背景:
这篇文章是对《LANGUAGE MODELS REPRESENT SPACE AND TIME》论文的翻译加解读。之所以选这篇文章是因为最近在研究大模型的可解释性,以及基于可解释性对大模型的下游任务适配做训练级别可控性增强研究。其实总结成两句话就是:
1.大模型到底学到什么了
2.是否能够在训练时候通过辅助probe来控制训练,增强模型能力
这篇文章正好有部分的回答了上面的两个问题,所以把这篇文章的工作做了翻译、解读。希望能够对这个方向感兴趣的同学有所帮助。
解读
对于LLM模型的工作原理有两个比较大的认识派别:1.随机鹦鹉 2.学会了世界建模。所谓的随机鹦鹉的意思就是LLM模型就跟学人讲话的鹦鹉其实并没有懂人讲的是什么,对人讲的话没有概念认识,只是人高频的喂了这些语料硬性的把人给他的语料重复复述、组合然后发音表达出来。所谓LLM学会世界建模就是说LLM对人类喂给他的语料做了知识、概念的重构,在他的世界里面把知识表达做了归类、知识做了抽象分层;人类给它指令时候,他的回答是对问题做了理解、在他的知识概念空间对知识做了整合表达出来。这篇文章其实就是想验证一下LLM模型是不是把地址信息、时间信息做了概念理解、在LLM知识空间做了合适表示。
这篇文章的主要工作是验证了LLM学会了时间、空间坐标的表征,具体的工作如下:
1.利用世界地区地理信息描述语料训练不同尺度的llama开源模型,然后把不同层的模型参数作为知识表征;把知识表征输入线性神经网络推断这个地名表示的经纬度坐标(这个线性神经网络有经过有监督训练:输入x为llama模型训练好的知识表征,输出Y为地点经纬信息);然后计算实际经纬度值和预测经纬度值差异,看看模型是不是学会了空间位置表征
2.利用美国地区地理信息描述语料训练不同尺度的llama开源模型,然后把不同层的模型参数作为知识表征;把知识表征输入线性神经网络推断这个地名表示的经纬度坐标(这个线性神经网络有经过有监督训练:输入x为llama模型训练好的知识表征,输出Y为地点经纬信息);然后计算实际经纬度值和预测经纬度值差异,看看模型是不是学会了空间位置表征
3.利用近3000年名人、作品信息描述语料训练不同尺度的llama开源模型,然后把不同层的模型参数作为知识表征;把知识表征输入线性神经网络推断这个人/作品名表示出现的时间(这个线性神经网络有经过有监督训练:输入x为llama模型训练好的知识表征,输出Y为时间信息);然后计算实际时间值和预测时间值差异,看看模型是不是学会了空间位置表征
4.并对知识表示的神经网络参数值做了pca分解,验证top的特征(对应就是少数几个神经元)是不是可以完整表示信息,以此证明少数的几个神经元是用来学习地址经纬信息表示、或者时间表示
5.验证了不同LLM的prompt对经纬度、时间特征表示的鲁棒性,以验证LLM是真正学习到了地名对应经纬度、人/作品名对应时间的概念表示,而不是无关上下文让模型得以猜测到准确答案
论文具体工作:
摘要
大型语言模型(LLM)的能力引发了关于这些系统是仅仅学习了一大堆表面统计数据还是一个连贯的数据生成过程模型——世界模型的辩论。通过分析Llama-2系列模型中学到的三个空间数据集(世界、美国、纽约地点)和三个时间数据集(历史人物、艺术作品、新闻标题),我们发现了支持后者观点的证据。我们发现LLMs跨多个尺度学习了空间和时间的线性表示。这些表示对于提示的变化具有鲁棒性,并且在不同的实体类型(例如城市和地标)之间是统一的。此外,我们还确定了个体的“空间神经元”和“时间神经元”,它们可靠地编码了空间和时间坐标。我们的分析表明,现代LLMs获取了关于空间和时间等基本维度的结构化知识,支持了它们不仅仅是学习表面统计数据,而是学习了真正的世界模型的观点。
