Redis实现简易消息队列的三种方式
消息队列简介
消息队列是一种用于在计算机系统中传递和处理数据的重要工具。如果你完全不了解消息队列,不用担心,我将尽力以简单明了的方式来解释它。
首先,想象一下你正在玩一个游戏,而游戏中有很多任务需要完成,但你不需要立刻完成它们。相反,你可以将这些任务列在一个清单上,然后按照你的时间表逐个完成。消息队列就像这个任务清单一样,只不过它用于计算机程序之间传递任务和数据。
消息队列的基本原理是,一个程序可以将一条消息(或任务)发送到队列中,然后另一个程序可以从队列中取出并处理这条消息。这种方式有几个关键优点:
-
异步通信:消息队列允许程序之间进行异步通信,也就是说,发送消息的程序不需要等待接收消息的程序立刻响应,它们可以继续执行其他任务。
-
解耦合:消息队列有助于解耦合(解除程序之间的依赖关系)。发送消息的程序不需要知道哪个程序将接收消息,而接收消息的程序只需要关注如何处理消息,而不需要担心消息的来源。
-
缓冲和负载均衡:消息队列可以用作缓冲区,帮助应对高负载情况。如果一个程序在某个时刻发送了大量消息,接收消息的程序可以按照自己的速度处理这些消息,而不会因为消息过多而崩溃。
-
数据持久化:有些消息队列系统还具有数据持久化功能,这意味着消息不会丢失,即使系统发生故障,消息也可以在恢复后重新处理。
-
可伸缩性:消息队列是构建分布式系统的重要工具,因为它们可以帮助应对不断增长的负载,而无需重新设计整个系统。
最常见的消息队列系统之一是RabbitMQ、Apache Kafka和Amazon SQS等。它们在不同情境下有不同的应用,但基本原理是相似的:它们都允许程序之间以异步、松散耦合的方式交换信息,从而提高系统的可伸缩性、可靠性和性能。
总之,消息队列是一种非常有用的工具,用于在计算机系统中传递和处理数据,帮助程序更高效地协同工作,提供了许多优点,包括异步通信、解耦合、缓冲、数据持久化和可伸缩性。希望这个简单的解释能帮助你理解消息队列的基本概念。
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
