本文将分享为什么以及如何使用外部的知识和工具来增强视觉或者语言模型。
全文目录:
1. 背景介绍
-
OREO-LM: 用知识图谱推理来增强语言模型
-
REVEAL: 用多个知识库检索来预训练视觉语言模型
-
AVIS: 让大模型用动态树决策来调用工具
技术交流群
建了技术交流群!想要进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
01
背景介绍

首先介绍示例“德州的 NBA 球队有哪些?他们分别在哪一年获得 NBA 总冠军?”对于这样的问题,ChatGPT 可以非常准确地回答。这个例子说明了类似 GPT 的模型,已经有非常强的世界知识记忆能力,并且存储在它们的参数当中,针对不同的问题,它能够准确地将其调用回答该问题。

“在2000年以后,有哪些球队没有获得过总冠军?”对于较难的问题,ChatGPT 还能够完成吗?实际上是不行的。类似的例子还有非常多。哪怕模型记住了某个知识,但并不能进行较为严格的逻辑推理。对于它不会的问题,它就不回答。这样的能力它们暂时还是缺失的。这隐含了包括大模型在内的很多神经基础模型(Neural Base Model)的一大缺陷,这是因为大部分的外部的知识都是通过类似 Continuous representation 的方式存储在模型的参数当中。因此,当处理逻辑推理或离散推理的场景时,通常来说,这些模型并不能很好地回答。
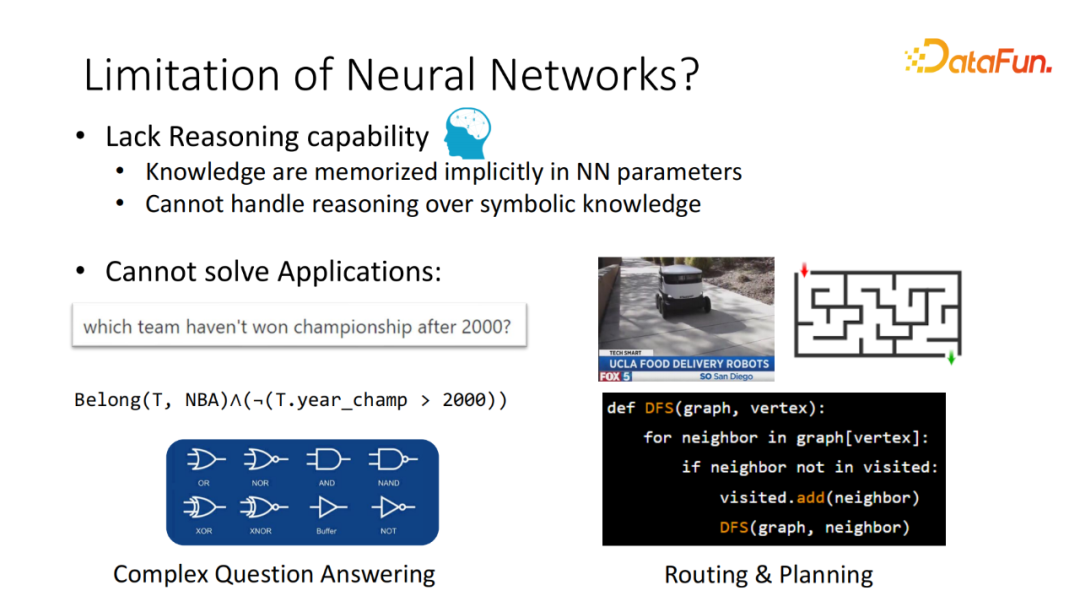
例如刚刚提到的需要一定的逻辑推理才能解决的问答系统,或者想构建一个寻路系统,比如在 UCLA 里,部署自动送外卖的工具。显而易见,如果想找到目标的位置,需要实现寻路的算法,像 DFS 找最优的路径。这个算法想用神经网络(Neural Network)完成,通常需要大量的数据。如果只采集某个特定领域(Domain),训练出来的模型,通常来说也只能够适用于该领域,而不能迁移泛化。
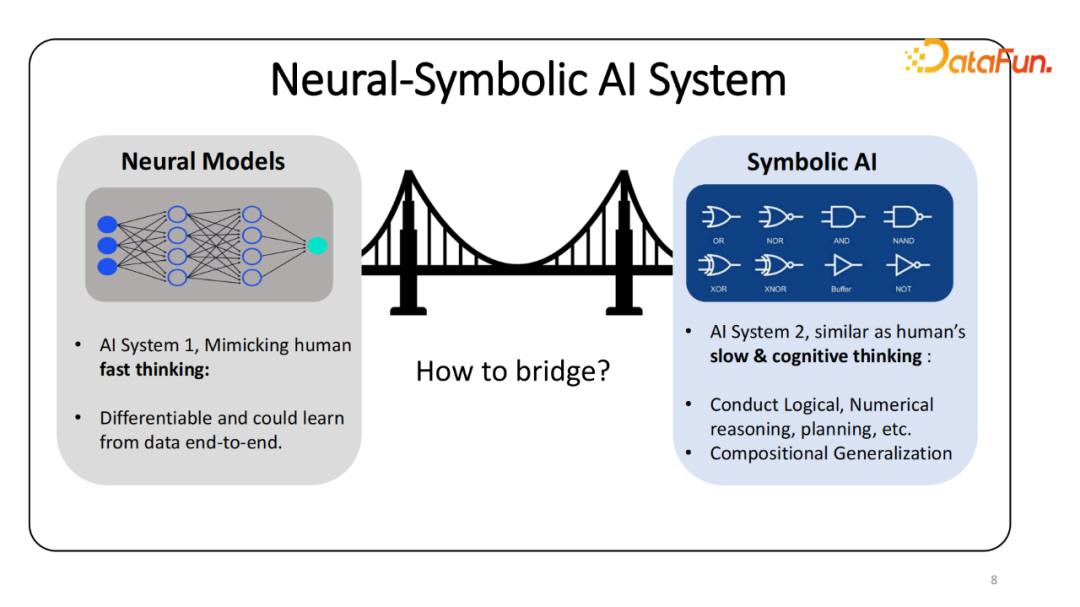
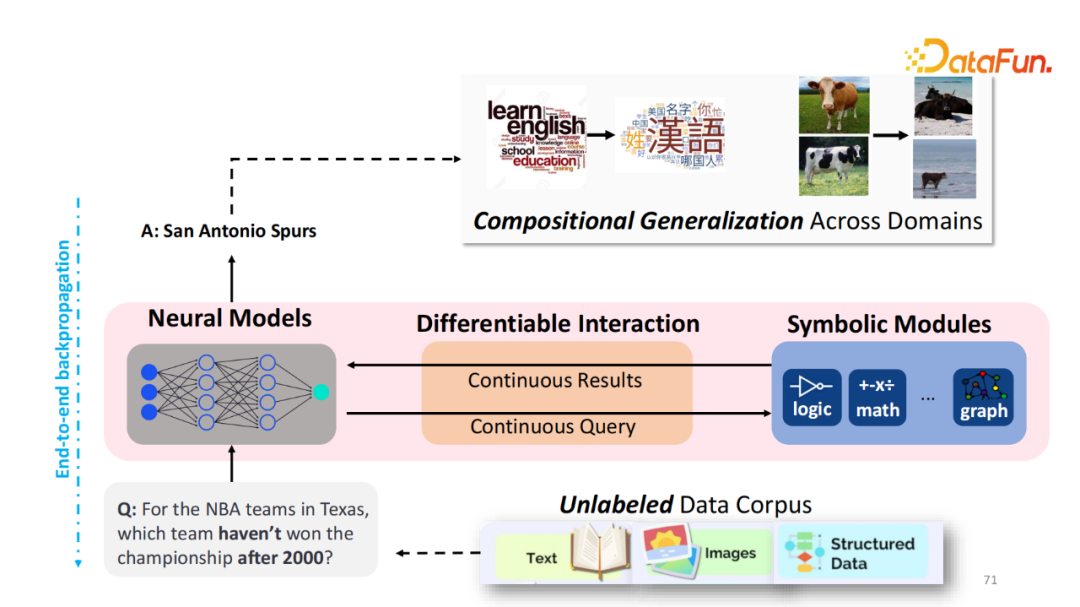
这一系列的问题激发了我个人博士生涯的工作,如何让传统的 Symbolic AI 工具被神经网络所使用。之前提到,需要进行快速和慢速思维(Fast and Slow Thinking),普遍的认知是神经网络可以快速推理,回答简单的问题,比如识别一个 Object,判断句子是正向还是负向。而对于相对较难的需要一定的思考才能解决的问题,比如围棋、寻路可能会需要一定的外部的工具或者知识才能解决。
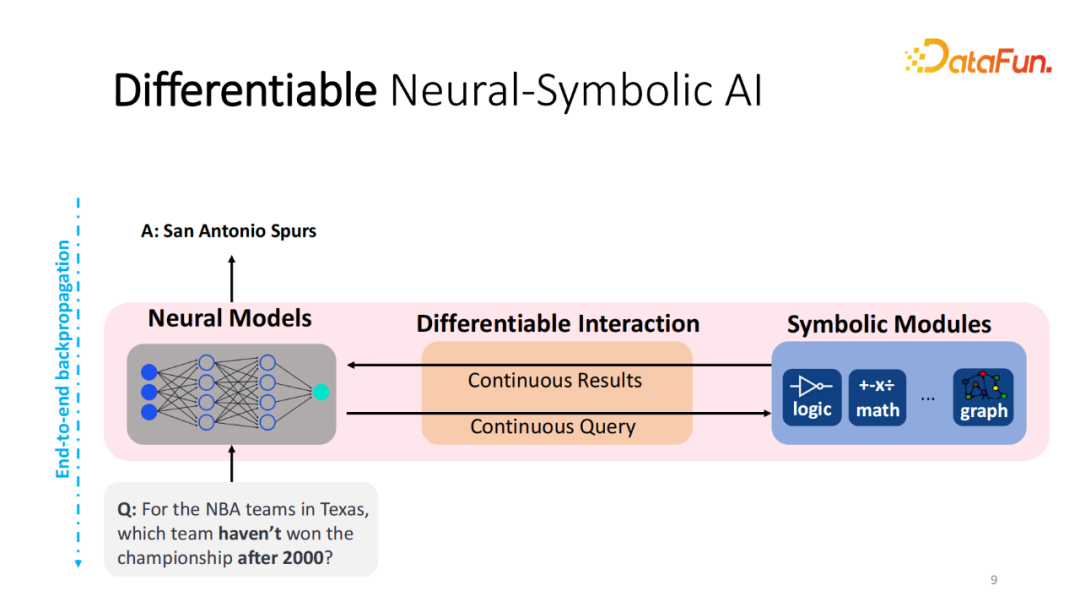
如何将这两个模块进行交互并且合并。传统的方法都是基于解析(Parsing)的方法,也就是将自然语言的输入转化为程序,并能够被 Symbolic 模块执行。中间的程序通常需要大量的标注才能训练,我的研究方向更多的是能不能不构建所谓可微分的 Neural-Symbolic AI,还是以神经网络作为解决问题的模型。希望模型能自由地和外部的工具(logical、计算器或知识图谱)进行可微分的交互。过程当中,察觉到某个问题需要某种特定的工具,能够向对应的工具发送相应的请求,得到对应的回答。中间的交互过程能够尽可能地被可微分化,可计算梯度,输入和输出能够表示成嵌入(Embedding)的形式。这样,在给定一个数据集,甚至是无标注数据集上,能够将整个系统直接进行预训练,而不需要中间结果的标注,这是最终的愿景。显而易见,如果这样的系统能够实现的话,它能够直接训练于无标注的数据集,比如文本或结构化的数据。

