说明
- 本次训练服务器使用Google Colab T4 GPU
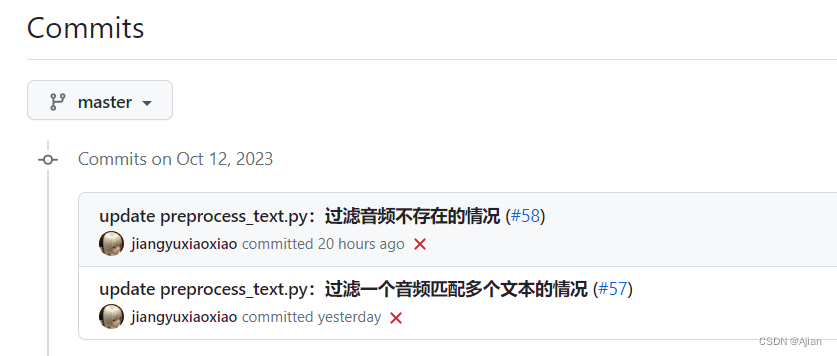
- Bert-VITS2库为:https://github.com/fishaudio/Bert-VITS2,其更新较为频繁,使用其2023.10.12的commit版本:
- 主要参考:B站诸多大佬视频,CSDN:https://blog.csdn.net/qq_51506262/article/details/133359555,
码云:https://gitee.com/Sake809/Bert-VITS2-Integration-package - 部署过程中出现诸多问题,对原版Bert-VITS2个别代码也有调整,调整后的代码已放码云:https://gitee.com/ajianoscgit/bert-vits2.git
- 本项目是确定可运行的,后续随着Bert-VITS2的持续更新,当前能稳定运行的代码后续可能会出问题。
环境准备
包括下载代码、下载模型等等步骤
下载项目
%cd /content/drive/MyDrive
# 这里是下载原仓库代码
#!git clone https://github.com/fishaudio/Bert-VITS2.git
# 这是下载码云调整后的代码
!git clone https://gitee.com/ajianoscgit/bert-vits2.git下载模型
这里只下载了中文语音的模型,在https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main 下载即可,根据/content/drive/MyDrive/Bert-VITS2/bert/chinese-roberta-wwm-ext-large目录缺失的文件下载补全。
%cd /content/drive/MyDrive/Bert-VITS2/bert/chinese-roberta-wwm-ext-large
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/flax_model.msgpack
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/pytorch_model.bin
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/tf_model.h5
下载底模文件:
底模文件使用b站大佬裁切好的底模,效果更好,https://www.bilibili.com/video/BV1hp4y1K78E
由于cloab无法直接下载到模型文件,只好先在站点下载完成之后再上传到谷歌云盘中,放在logs/base/目录下。
# 这是原版底模,使用1.1版b站大佬的底模替代!
%cd /content/drive/MyDrive/Bert-VITS2#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/DUR_0.pth
#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/D_0.pth
#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/G_0.pth
编写数据预处理脚本
训练特定音色的模型时,需要首先将准备好的音频干声文件进行分割,将分割后的文件文本提取出来备用。
可以本地将这些文件先准备好,也可以服务器上制作,服务器上制作就用以下脚本实现。
以下脚本为实现此功能的相关脚本(该脚本根据csdn大佬的代码进行了调整,实现读取运行时参数和音频转写文本时汉字繁体转简体):
import os
from pathlib import Path
import librosa
from scipy.io import wavfile
import numpy as np
import whisper
import argparse
from langconv import *def split_long_audio(model, filepath, save_dir="short_dir", out_sr=44100)->str:'''将长音源wav文件分割为短音源文件,返回短音源文件存储路径path'''# 短音频文件存储路径save_dir=os.path.join(os.path.dirname(filepath),save_dir)if not os.path.exists(save_dir):os.makedirs(save_dir)#分割文件print(f'分割文件{filepath}...')result = model.transcribe(filepath, word_timestamps=True, task="transcribe", beam_size=5, best_of=5)segments = result['segments']wav, sr = librosa.load(filepath, sr=None, offset=0, duration=None, mono=True)wav, _ = librosa.effects.trim(wav, top_db=20)peak = np.abs(wav).max()if peak > 1.0:wav = 0.98 * wav / peakwav2 = librosa.resample(wav, orig_sr=sr, target_sr=out_sr)wav2 /= max(wav2.max(), -wav2.min())for i, seg in enumerate(segments):start_time = seg['start']end_time = seg['end']wav_seg = wav2[int(start_time * out_sr):int(end_time * out_sr)]wav_seg_name = f"{i}.wav" # 修改名字i+=1out_fpath = os.path.join(save_dir,wav_seg_name)wavfile.write(out_fpath, rate=out_sr, data=(wav_seg * np.iinfo(np.int16).max).astype(np.int16))return save_dirdef transcribe_one(audio_path): # 使用whisper语音识别# load audio and pad/trim it to fit 30 secondsaudio = whisper.load_audio(audio_path)audio = whisper.pad_or_trim(audio)# make log-Mel spectrogram and move to the same device as the modelmel = whisper.log_mel_spectrogram(audio).to(model.device)# detect the spoken language_, probs = model.detect_language(mel)lang = max(probs, key=probs.get)# decode the audiooptions = whisper.DecodingOptions(beam_size=5)result = whisper.decode(model, mel, options)#繁体转简体txt = result.texttxt = Converter('zh-hans').convert(txt)fileName = os.path.basename(audio_path)print(f'{fileName}:{lang}——>{txt}')return txtif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('inputFilePath', type=str,help="干声源音频wav文件的全路径")parser.add_argument('listFileSavePath', type=str,help=".list文件存储全路径")parser.add_argument('--shortFilesPath', type=str, help="已经分割好了的短音频的存储目录全路径,用于当分割好之后再次运行时配置")opt = parser.parse_args()print(f'参数:{opt}')model = whisper.load_model("medium")#将长音源分割成短音源文件if not opt.shortFilesPath:save_dir = split_long_audio(model, opt.inputFilePath)else:save_dir = opt.shortFilesPath#为每个短音频文件提取文字内容,生成.lab文件和filelists目录下的.list文件if not os.path.exists(opt.listFileSavePath):file = open(opt.listFileSavePath, "w")file.close()print('提取文字内容...')files=os.listdir(save_dir)spk = os.path.basename(os.path.dirname(opt.inputFilePath))for file in files:if not file.endswith('.wav'):continuetext = transcribe_one(os.path.join(save_dir,file))with open(os.path.join(save_dir,f"{file}.lab"),'w') as f:f.write(text)with open(opt.listFileSavePath,'a', encoding="utf-8") as wf:wf.write(f"{os.path.join(save_dir,file)}|{spk}|ZH|{text}\n")print('音频预处理完成!')
安装依赖
#检查CUDA版本
import torch
print(torch.version.cuda)
print(torch.cuda.is_available())
#安装依赖
%cd /content/drive/MyDrive/Bert-VITS2!pip install wavfile
!pip install git+https://github.com/openai/whisper.git
!pip install -r requirements.txt
!pip install zhconv==1.4.3
!pip install zhtools==0.3.1
训练
音频预处理
- 音频需要自己录一段声音,1分钟以上,10分钟以内即可
- 音频使用Ultimate Vocal Remover工具去掉背景杂音,使其为一段纯音频的干声。Ultimate Vocal Remover工具使用见:https://github.com/Anjok07/ultimatevocalremovergui,作者封装了GUI,下载安装即可
- 提取好了的干声自行上传到项目的data目录下,data下需要新建一个名称目录,如zhangsan,文件结构如下:
Bert-VITS2
————data
——————zhangsan
————————ganshen.wav - 执行以下脚本,对音频预处理
%cd /content/drive/MyDrive/Bert-VITS2
!python 音频预处理脚本.py /content/drive/MyDrive/Bert-VITS2/data/zhangsan/ganshen.wav /content/drive/MyDrive/Bert-VITS2/filelists/zhangsan.list --shortFilesPath '/content/drive/MyDrive/Bert-VITS2/data/zhangsan/short_dir'
注意:音频预处理完成之后,要打开datalists目录下对应的list文件看看处理结果,把过分离奇的、错误明显的行直接删掉!
音频重采样
会在dataset下生成重采样后的音频,如果修改了源音频要进行二次训练,需要将原dataset下的文件删除。
%cd /content/drive/MyDrive/Bert-VITS2
!python resample.py --in_dir /content/drive/MyDrive/Bert-VITS2/data/zhangsan/short_dir
预处理.list文件
预处理完成会在filelists下生成.cleaned、train.list、val.list文件!
%cd /content/drive/MyDrive/Bert-VITS2
!python preprocess_text.py --transcription-path /content/drive/MyDrive/Bert-VITS2/filelists/zhangsan.list
生成pt文件
会在data/用户名/short_dir目录下生成对应视频文件的.bert.pt文件
%cd /content/drive/MyDrive/Bert-VITS2
!python bert_gen.py --num_processes 4
开始训练
注意1:开始训练前必须要先把data目录下本次训练的文件夹名字加到configs/config.json文件的spk2id下,并加一个id!!!这个案例中就是把“zhangsan”加到"标贝": 247,后面!
注意2:train_ms.py和data_utils.py有大量修改,支持多线程并行训练。但是T4服务器只有12G内存会爆仓,所以没有多线程的效果。
%cd /content/drive/MyDrive/Bert-VITS2# -m:base,表示的logs/base/底模文件目录的base
!python train_ms.py -m base -c configs/config.json --cont


![2023年中国云存储优势、产值及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/98f3228ef22b3e7bee39e15bc71dcc4b.png)