Redis消息队列-基于List实现消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
关于redis list的操作说明:
BLPOP key [key ...] timeoutsummary: Remove and get the first element in a list, or block until one is availablesince: 2.0.0BRPOP key [key ...] timeoutsummary: Remove and get the last element in a list, or block until one is availablesince: 2.0.0BRPOPLPUSH source destination timeoutsummary: Pop a value from a list, push it to another list and return it; or block until one is availablesince: 2.2.0BLPOP key [key ...] timeoutsummary: Remove and get the first element in a list, or block until one is availablesince: 2.0.0BRPOP key [key ...] timeoutsummary: Remove and get the last element in a list, or block until one is availablesince: 2.0.0LLEN keysummary: Get the length of a listsince: 1.0.0LPOP keysummary: Remove and get the first element in a listsince: 1.0.0LPUSH key value [value ...]summary: Prepend one or multiple values to a listsince: 1.0.0LPUSHX key valuesummary: Prepend a value to a list, only if the list existssince: 2.2.0RPOP keysummary: Remove and get the last element in a listsince: 1.0.0RPOPLPUSH source destinationsummary: Remove the last element in a list, prepend it to another list and return itsince: 1.2.0RPUSH key value [value ...]summary: Append one or multiple values to a listsince: 1.0.0RPUSHX key valuesummary: Append a value to a list, only if the list existssince: 2.2.0
更多详细内容通过命令
help @list
查看
通过list的演示代码
127.0.0.1:6379> rpush list1 1 2 3
(integer) 3
127.0.0.1:6379> lpop list1
"1"
127.0.0.1:6379> lpop list1
"2"
127.0.0.1:6379> lpop list1
"3"
阻塞演示:
一个生产者,两个消费者

让两个消费者获取消息
brpop list 123
此时两个消费者都进入阻塞模式
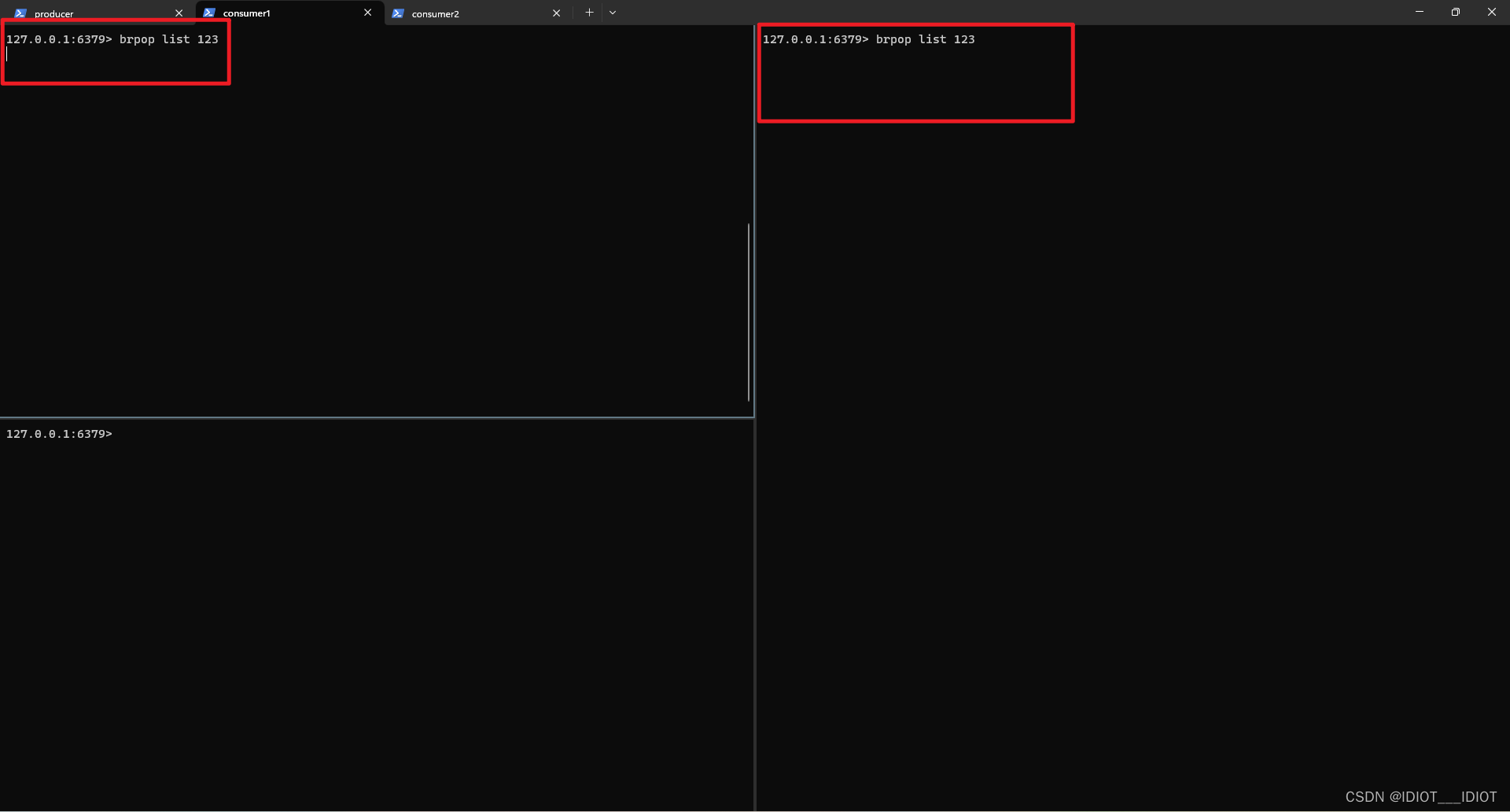
现在生产消息
lpush list test
结果:
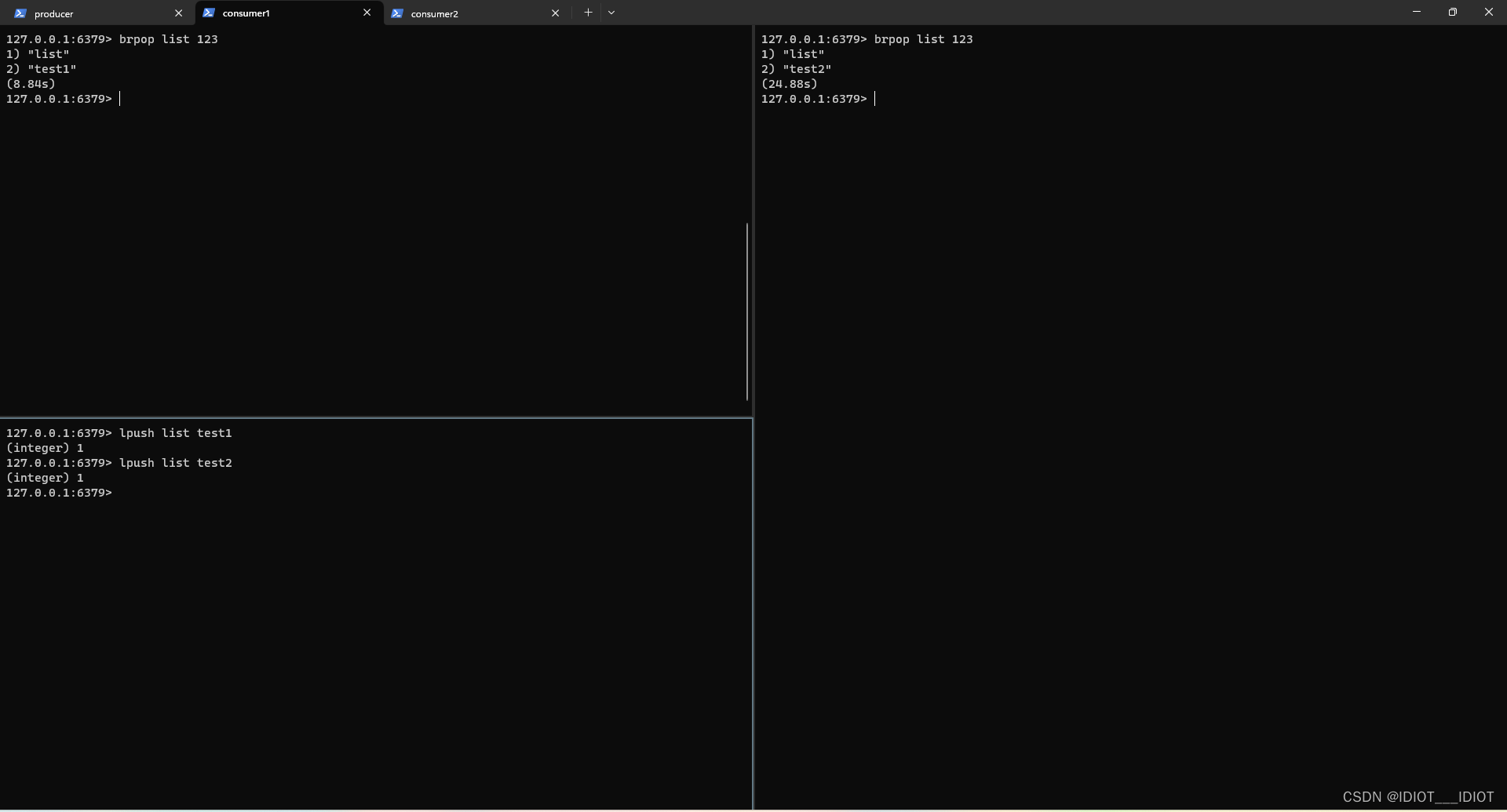
从图中可以看出,生产者进行了两次生产,消费者只能一个一个的获取消息。
基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失 (生产者处理消息时丢失,而在List中已经被删除)
- 只支持单消费者