今天报告主要展示三个工作,可能运用了不同水平的 Symbotic 模块。
-
第一个工作,尝试如何让语言模型调用知识图谱中的信息,并进行简单的推理。知识图谱是否能帮助模型解决复杂的问题。
-
第二个工作,尝试迁移到多模态。如果给定更多的数据集,比如视觉语言或网络数据,是否可以训练模型,使其根据不同的 Query自动地选取出更最相关的观点(Points)辅助式获取答案。
-
第三个工作,是否可以利用大语言模型动态的生成最适合解决某个问题的小程序。基于这个小程序调用不同的工具,解决需要上网搜寻或爬取信息的较难的问题。
02
OREO-LM: 用知识图谱推理来增强语言模型
1.为什么想使用知识图谱
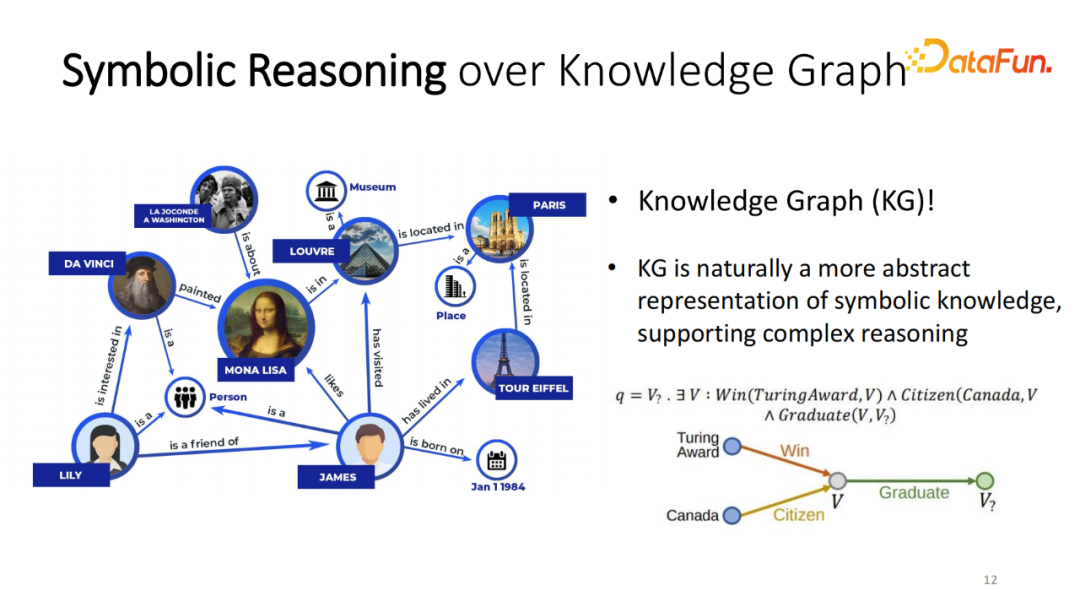
介绍基于知识图谱增强语言模型(OREO-LM)。为什么想使用知识图谱呢?虽然知识库已经被研究了多年,但它也有一定的局限性,比如不完整,它包含的信息可能只有节点信息。但它也有显著的优势,比如使用一个很大的知识库或整个 Web 作为知识的来源。相对来说,知识图谱相比这类知识库较为轻量,它已经将世界的知识抽象成离散的,并且每个节点使用少量的信息,轻量并简单的知识表征形式。因此可以非常容易地将其和部署的大小模型存储在同一个地方,快速地调用并执行。由于它的离散形式、图结构,如果处理带有逻辑推理或多跳的问题,知识图谱可以非常容易处理该问题。例如“哪一位是图灵奖获得者,同时出生在加拿大”,可以在知识图谱上获得对应的结果。

推理过程可以抽象成简单的逻辑推理的表达式,之前已经有非常多的借助知识图谱或其他的知识库来增强语言模型的工作。一种非常简单的方式,比如给定知识图谱,可以预训练一个 KG 嵌入,知道每个实体的向量嵌入的表征,然后将该表征加到词嵌入。这种方法一定程度上将知识图谱里的某些信息让模型获得,显而易见,这种增强的方式并没有充分地利用图谱的推理及交互能力。模型并没有真正的在图谱上进行游走,找到二跳的路径,只是寄希望于向量嵌入能够记住相应的图里的所有的信息,显而易见,其是有缺陷的。
2.知识推理与语言模型结合
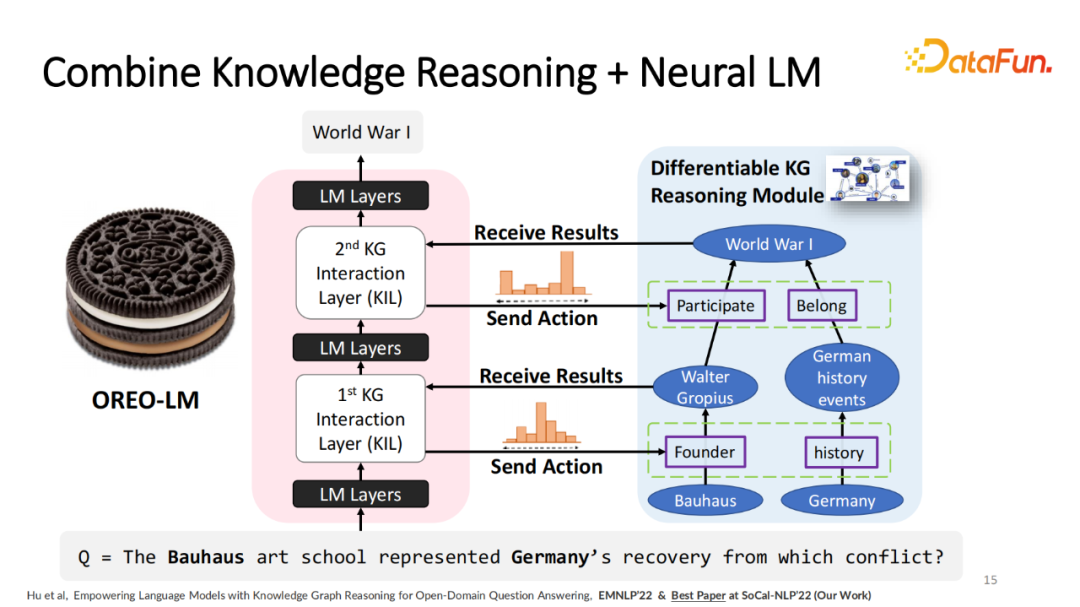
我们的工作当中希望模型能够更自由地和外部的知识图谱进行交互,并且尝试在图上进行游走与推理。实际过程当中,给定义预训练的语言模型,比如T-5将模型所有的参数冻结或微调。预训练的模型将它切成若干块(Block),比如说语言模型编码器(Language Model Encoder)切成3块。块与块之间,加入知识图谱交互层(Knowledge Graph Interaction Layer)也就是语言模型知识图谱的交互层。在每个交互层之中,提取出比较难,需要从知识图谱里面获得信息的 Query,将这些 Query 以嵌入形式发送给 KG,这样 KG 就能够根据 Query 进行游走,比如从 Germany 出发,走不同两条路径得到新的节点。然后将该信息通过嵌入形式传回语言模型,这样的交互可以重复多次,从而让模型处理需要多跳才能解决的问题。我们将交互层加在语言模型块中,所以将模型称之为 OREO-LM,交互像是奶油,模型就是饼干。
3.介绍语言模型是如何运作
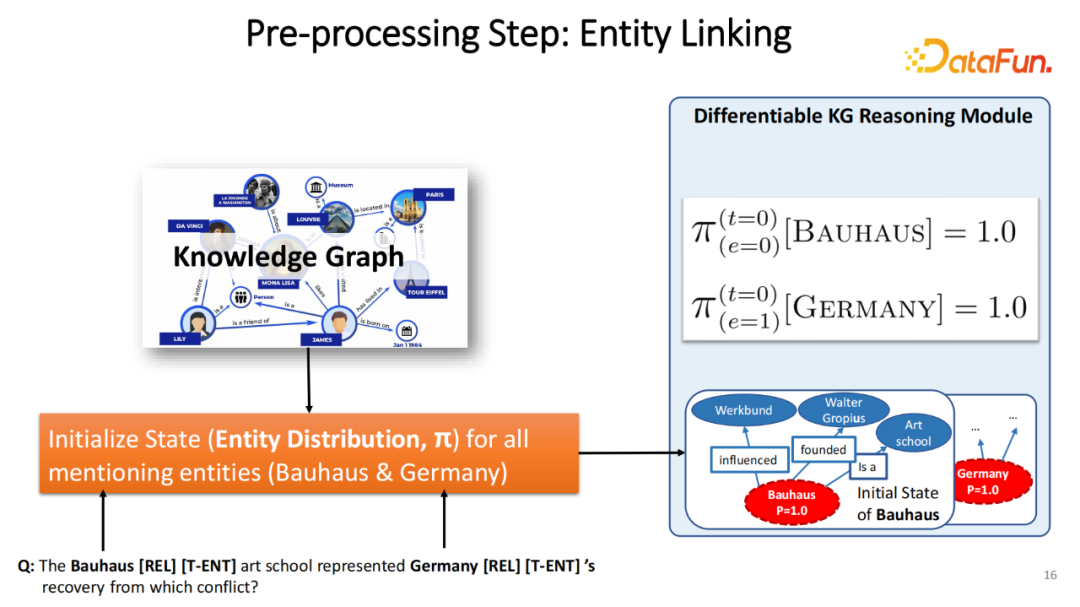
我们的工作核心是在图上进行游走。很自然地在最开始的时,需要获得问题里最基础的图上的表征。首先使用已经预训练的实体链接(Entity Linking)模型,找出 Query 中有哪些基础的实体。有多少实体,图谱初始化多少个推理状态(Reasoning State),推理状态的初始化100%停留在最初始的实体上。
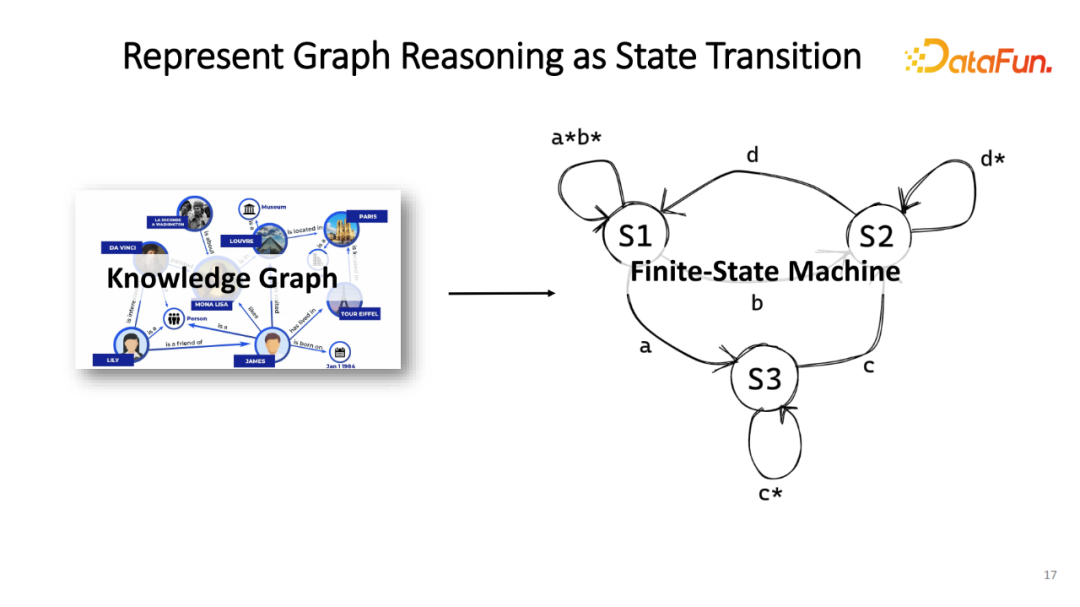
之后,需要让模型能在图谱上进行游走。在这篇工作当中,游走的表征就是将图谱的推理表征成有限状态机(Finite-State Machine),即每一个阶段维持新的实体分布,而每一次更新过程相当于在图谱上做一次实体分布的更新。

