数据收集(nginx)--->数据分析---> 数据清洗--->数据聚合计算---数据展示
可能涉及到zabix 做任务调度
我们的项目 电商日志分析
比如说我们现在有一个系统,我们的数仓建立也要有一个主题
我这个项目是什么我要干什么定义方向
对用户进行分析,用户信息
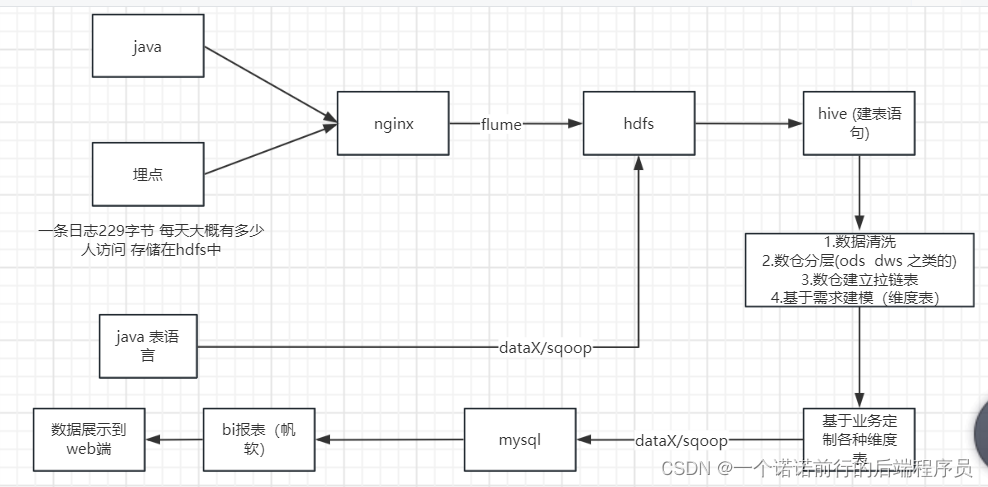
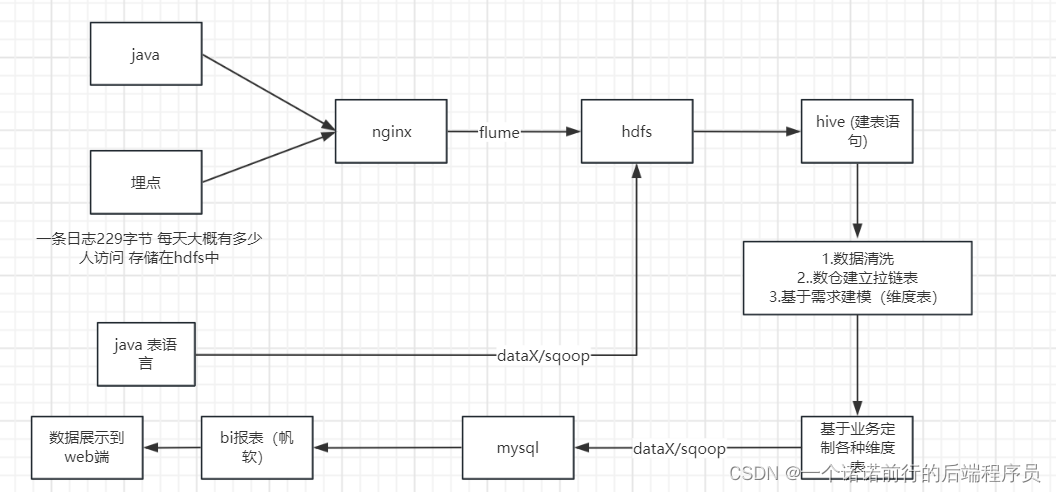