Redis 消息队列-基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
使用简介:
PSUBSCRIBE pattern [pattern ...]summary: Listen for messages published to channels matching the given patternssince: 2.0.0PUBLISH channel messagesummary: Post a message to a channelsince: 2.0.0PUBSUB subcommand [argument [argument ...]]summary: Inspect the state of the Pub/Sub subsystemsince: 2.8.0PUNSUBSCRIBE [pattern [pattern ...]]summary: Stop listening for messages posted to channels matching the given patternssince: 2.0.0SUBSCRIBE channel [channel ...]summary: Listen for messages published to the given channelssince: 2.0.0UNSUBSCRIBE [channel [channel ...]]summary: Stop listening for messages posted to the given channelssince: 2.0.0
使用结果
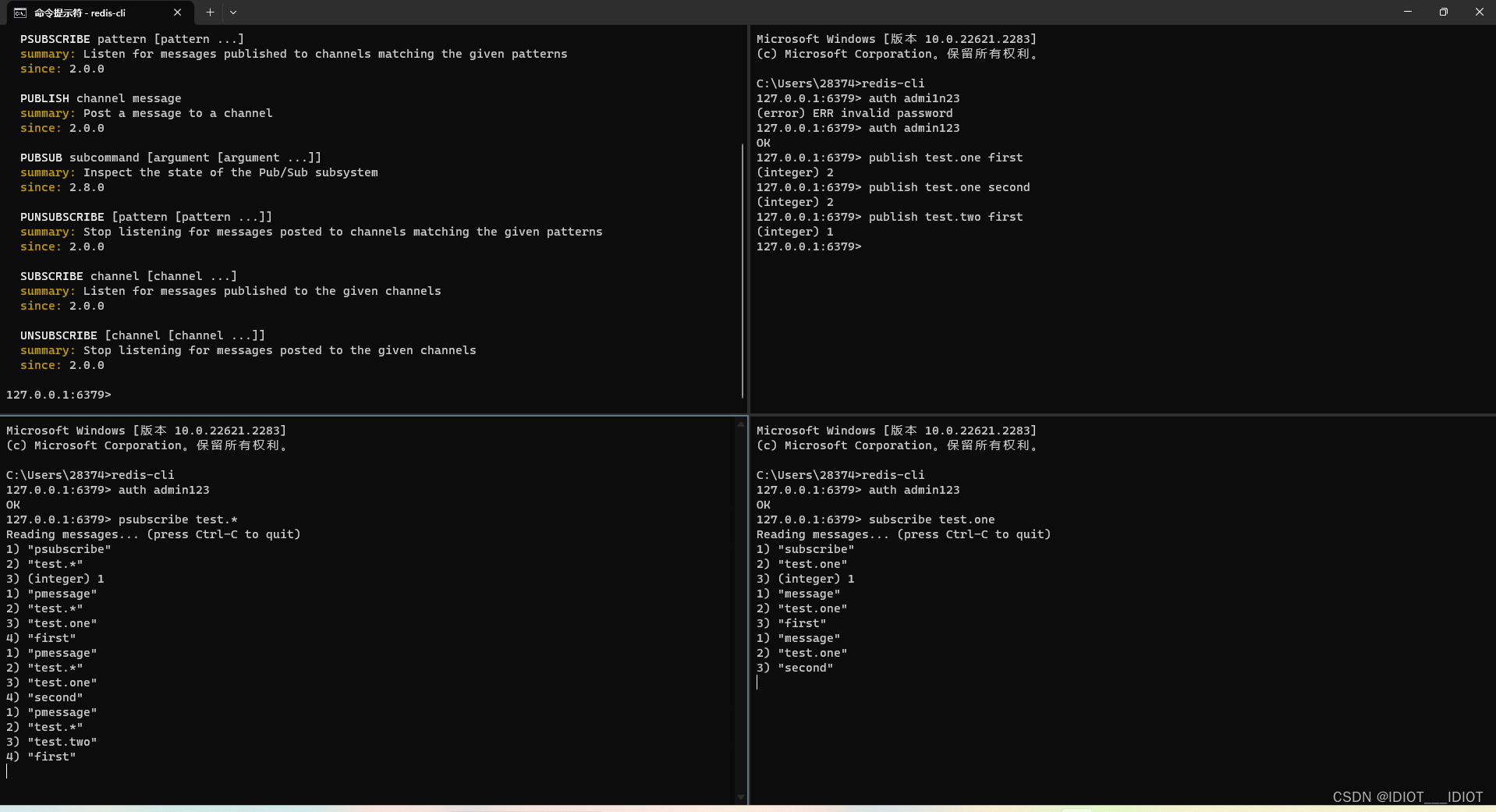
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
Redis 消息队列-基于Stream的消息队列
下面是添加消息的方法,其中key是指定stream的关键字,id是唯一的,如果输入*的话由redis自动生成,然后就是添加field string,键值对了
XADD key ID field string [field string ...]