1 引言
尽管现代大型语言模型(LLMs)被训练用于仅预测下一个标记,但它们展示出了一系列令人印象深刻的能力(Bubeck等人,2023年;Wei等人,2022年),引发了关于这些模型实际上学到了什么的问题和担忧。一个假设是,LLMs学到了大量的相关性,但缺乏对仅通过文本训练的基础数据生成过程的任何一致性模型或“理解”(Bender&Koller,2020;Bisk等人,2020)。另一个假设是,LLMs在压缩数据的过程中,学到了更紧凑、一致且可解释的模型,这些模型描述了训练数据背后的生成过程,即世界模型。例如,Li等人(2022年)已经表明,通过使用下一个标记预测来训练的变压器可以学到玩棋盘游戏奥赛罗的显式表示,而Nanda等人(2023年)随后表明这些表示是线性的。其他人已经显示,LLMs跟踪上下文中主题的布尔状态(Li等人,2021年),并具有反映空间和颜色领域的感知和概念结构的表示(Patel&Pavlick,2021年;Abdou等人,2021年)。更好地理解LLMs是否以及如何对世界建模对于思考当前和未来人工智能系统的鲁棒性、公平性和安全性至关重要(Bender等人,2021年;Weidinger等人,2022年;Bommasani等人,2021年;Hendrycks等人,2023年;Ngo等人,2023年)。
在这项工作中,我们尽可能直接地探讨了LLMs是否形成了世界(和时间)模型的问题——我们试图提取实际的世界地图!具体来说,我们构建了六个包含地点或事件名称以及相应的空间或时间坐标的数据集,这些坐标跨越了多个时空尺度:全球范围内的地点、美国和纽约市内的地点,以及过去3000年历史人物的死亡年份,从1950年代开始的艺术和娱乐作品的发布日期,以及从2010年到2020年的新闻标题的发布日期。使用Llama-2模型家族(Touvron等人,2023年),我们在每一层的名称的内部激活上训练线性回归探针(Alain&Bengio,2016年;Belinkov,2022年),以预测它们在现实世界中的位置或时间。
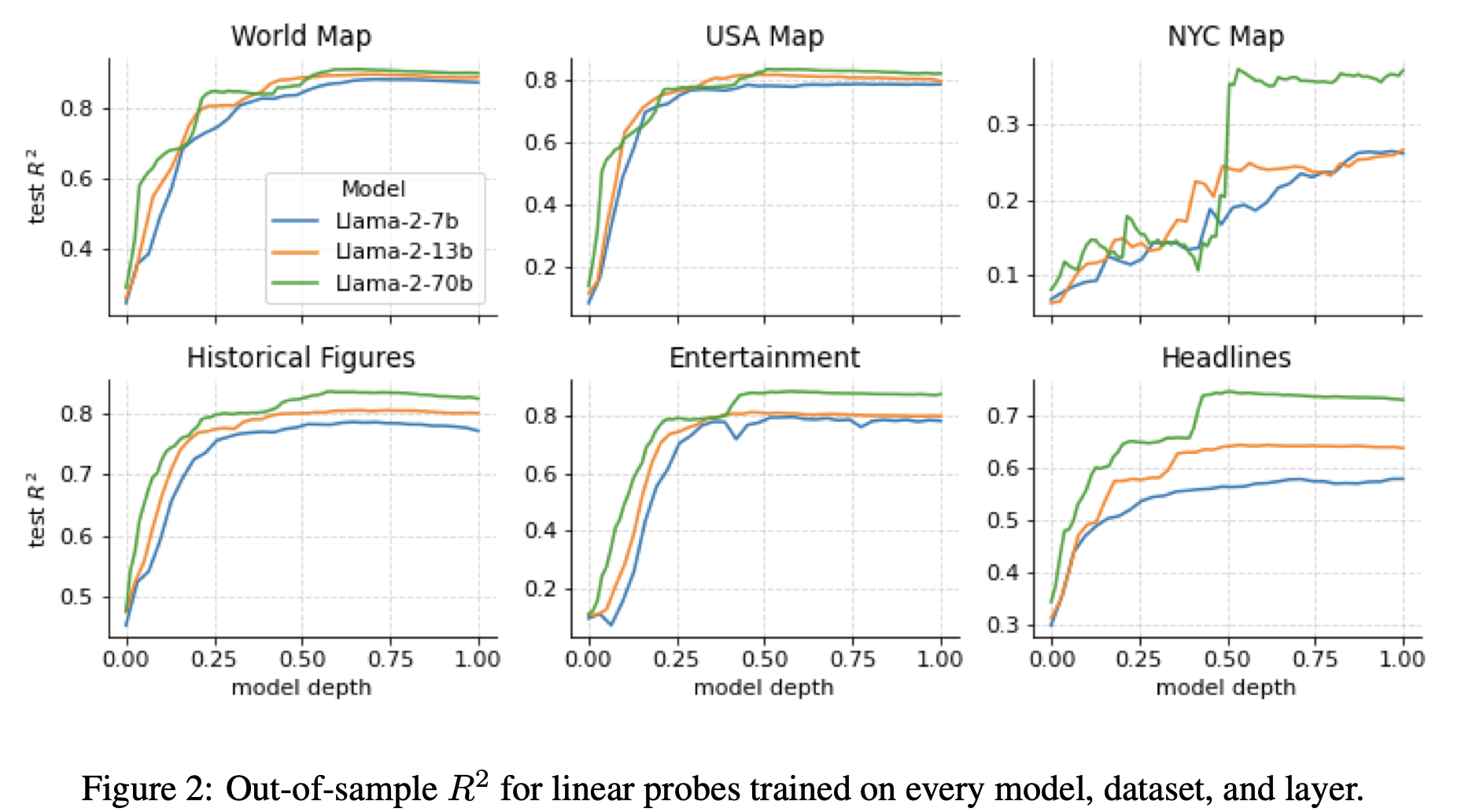
这些探测实验揭示了一个证据,即模型在早期层次之间建立了空间和时间表示,然后在大约模型的中途点达到稳定水平,较大的模型始终优于较小的模型(§ 3.1)。然后,我们展示这些表示是(1)线性的,因为非线性的探针表现不佳(§ 3.2),(2)相对于提示的变化相当鲁棒(§ 3.3),以及(3)统一适用于不同类型的实体(例如城市和自然地标)。
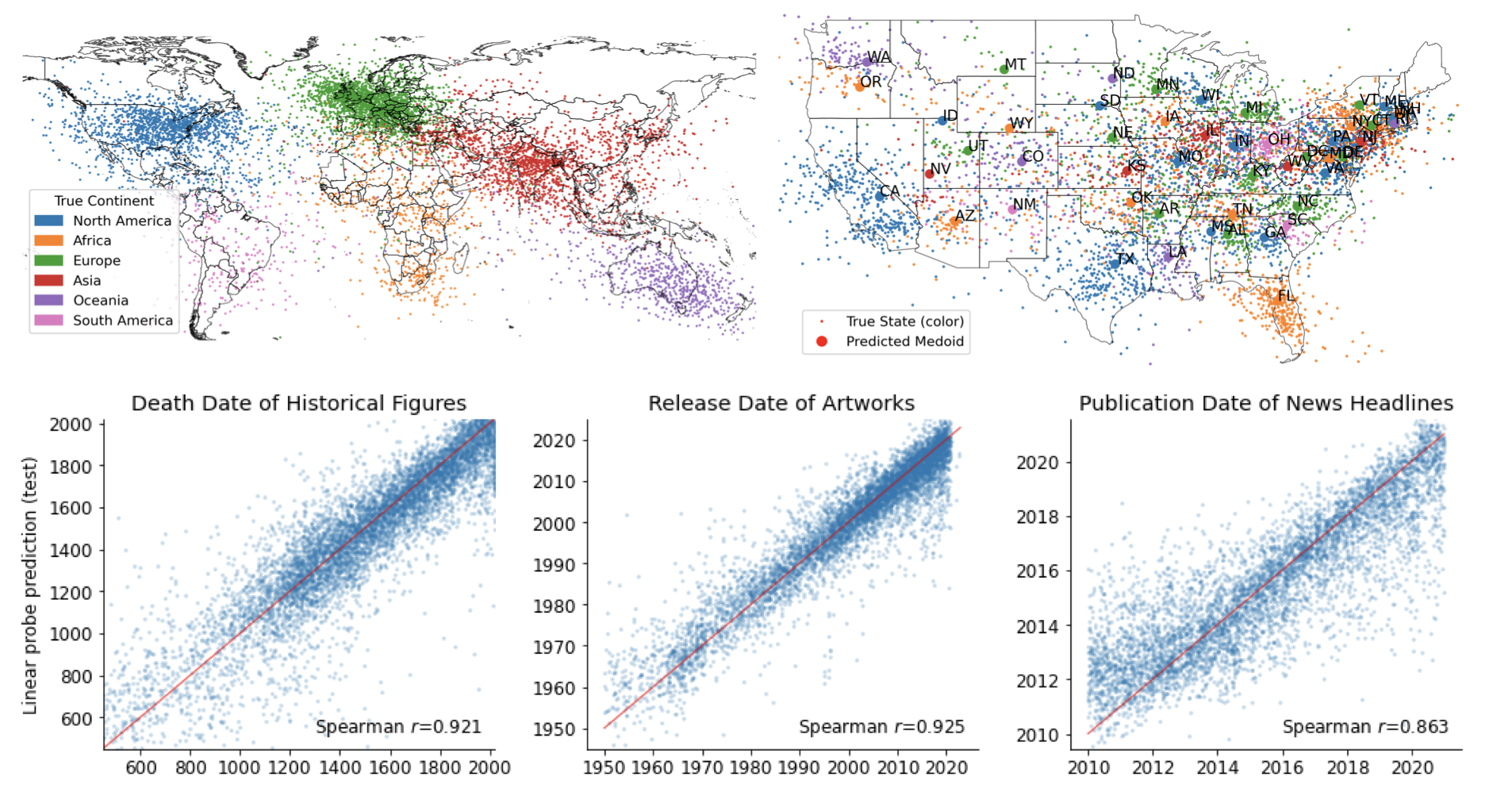
图1:Llama-2-70b的空间和时间世界模型。每个点对应于一个地点(顶部)或事件(底部)的最后一个标记的第50层激活,投影到一个学习到的线性探针方向上。图中的所有点都来自测试集。
