目录
- 前言
- 环境准备
- 一、创建虚拟机
- 二、虚拟机网络配置
- 三、克隆虚拟机
- 四、Linux系统配置
- 五、Hadoop的部署配置
- 六、Hadoop集群的启动
前言
大数据课程需要搭建Hadoop分布式集群,在这里记录一下搭建过程
环境准备
搭建Haoop分布式集群所需环境:
- VMware:VMware-workstation-full-17.0.2-21581411
- CentOS:CentOS-7-x86_64-DVD-2003,
- Hadoop:hadoop-3.1.3.tar
- JDK:jdk-8u212-linux-x64.tar.gz
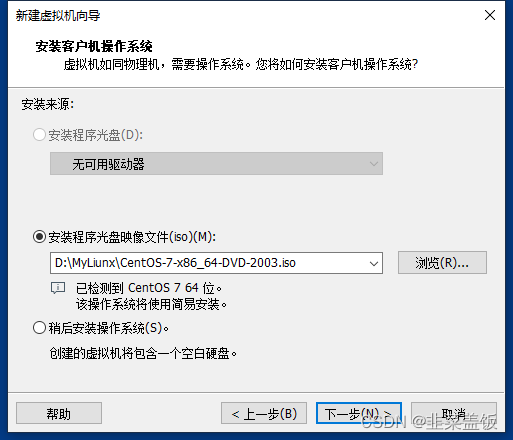
一、创建虚拟机
新建虚拟机
设置用户
命名虚拟机
自定义硬件,完成虚拟机创建
开始启动虚拟机,并安装CentOS
二、虚拟机网络配置
NAT网络模式:
- 宿主机可以看做一个路由器,虚拟机通过宿主机的网络来访问 Internet;
- 可以安装多台虚拟机,组成一个小型局域网,例如:搭建 hadoop 集群、分布式服务。
VMnet8 设置静态 IP
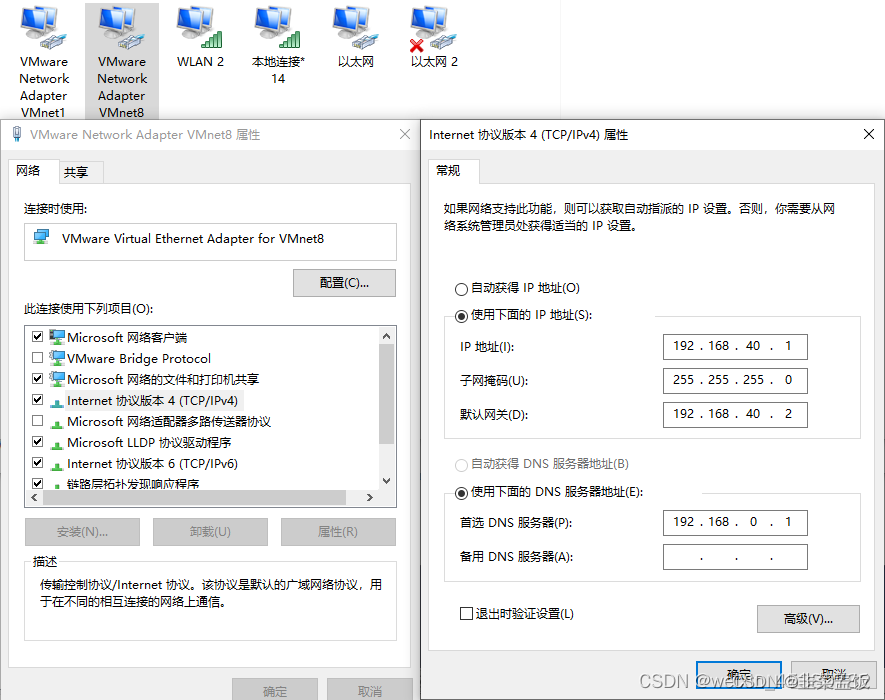
Centos 网络设配器为 NAT 模式
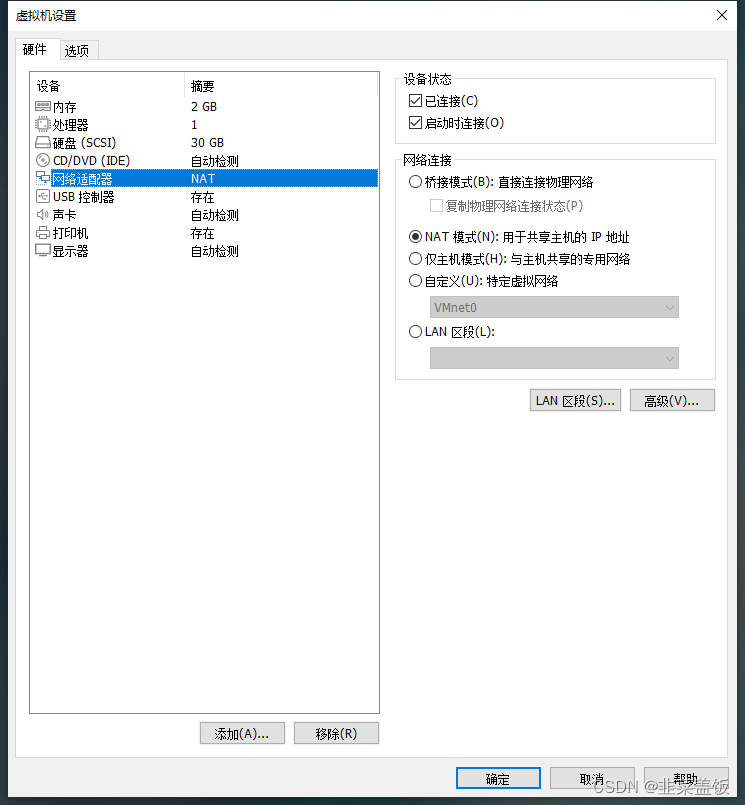
VMware 虚拟网络设置
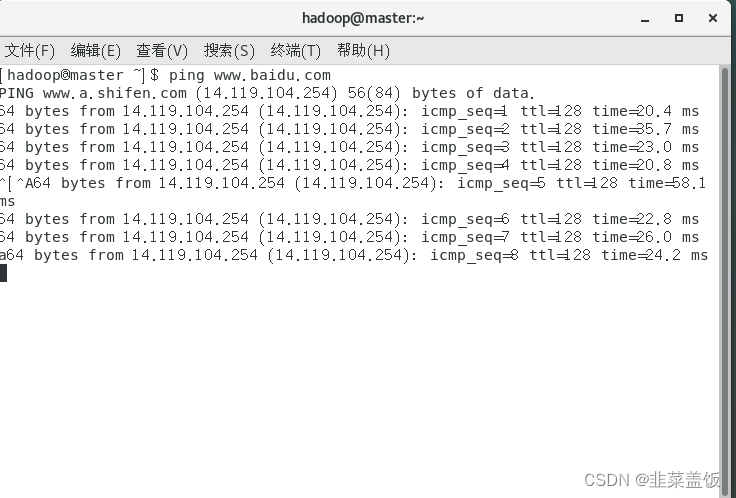
验证结果
因为网络这里一块,老早之前就配置过了,如果觉得不详细,可以参看以下文章:https://blog.csdn.net/ruiqu1650914788/article/details/124973841
三、克隆虚拟机
集群搭建需要至少三台服务器,这里我们再克隆两台虚拟机克HadoopSlave1与HadoopSlave2,
直接无脑下一步,记得修改名称
四、Linux系统配置
1、配置时钟同步
三台虚拟机都需要配置
yum install ntpdate
ntpdate ntp5.aliyun.com2、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service3、配置主机名
三台虚拟机都需要配置
以root用户身份登录HadoopMaster节点,直接使用vim编辑器打开network网络配置文件,命令如下:
vim /etc/sysconfig/network
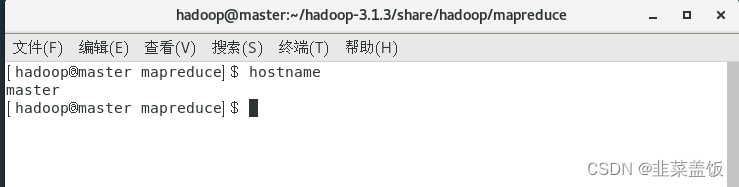
打开network文件,配置信息如下,将HadoopMaster节点的主机名修改为master,即下面第二行代码所示:
NETWORKING=yes #启动网络HOSTNAME=master #主机名
两个子节点分别为:
NETWORKING=yes #启动网络HOSTNAME=slave1 #主机名
NETWORKING=yes #启动网络HOSTNAME=slave2 #主机名
