目录
- 黑马旅游案例
- 分页查询
- 自动补全
- 安装依赖
- 自定义分词器
- Completion Suggester
- 聚合数据
- 聚合的分类
- Bucket 聚合
- Metrix 聚合
- RestClient 实现聚合
- suggest 查询结果
- 数据同步
- 同步策略
- mq 同步 es
- es 搭设集群
黑马旅游案例
分页查询
前端页面以及对应请求接口已经设置完备,我们仅需据此添加对应的后端内容即可
首先设置请求接收的实体类
@Data
public class RequestParams {private String key;private Integer page;private Integer size;private String sortBy;
}
紧接着是返回给前端的响应类(字段名必须要和前端一致,否则你传递给前端的内容他不认)
@Data
public class PageResult {private Long total;private List<HotelDoc> hotels;public PageResult() {}public PageResult(Long total, List<HotelDoc> hotels) {this.total = total;this.hotels = hotels;}
}
新增查询的 controller
@RestController
@RequestMapping("/hotel")
public class HotelController {@Autowiredprivate IHotelService hotelService;@PostMapping("/list")PageResult search(@RequestBody RequestParams params) {return hotelService.search(params);}
}
在对应的 service 中实现具体操作
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowiredprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {SearchRequest request = new SearchRequest("hotel");// 判断请求是否包含指定params,以此来选择查询方式String key = params.getKey();if (key == null || "".equals(key)) {request.source().query(QueryBuilders.matchAllQuery());} else {request.source().query(QueryBuilders.matchQuery("all", key));}// 分页Integer page = params.getPage(), size = params.getSize();request.source().from((page - 1) * size).size(size);SearchResponse response = client.search(request, RequestOptions.DEFAULT);return logResp(response);} catch (IOException e) {throw new RuntimeException();}}// 此方法将包装从es中查询到的所有文档到对象PageResult内,然后作为响应返回前端private PageResult logResp(SearchResponse response) {SearchHits searchHits = response.getHits();SearchHit[] hits = searchHits.getHits();System.out.println(searchHits.getTotalHits().value + "条数据");List<HotelDoc> hotelDocs = new ArrayList<>();for (SearchHit hit : hits) {String source = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);hotelDocs.add(hotelDoc);}return new PageResult(searchHits.getTotalHits().value, hotelDocs);}
}
自动补全
我们在搜索东西的时候经常会看见每输入一个词就会联想出很多相关内容,我们使用 pinyin 分词器进行分词操作来实现这个功能
安装依赖
es 的分词器包括三个部分:
character filters对文本简单处理,如删除替换字符tokenizer将文本按照一定规则切割为词条tokenizer filter将 tokenizer 的结果进一步细化处理,如大小写转换和同义词处理
其中,ik 分词器处理 tokenizer ,而 pinyin 分词器处理 tokenizer filter
下载 pinyin 分词器,安装步骤略:下载地址
自定义分词器
配置自定义的分词器,分词器的名称叫做 my_analyzer
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name":{"type": "text","analyzer": "my_analyzer"}}}
}
然后执行测试,看看我们的分词器运作效果如何
POST /test/_analyze
{"text": ["如家酒店真不戳"],"analyzer": "my_analyzer"
}
Completion Suggester
在创建倒排索引时:使用自定义分词器,同时对汉语分词并分出拼音
用户搜索时:直接使用 ik_smart 分词器
Completion Suggester 特性:
- Completion Suggester 是一种用于自动补全和建议功能的高级功能。它可以根据用户输入的部分词项提供匹配的建议结果。
- Completion Suggester 字段类型使用特定的数据结构来存储建议的文本。它使用了倒排索引和有限状态自动机(FSA)来提供高效的建议查询。
- Completion Suggester 查询的结果将包含一个 suggest 部分,其中包含与查询匹配的建议结果。每个建议结果都包含一个 options 数组,其中包含建议的文本和其他相关信息。
这里提供一个示例,示例内容是:创建索引myindex,并向其中插入三个随机数据,并使用 Completion Suggester 对字段title进行查询。
- 创建索引
myindex并定义字段映射:
title的字段,其类型为completion是为了进行 suggester 查询所用的!