我们结果的一个可能解释是,模型只学习了从地点到国家(例如)的映射,实际上是探针学习了这些不同组群在地理空间上(或在时间上)如何相关。为了研究这一点,我们进行了一系列的鲁棒性检查,以了解探针在不同数据分布下的泛化情况(§ 4.1),以及在PCA成分上训练的探针的表现(§ 4.2)。我们的发现表明,探针记忆了这些组群的绝对位置,但模型确实具有反映相对位置的表示。换句话说,探针学习了从模型坐标到人类可解释坐标的映射。最后,我们使用我们的探针来找到个体神经元,这些神经元根据空间或时间的函数被激活,为模型确实使用这些特征提供了有力的证据(§ 5)。
2 实证概述
2.1 空间和时间原始数据集
为了进行我们的调查,我们构建了六个实体名称(人物、地点、事件等)的数据集,每个数据集都具有不同数量级的尺度,并附带它们在位置或时间上的信息。对于每个数据集,我们包括了多种类型的实体,例如城市和湖泊等有人口的地点,以及城市和自然地标等自然地点,以研究不同对象类型之间的统一表示方式。此外,我们保留或丰富相关的元数据,以便使用更详细的细分分析数据,识别训练-测试泄漏的来源,并支持未来关于LLMs内部事实回忆的工作。我们还尝试去重和过滤掉模糊或噪音干扰的数据。
空间:我们构建了三个地点名称的数据集,分别位于世界范围内、美国和纽约市。我们的世界数据集是从DBpedia Lehmann等人(2015年)查询的原始数据构建的。具体而言,我们查询了有人口的地点、自然地点和结构(例如建筑物或基础设施)。然后,我们将这些数据与维基百科文章匹配,并过滤掉在三年内没有至少5,000次页面查看的实体。我们的美国数据集是从DBPedia和人口普查数据聚合器构建的,包括城市、县、邮政编码、学院、自然地点和建筑物的名称,其中稀疏人口或观看不多的地点被类似地过滤掉。最后,我们的纽约市数据集是从纽约市开放数据兴趣点数据集(纽约市开放数据,2023年)中改编的,其中包含了城市内的学校、教堂、交通设施和公共住房等位置。
时间:我们的三个时间数据集包括以下内容:(1)逝世时间介于公元前1000年到公元2000年之间的历史人物的名称和职业,改编自(Annamoradnejad&Annamoradnejad,2022年);(2)从1950年到2020年之间的歌曲、电影和书籍的标题和创作者,使用维基百科页面查看过滤技术从DBpedia构建而来;以及(3)来自写有关当前事件的纽约时报新闻台的2010年至2020年的新闻标题,改编自(Bandy,2021年)。

2.2 模型和方法
数据准备:我们的所有实验都是在基于Llama-2(Touvron等人,2023年)系列的自回归变压器语言模型上运行的,参数范围从70亿到700亿不等。对于每个数据集,我们将每个实体名称通过模型运行,可能在前面加上一个简短的提示,然后保存每一层的最后一个实体标记上的隐藏状态(残差流)的激活。对于一组n个实体,这会产生每一层的一个n×dmodel激活数据集。
探针:为了找到LLMs中的空间和时间表示的证据,我们使用了标准的探测技术(Alain&Bengio,2016年;Belinkov,2022年),该技术在网络激活上拟合一个简单的模型,以预测与标记的输入数据相关的某个目标标签。具体来说,给定一个激活数据集A∈Rn×dmodel,以及包含时间或二维纬度和经度坐标的目标Y,我们拟合线性岭回归探针。
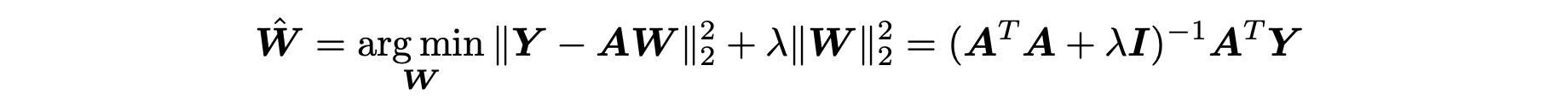
得到一个线性预测器Yˆ = AWˆ。在测试数据上的高预测性能表明基本模型在其表示中具有线性可解码的时间和空间信息,尽管这并不意味着模型实际上使用这些表示(Ravichander等人,2020年)。在所有实验中,我们使用高效的留一法交叉验证(Hastie等人,2009年)来调整λ,用于探针的训练集。
