分布式系统开发技术中的CAP定理原理
在分布式系统开发中,CAP定理(一致性、可用性和分区容忍性)是指导我们设计、开发和维护系统的核心原理。该定理阐述了分布式系统中一致性、可用性和扩展性之间无法同时满足的矛盾关系,为我们提供了在分布式环境下进行系统设计和优化时的理论指导。
分布式系统基础
分布式系统是由多个节点组成的,这些节点通过网络互连协同工作,共同提供某种服务或完成某种计算任务。在分布式系统中,节点可以位于不同的物理位置,通过网络通信进行信息交互。
节点
节点是分布式系统的基本单元,每个节点都具有独立的处理能力和存储能力,可以执行特定的任务或服务。节点之间通过网络互连,协同完成分布式任务。
服务
服务是分布式系统的核心,指节点之间通过通信和协作提供的一种功能或能力。例如,数据存储、数据处理、信息检索等。服务的设计和实现是分布式系统的关键。
数据
数据是分布式系统的基础,也是最重要的资源之一。在分布式系统中,数据被分散到不同的节点上存储和管理,以保证数据的可用性和扩展性。同时,由于节点的分散性,数据的一致性也成为分布式系统需要解决的重要问题之一。
CAP定理原理分析
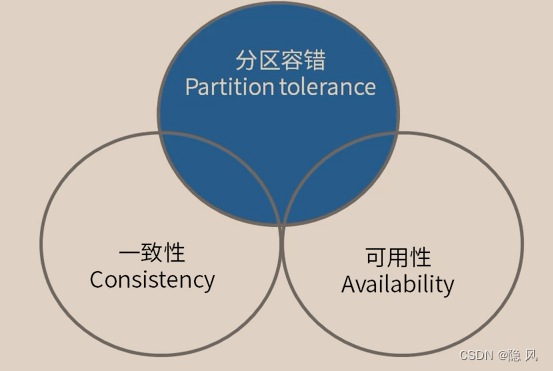
CAP定理是指在一个分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition-tolerance)三者无法同时满足。下面,我们将对CAP定理的三个要素进行详细分析。
一致性
一致性是指分布式系统中的所有节点对于某个数据项的值都能够达成一致状态。在分布式系统中,由于数据被分散到不同的节点上存储和管理,一致性的保证成为了一个重要的问题。
一致性又可以分为强一致性和弱一致性。强一致性是指所有节点在同一时间点上对于同一个数据项的值都完全相同;弱一致性则是指所有节点在经过一段时间后,对于同一个数据项的值能够达到一致状态,但并不保证实时一致。

可用性
可用性是指分布式系统中的所有节点在任何时候都能够对请求做出响应,不出现无响应或超时等情况。在分布式系统中,由于节点的分散性和网络的不稳定性,可用性的保证也成为一个重要的问题。
可用性又可以分为外部可用性和内部可用性。外部可用性是指对于外部请求来说,分布式系统中的所有节点都能够提供正常的服务;内部可用性则是指对于内部请求来说,分布式系统中的所有节点也都能够提供正常的服务。

扩展性
扩展性是指分布式系统中的节点可以动态增加或减少,以保证系统的可伸缩性和适应性。在分布式系统中,由于业务规模的不断扩大和计算需求的不断提升,扩展性的保证也成为一个重要的问题。
实例分析
为了更好地理解CAP定理原理,我们使用一个简单的Java代码示例来解释其应用。在本例中,我们将构建一个简单的分布式系统,包含两个节点A和B,它们之间通过消息传递进行通信。
首先,我们定义一个Node类,表示分布式系统中的节点:
public class Node {private String name;private List<Node> peers;private Map<String, Object> data;public Node(String name, List<Node> peers) {this.name = name;this.peers = peers;this.data = new HashMap<>();}public String getName() {return name;}public List<Node> getPeers() {return peers;}public Map<String, Object> getData() {return data;}public void setData(String key, Object value) {this.data.put(key, value);}
}
接下来,我们定义一个DistributedSystem类,表示分布式系统:
public class DistributedSystem {private List<Node> nodes;public DistributedSystem() {this.nodes = new ArrayList<>();}public void addNode(Node node) {this.nodes.add(node);}public void removeNode(String name) {for (Node node : nodes) {if (node.getName().equals(name)) {this.nodes.remove(node);break;}}}public Map<String, Object> getDataFromNode(String key) {Map<String, Object> result = new HashMap<>();for (Node node : nodes) {if (node.getData().containsKey(key)) {result.put(node.getName(), node.getData().get(key));}}return result;}
}
以上代码示例中,DistributedSystem类表示分布式系统,它包含一组节点(Node对象),并提供了添加和删除节点、从节点获取数据等功能。
现在,我们可以使用以上定义的类来模拟一个分布式系统的运行。假设我们有两个节点A和B,初始时它们的数据如下:
Node nodeA = new Node("A", Arrays.asList(new Node("B")));
Node nodeB = new Node("B", Arrays.asList(new Node("A")));nodeA.setData("key1", "value1");
nodeB.setData("key2", "value2");
接下来,我们可以创建一个分布式系统,并将节点A和B添加到系统中:
DistributedSystem system = new DistributedSystem();
system.addNode(nodeA);
system.addNode(nodeB);
然后,我们可以从系统中获取数据,并输出结果:
Map<String, Object> data = system.getDataFromNode("key1");
System.out.println(data); // 输出:{A=value1}
在上述代码中,我们通过getDataFromNode方法从分布式系统中获取键为"key1"的数据。由于节点A存储了该键的值,因此我们从节点A中获取到了"value1"。
分布式抉择
然而,在分布式系统中,一致性、可用性和分区容忍性三者之间存在矛盾关系。假设节点A和节点B之间的网络连接断开(分区故障),导致节点A无法与节点B通信。这时,如果我们继续在节点A上更新数据,并将数据复制到节点B,会出现数据一致性的问题。如果我们过分强调一致性,可能会导致可用性和分区容忍性受损;反之亦然。
确实,CAP定理的三个要素之间存在一种权衡关系。在分布式系统中,我们无法同时满足一致性、可用性和分区容忍性。这可以通过想象一个简单的分布式系统来说明。
假设我们有一个分布式系统,由两个节点A和B组成。这两个节点之间通过一个网络进行通信。在这种情况下,如果我们要求一致性(Consistency),也就是说,所有节点对于数据的读取和写入操作都能够保持一致,那么我们可能就需要一个中央协调器来同步所有节点的数据状态。这个中央协调器的存在可能会使系统在分区故障发生时变得不可用(Availability)。
另一方面,如果我们要求分区容忍性(Partition-tolerance),也就是说,系统能够在网络分区的情况下继续运行,那么我们可能需要牺牲一致性。在网络分区的情况下,节点A和B可能无法通信,因此无法保持数据一致。
同样,如果我们要求可用性(Availability),也就是说,系统能够在所有节点都正常运行时提供服务,那么我们可能需要牺牲一致性或分区容忍性。例如,如果节点A发生故障,而节点B仍然可用,那么为了保证可用性,我们可能需要在节点B上复制节点A的数据并继续提供服务。但是,这种做法可能会导致数据一致性的问题,因为在节点A和B之间可能存在数据复制的延迟。
因此,在分布式系统的设计中,我们需要根据实际需求来权衡这三个要素。例如,一些系统可能需要高一致性和高可用性,但可以容忍较低的分区容忍性;而另一些系统可能需要在分区故障发生时保持高分区容忍性,但可以牺牲一些一致性和可用性。
针对不同的应用场景,不同类型的分布式系统应运而生。例如,Google的Spanner是一种支持全球分布的、强一致性的分布式数据库;而Amazon的Amazon DynamoDB则是一种最终一致性的NoSQL数据库,具有高可用性和可扩展性。
总的来说,CAP定理为我们提供了在设计和实现分布式系统时的重要指导原则。理解这一定理对于有效地构建满足业务需求的高质量分布式系统是至关重要的。希望这个例子和讨论能帮助你更深入地理解CAP定理的原理和它在分布式系统设计中的重要性。