summary: Appends a new entry to a stream
since: 5.0.0
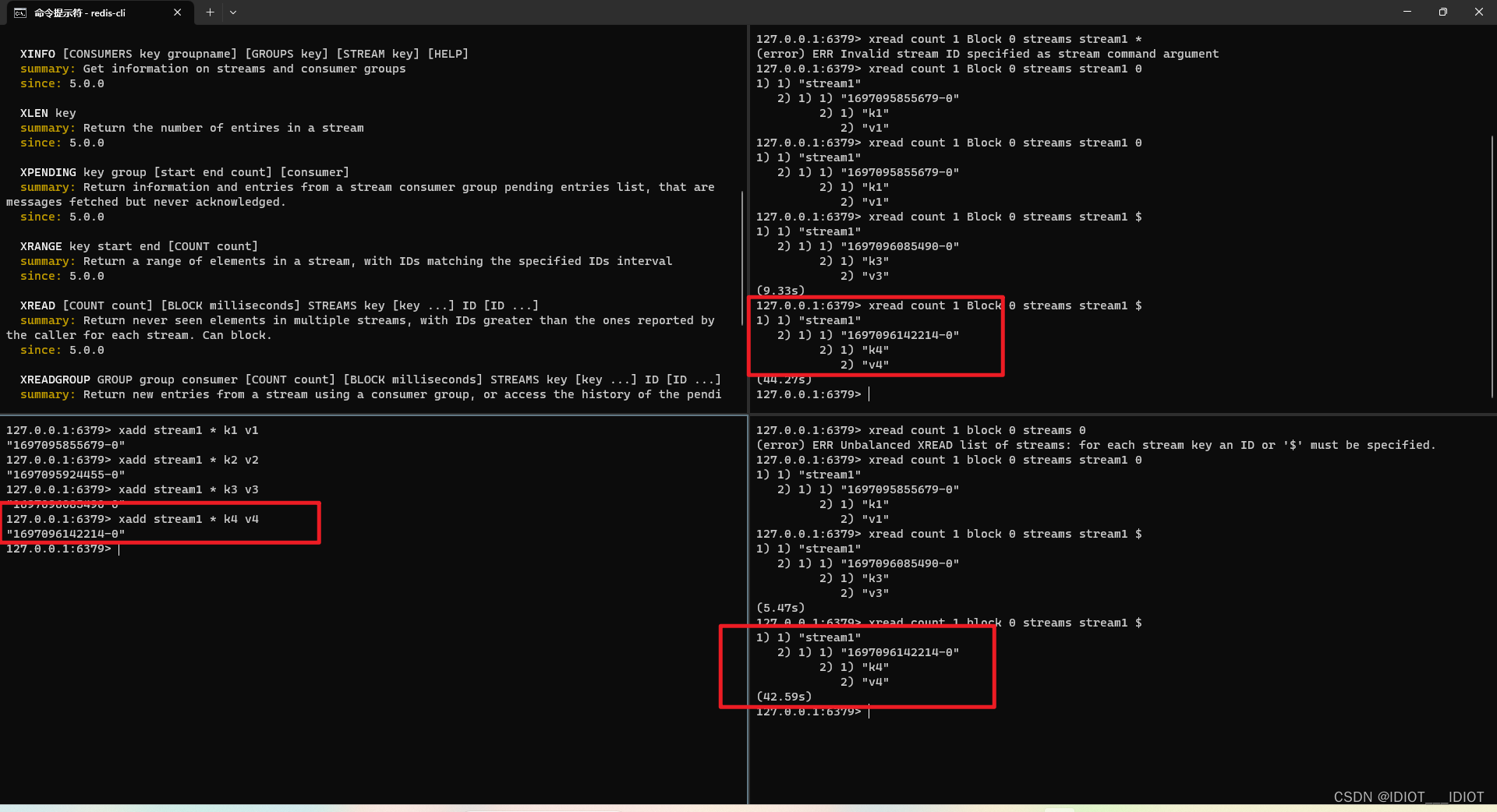
下面是读消息的方法,其中COUNT可选字段表示读几条消息,BLOCK表示阻塞读取,其中的milliseconds如果为0表示永久,STREAMS就表示你要看的stream的key是什么,然后就是ID了,ID有两个选项一个0表示读取第一条消息$表示读取最新消息,但是这个读取最新消息可能会出现漏读现象。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
summary: Return never seen elements in multiple streams, with IDs greater than the ones reported by the caller for each stream. Can block.
