NLP - 数据预处理 - 文本按句子进行切分
文章目录
- NLP - 数据预处理 - 文本按句子进行切分
- 一、前言
- 二、环境配置
- 1、安装nltk库
- 2、下载punkt分句器
- 三、运行程序
- 四、额外补充
一、前言
在学习对数据训练的预处理的时候遇到了一个问题,就是如何将文本按句子切分,使用传统的jieba切割的颗粒度在词的程度,不能满足训练word2vec模型的需要。(py,手动实现自然也是可以,不过感觉斯,有py社区辣么发达相比有人实现了伐,就没有重复造轮子)
要对文本按句子进行切分,可以使用Python的nltk库,它提供了一个名为sent_tokenize的函数,用于将文本切分为句子。以下是如何实现这个功能的示例:
二、环境配置
1、安装nltk库
pip install nltk
2、下载punkt分句器
如果使用的是nltk的第一次,需要下载punkt资源
下载地址:https://www.nltk.org/nltk_data/
手动下载所需punkt包(运行程序也能下载,不过由于一些网络原因比较难直接下载下来)
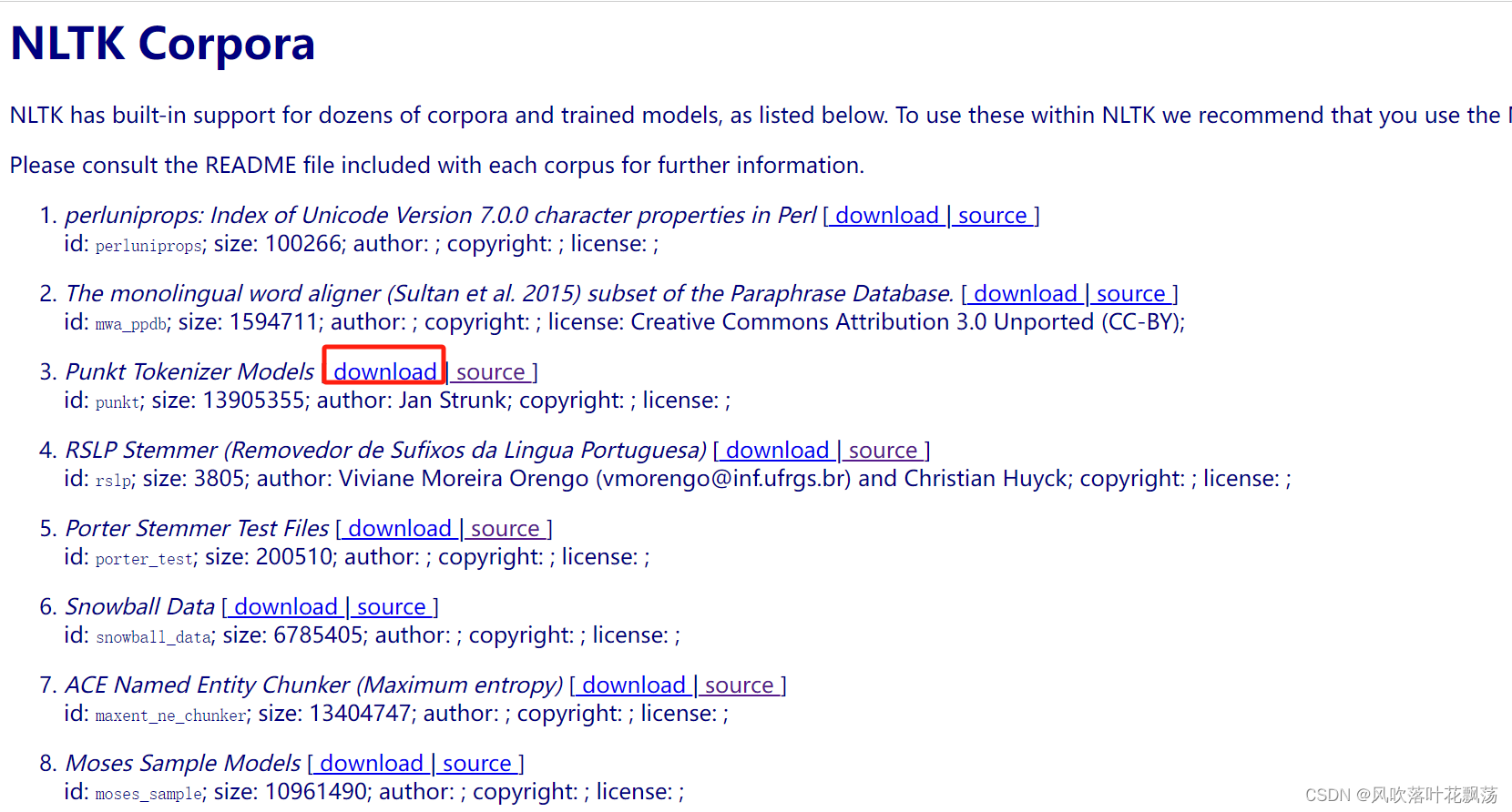
将下载的文件解压放到这个文件夹:C:\Users\Admin\AppData\Roaming\nltk_data\tokenizers
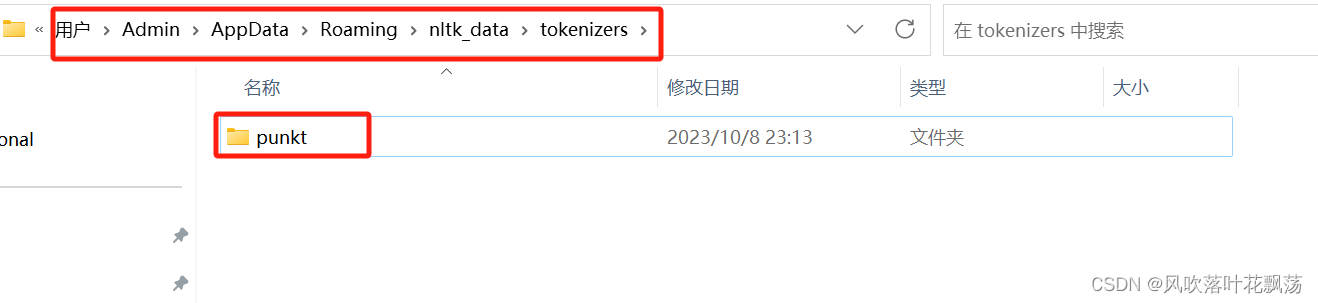
注:如果找不到路径:nltk_data\tokenizers,则手动创建
三、运行程序
使用sent_tokenize函数对文本进行按句切分:
import nltk
from nltk.tokenize import sent_tokenize# 如果使用的是nltk的第一次,需要下载punkt资源
nltk.download('punkt')# 示例文本