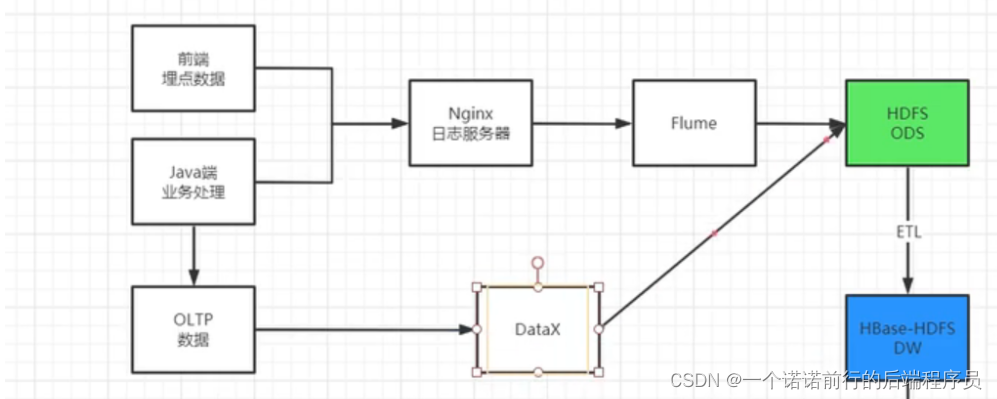
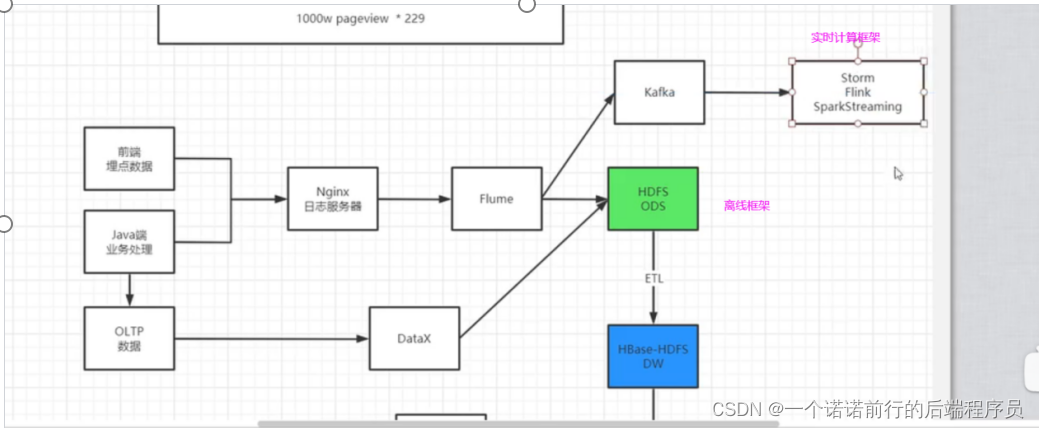
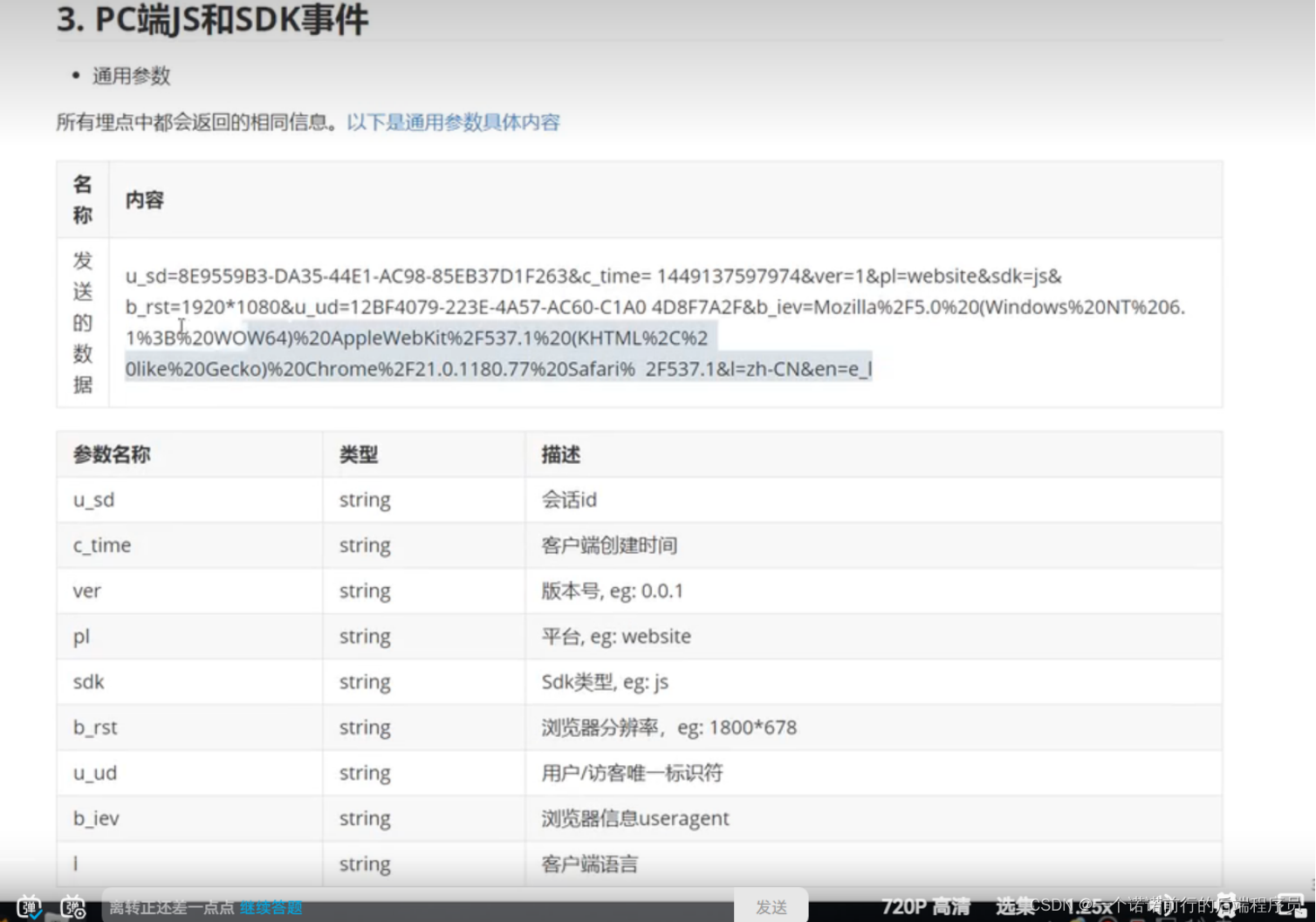
要懂整个数据的流程1. 前端埋点数据
2. java业务端数据 (比如说 支付成功或者支付失败我要发到nginx 服务上)
3. java (oltp数据)
4. nginx 负载均衡 反向代理,基于nginx的access.log文件可以做日志收集