PUT /myindex
{"mappings": {"properties": {"title": {"type": "completion"}}}
}
- 向索引
myindex插入三个随机数据:
POST /myindex/_doc/1
{"title": {"input": ["Apple", "iPhone"]}
}POST /myindex/_doc/2
{"title": {"input": ["Samsung", "Galaxy"]}
}POST /myindex/_doc/3
{"title": {"input": ["Google", "Pixel"]}
}
上述操作将三个文档插入到索引myindex中,每个文档包含一个title字段,其中input数组定义了建议的文本。
- 使用 Completion Suggester 进行查询:
GET /myindex/_search
{"suggest": {"suggestion": { // Completion Suggester的名称,可以自定义"prefix": "i", // 指定以字母"i"开头的前缀"completion": {"field": "title", // 指定要执行建议查询的字段为"title""size": 10 // 指定返回的建议结果数量,这里设置为10}}}
}
上述查询使用 Completion Suggester 在字段title中搜索以字母"i"开头的建议文本
执行查询后,你将获得与查询匹配的建议结果,类似于以下示例响应:
{"suggest": {"suggestion": [{"text": "i","offset": 0,"length": 1,"options": [{"text": "iPhone","score": 1.0}]}]}
}
聚合数据
聚合的分类
聚合可以划分为三类

Bucket 聚合
使用 aggs 字段进行聚合查询,聚合查询的桶里面默认存在一个字段“_count”,用于表示寻找到的相同的数据量
// GET请求示例,执行聚合查询
GET /hotel/_search
{"size": 0, // 设置搜索结果的大小为0,只返回聚合结果"aggs": {"brandAgg": {// 聚合名称为brandAgg"terms": {"field": "brand", // 根据brand字段进行分组"order": {"_count": "asc" // 按照聚合桶中文档数量的升序排序},"size": 20 // 返回前20个分组}}}
}
同样的,额外添加一个 query 字段,让我们将待查询的索引限定到一定范围内
这样可以避免查询全部索引的内存占用问题
GET /hotel/_search
{// 只对价格200及以下的酒店进行统计"query": {"range": {"price": {"lte": 200}}},"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc"},"size": 20}}}
}
Metrix 聚合
聚合里面再写一个聚合,相当于子聚合,子聚合的定义方式和普通聚合一致
stats 用于统计指定字段的 min、max、avg 等基本数据
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}
RestClient 实现聚合
@Test
void testAgg() throws IOException {// 这一块执行聚合查询SearchRequest request = new SearchRequest("hotel");request.source().size(0);request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));// 这一段取出聚合查询的结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);Aggregations aggregations = response.getAggregations();Terms brandAgg = aggregations.get("brandAgg");List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();for (Terms.Bucket bucket : buckets) {String keyAsString = bucket.getKeyAsString();System.out.println(keyAsString);}
}
suggest 查询结果
编写查询方法 suggestion,下图对应了查询方法及其 java 写法

查询完了自然要解析返回的 json

前端实现自动补全的效果流程:
- 检测用户在搜索框输入内容变化,使用 get 请求发送,params 为当前输入框内容
- 后端接收 get 请求,解析 requestparams,获取输入框内容
- 将内容使用 suggestion 发给 es,es 解析返回结果后再由后端解析
- 查询得到的 list 返回前端,完成!