为了实现这一点,每一次更新过程之前知道下一步更新时往哪个方向走,即在当前情况下,下次游走的关系(Relation)是什么。在这份工作当中,把输入表示成分布。假设1000维度的概率分布,每个维度表示预测要使用该关系的概率。根据这关系分布游走,也就是重新估全图上每一条边的权重。比如开始有100%的概率在 Bohos 节点,而 Bohos 有三条出去的边(Influenced、Founded和is a),假设 Founded 有最高的概率,会将它赋予最高的概率的权重。在下次更新过程当中,会以更新过的图上的权重来做游走。那么更新之后最高概率的节点就变成了 Walter Gropius。整个过程可以被表示成一个简单的在图上的随机游走的形式,因此称该过程为情境化随机游走。这个步骤是完全可微分的,如果在数据集上训练,模型可以直接传递梯度到关系和实体的模块当中。在这个框架下如何获得关系?在传统的工作中,首先识别出问题中需要哪些最基础的关系,可以先通过解析方法把它转成一个程序,如果希望用神经网络的方法和 KG 进行结合的话,并不能预先获得该信息。


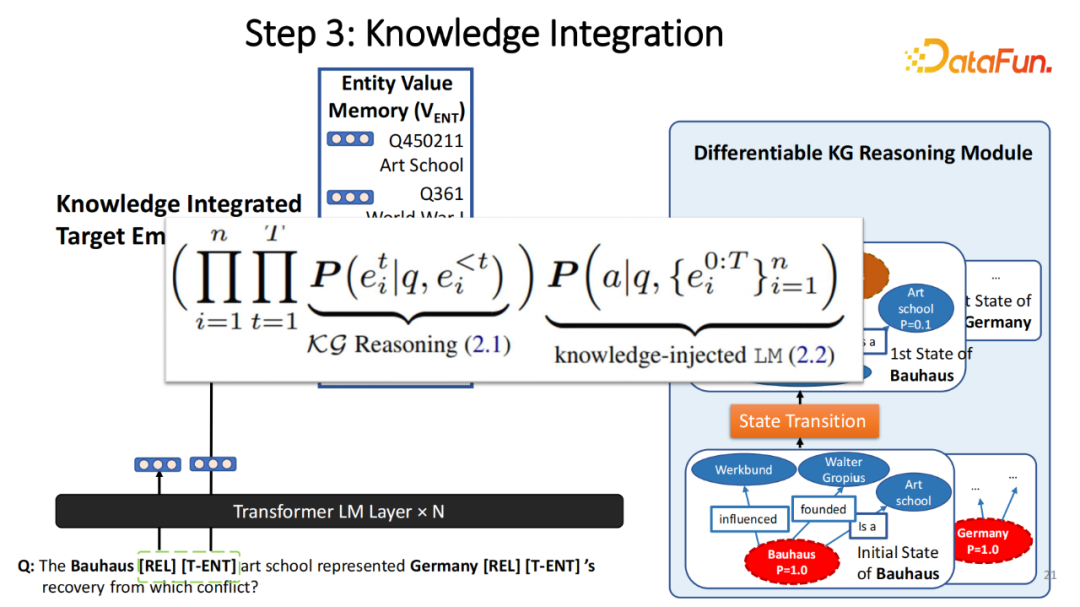
那么如何得到该信息?实现方式是在识别出的每个实体后,增加两个特殊 Token(RET、T-ENT)。这两个 Token 是语言模型和外部的知识图谱进行交互的条件。在若干个语言模型块之后,会将 RET 的嵌入输出,将它与预先得到的关系键存储器(实体嵌入,关系嵌入)进行相乘来得到预测的关系分布。所有的关系 REL 的输出和关系存储器都是可以被训练的,因此将模型预测出的关系输出发送给 KG,KG 进行一次的游走。在每次游走后,得到更新的实体分布,将这个信息传送给模型。一种非常简单的方式就是将它加权平均于一个实体存储模块(Entity Memory),每个实体还是表征实体嵌入。这种方式它非常简单粗暴,但有缺陷,尤其是表征有多个实体的集合。如果集合当中包含了两个离得特别远的实体,比如一个形容一个人、一个建筑,那么这两个的平均值并不一定是最合理的实体表征。在我另外的一篇工作基于快速逻辑的方法中,选用了 Fast set 表征 set 嵌入。在这工作里,为了简单实现,使用加权平均数。通过实体分布的加权平均,得到更新以后的实体嵌入,直接将这嵌入加在目标实体之后。通过这种模式,可以非常容易地将更新后的知识传输给模型,并且整个 Query 和检索结果的所有过程都是可被微分的。
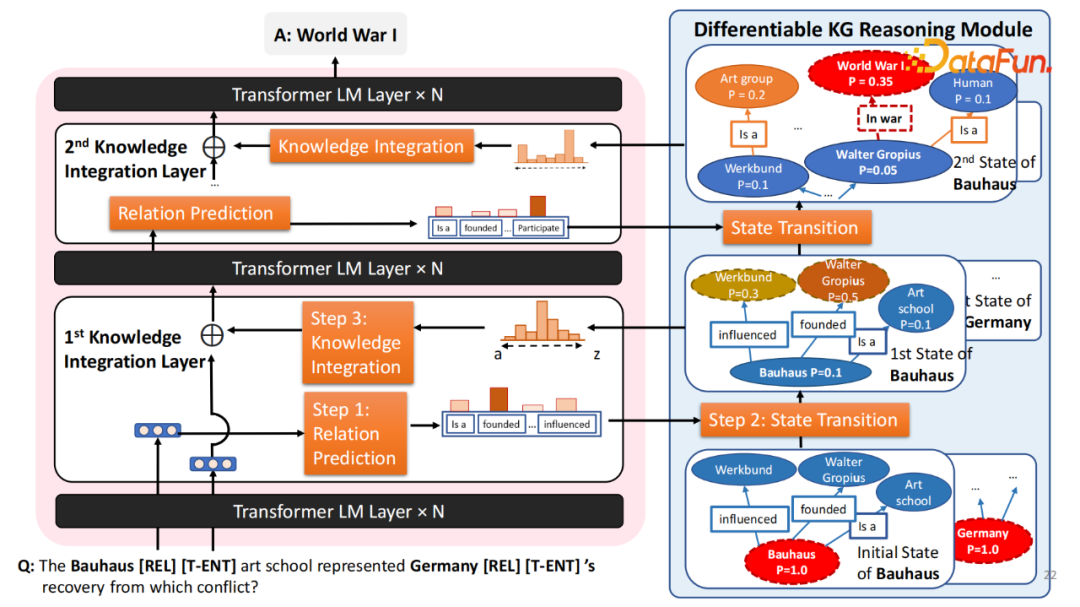
这整个模块可以被重复多次。在第一次的 State transition (推理)之后,在经过若干个语言模型的内部的推理后,增加第二次交互层就可以实现多跳的推理。比如在第一跳的过程中得到 Walter Gropius,在第二跳知道 Walter Gropius 参与了哪些事件?发现预测和之前第一步的不同,第二次的最高关系变成 Participate,这样就可以得到最终的结果。
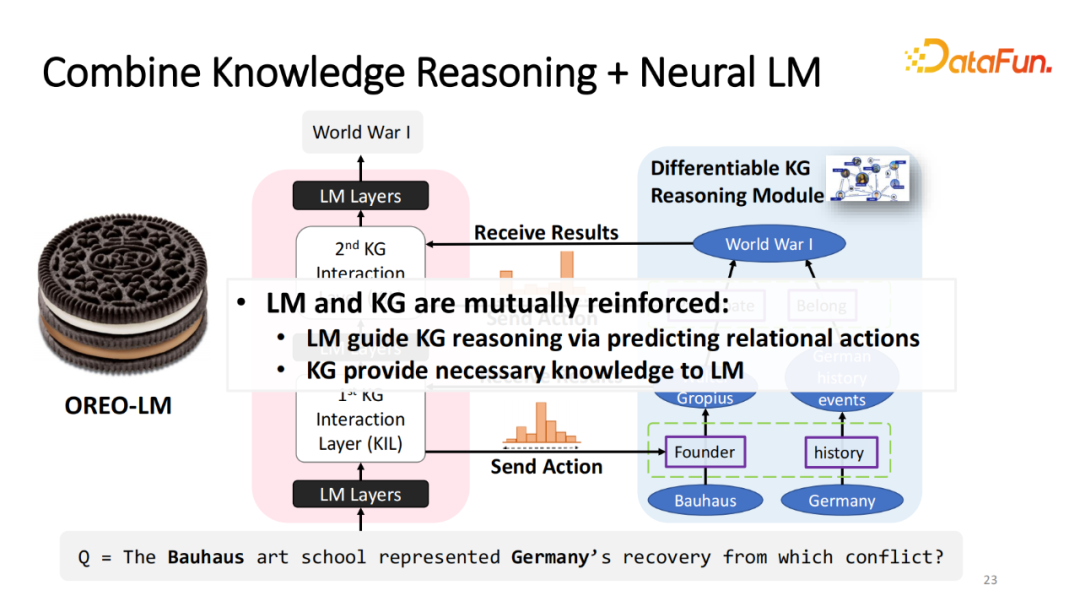
在整个过程中,语言模型和知识图谱并不是互相割裂的,两个模块是互相帮助彼此。语言模型能够帮助知识图谱更好地预测,在图谱上应该怎么样游走来预测最合理的关系。同理反之,知识图谱告诉语言模型解决这个问题需要哪些相应的知识。因此这两个模块可以有机的进行结合。
4.实验结果
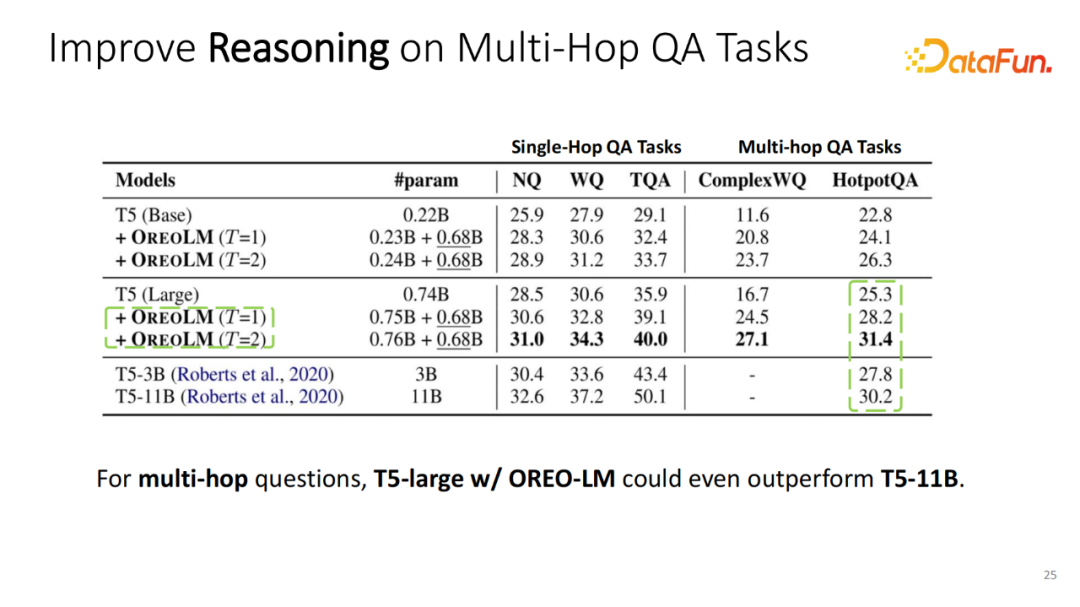
实验选用 T5 作为基础的语言模型。在 T5 的基础之上增加 OREO-LM 块。尤其在 Multi-hop QA 上,这种增强模式有非常大的模型性能提升。