进而统计网站的pv埋点日志一条日志 229字节 一条埋点日志229字节10000w的点击量*229字节 (存储hdfs)
nginx 专门做日志收集
flume专门做日志采集
我们的日志分结构化和非结构化日志
DATAX/sqoop可以做数据迁移 数仓分离线数仓 以及实时数仓
前端基于事件触发的埋点 比如说点击事件
java支付成功,支付失败的事件,可能Java业务端 付款成功会发一条请求 发送到nginx 服务上
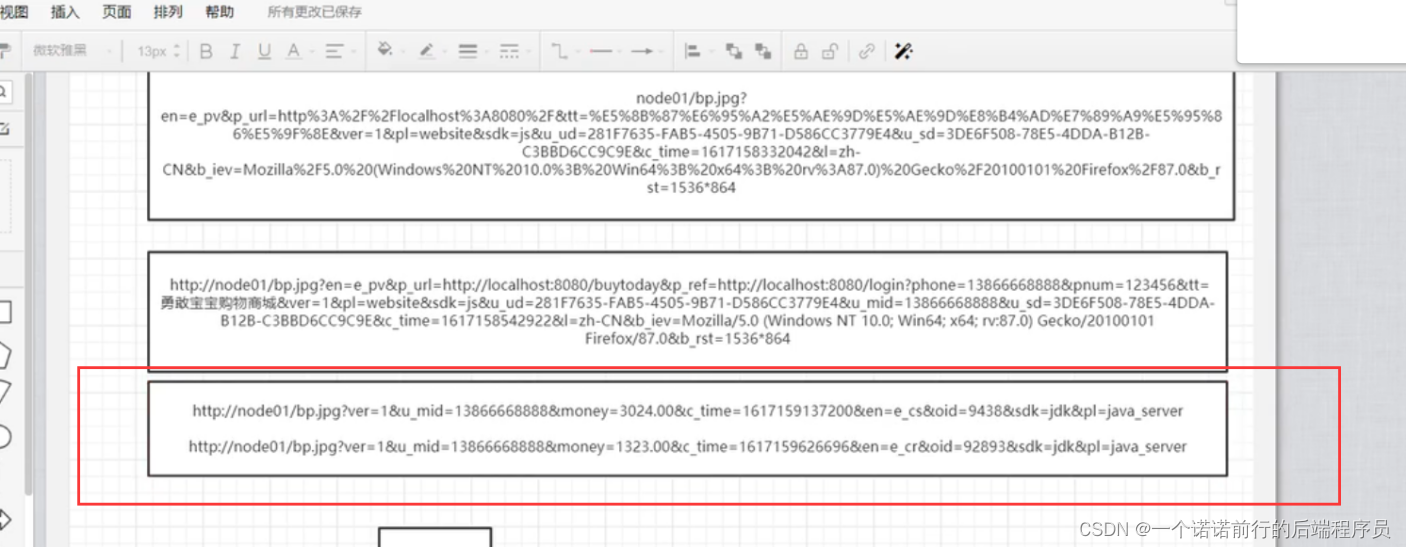
我们的日志已经拿到了 包括支付成功,支付失败或者pv 点击事件
我们会吧日志统一发送到------>nginx 负责采集
nginx 的access.log 帮我们做统计日志的情况
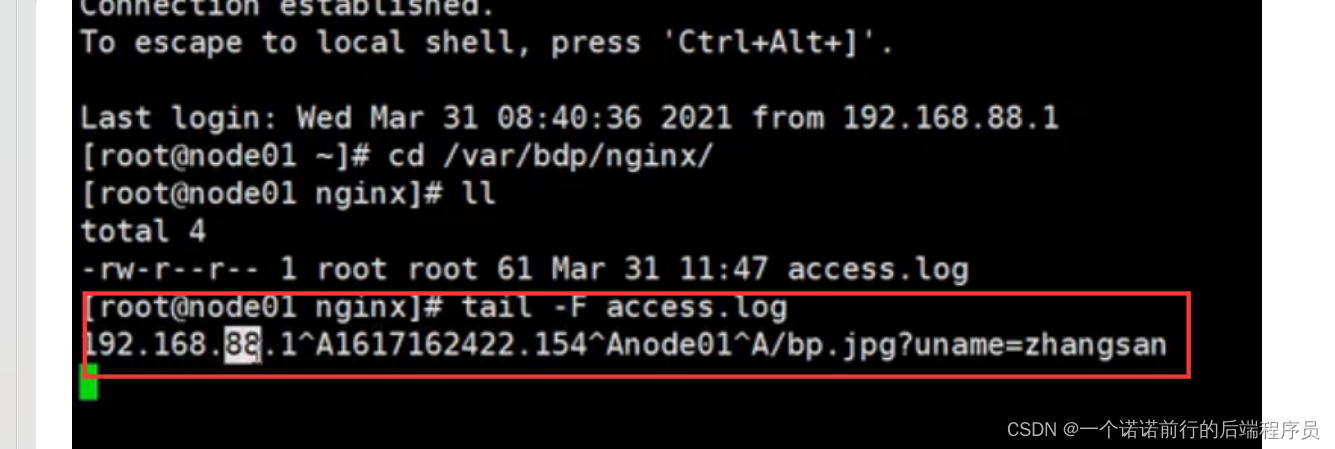
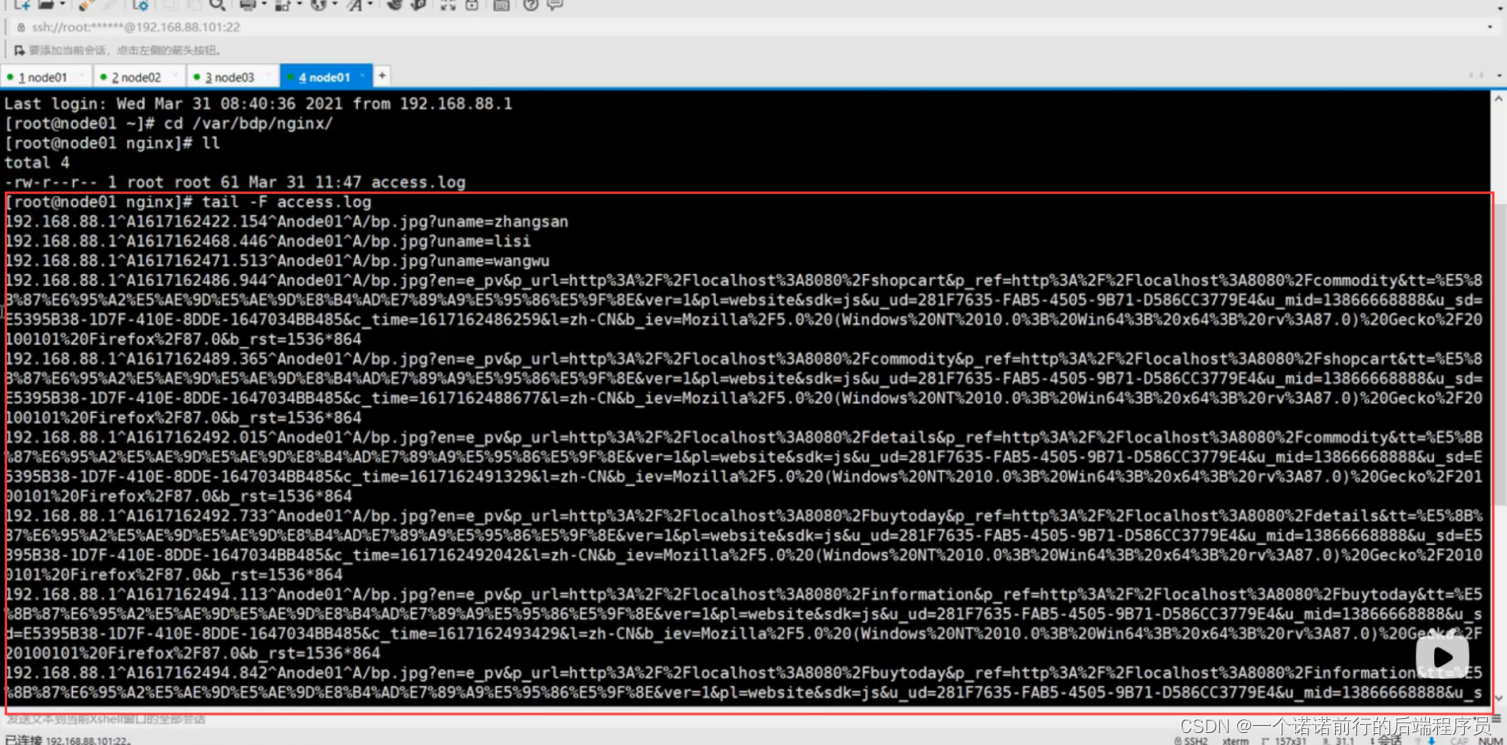