数据同步
同步策略
当修改 mysql 后,es 内容仍未变化,需使用对应同步策略使 es 同步更新数据
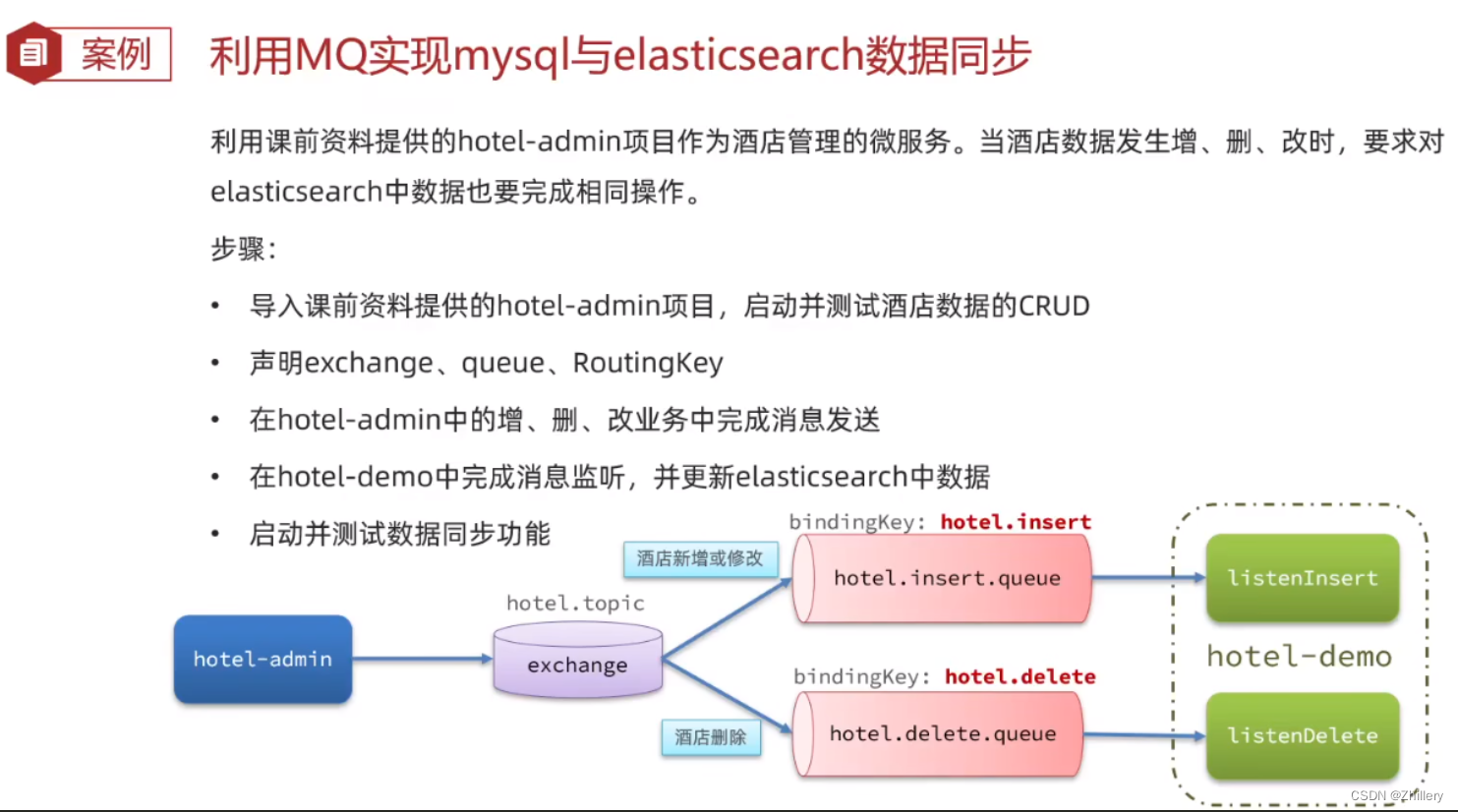
同步调用策略:酒店管理服务先修改 mysql,再调用接口来让酒店搜索服务修改 es(简单粗暴,耦合度较高)
异步通知策略:酒店管理服务修改 mysql 后,把修改 es 的请求发送到 mq,酒店搜索服务依次处理 mq 中的更改请求(低耦合,易实现,依赖 mq)
监听 binlog 策略:略去了酒店管理服务发送请求的过程,而是由 mq 直接监听 mysql 改变从而对应通知酒店搜索服务做出改变(完全解耦,但开启 binlog 会增加数据库负担)

mq 同步 es
es 搭设集群