2.3 评估
为了评估我们的探针的性能,我们报告了标准的回归指标,如R2和Spearman秩相关系数,这些指标在我们的测试数据上计算(对于空间特征,经度和纬度的相关性进行了平均处理)。我们计算的另一个指标是每个预测的接近误差,定义为预测中更接近目标点的预测所占的比例,而不是实际预测的误差。直觉是对于空间数据,绝对误差度量可能会误导(对于美国东海岸城市的500公里误差远比西伯利亚的500公里误差重要得多),因此在分析每个预测的误差时,我们经常报告这个指标,以考虑所需精度的局部差异。
3 空间和时间的线性模型
3.1 存在性
我们首先研究以下经验性问题:模型是否完全表示时间和空间?如果是,模型在内部的哪个部分表示?表示质量是否随着模型规模的变化而显著改变?在我们的第一个实验中,我们为每个Llama-2-{7B、13B、70B}的层次以及我们的每个空间和时间数据集训练了探针。我们的主要结果如图2所示,显示了跨数据集的相当一致的模式。特别是,线性探针可以恢复出空间和时间特征,这些表示在模型规模增加时更精确,并且这些表示在模型的前半部分层次中逐渐提高质量,然后达到一个稳定水平。这些观察结果与关于事实回忆文献的结果一致,该文献表明,早期到中期的MLP层负责回忆有关事实主题的信息(Meng等人,2022a;Geva等人,2023年)。
表现最差的数据集是纽约市数据集。这是预期的,因为与其他数据集相比,大多数实体相对较不为人知。然而,这也是最大模型相对表现最佳的数据集,几乎是较小模型的2倍的R2,这表明足够大的LLMs最终可以形成个别城市的详细空间模型。
3.2 线性表示
在可解释性文献中,越来越多的证据支持线性表示假设,即神经网络中的特征是线性表示的,也就是说,可以通过将相关激活投影到某个特征向量上来读取特征的存在或强度(Mikolov等人,2013年;Olah等人,2020年;Elhage等人,2022b年)。然而,这些结果几乎总是针对二元或分类特征,不同于空间或时间的自然连续特征。
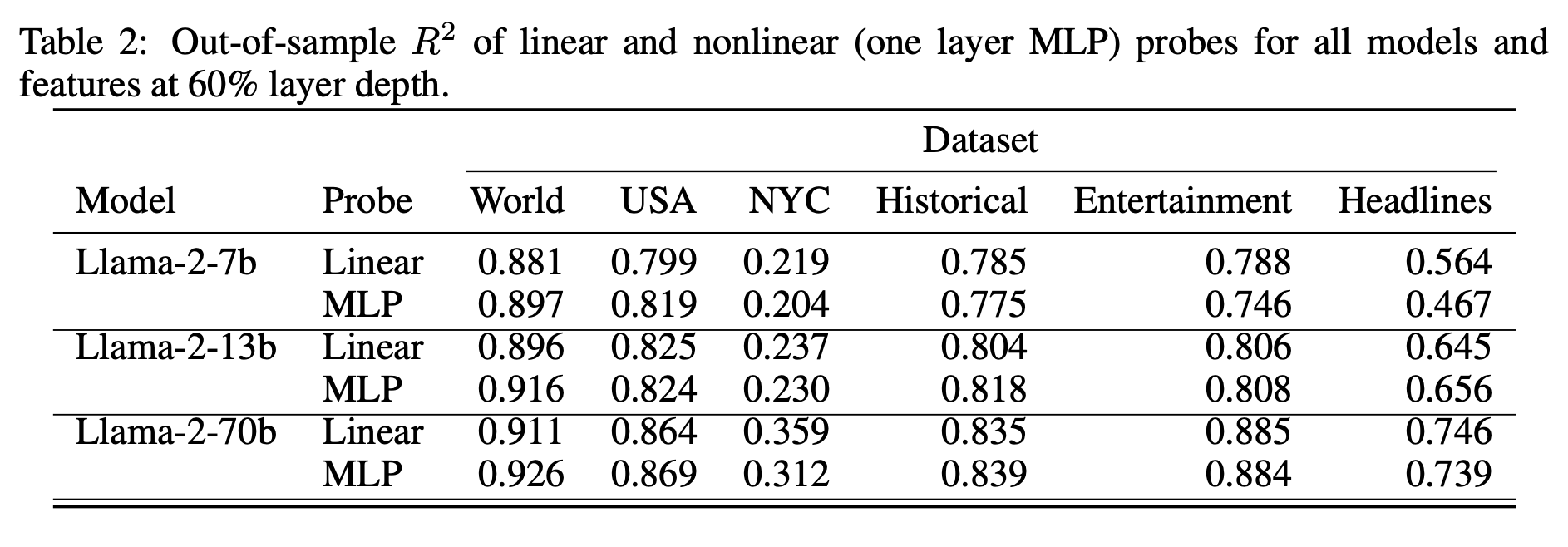
为了测试空间和时间特征是否以线性方式表示,我们将我们的线性岭回归探针与形式为W2ReLU(W1x + b1)+ b2的具有256个神经元的非常更具表现力的非线性MLP探针的性能进行比较。表2报告了我们的结果,并显示使用非线性探针在任何数据集或模型上都只会导致R2的微小提高。我们将这看作是强有力的证据,表明空间和时间也是线性表示的(或至少是线性可解码的),尽管它们是连续的。
3.3 对提示的敏感性
另一个自然的问题是这些空间或时间特征是否对提示敏感,也就是说,上下文是否可以引发或抑制这些事实的回忆?直观地说,对于任何实体标记,自回归模型被激励产生一个适合回答任何未来可能的上下文或问题的表示。
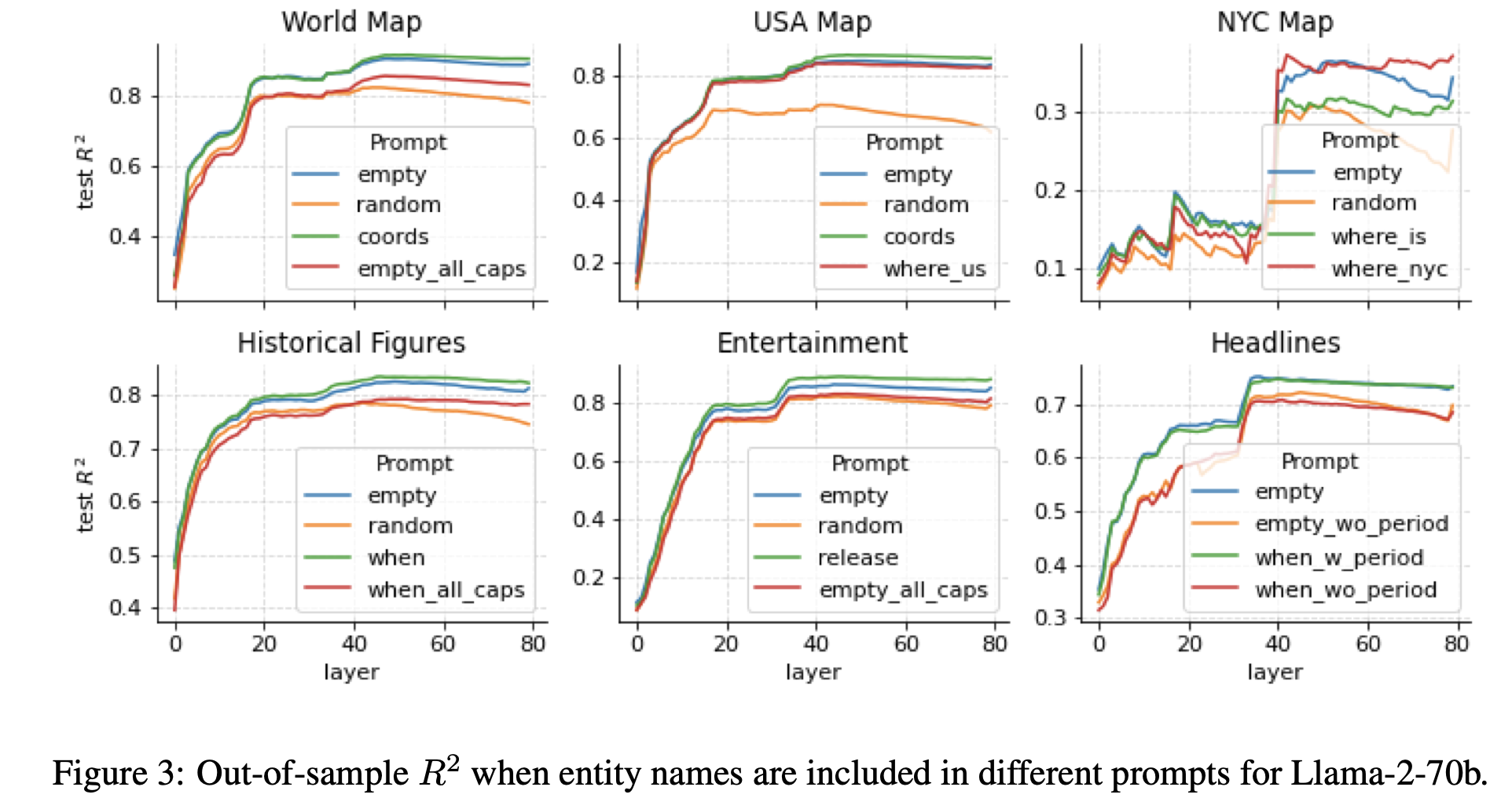
为了研究这一点,我们创建了新的激活数据集,其中我们在每个实体标记之前加上不同的提示,遵循一些基本的主题。在所有情况下,我们包括一个“空”的提示,除了实体标记(和序列开始标记)之外什么都没有。然后,我们包括一个提示,要求模型回忆相关事实,例如,“<地点>的纬度和经度是多少”或“<作者>的<书>的发布日期是什么”。对于美国和纽约市的数据集,我们还包括了这些提示的版本,询问这个地点在美国或纽约市的哪里,以尝试消除常见地点的歧义(例如市政厅)。作为基线,我们包括了10个随机标记的提示(对于每个实体进行了采样)。为了确定我们是否可以混淆主题,对于某些数据集,我们将所有实体的名称完全大写。最后,对于新闻标题数据集,我们尝试在最后一个标记上进行探测,以及在标题后附加了一个句点标记上进行探测。