since: 5.0.0
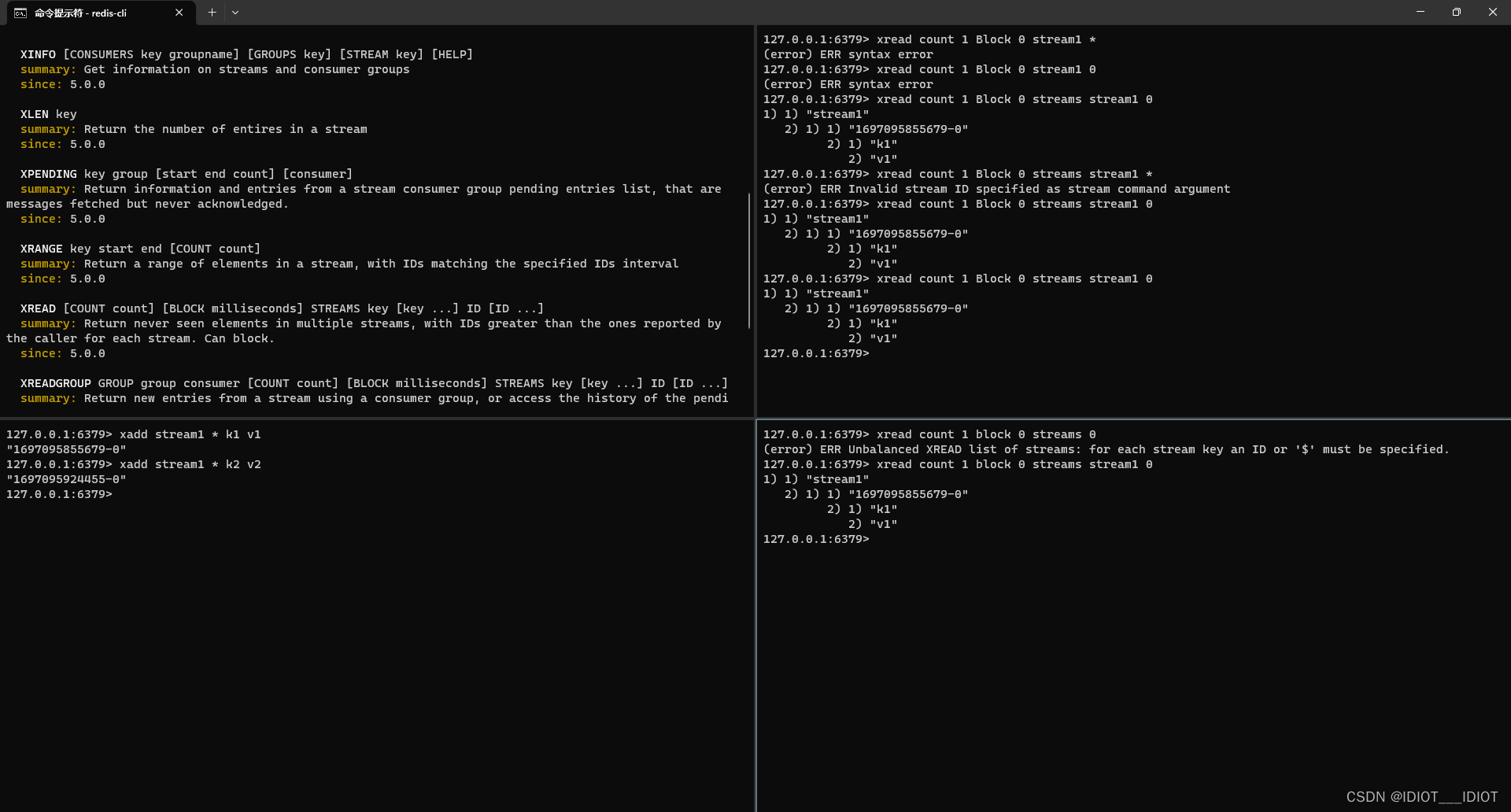
两个消费者同时进入阻塞读取最新消息
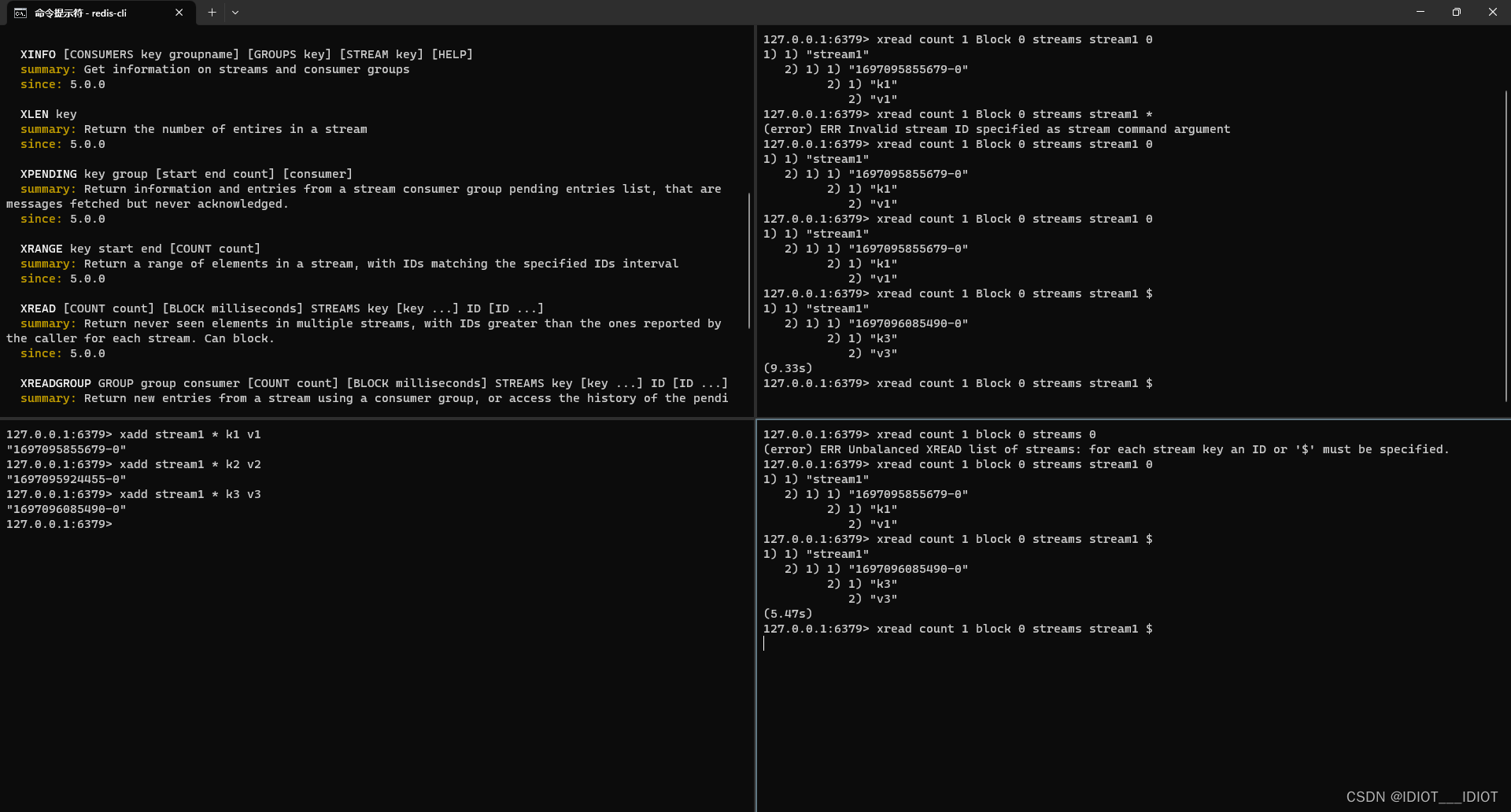
可以看到两个同时读取到了
新增多条消息,只能收取到最新消息
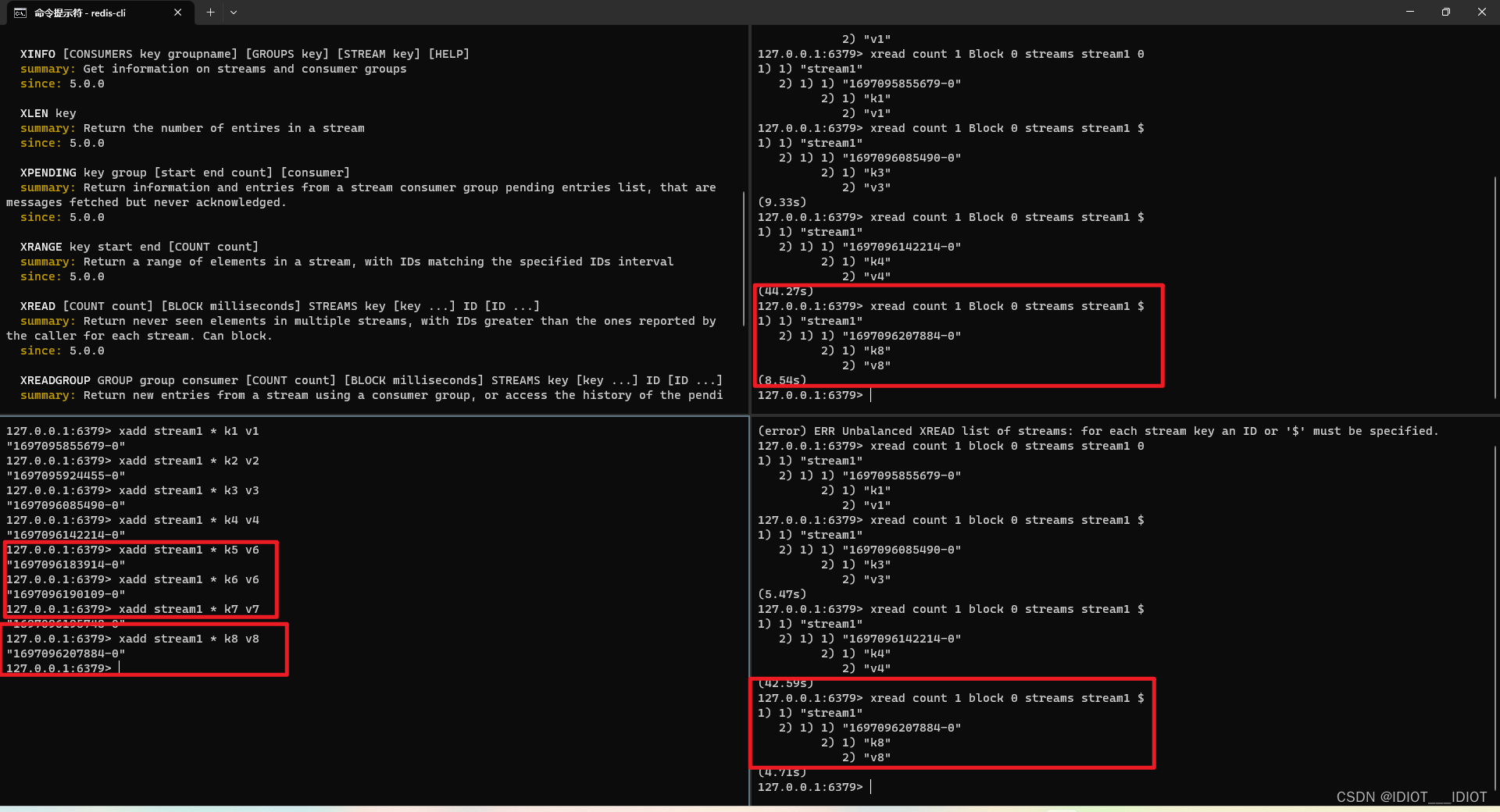
STREAM类型消息队列的XREAD命令特点:
优点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
缺点:
- 有消息漏读的风险
消费者组解决漏读问题
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:
- 消息分流
- 队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
- 消息标示
- 消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费
- 消息确认
- 消费者获取消息后,消息处于pending状态,并存入一个pending-list。当处理完成后需要通过XACK来确认消息,标记消息为已处理,才会从pending-List移除。
创建消费者组
