文章目录
- 一、Hadoop部署模式
- (一)独立模式
- (二)伪分布式模式
- (三)完全分布式模式
- 二、搭建伪分布式Hadoop
- (一)登录虚拟机
- (二)上传安装包
- (三)配置免密登录
- 1、生成密钥对
- 2、将生成的公钥发送到本机
- 3、验证虚拟机是否能免密登录自己
- (四)配置JDK
- 1、解压到指定目录
- (1)解压到指定目录
- (2)查看java解压目录
- 2、配置JDK环境变量
- 3、让环境变量配置生效
- 4、查看JDK版本
- 5、玩一玩Java程序
- (五)配置Hadoop
- 1、解压hadoop安装包
- (1)解压到指定目录
- (2)查看hadoop解压目录
- (3)常用目录和文件
- 2、配置hadoop环境变量
- 3、让环境变量配置生效
- 4、查看hadoop版本
- 5、编辑Hadoop环境配置文件 - hadoop-env.sh
- 6、编辑Hadoop核心配置文件 - core-site.xml
- 7、编辑HDFS配置文件 - hdfs-site.xml
- 8、编辑MapReduce配置文件 - mapred-site.xml
- 9、编辑YARN配置文件 - yarn-site.xml
- 10、编辑workers文件确定数据节点
- (六)格式化名称节点
- (七)启动Hadoop服务
- 1、启动hdfs服务
- 2、启动yarn服务
- 3、查看Hadoop进程
- (八)查看Hadoop WebUI
- (九)关闭Hadoop服务
- 1、关闭hdfs服务
- 2、关闭yarn服务
一、Hadoop部署模式
(一)独立模式
- 在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
(二)伪分布式模式
- 在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