我们在图3中报告了70B模型的结果,而在图7中报告了所有模型的结果。我们发现,明确提示模型获取信息,或者提供类似于地点在美国或纽约市这样的消歧提示,几乎不会对性能产生影响。然而,我们对随机分散的标记对性能的影响程度感到惊讶。大写实体也会降低性能,尽管程度较轻,这可能干扰了对实体的“解标记”(Elhage等人,2022a;Gurnee等人,2023年;Geva等人,2023年)。唯一明显改善性能的修改是在新闻标题后附加句点标记进行探测,这表明句点用于包含句子结束时的一些摘要信息。
4 鲁棒性检查
前一部分已经显示,可以从LLMs中期到后期的内部激活中线性恢复各种类型的事件或位置的真实时间或空间点。然而,这并不意味着模型实际上如何使用探针学习的特征方向,因为探针本身可能正在学习一些模型实际使用的更简单特征的线性组合。
4.1 通过泛化验证
4.1.1 块保留泛化
为了说明我们的结果可能存在的一个问题,考虑表示完整世界地图的任务。如果模型像我们预期的那样,对于在国家X中的特征几乎正交,那么可以通过对每个国家的这些正交特征向量进行求和,系数等于该国的纬度(经度)来构建高质量的纬度(经度)探针。假设一个地点只属于一个国家,这样的探针会将每个实体放在其国家的质心。然而,在这种情况下,模型实际上并不表示空间,只表示国家成员资格,只有探针从明确的监督中学习了不同国家的几何形状。
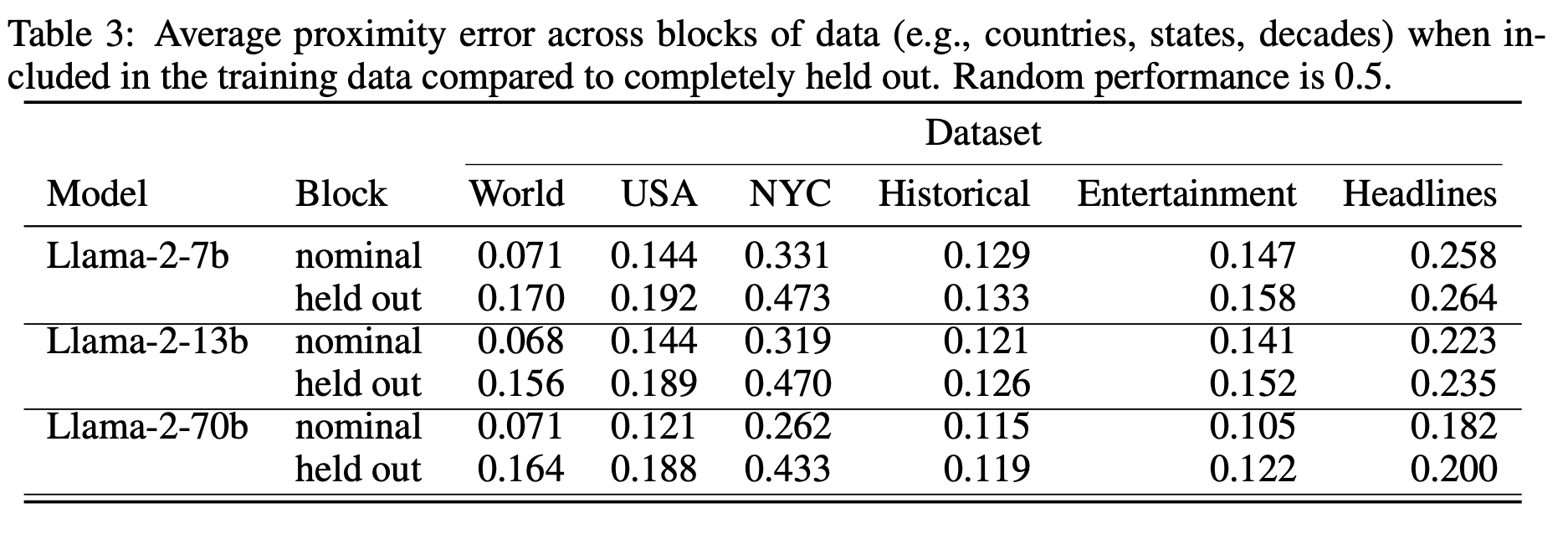
为了更好地区分这些情况,我们分析了在保留特定数据块时探针如何泛化。具体而言,我们训练了一系列的探针,对于每个探针,我们分别保留了世界、美国、纽约市、历史人物、娱乐和新闻标题数据集中的一个国家、州、区、世纪、十年或年份。然后,我们在保留的数据块上评估探针。在表3中,我们报告了完全保留数据块的平均接近误差,与默认的训练-测试拆分中来自该数据块的测试点的误差相比,对所有保留的数据块进行了平均处理。
我们发现,尽管泛化性能有所下降,特别是对于空间数据集,但显然比随机性能要好。通过在图10和11中绘制保留的州或国家的预测结果,可以更清楚地看到一个定性上更清晰的图像。也就是说,探针通过将点放置在正确的相对位置(以真实质心和预测质心之间的夹角来衡量)来正确泛化,但不是在其绝对位置。我们将此视为探针正在提取模型明确学习的特征的微弱证据,但正在记住从模型坐标到人类坐标的转换。然而,这并不能完全排除底层二进制特征的假设,因为可能存在不遵循国家或十年边界的此类特征的层次结构。
4.1.2 跨实体泛化
迄今为止,我们的讨论中隐含的观点是,模型以统一的方式表示不同类型实体(如城市或自然地标)的空间或时间坐标。然而,与纬度探针可能是成员特征的加权和的担忧类似,纬度探针也可能是城市纬度和自然地标纬度的不同(正交)方向之和。
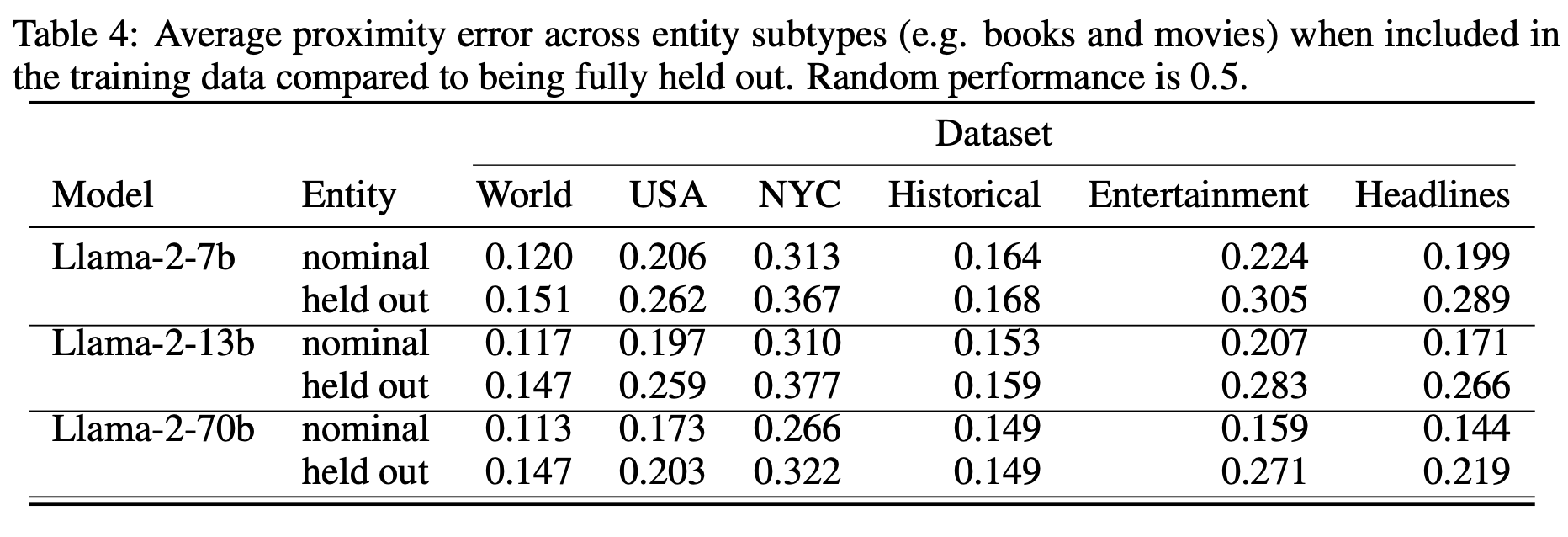