同时除了能够提升模型的性能以外,这种显式的知识图谱推理也能帮助更好地解释模型的决策。比如问“where was the Lisa kept during ww2”模型不止准确的回答“the Ingres Museum”,同时还能将模型预测的关系进行top1的选择,了解它们通过怎样的路径得到最后的结果。比如说 Lisa 的创始人在哪里,以及 war 2发生在哪里?通过这两条路径,能够更准确的得到最后答案,并且理解模型为什么会输出该答案。

在之前的实验结构里展示了 OREO-LM 能够提升模型的推理性能。但是,该性能提升是否真的来自于知识图谱的推理,为了验证这一点,做了一个蛮有意思的实验。首先,选择知识图谱上的非简单的 Triple。这些 Triple 只要能够找到对应的知识图谱上的一个实体(能非常容易获得回答)。但是,为了验证模型有一定的推理能力,不希望知识显式存在 KG 里面。我们将对应的某一种类型的知识全部从 KG 里删除。比如将所有包含 Capital Of 的边全部从 KG 里删除。如果模型还能回答对应的问题,边(Edge)是它已经记住的知识,或它必须从图谱上进行多跳的推理,或选择其他的知识和边来辅助回答模型预测出这一条不存在的边。
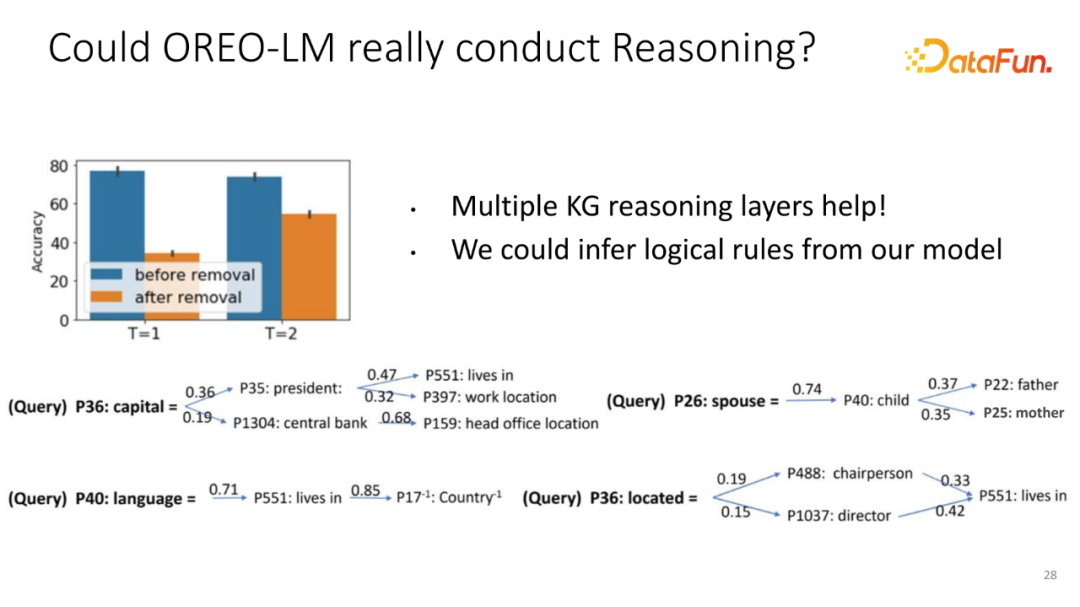
实验结果,如果增加多个推理模块,在删除知识的边之后,性能下降会越来越小。某种意义上,在显式的知识图谱上推理确实提升模型的鲁棒性,尤其是对于在知识图谱缺失了很多信息的情况下面,它还能通过多跳来辅助回答相应的问题。为了进一步验证这一点,我们将不同的删除掉的 Query,模型到底选择哪条多跳路径来展示成了一个树的形式。每条路径可以简单的理解为单一逻辑规则。比如想预测首都在哪里,模型的选择路径:先知道这个国家的总统在哪里,总统是谁,这位总统居住在哪里或者哪个地方工作,这条简单的路径可以用来辅助预测这个国家的首都是哪里。同样预测一个人的伴侣,他工作在哪里或他居住在哪里,或他使用怎样的语言,都可以通过其他的路径去预测。

实验和结果总结,如果想增强神经基础模型,仅使用最基础的 Symbolic Operator。在这份工作里,只是最基础的知识图谱游走,就已经取得很不错的性能,哪怕使用较小的模型参数,也能取得很好的性能。为了让整个框架能真正的 Work,最核心的一点是可以端到端训练,不需要中间的任何的标注,只在无标注得数据上就能学到如何真正的推理。如果想训练而不需要中间标注,让推理过程(尤其是 symbolic 推理)变得可微分是一个最关键的步骤。通过这种方式,模型可以直接在每个下游 QA 数据集做预训练或端到端训练,这是让模型能够真正 Work 的关键。
03
REVEAL: 用多个知识库检索来预训练视觉语言模型

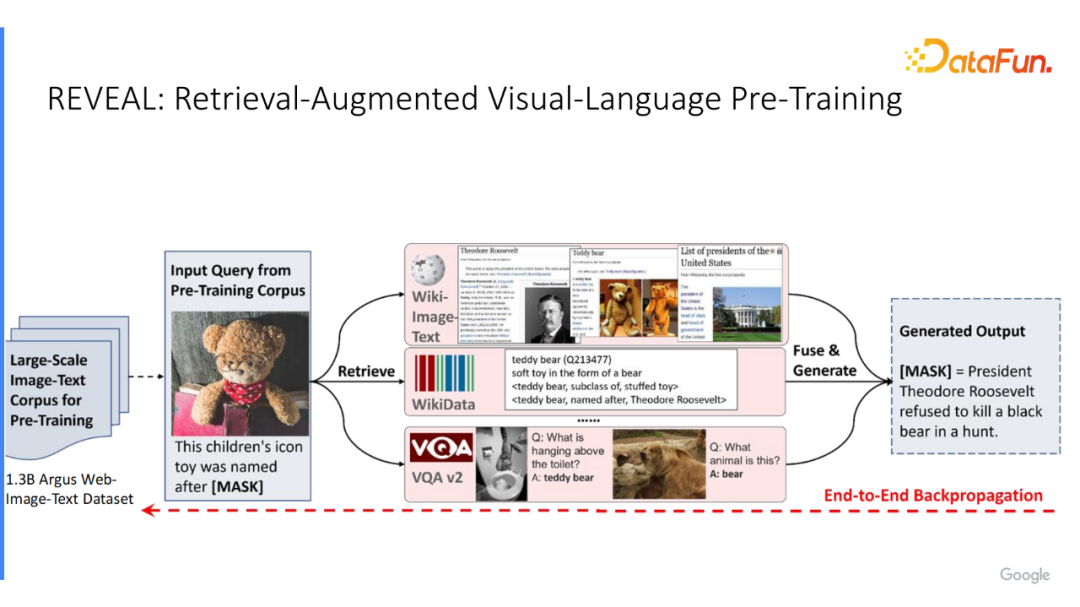
以上工作可能局限于纯文本领域,并使用了知识图谱,我们知道非常多的知识源,比如网上的文本或知识库。在 REVEAL 介绍如何让视觉语言模型使用多知识源?比如“这个小玩具和哪一位美国总统有关联?”,从维基百科中获得美国的总统和泰迪熊的信息,找出相应的 Triple,甚至可以从 VQA 数据集里找到相关的问答对。统一将所有选取出来的相关的知识合并在一起。工作的目标是让模型能选取出来自不同知识源和问题相关的知识;使视觉语言模型具备更好地回答较难问题的能力,能端到端训练;只在一个数据集中学习检索怎样的信息,怎样将它们给合,并且回答相应的问题。