(三)完全分布式模式
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
二、搭建伪分布式Hadoop
(一)登录虚拟机
- 登录ied虚拟机
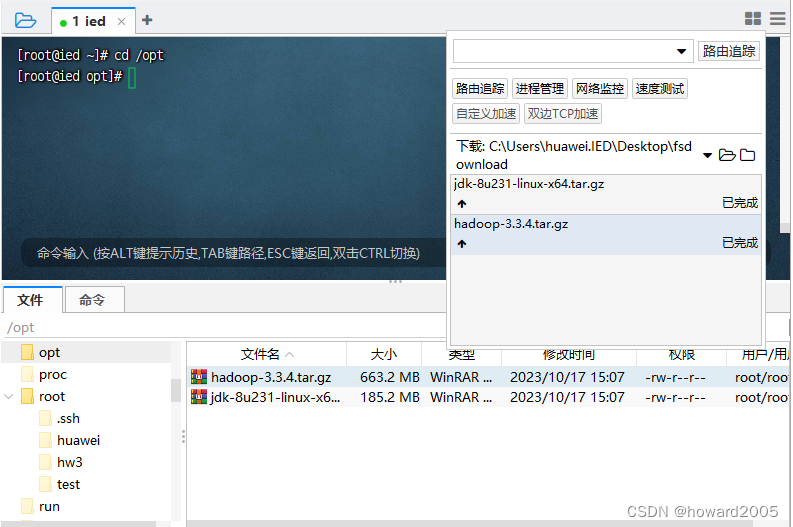
(二)上传安装包
-
上传jdk和hadoop安装包
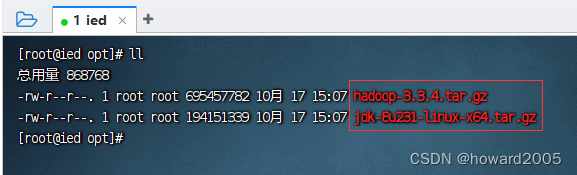
-
查看上传的安装包
(三)配置免密登录
1、生成密钥对
- 执行命令:
ssh-keygen
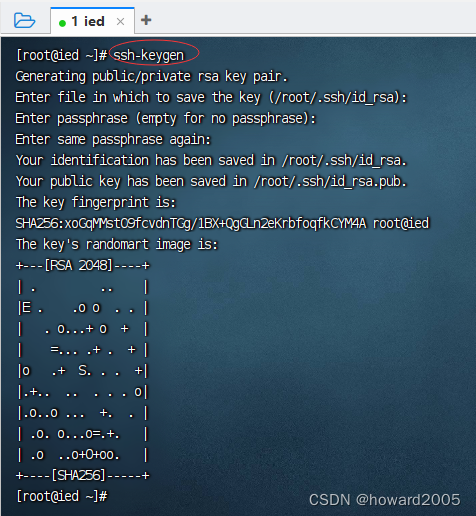
- 执行命令后,连续敲回车,生成节点的公钥和私钥,生成的密钥文件会自动放在/root/.ssh目录下。
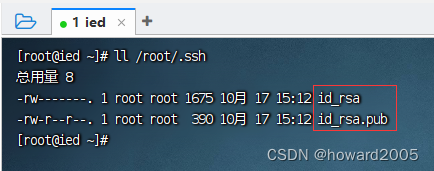
2、将生成的公钥发送到本机
- 执行命令:
ssh-copy-id root@ied
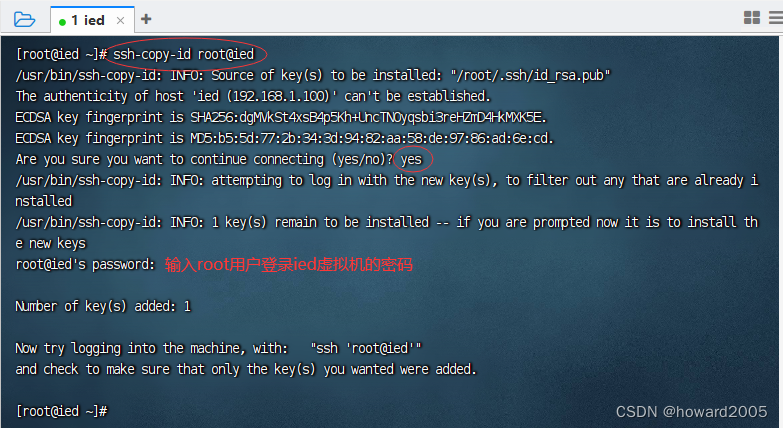
3、验证虚拟机是否能免密登录自己
- 执行命令:
ssh ied
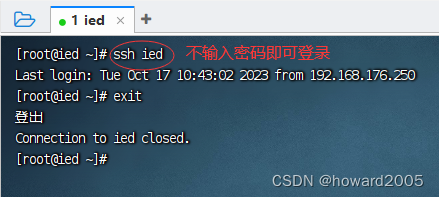
(四)配置JDK
1、解压到指定目录
(1)解压到指定目录
- 执行命令:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local

(2)查看java解压目录
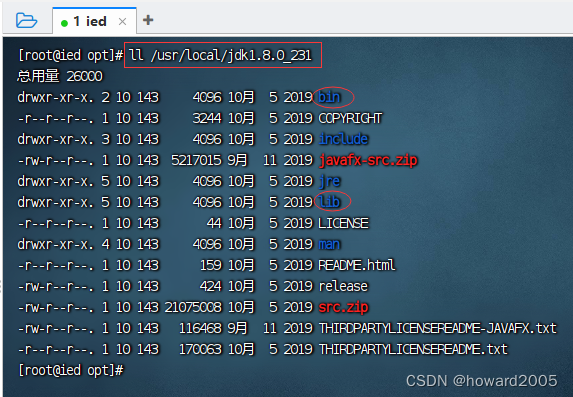
- 执行命令:
ll /usr/local/jdk1.8.0_231
2、配置JDK环境变量
- 执行命令:
vim /etc/profile
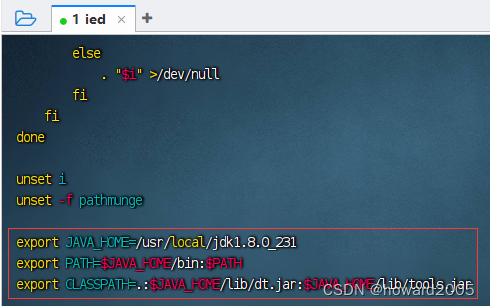
