目录
- 一. 自编码器
- 二. 香草自编码器(vanilla autoencoder)
- 三. 多层自编码器
- 四. 卷积自编码器
- 五. 稀疏自编码器
- 六. 降噪自编码器
一. 自编码器
Auto-Encoder,中文叫作自编码器,是一种无监督式学习模型。它基于反向传播算法与最优化方法(如梯度下降法),利用输入数据X本身作为监督,来指导神经网络尝试学习一个映射关系,从而得到一个重构输出XR。
在时间序列异常检测场景下,异常对于正常来说是少数,所以我们认为,如果使用自编码器重构出来的输出XR跟原始输出的差异超出一定阈值的话,原始时间序列即存在了异常。
神经网络就是一种特殊的自编码器,区别在于自编码器的输出和输入是相同的,是一个自监督的过程,通过训练自编码器,得到每一层中的权重参数,自然地我们就得到了输入x的不同表示(每一层代表一种),这些就是特征。自动编码器就是一种尽可能复现原数据的神经网络。
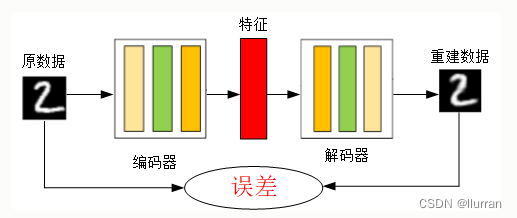
“自编码”是一种数据压缩算法,其中压缩和解压缩过程是有损的。自编码训练过程,不是无监督学习而是自监督学习。
自编码器是一种利用反向传播算法取得使输入值和输出值误差最小的特征。自编码器由两个部分组成:
- 编码器Encoder:将输入值进行特征提取,数据降维;
- 解码器Decoder:将特征还原为原始数据。
编码器的作用是把高维输入X编码成低维的隐变量h,从而强迫神经网络学习最有信息量的特征;
解码器的作用是把隐藏层的隐变量h还原到初始维度,最好的状态就是解码器的输出能完美地或者近似恢复出原来的输入,即XR≈X。
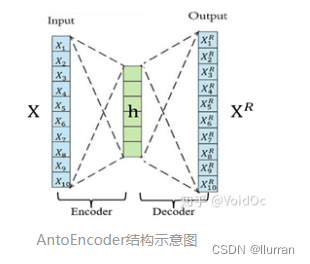
从图1应该已经看出,相比于原数据,重建数据变得模糊了,自编码器是一个有损自监督的过程,但是自编码器的目的不是求得损失函数最小的重建数据,而是求使得误差最小的特征,自编码器的用途主要有:
- 特征提取
- 数据降维
- 数据去噪
自编码器和PCA(主成分分析)有点相似,但是效果超越了PCA。PCA是通过求解特征向量进行降维,是一种线性降维方式,而自编码器是一种非线性降维。
tips:
自编码器只能压缩那些与训练数据类似的数据。
训练好的自编码器只适用于一种编码的数据集。
如果另外一种数据集采用了不同的编码,则这个自编码器不能起到很好的压缩效果。训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。
不同类型的自编码器旨在实现不同类型的属性。
AE算法的优缺点:
优点:泛化性强,无监督不需要数据标注;
缺点:针对异常识别场景,训练数据需要为正常数据。
二. 香草自编码器(vanilla autoencoder)
在这种自编码器的最简单结构中,只有三个网络层,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用Adam优化器和均方误差损失函数,来学习如何重构输入。
在这里,如果隐含层维数(64)小于输入维度(784),则称这个编码器是有损的。通过这个约束,来迫使神经网络来学习数据的压缩表征。
三. 多层自编码器
如果一个隐含层还不够,显然可以将自动编码器的隐含层数目进一步提高。
在这里,实现中使用了3个隐含层,而不是只有一个。任意一个隐含层都可以作为特征表征,但是为了使网络对称,我们使用了最中间的网络层。
四. 卷积自编码器
除了全连接层,自编码器也能应用到卷积层,原理是一样的,但是要使用3D矢量(如图像)而不是展平后的一维矢量。对输入图像进行下采样,以提供较小维度的潜在特征,来迫使自编码器从压缩后的数据进行学习。
五. 稀疏自编码器
一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复现任务可以得到能学习有用特征的模型。
还有一种用来约束自动编码器重构的方法,是对其损失函数施加约束。比如,可以对损失函数添加一个正则化约束,这样能使自编码器学习到数据的稀疏表征。
要注意,在隐含层中,还加入了L1正则化,作为优化阶段中损失函数的惩罚项。与香草自编码器相比,这样操作后的数据表征更为稀疏。
六. 降噪自编码器
这里不是通过对损失函数施加惩罚项,而是通过改变损失函数的重构误差项来学习一些有用信息。
向训练数据加入噪声,并使自编码器学会去除这种噪声,来获得没有被噪声污染过的真实输入。因此,这就迫使编码器学习提取最重要的特征并学习输入数据中更加鲁棒的表征,这也是它的泛化能力比一般编码器强的原因。
这种结构可以通过梯度下降算法来训练。
参考文章:
https://www.cnblogs.com/LXP-Never/p/10921257.html
https://blog.csdn.net/zbzcDZF/article/details/86647125
https://zhuanlan.zhihu.com/p/133207206


![聊聊分布式架构06——[NIO入门]简单的Netty NIO示例](https://img-blog.csdnimg.cn/de39637e3e8a4d5c9bd3b4789af7254f.png)