text = "This is an example sentence. Here is another one! And what about this one? Let's try it out."# 将文本切分为句子
sentences = sent_tokenize(text)# 输出切分后的句子
for i, sentence in enumerate(sentences):print(f"Sentence {i+1}: {sentence}")
在这个示例中,我们首先从nltk.tokenize模块中导入sent_tokenize函数。然后,我们定义了一个包含多个句子的文本。接下来,我们使用sent_tokenize函数将文本切分为句子,最后输出切分后的句子。
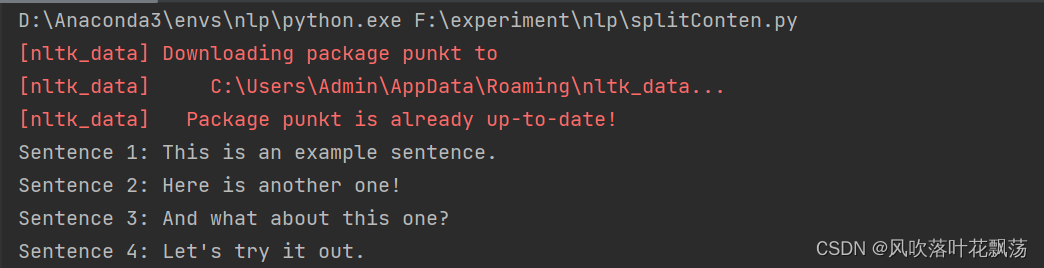
运行参考结果:
sent_tokenize函数使用预训练的Punkt分句器,它能够处理多种语言,并能很好地处理复杂的句子切分。在使用sent_tokenize时,您还可以通过提供一个可选参数language来指定文本的语言,以便更好地适应不同语言的句子切分规则。例如:
sentences = sent_tokenize(text, language='english')
四、额外补充
注:punkt 该库不支持中文,中文分句子比较的是另外一个库:pkuseg
这个库配好环境后下面的就可以直接使用了
import pkuseg# 示例中文文本
text = "这是一个示例句子。这是另一个!这个怎么样?让我们试试看。"# 配置pkuseg
seg = pkuseg.pkuseg()# 将文本切分为句子
sentences = seg.cut(text)# 输出切分后的句子
for i, sentence in enumerate(sentences):print(f"句子 {i + 1}: {sentence}")