这类需要外部知识的问题,不仅在纯文本里很重要,在多模态中也重要。最近几年大家越来越关注外部支持的 VQA 答案,比如“在饭里哪部分拥有最多的碳水化合物?”。这样的问题,不仅需要模型能够理解图片里出现什么样的 Object 以及它们之间的关系,还需要一定的外部知识。比如,米饭是一种主食,而主食包含了最多的碳水化合物。我们的解决思路是让模型能够有能力和外部的知识库进行存储模块查找。将所有的外部知识统一编码在存储模块里,传送模型能够选取相应的 Token 和知识的结果。
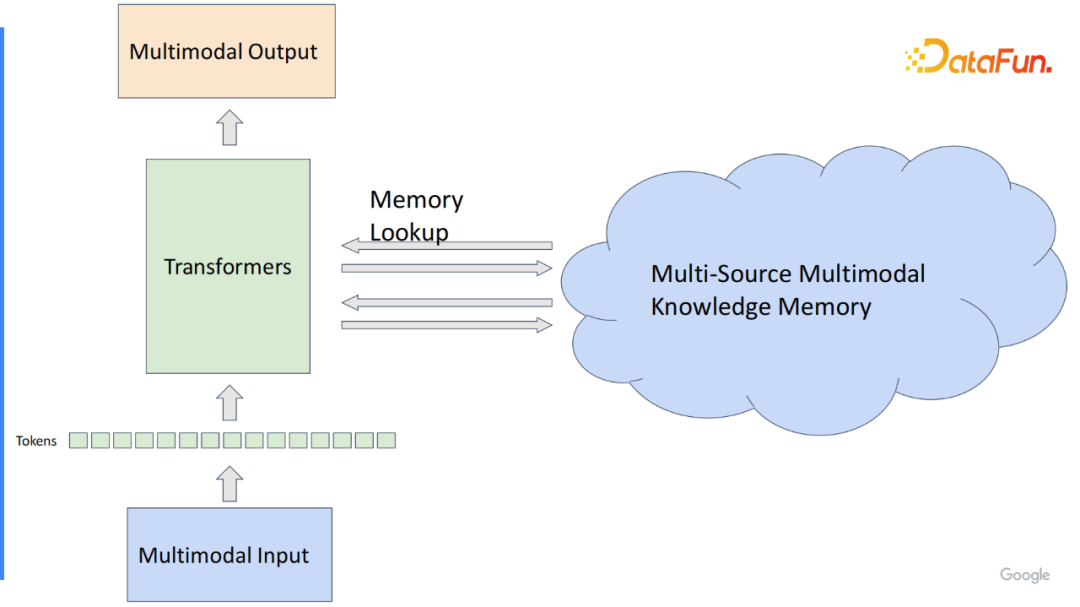
为了实现这一点,需要将不同的 Multimodal 变成 Multi-Source 的 Multi-memory 编码到统一的存储模块里,它的键和值的表征需要完全一致。简单的做法是选用已训练好的视觉语言模型,比如 Multimodal 的基础模型,利用它将视觉语言的输入转化成序列 Token,并将其全都存储在大的存储模块里,动态地选取,显而易见是可行的。当文本非常长(图像本身包含非常多的信息),如果将它全部压缩在一个序列 Token 里面,可能会有几百甚至上千个 Token,每个 Token 是一个嵌入。如果存储在在线服务里,不太可能存储非常多的知识,最多存储几十万个,不能到几百万甚至上千万,更不用说上亿。
1. 多模式语料库中存储模块的构建

为了解决这一点,我们选用感知模型(Perceived Model),也就是基于 Transformer Decoder 的框架来压缩每个知识的实体。比如,原始有1000维度的输入序列,将它输入感知模型,该模型可以预先设定好最终保留几位的知识 Token,如果想保留16位,随机初始化16位的输入,将它作为 Decoder 的输入,压缩的信息作为 Decoder 的 Key 和 Value,然后将它压缩成16维的 knowledge value。
通过这种方式,可以将来自不同知识源的数据集里每个实体表示成一个 key-value 对。key 就是单一嵌入,而 value 是压缩后的16维或32维的 Tokens 列表。压缩后它大概只需要十几维的嵌入来表示的知识实体。这统一的存储模块(Unified Memory)可以存储百万甚至千万。如果实现云服务的话,可以实现接近上亿或者更多的数据集的增强。
2. 端到端训练检索模块和问答模
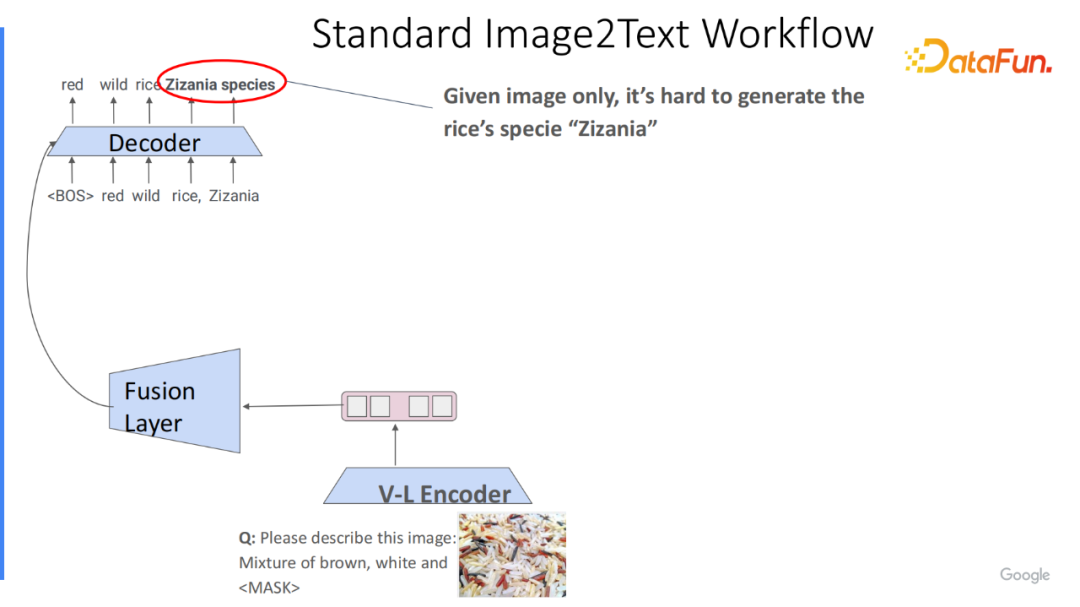
接下来,将展示如何去借助统一的存储模块来增强已有模型。首先,展示最基础的图像到文本的工作流程。给定图像和 Prompt,生成完整的说明文字,可以把它的前缀(prefix)也作为模型的输入,来补全剩下的信息。最简单的方式是用V-L编码器把它转换成 Tokens 列表,然后输给解码器自回归生成后面的信息。示例,描述图片里有什么东西,标准答案里包含菰属(Zizania 物种)。这类长尾的单词,对于较小的语言模型来说,比较难理解且记住。
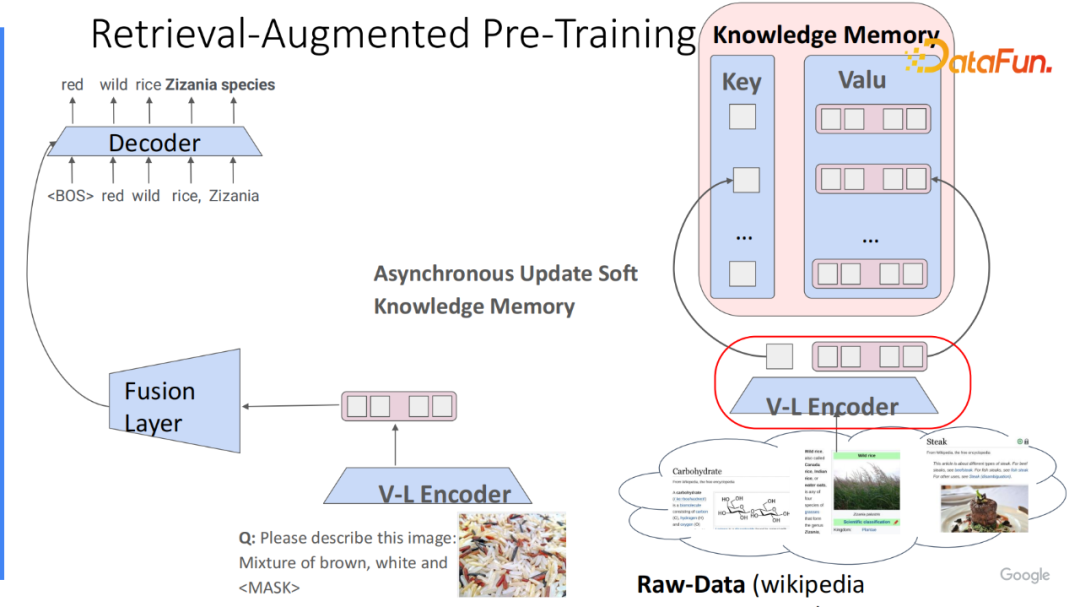
如何使用外部的已有的统一的存储模块来补全信息?现在已有编码好的统一的存储模块且可以动态地去更新,因为每次 V-L 编码更新后,都会重新的更新 key 和 value。
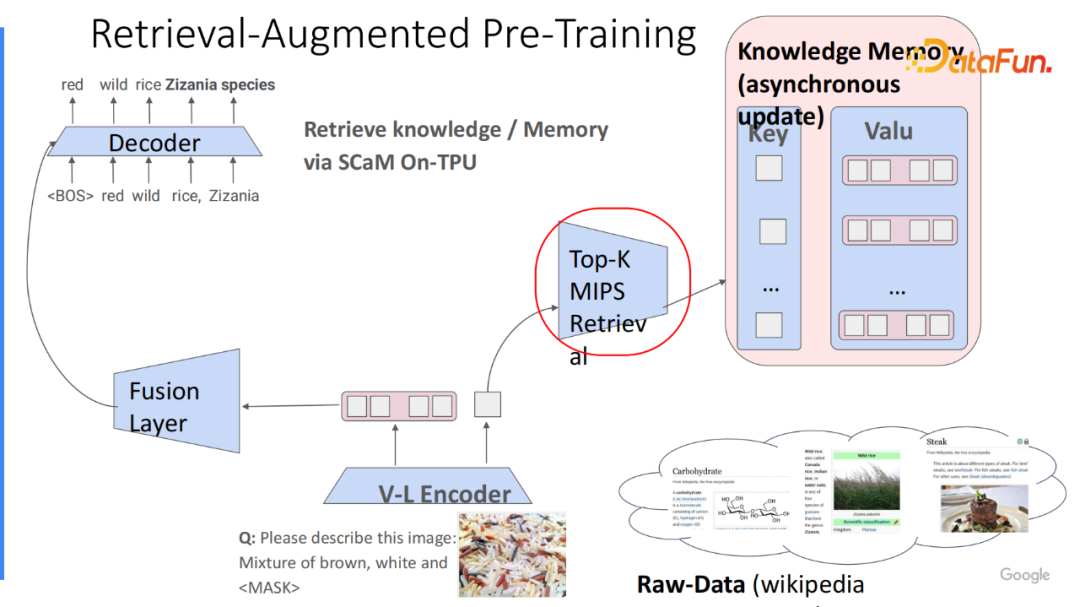
在线上处理过程中,会根据已有输入作为 Query 嵌入来选取出和该 Query 最相关的若干个,比如 Top k 个知识实体,将它的 value 取出。在选取过程中,因为知识存储模块包含来自不同的数据集,而对于不同的 Query 最相关的知识实体的数据集可能各不相同。因此先通过语料库门控(Corpus Gating)选取出最相关的数据集,在该数据集中选取 k 个最相关的结果及对应的索引(Index),并选取出相应的 k 结果。

