关于TDSQL-C Serverless介绍
TDSQL-C 是腾讯云自主研发的新一代云原生关系型数据库。
它融合了传统数据库、云计算和新硬件技术的优势,100%兼容 MySQL,为用户提供具有极致弹性、高性能、高可用性、高可靠性和安全性的数据库服务。
TDSQL-C 实现了超过百万每秒的高吞吐量,支持 PB 级海量分布式智能存储,并具备 Serverless 秒级扩缩能力,可加速企业数字化转型。
其 Serverless 服务是建立在腾讯云自研的新一代云原生关系数据库 TDSQL-C MySQL 版之上的无服务器架构实现,是一款全 Serverless 架构的云原生数据库。
Serverless 服务按实际使用的计算和存储资源进行收费,不用不付费,将腾讯云的云原生技术普惠用户。
适用的场景介绍
这类数据库实际是按量付费的,非常适合在测试和研发环境使用,如果业务存在明显的波动期,那么它的弹性伸缩功能也是比较适合的。对于一些小程序的云开发,小企业的一些网站建设也可以考虑此类数据库。
数据库购买
- 这里简单介绍下如何找到这款数据库
-
搜索进入腾讯云注册并登录
-
在搜索框输入 TDSQL-C MYSQL 版 , 点击搜索
-
点击立即选购
-
根据需要调整配置 注意 选择Serverless 的实例形态哦!!!
-
配置TDSQL-C 集群
-
根据实例信息连接数据库
- 如果你只是想体验下功能,那么可以通过如下链接进行免费体验:
https://mc.tencent.com/uQHh7pDI
数据库压测
- sysbench安装
我们通过sysbench做个简单的压测,看下数据库的一些性能指标
安装,通过如下命令
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh |bash yum install -y sysbench
通过如下命令进行检验:
sysbench --version
- 压测数据写入
通过执行如下命令,新建20张表,并且每个表中构建出 100万条测试数据,具体的host、port、user、password根据实际情况进行修改,新建的表也可以根据自己需要去建立。
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=gz-cynosdbmysql-grp-d27hp6vl.sql.tencentcdb.com --mysql-port=27529 --mysql-user=root --mysql-password=password --mysql-db=experience-15 --tables=20 --table_size=1000000 oltp_read_write --db-ps-mode=disable prepare
- 整体的读写测试
测试数据库的综合读写TPS,使用oltp_read_write模式
通过如下命令执行,可以看到控制台有压测数据输出,如果你想要输出到文件,也可以通过命令配置实现
因为目前实际访问是通过公网进行的,这里只是提供一个压测的思路,感兴趣可以自己在内网实践下
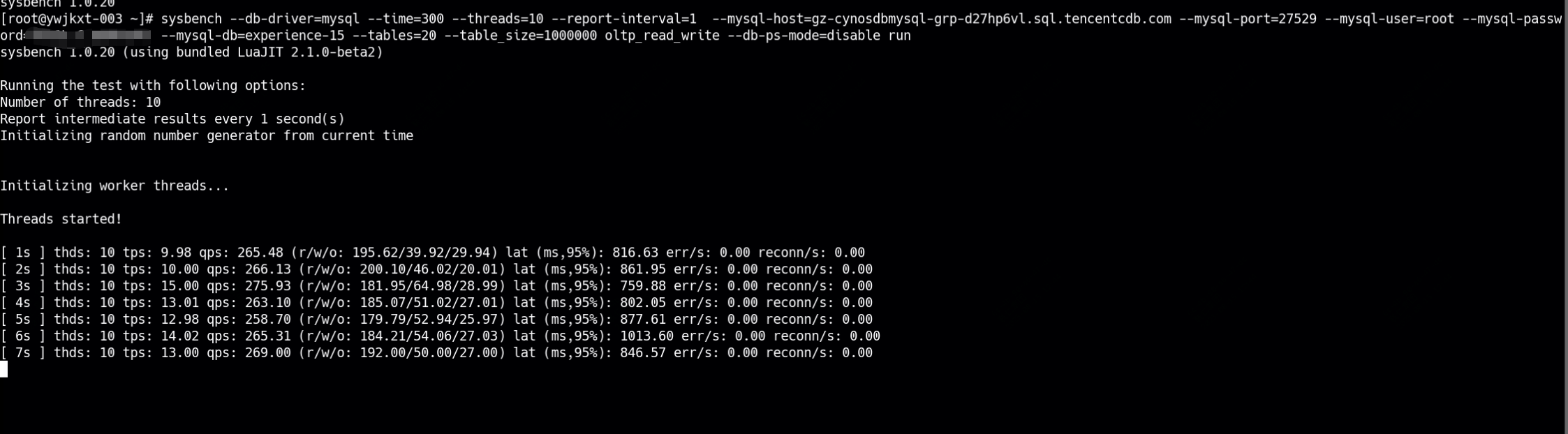
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=gz-cynosdbmysql-grp-d27hp6vl.sql.tencentcdb.com --mysql-port=27529 --mysql-user=root --mysql-password=password --mysql-db=experience-15 --tables=20 --table_size=1000000 oltp_read_write --db-ps-mode=disable run
控制台压测数据:
注意:
使用sysbench对数据库进行读写测试时,需要注意的几点:
-
- 选择合适的测试模式,如顺序读/写、随机读/写等,根据实际业务场景选用。
-
