目录
编辑
介绍
Huffman编码的原理
信息理论背景
频率统计
Huffman树
Huffman编码的代码示例
数据结构
权重选择
Huffman编码生成
完整示例
完整代码
测试截图
Huffman编码的应用
总结
介绍
在这个数字时代,数据的有效压缩和传输变得至关重要。Huffman编码是一种经典的数据压缩算法,它通过将常见字符映射到短编码来降低数据大小,从而节省存储空间和带宽。本篇博客将深入介绍Huffman编码的原理、代码示例以及实际应用。
Huffman编码的原理
信息理论背景
首先,让我们了解为什么需要数据压缩。信息熵和编码理论是理解Huffman编码的基础。信息熵衡量了信息的不确定性,而编码理论涉及将信息编码为更紧凑的形式。
频率统计
在Huffman编码中,首先需要统计字符的出现频率。这些频率将成为构建Huffman树的基础,我们将使用它们来决定字符的编码。
Huffman树
Huffman树是一个二叉树,其中叶子节点对应于字符,而树中的路径对应于字符的编码。我们将详细解释如何构建Huffman树,选择最小权重的节点,并生成字符的编码。
Huffman编码的代码示例
现在,让我们深入研究Huffman编码的代码示例。以下是一个简化的示例代码,具体步骤包括:
数据结构
首先,我们定义Huffman树节点的数据结构以及编码数组。
typedef struct {int weight, parent, lchild, rchild;
} HTNode, * HuffmanTree;
typedef char** HuffmanCode;
权重选择
我们解释如何选择两个最小权重的节点来构建Huffman树。
void Select(HuffmanTree HT, int stop, int& s1, int& s2) {int min1, min2, i = 1;min1 = min2 = INT_MAX; // 初始化最小值为最大可能值while (i <= stop) {if (HT[i].parent == 0) {if (HT[i].weight < min1) {min2 = min1;s2 = s1;min1 = HT[i].weight;s1 = i;} else if (HT[i].weight < min2) {min2 = HT[i].weight;s2 = i;}}i++;}
}
在这个示例中,我们对 min1 和 min2 初始化为 INT_MAX,以确保第一个节点会成为 min1。然后,在循环中,我们根据节点的权重来更新 min1 和 min2。
Huffman编码生成
我们展示如何从Huffman树生成字符的编码。
void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, int n) {char* temp;int i, c, f, start;HC = (HuffmanCode)malloc((n + 1) * sizeof(char*));temp = (char*)malloc(n * sizeof(char));temp[n - 1] = '\0';for (i = 1; i <= n; i++) {start = n - 1;for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) {if (HT[f].lchild == c) {temp[--start] = '0';} else {temp[--start] = '1';}}// 分配内存并复制编码到HuffmanCode数组HC[i] = (char*)malloc((n - start) * sizeof(char));strcpy(HC[i], temp + start);}free(temp); // 释放临时内存
}