测试
4、 配置Hosts列表
主机列表的作用是让集群中的每台服务器彼此之间都知道对方的主机名和IP地址。因为在Hadoop分布式集群中,各服务器之间会频繁通信,做数据的同步和负载均衡。
以root用户身份登录三个节点,将下面3行代码添加到主机列表/etc/hosts 文件中。
192.168.17.130 master192.168.17.131 slave1192.168.17.132 slave2
ip地址可以使用命令:ip addr查看
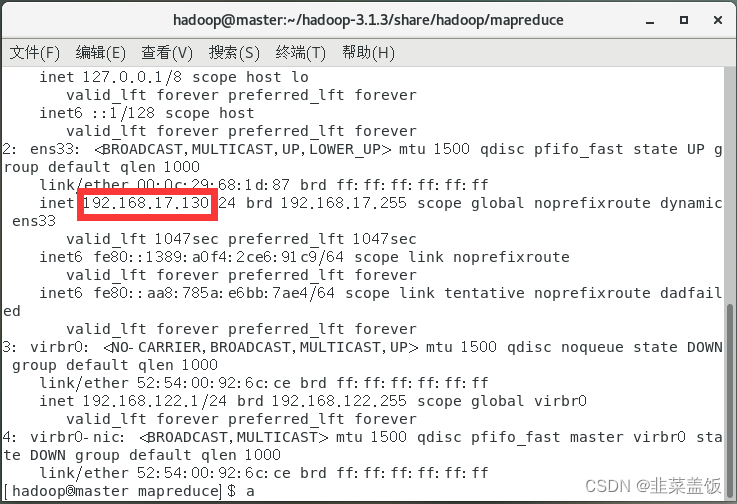
验证主机hosts是否配置成功
ping masterping slave1ping slave2
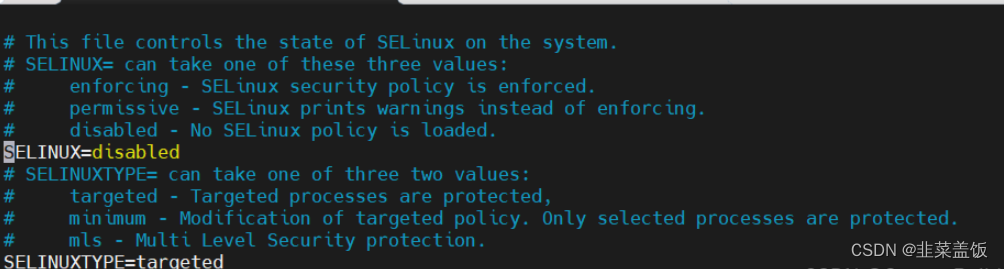
5、关闭selinux
vim /etc/selinux/config
修改为 SELINUX=disabled
6、免密钥登录配置
免密钥登录是指从一台节点通过SSH方式登录另外一台节点时,不用输入该节点的用户名和密码,就可以直接登录进去,对其中的文件内容直接进行操作。没有任何校验和拦截。
从root用户切换到hadoop用户,输入su hadoop,在终端生成密钥,输入以下命令:
ssh-keygen –t rsa
一直回车即可
复制公钥文件到authorized_keys文件中,命令如下:
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
修改authorized_keys文件的权限,只有当前用户hadoop有权限操作authorized_keys文件,命令如下:
chmod 600 /home/hadoop/.ssh/authorized_keys
将HadoopMaster主节点生成的authorized_keys公钥文件复制到HadoopSlave1和HadoopSlave2从节点,命令如下:
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/
如果出现提示,则输入yes并按回车键,输入密码
以hadoop用户身份登录HadoopSlave1、HadoopSlave2节点,进入到/home/hadoop/.ssh目录,修改authorized_keys文件的权限为当前用户可读可写,输入以下命令:
chmod 600 /home/hadoop/.ssh/authorized_keys
在HadoopMaster节点的Terminal终端上输入以下命令验证免密钥登录
ssh slave1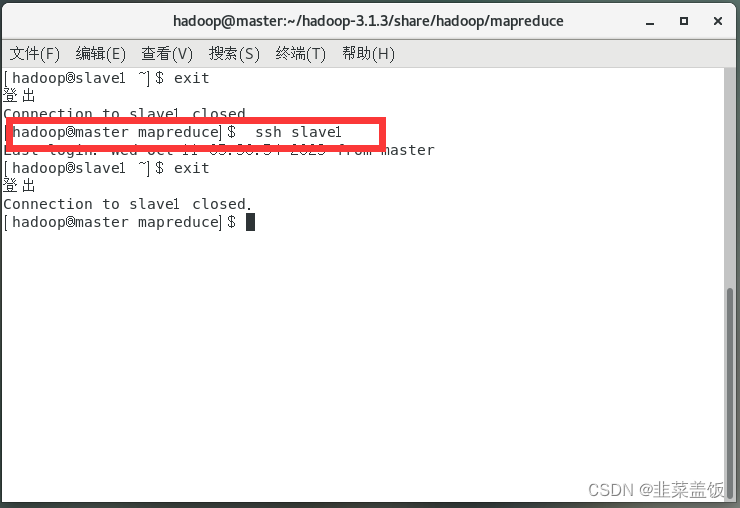
五、Hadoop的部署配置
1、安装JDK
三台虚拟机都需要配置
卸载现有JDK
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
将JDK文件复制到新建的/usr/java 目录下解压,修改用户的系统环境变量文件/etc/profile