- 调整线程数和测试时长,逐步增加压力直到找到数据库的压力瓶颈。
-
- 测试前后要重新加载测试数据,避免缓存影响结果。
-
- 对照不同的数据库参数进行测试,如buffer pool大小、索引设置等。
-
- 记录不同压力情况下的指标,如TPS、延迟、资源利用率等。
- 只读性能测试
测试数据库的只读性能,使用oltp_read_write模式,执行命令如下:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 -mysql-host=gz-cynosdbmysql-grp-d27hp6vl.sql.tencentcdb.com --mysql-port=27529 --mysql-user=root --mysql-password=password --mysql-db=experience-15 --tables=20 --table_size=1000000 oltp_read_only --db-ps-mode=disable run
- 插入性能测试
测试数据库的数据插入性能,使用模式:oltp_insert,命令如下:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 -mysql-host=gz-cynosdbmysql-grp-d27hp6vl.sql.tencentcdb.com --mysql-port=27529 --mysql-user=root --mysql-password=password --mysql-db=experience-15 --tables=20 --table_size=1000000 oltp_insert --db-ps-mode=disable run
关于一些性能测试的情况,官方也是给出一些数据的,可以参考:
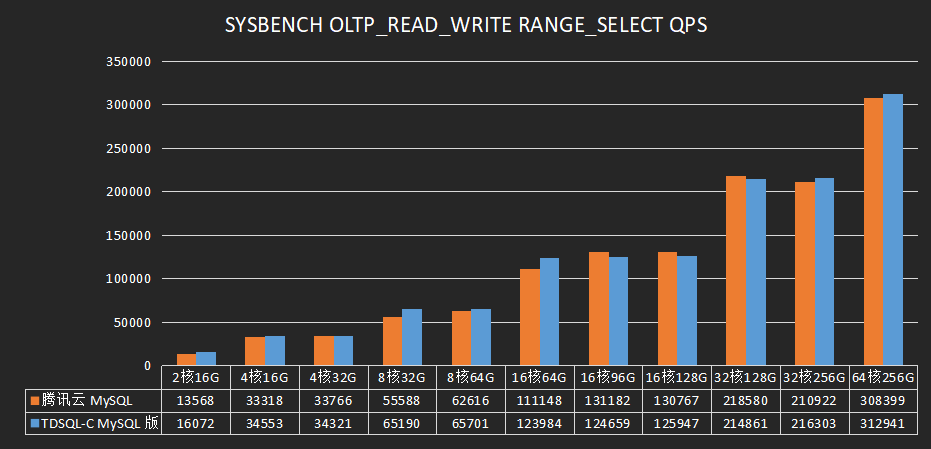
实际使用体验
使用 Python 向 TDSQL-C 添加读取数据 实现词云图

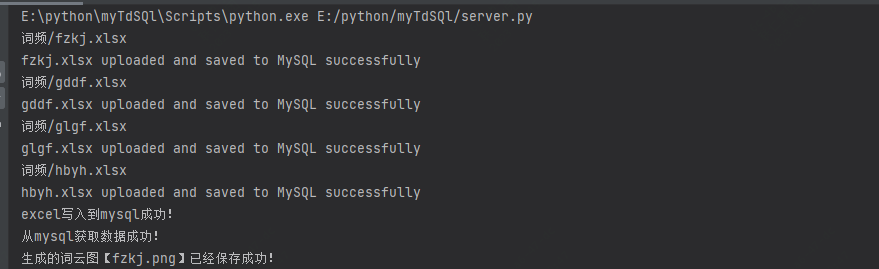
整个实践步骤如下:
- 准备python环境,安装依赖包
pip install PyMySQL==1.1.0
pip install pandas==2.0.1
pip install wordcloud==1.9.1.1
pip install numpy==1.23.5
pip install matplotlib==3.7.2
pip install Pillow==9.5.0
- 配置数据库连接信息
- 创建读取excel文件的函数
- 根据excel文件名创建数据库表名
- 将读取的excel 数据保存到数据库对应的表中
如下是通过读取excel后存入数据库的数据,在使用上与常规的数据库没有差别
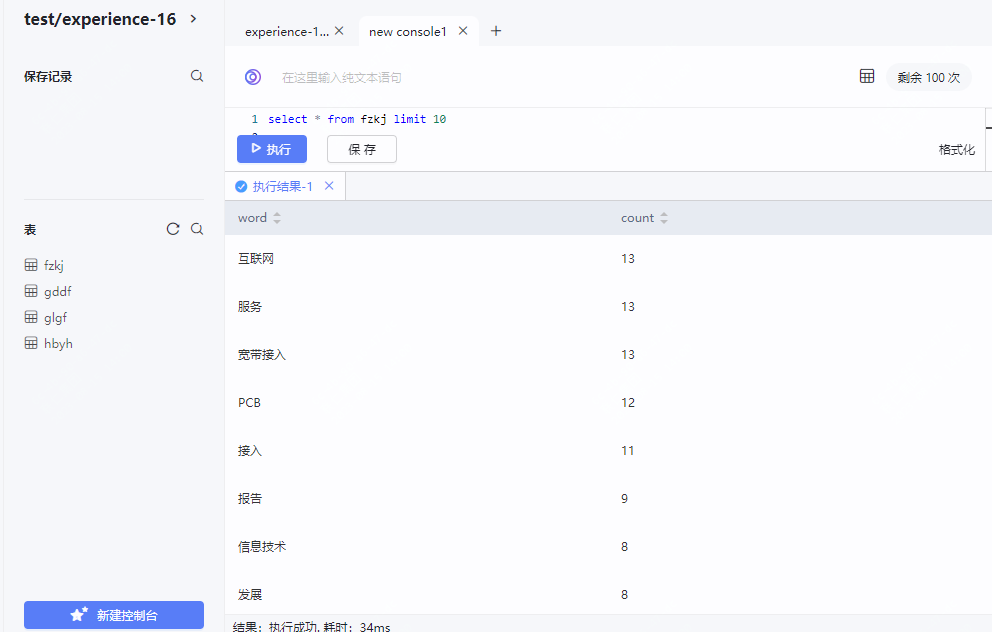
- 读取数据库中存入的数据
- 执行函数,并生成词云图
如下为根据代码生成的词云图

完整代码如下:
import pymysql
import pandas as pd
import os
import wordcloud
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt# MySQL数据库连接配置
db_config = {'host': "gz-cynosdbmysql-grp-d27hp6vl.sql.tencentcdb.com", # 主机名'port': 27529, # 端口'user': "root", # 账户'password': "pass", # 密码'database': 'experience-16',}def create_table(table_name, columns):# 建立MySQL数据库连接conn = pymysql.connect(**db_config)cursor = conn.cursor()# 组装创建表的 SQL 查询语句query = f"CREATE TABLE IF NOT EXISTS {table_name} ("for col_name, col_type in columns.items():query += f"{col_name} {col_type}, "query = query.rstrip(", ") # 去除最后一个逗号和空格query += ")"# 执行创建表的操作cursor.execute(query)# 提交事务并关闭连接conn.commit()cursor.close()conn.close()def excelTomysql():path = '词频' # 文件所在文件夹files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径for file_path in files:print(file_path)filename = os.path.basename(file_path)table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名# 使用pandas库读取Excel文件data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型create_table(table_name, columns) # 创建表save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名print(filename + ' uploaded and saved to MySQL successfully')def save_to_mysql(data, table_name):# 建立MySQL数据库连接conn = pymysql.connect(**db_config)cursor = conn.cursor()# 将数据写入MySQL表中(假设数据只有一个Sheet)for index, row in data.iterrows():query = f"INSERT INTO {table_name} ("for col_name in data.columns:query += f"{col_name}, "query = query.rstrip(", ") # 去除最后一个逗号和空格query += ") VALUES ("values = tuple(row)query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符query += ")"cursor.execute(query, values)# 提交事务并关闭连接conn.commit()cursor.close()conn.close()def query_data():# 建立MySQL数据库连接conn = pymysql.connect(**db_config)cursor = conn.cursor()# 查询所有表名cursor.execute("SHOW TABLES")tables = cursor.fetchall()data = []dic_list = []table_name_list = []for table in tables:# for table in [tables[-1]]:table_name = table[0]table_name_list.append(table_name)query = f"SELECT * FROM {table_name}"# # 执行查询并获取结果cursor.execute(query)result = cursor.fetchall()if len(result) > 0:columns = [desc[0] for desc in cursor.description]table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result]data.extend(table_data)dic = {}for i in data:dic[i['word']] = float(i['count'])dic_list.append(dic)conn.commit()cursor.close()conn.close()return dic_list, table_name_listif __name__ == '__main__':##excelTomysql()方法将excel写入到mysqlexcelTomysql()print("excel写入到mysql成功!")# query_data()方法将mysql中的数据查询出来,每张表是一个dic,然后绘制词云result_list, table_name_list = query_data()print("从mysql获取数据成功!")for i in range(len(result_list)):maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图# 定义词云样式wc = wordcloud.WordCloud(font_path='PingFangBold.ttf', # 设置字体mask=maskImage, # 设置背景图max_words=500, # 最多显示词数max_font_size=100) # 字号最大值# 生成词云图wc.generate_from_frequencies(result_list[i]) # 从字典生成词云# 保存图片到指定文件夹wc.to_file("词云图/{}.png".format(table_name_list[i]))print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))# 在notebook中显示词云图plt.imshow(wc) # 显示词云plt.axis('off') # 关闭坐标轴plt.show() # 显示图像
总结
-
腾讯云 TDSQL-C MySQL Serverless 版是国内首个也是最大规模的 MySQL 无服务器数据库产品,其最大的特点和优势在于高度弹性灵活的使用方式,根据实际使用量进行计费,不使用则不收费,非常适合对业务量波动较大且难以预计的中小企业或个人开发者。这种按需使用和计费的模式,极大降低了使用成本和资源浪费。100%兼容MySQL,几乎无需改动代码,即可完成数据库的查询、应用和工具平滑迁移。
-
TDSQL-C MySQL Serverless 版特别适合一些刚刚上线或者业务量难以预测的新服务。对于业务负载存在周期性波动的应用也非常合适,可以根据高峰期和低峰期进行实时调整,无需固定预留资源,既灵活又经济。最高400TB存储,无服务器架构,自动扩缩容,轻松应对业务数据量动态变化和持续增长。
-
与传统数据库相比,TDSQL-C MySQL Serverless版可以实现秒级的启停容量扩缩容,根据实际使用情况弹性调整,并且实行按量计费模式,可以精确到秒级别计费,使用灵活而不会造成资源浪费。最高400TB存储,无服务器架构,自动扩缩容,轻松应对业务数据量动态变化和持续增长。
-
如果业务主要部署在微信生态内,例如微信小程序,TDSQL-C MySQL Serverless版可以与微信生态深度整合,为小程序等微信平台的开发者提供一站式的后端云数据库服务。开发和运维非常便捷高效。计算节点可根据业务需要快速升降配,秒级完成扩容,结合弹性存储,实现计算资源的成本最优。
-
对于已经存在的数据库或数据,TDSQL-C MySQL Serverless版也提供了多种快速迁移的方案。除了使用腾讯云提供的数据传输服务DTS迁移外,还可以通过mysqldump等命令行工具进行数据迁移,整个迁移过程可以做到快速便捷。


![[PyTorch][chapter 57][WGAN-GP 代码实现]](https://img-blog.csdnimg.cn/1a227a6496cf4e3fb077aa12551839c9.png)