然后我们可以基于awk sed grep 来进行nginx日志的处理
nginx的access.log 我们的pv就出来了 我们nginx就充当了 日志收集着的角色然后我们可以启动一个springboot项目 通过maven打包 java-jar 执行
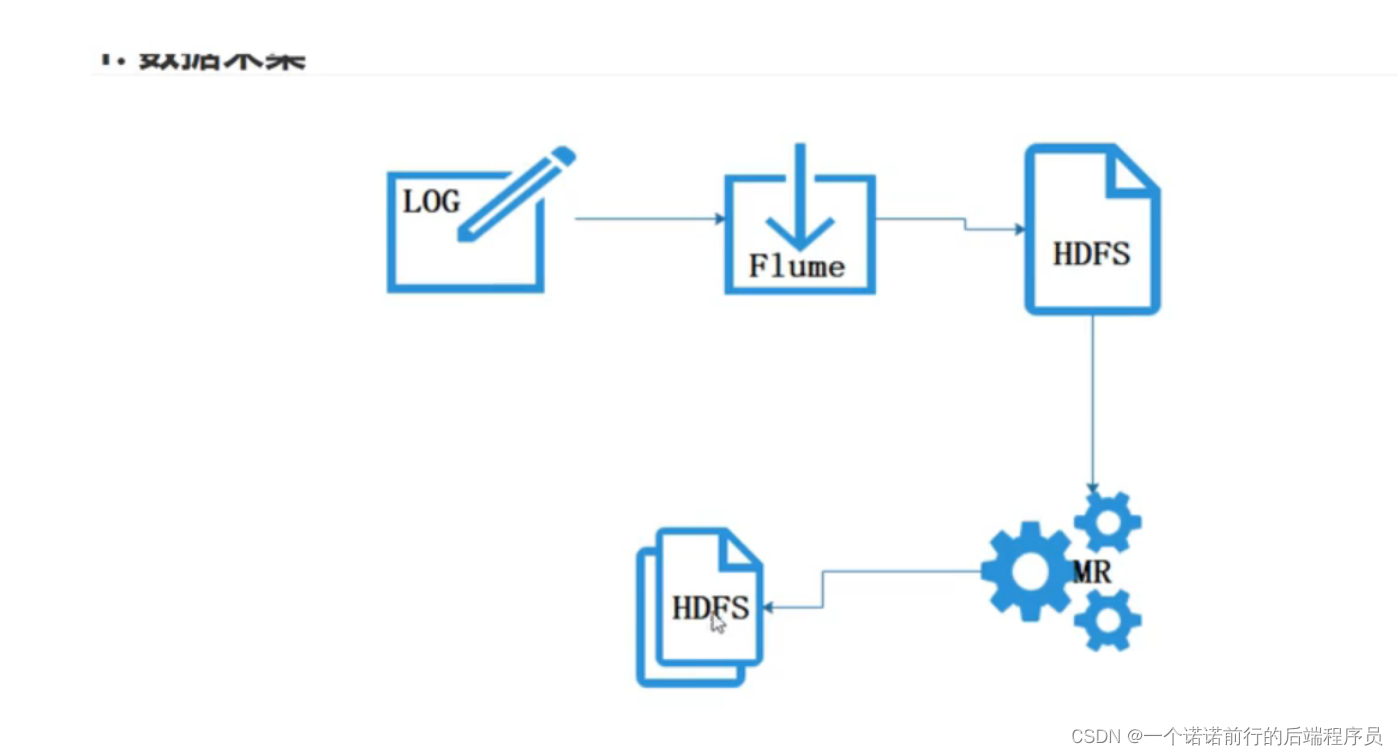
nginx 收集到日志,我们下一步要吧这个nginx日志打到hdfs中
接下来我们要配置flume 吧nginx数据导入到hdfs中
