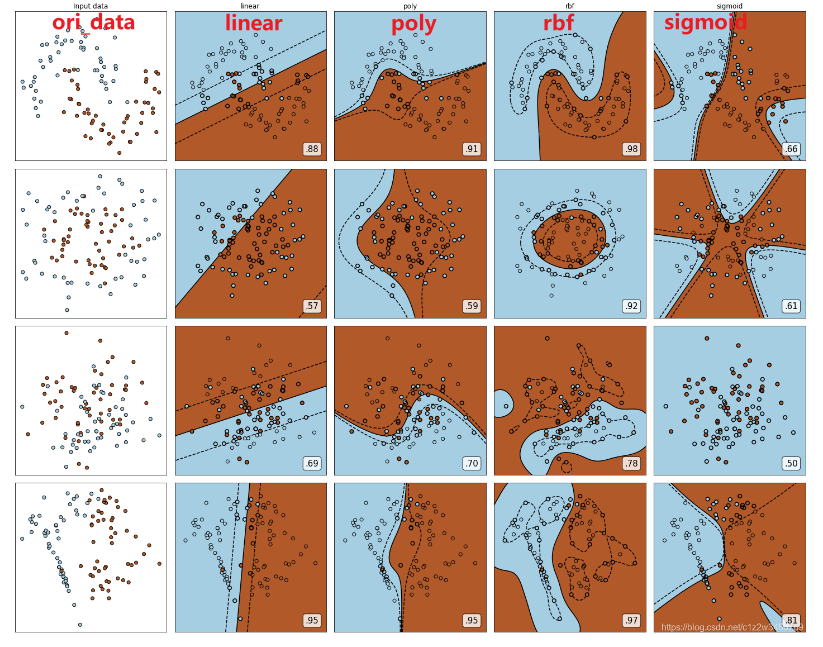
博主总结:
linear、poly:
非线性数据集:linear和poly核函数在上表现会浮动,如果数据相对线性可分,则表现不错,如果是像环形数据那样彻底不可分的,则表现糟糕。
线性数据集:linear和poly核函数即便有扰动项也可以表现不错,可见poly核函数虽然也可以处理非线性情况,但更偏向于线性的功能。
sigmoid:
Sigmoid核函数就比较尴尬了,它在非线性数据上强于两个线性核函数,但效果明显不如rbf,它在线性数据上完全比不上线性的核函数们,对扰动项的抵抗也比较弱,所以它功能比较弱小,很少被用到。
rbf:
rbf核函数基本在任何数据集上都表现不错,属于比较万能的核函数。
python中svm使用
clf = svm.SVC(kernel='rbf', class_weight='balanced', C=5, gamma=0.3, max_iter=3000, tol=0.001, probability=True)
C:根据官方文档,这是一个软间隔分类器,对于在边界内的点有惩罚系数C,C的取值在0-1之间,默认值为1.0。C越大代表这个分类器对在边界内的噪声点的容忍度越小,分类准确率高,但是容易过拟合,泛化能力差。所以一般情况下,应该适当减小C,对在边界范围内的噪声有一定容忍。
class_weight:默认为None,给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面指出的参数C.
tol:停止训练的误差精度,默认值为0.001
probability:默认为False,决定最后是否按概率输出每种可能的概率,但需注意最后的预测函数应改为clf.predict_proba。
max_iter:默认为-1,最大迭代次数,如果为-1,表示不限制