XGROUP CREATE key groupName ID [MKSTREAM]
- key : 队列名称
- groupName: 消费者组名称
- ID: 起始ID标示 , $代表队列中最后一个消息,0则代表队列中第一个消息
- MKSTREAM: 队列不存在时自动创建队列
删除指定的消费者组
XGROUP DESTORY key groupName
给指定的消费者组添加消费者(一般自动添加)
XGROUP CREATECONSUMER key groupName consumername
删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername
从消费者组读取消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ……] ID [ID ……]
- group : 消费者组名
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count : 本次查询的最大数量
- BLICK milliseconds: 当没有消息时最长等待时间
- NOACK: 无需手动ACK(ACK确认消息,从pending-list中移除),胡渠道消息后自动确认
- STREAMS key : 指定队列名称
- ID : 获取雄安锡的起始ID
>: 从下一个未消费的消息开始- 其他:根据指定id从pending-list中获取已消费单位确认的消息,例如0,从pending-list中的第一个消息开始。
确认消息
XACK key group ID [ID ...]
- key : stream 名称
- group : 消费者组名称
- id: 就是消息的ID
查看pending-list中的消息信息
XPENDING key group [start end count] [consumer]
-
key: stream 名称
-
group : group 名称
-
start end count : 可以使用
-代表从第一个+代表对后一个这两个配合就是所有,然后用count表示出几个,示例xpending stream1 g1 - + 10
在java中的逻辑

STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次



![Flask框架配置celery-[1]:flask工厂模式集成使用celery,可在异步任务中使用flask应用上下文,即拿即用,无需更多配置](https://img-blog.csdnimg.cn/92a5319c10354348b1c7ba2819c89045.png)