tar –zxvf xxx
vi /etc/profile
写入以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_212export JRE_HOME=/usr/java/jdk1.8.0_212/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/libexport PATH=$JRE_HOME/bin:$JAVA_HOME/bin:$PATH使配置生效
source /etc/profile
测试
java -version
2、安装Hadoop
将Hadoop安装文件通过SSH工具上传到HadoopMaster节点hadoop用户的主目录下。进入hadoop用户主目录,输入以下命令进行解压:
tar –zxvf hadoop-3.1.3.tar.gz
3、配置环境变量hadoop-env.sh
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
在文件靠前的部分找到以下代码(没有就自己添加):
export JAVA_HOME=${JAVA_HOME}
将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_212
保存文件,此时Hadoop具备了运行时的环境。
4、配置环境变量yarn-env.sh
YARN主要负责管理Hadoop集群的资源。这个模块也是用Java语言开发出来的,所以也要配置其运行时的环境变量JDK。
打开Hadoop的YARN模块的环境变量文件yarn-env.sh,只需要配置JDK的路径。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/yarn-env.sh
#export JAVA_HOME
将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_212
5、配置核心组件core-site.xml
Hadoop集群的核心配置,是关于集群中分布式文件系统的入口地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置。
分布式文件系统(Hadoop Distributed FileSystem,HDFS)是集群中分布式存储文件的核心系统,将在后面章节详细介绍,其入口地址决定了Hadoop集群架构的主节点,其值为hdfs://master:9000,协议为hdfs,主机为master,即HadoopMaster节点,端口号为9000。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/core-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入:
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoopdata</value></property></configuration>
HDFS文件系统数据落地到本地磁盘的路径信息/home/hadoop/hadoopdata,该目录需要单独创建。
在三个虚拟机上的目录/home/hadoop下创建目录hadoopdata
mkdir hadoopdata
6、 配置文件系统hdfs-site.xml
在分布式的文件系统中,由于集群规模很大,所以集群中会频繁出现节点宕机的问题。分布式的文件系统中,可通过数据块副本冗余的方式来保证数据的安全性,即对于同一块数据,会在HadoopSlave1和HadoopSlave2节点上各保存一份。这样,即使HadoopSlave1节点宕机导致数据块副本丢失,HadoopSlave2节点上的数据块副本还在,就不会造成数据的丢失。
配置文件hdfs-site.xml有一个属性,就是用来配置数据块副本个数的。在生产环境中,配置数是3,也就是同一份数据会在分布式文件系统中保存3份,即它的冗余度为3。也就是说,至少需要3台从节点来存储这3份数据块副本。在Hadoop集群中,主节点是不存储数据副本的,数据的副本都存储在从节点上,由于现在集群的规模是3台服务器,其中从节点只有两台,所以这里只能配置成1或者2。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
在<!-- Put site-specific property overrides in this file. --> 下方,输入:
<configuration><property><!--配置数据块的副因子(即副本数)为2--><name>dfs.replication</name><value>2</value></property></configuration>
7、 配置YARN资源系统yarn-site.xml
YARN的全称是Yet Another Resource Negotiator,即另一种资源协调者,运行在主节点上的守护进程是ResourceManager,负责整个集群资源的管理协调;运行在从节点上的守护进程是NodeManager,负责从节点本地的资源管理协调。
YARN的基本工作原理:每隔3秒,NodeManager就会把它自己管理的本地服务器上的资源使用情况以数据包的形式发送给主节点上的守护进程ResourceManager,这样,ResourceManager就可以随时知道所有从节点上的资源使用情况,这个机制叫“心跳”。当“心跳”回来的时候,ResourceManager就会根据各个从节点资源的使用情况,把相应的任务分配下去。“心跳”回来时,携带了ResourceManager分配给各个从节点的任务信息,从节点NodeManager就会处理主节点ResourceManager分配下来的任务。客户端向整个集群发起具体的计算任务,ResourceManager是接受和处理客户端请求的入口。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/yarn-site.xml