这个示例演示了如何为每个字符生成Huffman编码,将编码复制到 HuffmanCode 数组中,并在结束后释放临时内存。
完整示例
最后,我们提供完整的代码示例,包括输入样例和输出。
int main() {HuffmanTree HT;HuffmanCode HC;int* w, n, i;printf("请输入字符个数:");scanf("%d", &n);if (n > 1) {printf("\n请依次输入每个字符出现的次数,之间用空格隔开:");w = (int*)malloc((n + 1) * sizeof(int));for (i = 1; i <= n; i++) {scanf("%d", &w[i]);}CreateHuffmanTree(HT, w, n);HuffmanCoding(HT, HC, n);// 输出Huffman编码结果DispHuffmanCode(HT, HC, n);// 释放动态分配的内存for (i = 1; i <= n; i++) {free(HC[i]);}free(HC);free(HT);free(w);} else {printf("输入的字符个数非法!\n");}
}
在 main 函数中,我们首先输入字符的个数和权重,然后生成Huffman编码,并输出编码结果。最后,我们确保释放了动态分配的内存,以避免内存泄漏。
完整代码
#define _CRT_SECURE_NO_WARNINGS
#include<string.h>
#include<ctype.h>
#include<malloc.h>
#include<limits.h>
#include<stdio.h>
#include<stdlib.h>
#include<io.h>
#include<math.h>
#include<process.h>
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
typedef int Status;
typedef struct {int weight, parent, lchild, rchild;
}HTNode, * HuffmanTree;
typedef char** HuffmanCode;
void Select(HuffmanTree HT, int stop, int& s1, int& s2) {int min1, min2, i = 1;min1 = min2 = 32767;while (i <= stop) {if (HT[i].parent == 0) {if (HT[i].weight < min1) {min2 = min1;s2 = s1;min1 = HT[i].weight;s1 = i;}else if (HT[i].weight < min2) {min2 = HT[i].weight;s2 = i;}}i++;}
}
void CreateHuffmanTree(HuffmanTree& HT, int* w, int n) {int i, s1, s2;int m = 2 * n - 1;HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode));for (i = 1; i <= n; i++) {HT[i].weight = w[i];HT[i].parent = 0;HT[i].lchild = 0;HT[i].rchild = 0;}for (; i <= m; i++) {HT[i].weight = 0;HT[i].parent = 0;HT[i].lchild = 0;HT[i].rchild = 0;}for (i = n + 1; i <= m; i++) {Select(HT, i - 1, s1, s2);HT[s1].parent = i;HT[s2].parent = i;HT[i].lchild = s1;HT[i].rchild = s2;HT[i].weight = HT[s1].weight + HT[s2].weight;}