由于最大内积搜索算法(Maximum Inner Product Search)相应的实现,已经有非常多高效的 MIPS 的加速算法,比如基于哈希或基于聚类。这整个算法复杂度其实是 On 于存储的数量,是非常高效的。

在选取出 k 个结果后,将它和已有的输入进行融合。最简单的方法是,直接将每个知识实体拼接在已经编码好的语言输入之后。但是,如果希望模型能端到端的训练检索的话,它并不能够直接获得训练符。因此,我们实现了一个非常简单的技巧,在计算得到检索分数后,将分数承载在每个选取出来的知识实体之上,我们称之为 Attentive Knowledge Fusion。
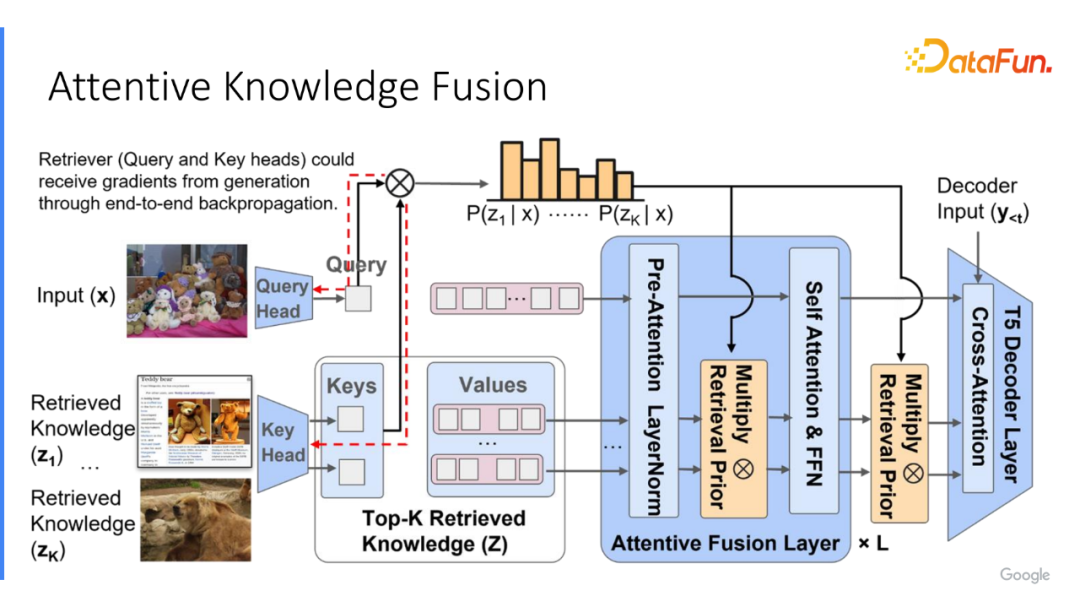
实现如下,在计算每个 Query 和知识实体的注意力分数时,将这两个嵌入进行乘积,它表征了模型预测出每个知识实体有多相关于每个输入,如果想进一步优化这点,需要判断这个能力是不是真的对回答问题有用,那有什么信息能更好地辅助获得这个过程。隐式的过程是模型计算出来的注意力分数,即实体有多好的帮助模型回答相应的问题。为了使模型能够得到这过程,将计算出的检索分数乘在每次计算自注意力之前,归一化之后。假设有6层的注意力编码,会将信息承接6次,让它充分地获得相应的 supervision signal。
通过这种方式,如果在训练过程中知道某个知识实体非常有用,它对应的注意力分数需增加对应的比率得分,在下次更容易被检索。

我们在描述图片数据集上进行预训练,将预训练后所有的知识存储模块直接冻结,迁移到对应的 VQA 数据集,比如在 OK-VQA 上实现了非常好的结果。
3.实验结果
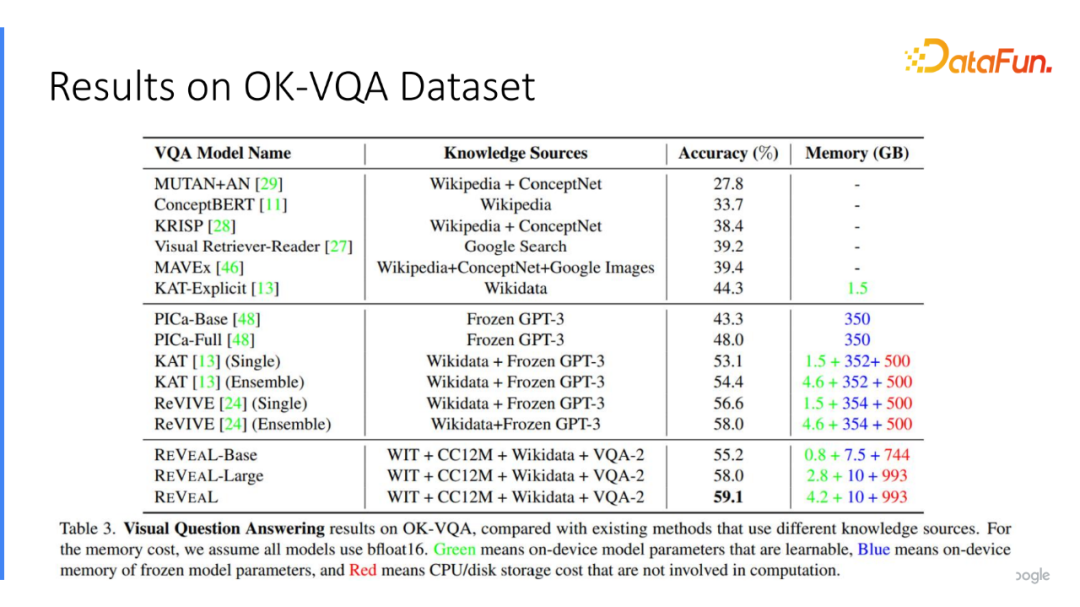
在文章中选用4个不同的数据集:WIT、CC12M、Wikidata、VQA-2。将这四个数据集编码在统一的存储模块中进行预训练,并在 REVEAL 里面实现非常好的结果。比如 PICa 和ReVIVE 都使用 GPT-3 的模型作为显式的知识库。值得一提的是,在我们的模型中只用了轻量级的 10B 存储在模型当中,不需要存储 350B 的大模型,已经能取得比大语言模型更高的结果。

这里展示模型预测的知识对。比如识别“飞机的航空公司是什么”,模型根据 LOGO 准确地识别出来“加拿大航空公司”,然后找到其相关的两个说明文字,并找出答案。

进一步,相对更难的例子,例如“这个巴士来自于哪个城市”,人比较难以回答。但通过模型可以找出和巴士非常相似的同款设计风格的来自于旧金山的公交系统。模型最后准确的回答它是来自于旧金山。同理,还能找出其他的需要一定的外部知识补全才能够回答的案例。

同样的,这个模型并不仅仅能处理 VQA 的任务,对于加说明文字的数据集也能取得非常好的结果。

除了取得更好的性能外,还希望检索方法有更好的适应能力。尤其基于 GPT 的模型,通常是收集2021年前获取的数据做预训练。但对于最近发生的新闻或信息,没有办法高效地更新。我们在实验中,测试它对没见过的知识,是否有很好的适应能力。因此在预训练和微调过程中删除一定比例的知识实体,比如随机的从知识代码里删除50%的信息,在预训练之后,仅在最后的推断阶段将该信息给补上。

测试发现,如果全部删除掉,它的性能下降非常大,上图蓝色线。但是补全后,结果和开始用100%的信息相差无几。这种结果某种意义上说明,即便在预训练和微调阶段并没有见过相应的知识,只要在最终推理阶段将知识进行补全,或有最新的知识加入到模型,其有能力去选取出相应的实体来回答问题。

总结,我们提出了 REVEAL,其包含了一个非常高效的知识检索,它可以使用不同的知识源,每个知识源来自于不同的方式,不同的表征。利用所有数据集来帮助回答相对较难的,需要一定知识的问题。我们通过一个非常简单,但有效的注意力融合的技巧,使 REVEAL 直接在大的语料库上预训练,而不需要中间的标注。
04
AVIS: 让大模型用动态树决策来调用工具