在<!-- Site specific YARN configuration properties -->下方,输入:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:18040</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:18030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:18025</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:18141</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:18088</value>
</property>
8、 配置计算框架mapred-site.xml
YARN主要负责分布式集群的资源管理,将Hadoop MapReduce分布式并行计算框架在运行中所需要的内存、CPU等资源交给YARN来协调和分配,通过对mapred-site.xml配置文件的修改来完成这个配置。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/mapred-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入:
<configuration><!—MapReduce计算框架的资源交给YARN来管理--><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
在这里可能出现以下Bug
处理方式:
先运行shell命令:hadoop classpath
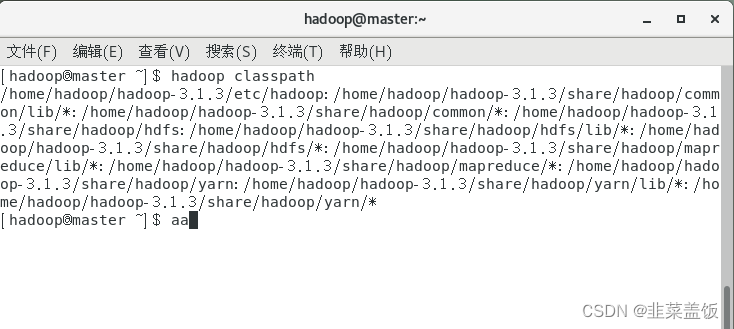
在mapred-site.xml添加以下配置
<property><name>yarn.application.classpath</name><value>hadoop classpath返回的信息</value>
</property>9、复制hadoop到从节点
主节点的角色HadoopMaster已在配置HDFS分布式文件系统的入口地址时进行了配置说明,从节点的角色也需要配置,此时,workers文件就是用来配置Hadoop集群中各个从节点角色。
打开workers配置文件。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/workers
用下面的内容替换workers文件中的内容:
slave1slave2
在Hadoop集群中,每个节点上的配置和安装的应用都是一样的,这是分布式集群的特性,所以,此时已经在HadoopMaster节点上安装了Hadoop-3.1.3的应用,只需要将此应用复制到各个从节点(即HadoopSlave1节点和HadoopSlave2节点)即可将主节点的hadoop复制到从节点上。