与上述情况类似,我们通过训练一系列的探针来区分这些假设,在这些探针中,训练-测试拆分是为了保留特定实体类别的所有点。表4报告了与默认测试拆分中的实体相比,当保留时的接近误差,与以前一样,对所有这样的拆分进行了平均处理。结果表明,这些探针在实体类型之间主要进行泛化,唯一的例外是娱乐数据集2。
4.2 降维
尽管我们的探针仍然是线性的,但它们仍然具有可学习的dmodel参数(对于7B到70B模型,范围从4096到8192),使其能够进行大量记忆。作为对泛化实验的补充证据,我们使用比完整dmodel维探针少2到3个数量级的参数训练探针,通过将激活数据集投影到其k个最大主成分上。
图4说明了在一系列k值上对每个模型和数据集训练的探针的测试R2,与完整的dmodel维探针的性能进行了比较。我们还在图12中报告了测试Spearman相关性,它随着k的增加比R2更快地增加。值得注意的是,Spearman相关性仅取决于预测的排名顺序,而R2还取决于它们的实际值。我们认为这个差距是进一步证明了模型明确表示空间和时间的证据,因为这些特征必须解释足够的方差,以便在前十几个主成分中,但探针需要更多的参数来将其从模型的坐标系转换为文字空间坐标或时间戳。我们还观察到前几个主成分将数据集中的不同实体类型聚集在一起,解释了为什么需要更多的主成分。

5 空间和时间神经元
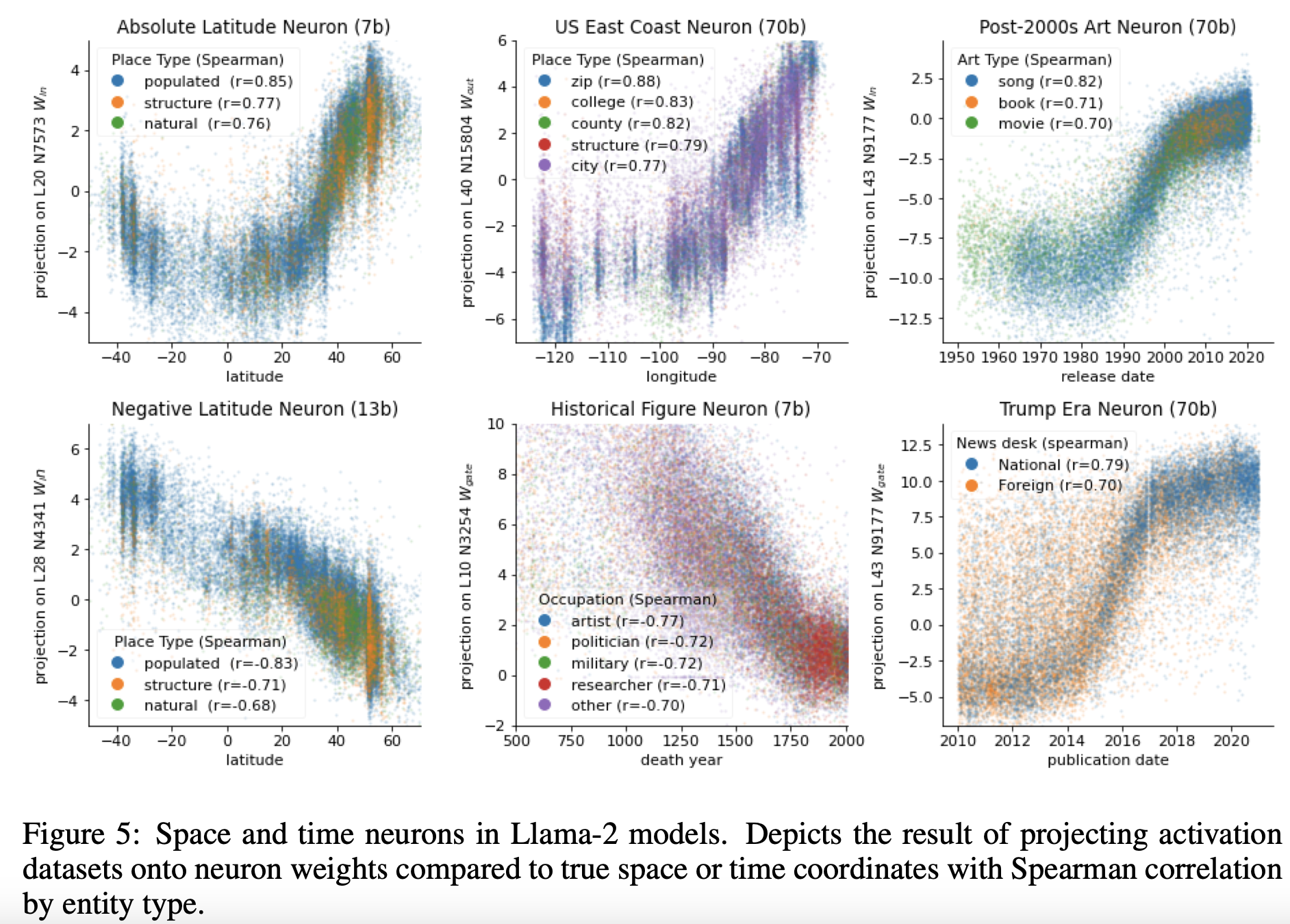
尽管先前的结果具有一定的暗示性,但我们的证据没有直接显示模型使用了探针学习的特征。为了解决这个问题,我们搜索具有与学习的探针方向具有高余弦相似性的输入或输出权重的单个神经元。也就是说,我们寻找那些从或写入与探针学习的方向相似的方向的神经元。
我们发现,当我们将激活数据集投影到最相似神经元的权重上时,这些神经元确实对实体在空间或时间中的真实位置非常敏感(见图5)。换句话说,在模型内部存在一些个别的神经元,它们本身就是相当有预测性的特征探针。而且,这些神经元对我们数据集中的所有实体类型都很敏感,为声称这些表示是统一的提供了更有力的证据。
如果使用明确的监督训练的探针是模型表示这些空间和时间特征程度的近似上限,那么单个神经元的性能就是一个下限。特别是,我们通常希望特征以叠加方式分布(Elhage等人,2022b),这使得单个神经元成为错误的分析级别。尽管如此,这些个别神经元的存在,它们除了来自下一个标记预测的监督之外没有任何监督,是非常有力的证据,表明模型已经学习并利用了空间和时间特征。
6 相关工作
神经世界模型
我们的工作最直接受到先前关于深度学习系统形成可解释模型的研究的启发,这些模型探讨了它们的数据生成过程的程度。最清晰的演示来自于GPT风格的模型,这些模型在国际象棋(Toshniwal等人,2022)和奥赛洛(Li等人,2022)游戏上进行了训练,这些模型被证明具有棋盘和游戏状态的明确表示。随后的奥赛洛工作表明这些表示也是线性的(Nanda等人,2023)。在真正的语言模型中,Li等人(2021)显示,实体的动态属性或关系可以从上下文中不同位置的表示中线性读取出来。Abdou等人(2021)和Patel&Pavlick(2021)显示,大型语言模型具有反映颜色和空间(但不是地理)领域的知觉和概念结构的表示,类似于我们尝试显示表示反映地理结构。与我们的工作最相关的是Konkol等人(2017)和Liétard等人(2021),他们研究了地理在词嵌入或小型语言模型中反映的程度。Liétard等人(2021)得出结论,信息量“有限”,但更大的模型显示出更多地理知识的迹象。通过研究拥有100倍参数和10倍标记数据的模型,我们证实了这一假设。