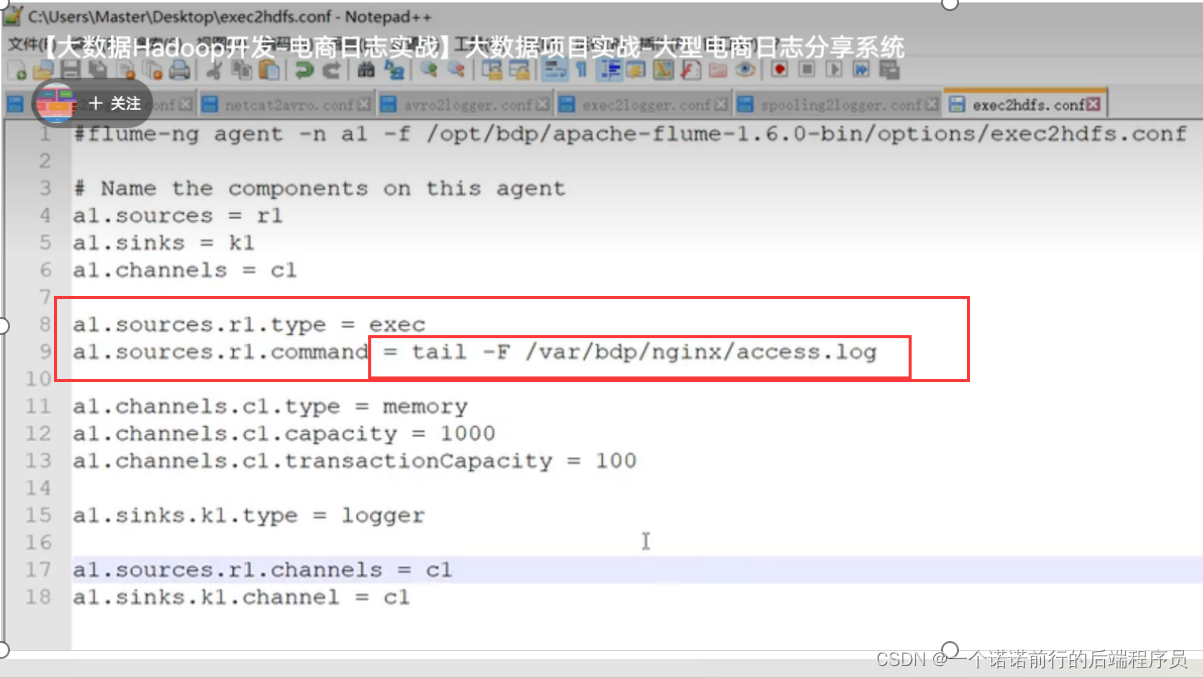
flume可以监控log的变化 我们吧数据从nginx 通过flume导入到了hdfs中 接下来我们要做的就是数据清洗
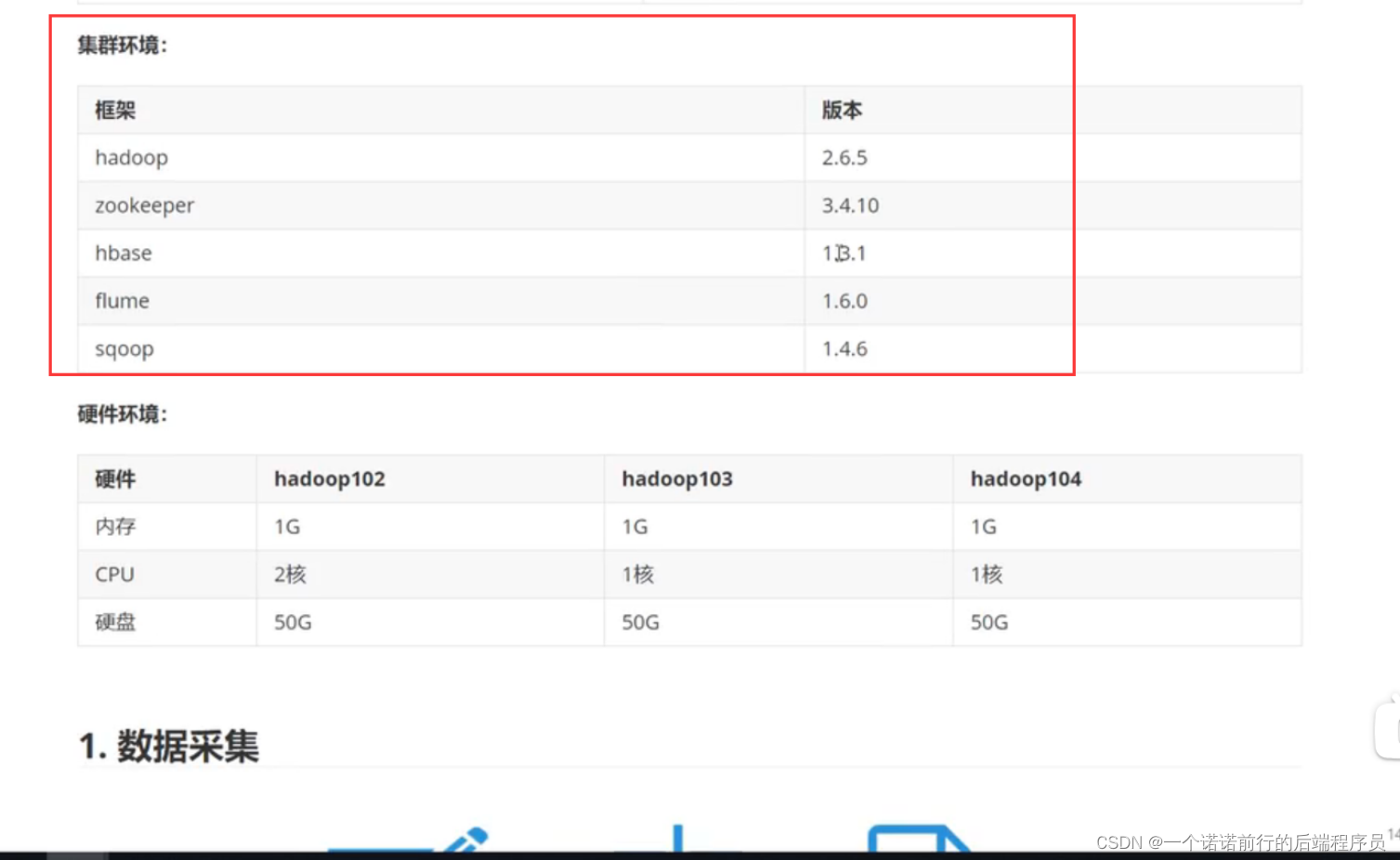
如何吧数据进行拆解 拆解成我们想要的样子 我们要基于我们的业务 来分析 用什么软件 用了多少台服务器 集群配置 集群规划(什么版本)
数据采集
etl:做数据清洗,去除脏数据.如何吧数据进行拆解 拆解我们想要的样子

在这里插入代码片
做数据采集的思路


我到时候可以分析出 一个用户在一个会话中访问了多少网站
吧数据进行拆分 我们etl会拿出数据进行分析 比如说ip,他们就会知道在那个地方访问的我
用的什么浏览器
浏览器信息
基于一个会话 我就可以知道他的页面链路了
基于mr进行解析日志 之后映射成表
我们的数据就洗出来了
然后我们建维度 就给各个维度表里面导数据了
当我们访问服务器的时候 就会有埋点日志
java/js========>nginx 埋点日志数据----->hdfs -->(基于mr去进行拆解以及数据清洗)-->导入hive
mr的作用帮我们解析日志
首先数据我们已经做了一些简单的清洗,错误的数据已经是没有了,不符合规则的数据
我们肯定对数据进行一些计算
我们要基于我们的业务数据进行建模(建立各种维度表)
先确定我们要分析的维度 (需求) ----------->基于维度建表
我们会设计很多的维度表 来满足我们的需求