以上两份工作,选用的语言模型都是相对较小的 T5 基础模型。随着 OpenAI 发布了 GPT-4,很多的热潮慢慢迁移到我们能不能使用大语言模型解决各种各样的问题,大语言模型有它自己的缺陷,例如它并不能够很准确地回答逻辑推理的问题,有没有可能让自由地调用外部的工具和知识库来辅助它解决。通常来说,是不太能直接获得大语言模型中间表征的参数,因此在这个工作里我们并没有真正去实现可微分的训练。相应的我们更多的是使用基于 Prompt 的方法让语言模型学会调用相应的工具,和如何利用它解决较难的问题。
1.外部工具
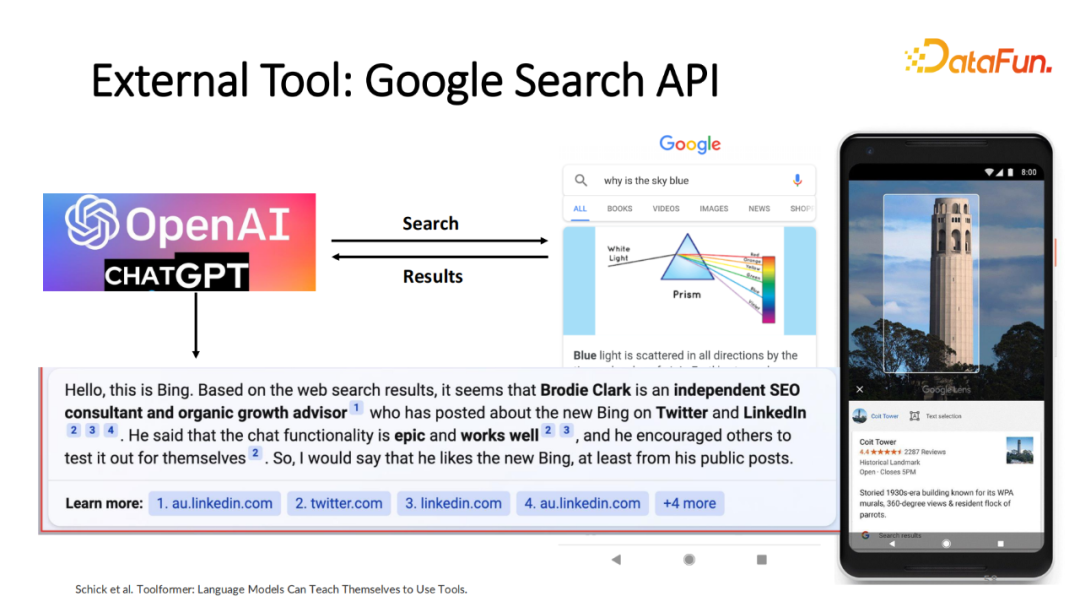
比如尝试让基于 GPT 的模型或者其他的大语模型调用 Google 的搜索工具,包括文本搜索工具和视觉搜索工具 Lens,它能够识别图片里的 Object 和它相关的产品或描述。通过它的输出回答,不仅仅能给出最基础的回答,还能标注出每个回答来自于哪个知识源,帮助人类检验回答是否准确。

对于需要数学推理的问题,可以利用数学计算器,比如 Wolfram Alpha,是非常强大的科学计算器,可以辅助回答较难的需要一定的数学推理才能解决的问题。
2.外部工具增强的大语言模型
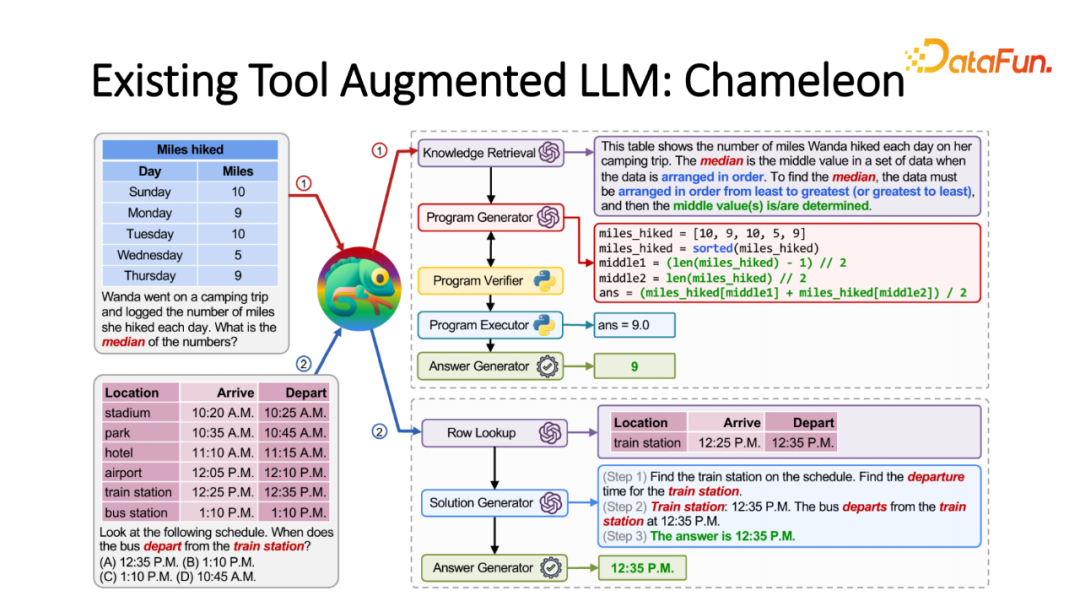
在我们工作之前,其实已经有非常多相应的工作,比如给定较难的问题,利用语言模型拆解成基础工具调用的程序,通常都是 plan-then-execute 的框架。先利用语言模型作为规划模块将复杂 Query 转化成小的程序。而每个程序就是调用哪个 API,获得怎样的结果,回答怎样的问题。最近效果非常好的例子是,Chameleon 接受不同的模态的问题,将它拆解成 API 列表。比如知识检索或程序生成器分别调用特定的外部 API 回答相应的子问题。

另一个受到关注的工作是来自于哥伦比亚大学的 ViperGPT 的工作,同样也是生成 Python 基础程序。比如回答“how many muffins can each kid have for it to be fair?”首先计算出图片里有多少松饼,有多少小孩,计算出数量后,确定是否整除,以回答对应的问题。
3. plan-then-execute 的框
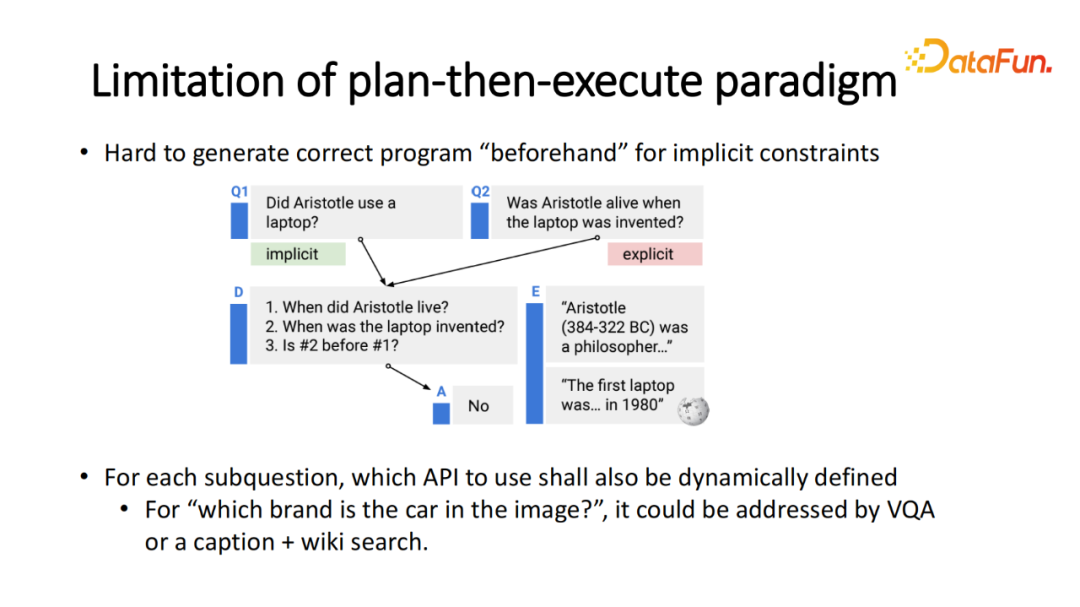
这类工作,通常按照 plan-then-execute 的框架。先利用大语言模型的规划模块将问题拆解成子问题列表,而每个子问题可能对应一个 API,根据生成出来的程序分别去执行。当然每个执行过程也可以使用大语言模型。但该框架也存在问题。比如其默认问题本身已经包含足量的信息,这样它才能生成非常完整的程序。
NLP 领域里已经有人研究,如果问题不完整,包含了所谓的印象深刻的推理,比如问题“Did Aristotle use a laptop”,如果拆解成子问题的话,首先需要知道 Aristotle 出生的年份,以及这年份 laptop 是否被发明,最后计算两者的年月的顺序。中间潜在的推理并没有被显式地表征在问题里,需要在执行过程中隐式的地生成出来。就像下围棋,下第一步时并不知道100步后会怎么执行。这是第一个很大的问题。如果在最开始就生产出程序,便不能根据执行过程中的反馈来动态更新程序。第二个问题是,某时刻执行过程不确定。比如回答子问题“图片里面的汽车来自于哪个品牌?”回答该问题可以用不同的工具解决,比如简单的 VQA 或生成说明文字再维基搜索。实际上,我们并不知道最终是哪个工具准确地回答该问题。可能是 VQA,但其给出模棱两可的答案,并不能真正地满足要求,这时就切换到另一个工具。但如果事先已经存在固定的程序话,就不存在自由切换中间执行过程。
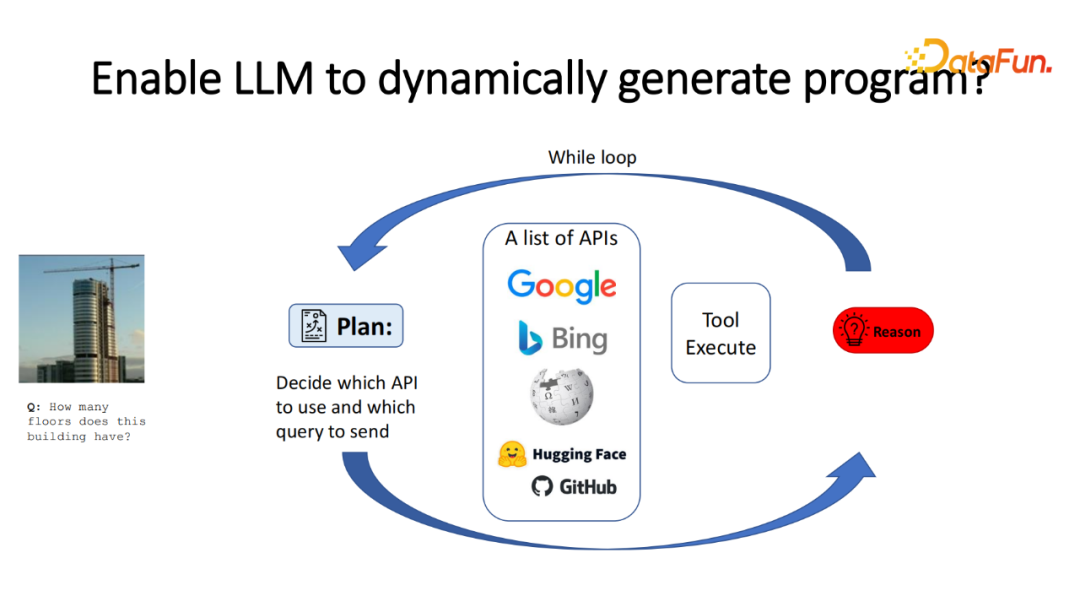
因此,在实行过程中希望能更自由、更动态地让模型做规划以及执行。我们实现了大致的框架如上图。两个模块,一个规划模块预测出每个阶段选用哪个 API,并且发送对应的 Query,根据这个信息选择并调用对应的 API,得到对应的结果。在该结果之后,判断该结果是否正确地回答相应的问题。如果没有,需要再次回到之前的结果。如果某条路径没有回答,需要回溯到之前的节点,再次进行规划;如果回答了子问题,需要进一步决策;如果已经回答了完整的问题,则提前结束搜索过程。