事实回忆
事件或地点的时间或空间点是一种特殊的事实。我们的调查受到了关于LLMs中事实回忆机制的先前工作的启发(Meng等人,2022a;b; Geva等人,2023),该工作表明,早期到中期的MLP层负责输出关于事实主题的信息,通常位于主题的最后一个标记上。许多这些作品还显示了线性结构,例如在陈述的事实性(Burns等人,2022)或主客体关系的结构(Hernandez等人,2023)。据我们所知,我们的工作在考虑连续事实方面是独一无二的。
可解释性
总的来说,我们的工作借鉴了解释性文献(Ra ̈uker等人,2023)中的许多结果和思想,特别是与探测(Belinkov,2022)、BERTology(Rogers等人,2021)、线性假设和叠加(Elhage等人,2022b)以及机制解释性(Olah等人,2020)相关的主题。与我们的工作相关的更具体的结果包括Hanna等人(2023)发现在年份背景下实现大于的电路,以及Goh等人(2021)发现多模型中对应于地点的神经元,与我们的时间和空间神经元类似。
7 讨论
我们提供了证据表明,大型语言模型(LLMs)学习了关于空间和时间的线性表示,这些表示在不同实体类型之间是统一的,并且对提示具有相当强的鲁棒性,而且存在个别神经元对这些特征非常敏感。因此,下一个令牌预测仅需要足够的模型和数据规模就足以学习出地图世界的字面表示。
我们的分析引发了许多有趣的未来工作问题。虽然我们展示了可以线性重构样本在空间或时间中的绝对位置,以及一些神经元使用了这些探针方向,但空间和时间表示的真实范围和结构仍然不清楚。特别是,我们猜测最常见的结构形式是分层的离散网格,其中任何样本都表示为其在每个粒度级别的最近基础点的线性组合。此外,模型可以并且确实使用这个坐标系统来表示绝对位置,使用正确的基础方向的线性组合,就像线性探测器一样。我们预计,随着模型的扩展,这个网格将增强更多的基础点、更多的粒度级别(例如城市中的街区)和更准确的实体映射到模型坐标(Michaud等人,2023)。
这提出了未来的工作可能是在模型的坐标系中提取表示,而不是尝试重构人类可解释的坐标,也许可以使用稀疏自动编码器(Cunningham等人,2023)等方法。我们分析中的另一个混淆因素,以及更广泛的事实回忆研究,是我们的数据集中存在许多模型不知道的实体,污染了我们的激活数据集。我们会对能够识别模型何时认识到特定实体的方法感兴趣,而不仅仅是提示特定事实并冒险产生幻觉。
我们还只是初步了解了这些空间和时间世界模型如何在内部学习、回忆或使用。通过查看训练检查点,可能有可能定位模型何时将构成部分组织为一致的几何结构,或者得出这个过程是渐进的(Liu等人,2021)。我们预计构建这些表示的模型组件与事实回忆的模型组件类似或相同(Meng等人,2022a; Geva等人,2023)。在初步实验中,我们发现我们的模型在没有依赖多步推理的情况下回答基本的空间和时间关系问题非常困难,这使得任何因果干预分析Wang等人(2022)变得更加复杂,但我们认为这是理解这些特征何时以及如何使用的自然下一步。
最后,我们注意到,关于空间和时间表示的研究在生物神经网络中得到了比人工神经网络更多的关注(Buzsáki&Llinás,2017)。特别是,地点和网格细胞(O'Keefe&Dostrovsky,1971; Hafting等人,2005)是大脑中研究最充分的神经元之一,因此我们期望这将成为未来LLMs研究的有益灵感来源。