scp –r /home/hadoop/hadoop-3.1.3 hadoop@slave1:~/scp –r /home/hadoop/hadoop-3.1.3 hadoop@slave2:~/
10、配置Hadoop启动的系统环境变量
和JDK的配置环境变量一样,也要配置一个Hadoop集群的启动环境变量PATH。
此配置需要同时在三台虚拟机上进行操作,操作命令如下:
vi /etc/profile
将下面的代码追加到文件的末尾:
#Hadoop Path configurationexport HADOOP_HOME=/home/hadoop/hadoop-2.5.2export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
输入:wq保存退出,并执行生效命令:
source /etc/profile
登录HadoopSlave1和HadoopSlave2节点,依照上述配置方法,配置Hadoop启动环境变量。
这里存在一个问题:CentOS 7 每次进入要重新加载环境变量
解决方式:
进入系统配置文件
vim ~/.bashrc
末尾添加如下代码
source /etc/profile
保存即可
六、Hadoop集群的启动
启动集群时,首先要做的就是在HadoopMaster节点上格式化分布式文件系统HDFS:
hadoop namenode -format
启动Hadoop
cd /home/hadoop/hadoop-3.1.3
sbin/start-all.sh
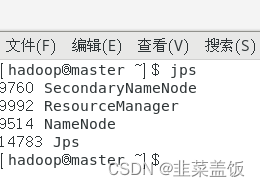
查看进程是否启动
在HadoopMaster的Terminal终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode。
在HadoopSlave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps。
注意:jps是JDK的命令,如果没有该命令,请检查JDK是否配置正确
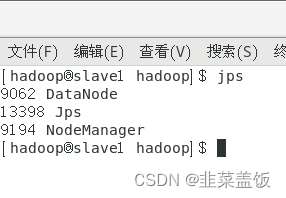
如果子节点不存在DataNode,参考以下文章:https://blog.csdn.net/m0_61232019/article/details/129324464
也可以删除hadoopdata目录里面的内容重新启动Hadoop来解决
检查NameNode和DataNode是否正常
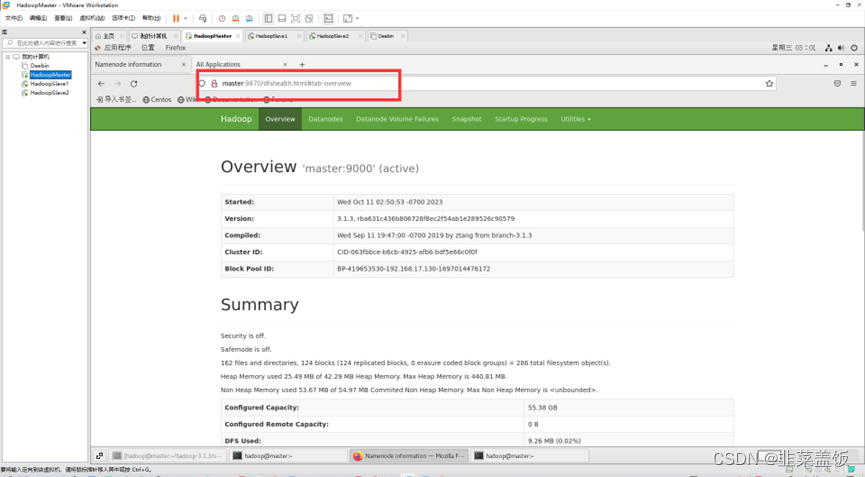
检查YARN是否正常
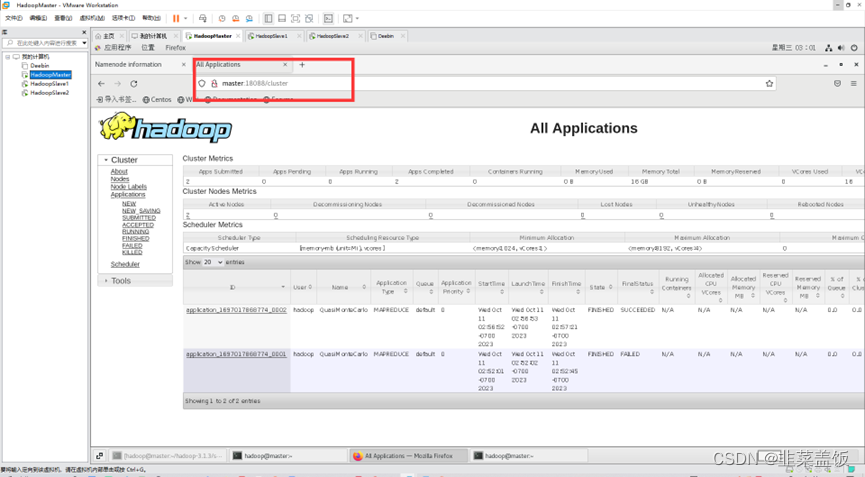
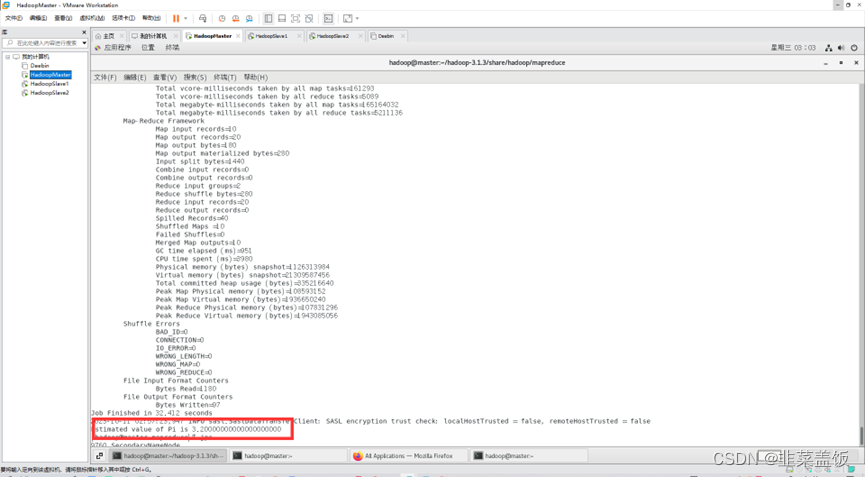
运行PI实例检查集群是否启动成功