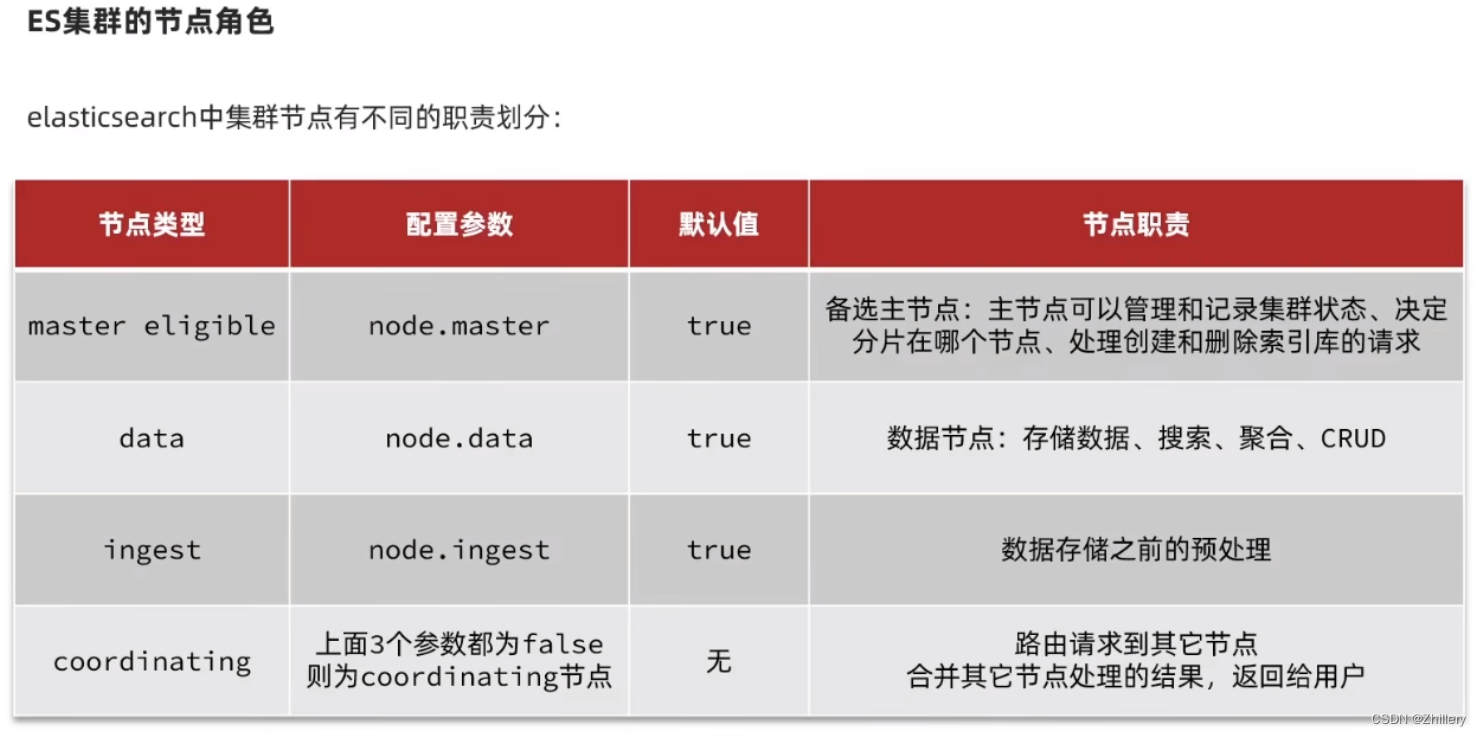
ES 主从结构通常会发生所谓的脑裂问题:指由于网络分区或其他故障导致集群中的节点无法相互通信,从而导致集群中形成多个独立的子集群。这可能会导致数据不一致和操作冲突(说人话就是会产生多个 master)
配置文件解决法:在 Elasticsearch 的配置文件中,可以设置 discovery.zen.minimum_master_nodes 参数来指定在集群中需要的最小主节点数目。这可以帮助防止脑裂情况下的自动选举多个主节点。建议将此参数设置为集群中主节点数目的一半加一
(es7 及以上版本已经自动设置了此属性,故一般无脑裂问题发生)
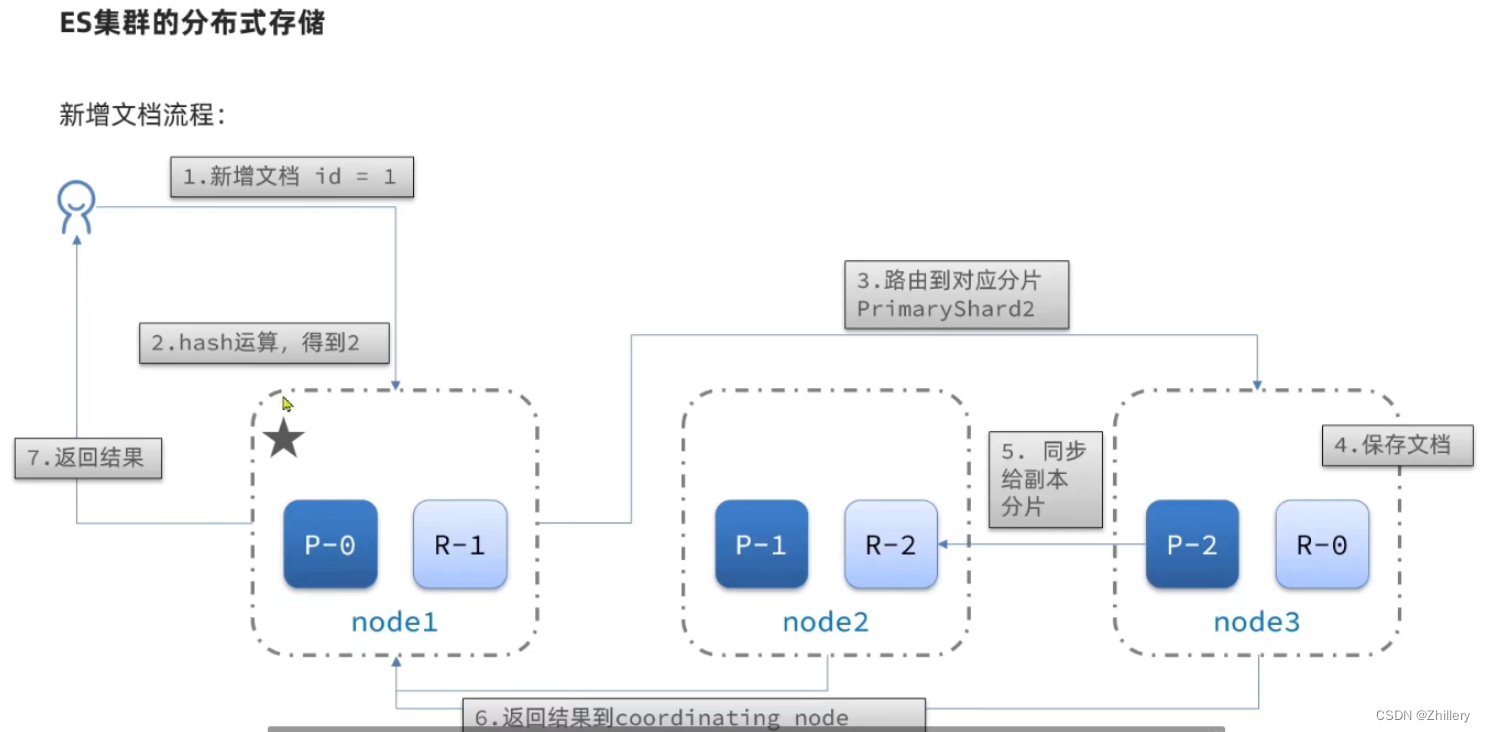
es 分片原理
es 会通过 hash 算法决定当前的文档应该存储到哪一个分片上去
由于 hash 算法和 es 分片数量有关,所以一旦索引库创建,分片数量就不可变
shard = hash(_routing) & number_of_shards
es 分片查询流程
- scatter phase 分散阶段:hash 算法算出每一个文档应该去往的分片,由 coordinating node 执行分发
- gather phase 聚集阶段:coordinating node 汇集每一个分片返回的结果,返回给用户
es 故障转移
集群的 master 节点侦测到某个节点宕机,就会立即将其分片数据复制到其他节点,这就是故障转移技术