A 数据集
我们将更详细地描述我们数据的构建和后处理过程,同时还介绍已知的限制。所有数据集和代码都可以在GitHub - wesg52/world-models: Extracting spatial and temporal world models from LLMs上找到。
世界地点
我们运行了三个单独的查询,以获取DBPedia数据库Lehmann等人(2015)中所有物理地点、自然地点和建筑物的名称、位置、国家和相关的维基百科文章。使用维基百科文章链接,我们将这些信息与维基百科页面浏览统计数据库中的数据连接起来,以查询在2018年至2020年期间该页面被访问了多少次。我们将其用作LLM是否应该了解这个地方的代理,过滤掉在此时间段内少于5000次浏览的地方。
值得强调的是,我们的数据只来自英语维基百科,因此偏向于英语世界。此外,实体类型的分布不均匀,例如,我们注意到英国的火车站比其他任何国家都多,这可能会引入不需要的数据相关性,可能会影响探测器的性能。最后,约25%的样本在末尾带有某种州或省的修饰符,例如“爱荷华州达拉斯县”。由于许多这些地点更加隐晦,或者没有这些修饰符会产生歧义,因此我们选择重新排列字符串,使其形式为“Iowa’s Dallas County”,以使实体得到澄清,但我们不会在常见的国家或州名上进行探测。
美国地点
美国地点数据集使用了世界地点数据集中的结构和自然地点作为起点,此外还使用了美国高校的另一个DBPedia。然后,我们从人口普查数据聚合器中收集每个县4、邮政编码5和城市6的名称、总人口和州。然后,我们删除了所有重复的县或城市名称(美国有31个华盛顿县!),尽管我们保留了任何重复的名称,其人口是同名下一个最大地点的2倍。我们还过滤掉了人口少于500人的城市、人口少于10000(或人口密度大于50且人口大于2000)的邮政编码,以及不位于下连续的48个州(或华盛顿特区)的任何地方。
纽约市地点
我们的纽约市数据集是根据纽约市政府跟踪的兴趣点数据集(NYC OpenData,2023)进行的,其中包含了城市政府跟踪的位置的名称。这包括学校、宗教场所、交通枢纽、重要道路或桥梁、政府建筑、公共住房等地的名称。每个地点都附带有多个这样的建筑物组成的位置的复杂ID(例如纽约大学或拉瓜迪亚机场)。我们构建我们的测试训练拆分,以确保所有在同一复杂中的地点都放在同一拆分中,以避免测试训练泄漏。我们过滤掉了许多描述了围绕纽约市的多个水域的浮标位置。
历史人物
我们的历史人物数据集包含了在公元前1000年至公元2000年之间去世的历史人物的名称和职业,这些信息是从(Annamoradnejad&Annamoradnejad,2022)中提取的。我们将数据集过滤,仅包含每个十年去世的最有名的350位人物,通过其Wikidata实体标识符的索引不完美地衡量。
艺术和娱乐
我们的艺术和娱乐数据集包括歌曲、电影和书籍的名称,以及它们的艺术家、导演和作者的发行日期。我们从DBpedia构建了这个数据集,并类似地过滤了在2018年至2020年期间收到少于5000次页面浏览的实体。由于许多歌曲或书籍具有相当通用的标题,我们在提示中包含创作者的名称以消除歧义(例如,对于空提示,“斯蒂芬·金的《这》”)。但是,由于一些艺术家或作者发布了许多歌曲或书籍,我们按创作者进行测试-训练拆分以避免泄漏。