上图展示如何利用整个框架解决问题。比如“How many floors does this building have?”首先,模型先预测出图片里有哪个 Object,并进行选择。根据选择的 Object 做图像搜索,找出哪些图像和Object比较相似,而图像搜索的过程中得出其是 Bridgewater Place。在推理过程中获得其确实是答案,回答子问题。但还要回答它有多少层,这则需要一定的常识或领域知识,不是模型本身已存在的记忆。因此,需要借助网络搜索,比如 Google 或 Bing,回答对应的结果32。
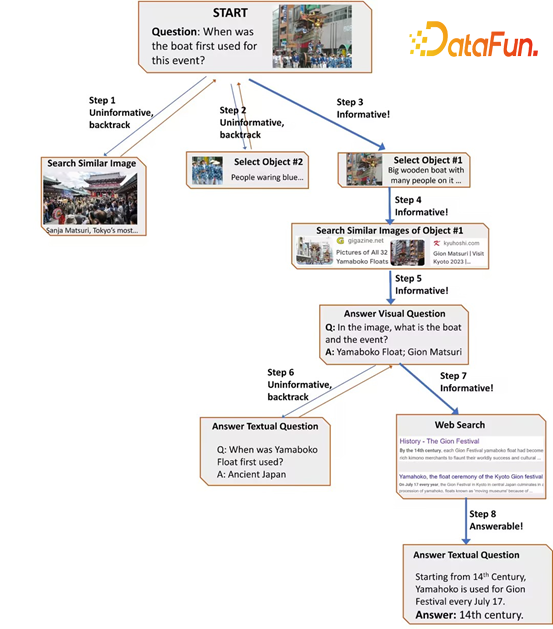
类似的例子较多,每个例子每次中间结果生成的 API 都不一样。有时选择的路径无效,需要选择另外一个目标,我们的框架可以支持的动态选择。
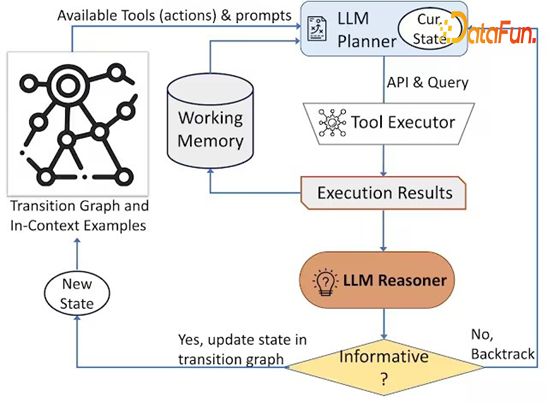
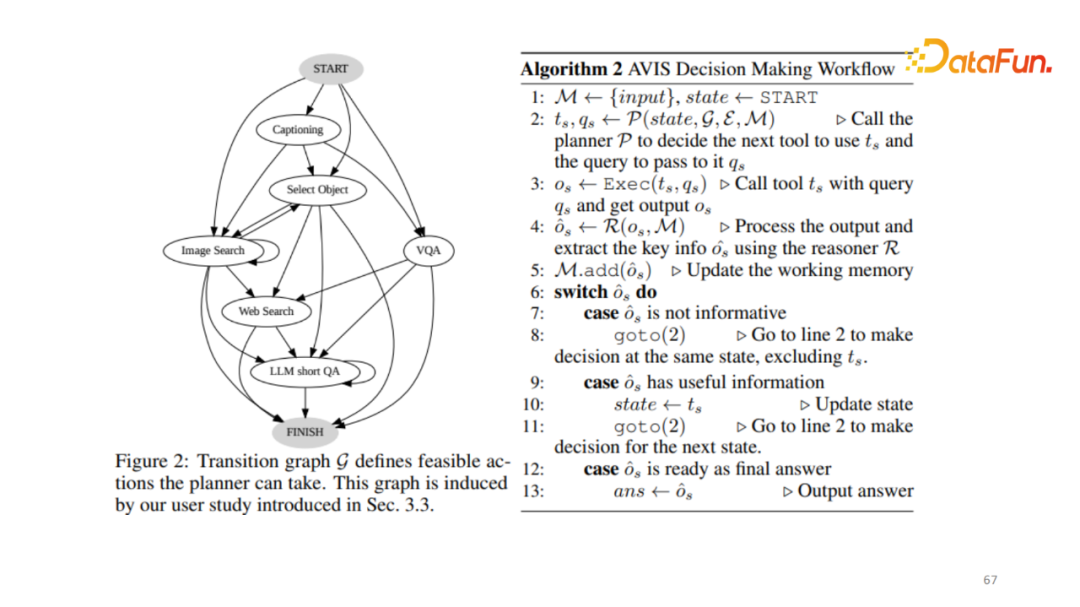
追踪框架如何实行,包含以下几个模块。首先,获得基础的 M,最开始只保存输入数据,同时存储 State 在初始节点。在规划阶段,根据当前的 Memory 决定下一步选择怎样的 API 及其对应的 Query。执行结果输入给 Reasoner,其判断该结果是否有用。将这个信息加入到 Working Memory 后来判断 Reasoner 的结果是没用、有用还是已经回答问题。如果没用,回到第二个结果,并把 Working Memory 踢出,重新进行递归;如果包含有用的信息,更新当前的 State;如果已经回答了对应的问题则跳出。

这个框架的核心在规划模块,也就是每个阶段选用哪个 API,以及发送怎样的 Query。实现这点,可以使用 GPT 4 直接做 Zero Shot 的预测,或提供一定的上下文来进行预测。如果 API 的数量达到几百上千,那Prompt尤其是输入给模型的例子会非常大。现在大语言模型其实并不能接受非常长的文本输入。随着使用的API的数量增多,它并不一定能适应长的 Prompt。因此在这份工作里借助了人类知识,即人工标注者在 VQA 数据集上进行简单的标注,作为人类如何使用这些工具来回答相应的问题,在收集了几百个结果后,构建 Transition graph。人类在每个节点或当前情况下会选择使用哪些工具?一般情况下,不会直接进行网络搜索。因为,开始并不知道图像包含哪些信息。通常来说,最开始先用 Captioning 模型或 Object 选择模型找出最基础的信息。根据人工定义好的 Transition graph,根据当前的 State 确定下一步有哪些可操作的 Action state。这个 Action 的数量肯定会远远小于所有的 API 列表。比如全部有100个,下一步可能只需要10个。然后根据选用的10个和之前人工标注出的 Prompt 动态地生成出最适合当前的上下文 Prompt 输给模型。模型根据动态生成的 Prompt 预测下一步选用的 Action,以及它对应的输给 API 的 Query。
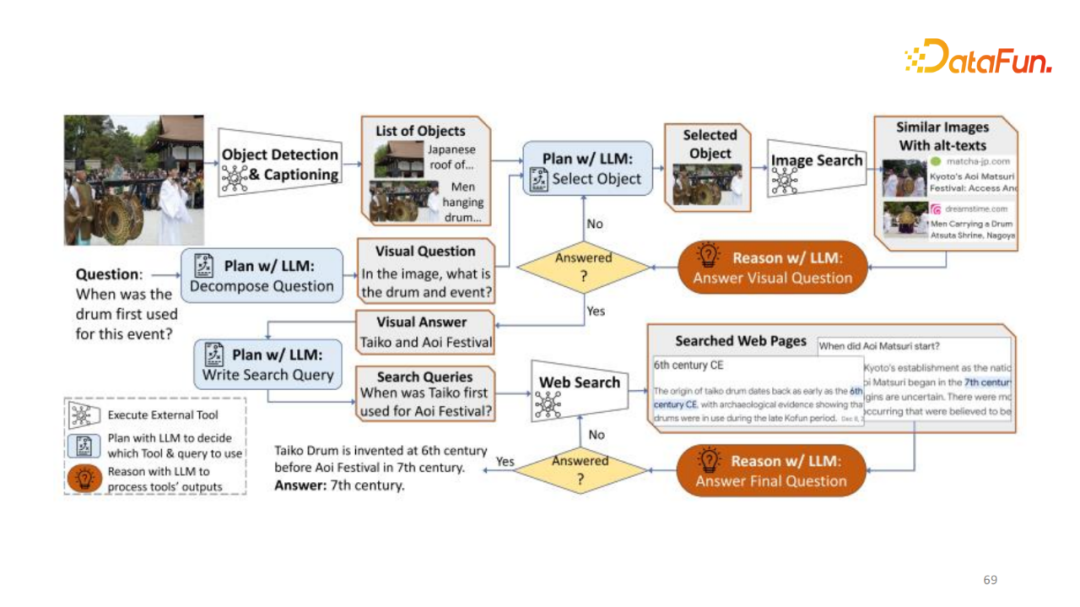
图中展示回答“when was the drum first used for this event?”首先,要了解鼓是什么,以及鼓发生在哪个年代才能回答这个问题。首先找出 object,输入给大语言模型来选择哪个 object 与这个问题最相关,可能会选择错误的object,比如选择第一个,输给 Reasoner 来判断它有没有回答这个问题。如果第一部分选择的信息没有鼓,模型则没有回答正确,那么需要进一步的选择(像搜索树一样直到回答问题)输给下一步规划阶段,该步知道是什么鼓和鼓的事件,通过 Google 搜索回答出对应的问题。
4.实验结果

实验含有最新的 Infoseek 数据集,这是比较难的需要关联信息才能回答的 VBQ 数据集。上图发现,之前非常强的 baseline,比如 PALI 哪怕是微调之后也只有16%。第一个 PALM 的模型也只有12.8% ,这样的结果基本属于没有完全的回答。但是在加了所有工具以及规划阶段框架后,能接近50%的准确率,已非常接近完成数据集一半的问题。在此对细节不做展示,包括 Prompt 如何去设计,如何进行用户实验,大家感兴趣的话可以仔细查阅论文。
最后进行一下总结,一共介绍了三个工作,一是如何利用知识图谱作为知识库,帮助语言模型进行较为复杂推理;二是如何使用更多的知识源帮助视觉语言模型,设置注意力和检索得分的融合,让模型能够直接进行训练;三是给定一个大语言模型,不做任何微调,如何设计一个框架,使其动态地生成最好的程序回答稍微复杂的问题。