}
void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, int n)
{char* temp;int i, c, f, start;HC = (HuffmanCode)malloc((n + 1) * sizeof(char*));temp = (char*)malloc(n * sizeof(char));temp[n - 1] = '\0';for (i = 1; i <= n; i++) {start = n - 1;for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent)if (HT[f].lchild == c)temp[--start] = '0';else temp[--start] = '1';HC[i] = (char*)malloc((n - start) * sizeof(char));strcpy(HC[i], temp + start);}free(temp);
}
void DispHuffmanCode(HuffmanTree& HT, HuffmanCode& HC, int n) {int i;for (i = 1; i <= n; i++) {printf("第%d个字符的编码是:", i);printf("%s\n", HC[i]);}
}
int main() {HuffmanTree HT;HuffmanCode HC;int* w, n, i;printf("请输入字符个数:");scanf_s("%d", &n);if (n > 1) {printf("\n请依次输入每个字符出现的次数,之间用空格隔开:");w = (int*)malloc((n + 1) * sizeof(int));for (i = 1; i <= n; i++)scanf_s("%d", &w[i]);CreateHuffmanTree(HT, w, n);HuffmanCoding(HT, HC, n);DispHuffmanCode(HT, HC, n);}else printf("输入的字符个数非法!\n");
}测试截图
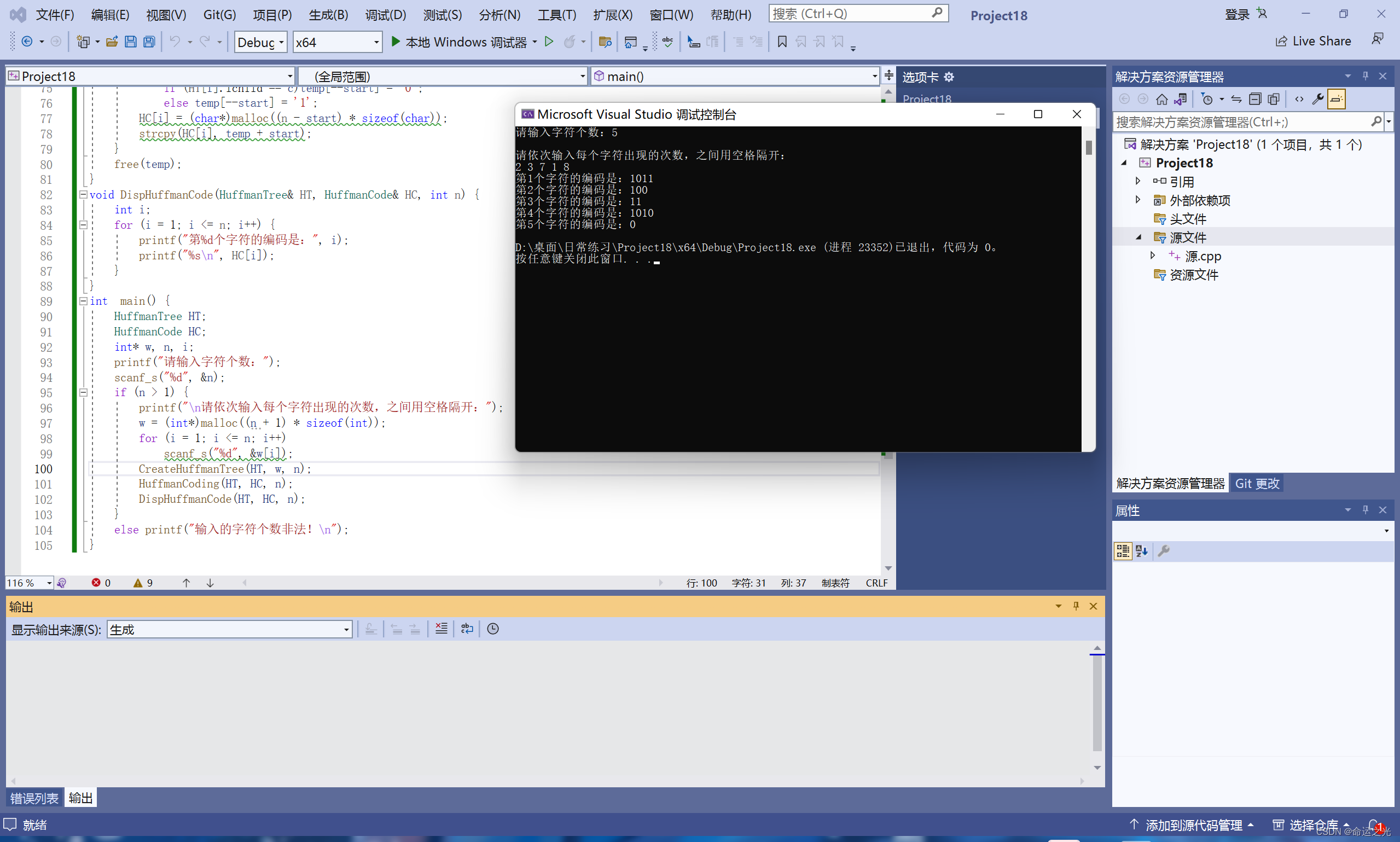
这段代码的输入样例是用于构建Huffman树的字符及其权重。以下是一个示例输入:
请输入字符个数:5
请依次输入每个字符出现的次数,之间用空格隔开:
2 3 7 1 8
这个示例输入首先要求输入字符的总数,然后要求按照字符的顺序输入每个字符出现的次数(权重)。在上述示例中,有5个字符,它们的权重分别为2、3、7、1和8。
根据这些输入,代码将构建Huffman树并生成每个字符的Huffman编码。
Huffman编码的应用
在这一部分,我们将探讨Huffman编码的实际应用,包括:
- 数据压缩:我们解释如何使用Huffman编码来压缩文本数据,减小存储和传输开销。
- 数据传输:介绍Huffman编码在网络通信和文件传输中的应用,以提高传输效率。
- 数据加密:简要讨论Huffman编码在数据加密领域的潜在用途。
总结
在博客的结尾,我们总结了Huffman编码的重要性、原理、实现和应用领域。鼓励读者深入学习Huffman编码,并了解如何在实际项目中应用它,以提高数据处理效率和节省资源。
🌌点击下方个人名片,交流会更方便哦~(欢迎到博主主页加入我们的 CodeCrafters联盟一起交流学习)↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