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 存盘退出
3、让环境变量配置生效
- 执行命令:
source /etc/profile
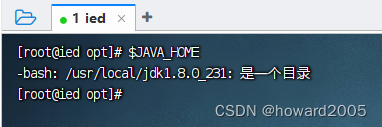
- 查看环境变量
JAVA_HOME
4、查看JDK版本
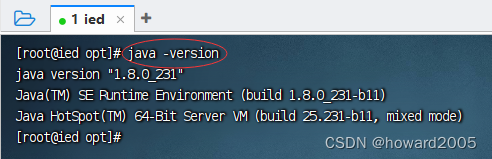
- 执行命令:
java -version
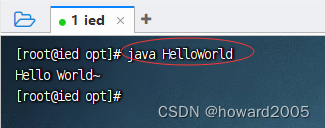
5、玩一玩Java程序
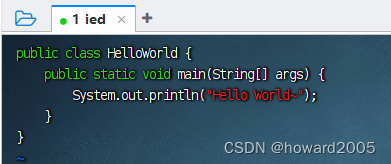
- 编写源程序,执行命令:
vim HelloWorld.java
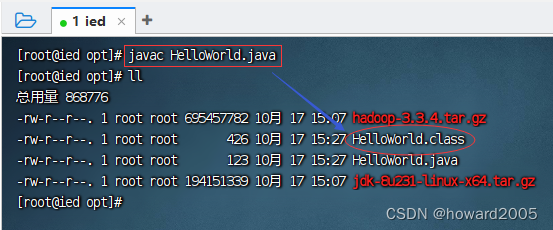
- 编译成字节码文件,执行命令:
javac HelloWorld.java
- 解释执行类,执行命令:
java HelloWorld
(五)配置Hadoop
1、解压hadoop安装包
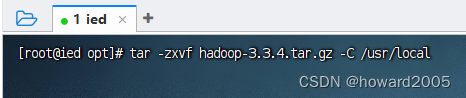
(1)解压到指定目录
- 执行命令:
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local
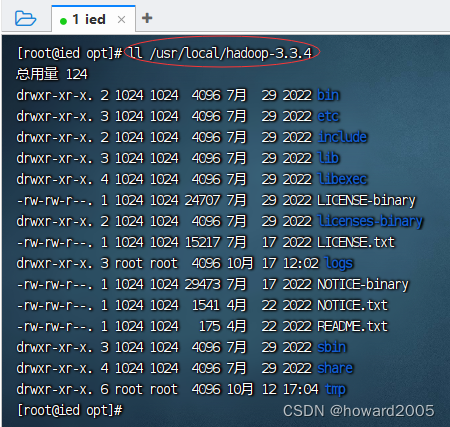
(2)查看hadoop解压目录
- 执行命令:
ll /usr/local/hadoop-3.3.4
(3)常用目录和文件
- bin目录 - 存放命令脚本
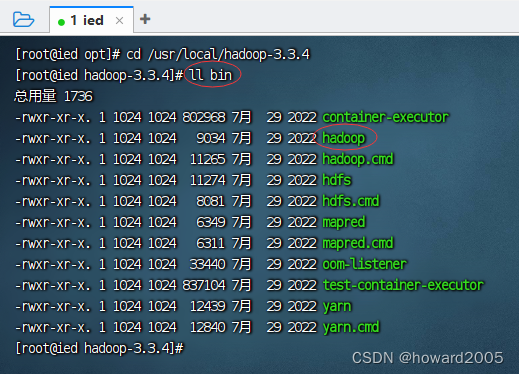
- etc/hadoop目录 - 存放hadoop的配置文件
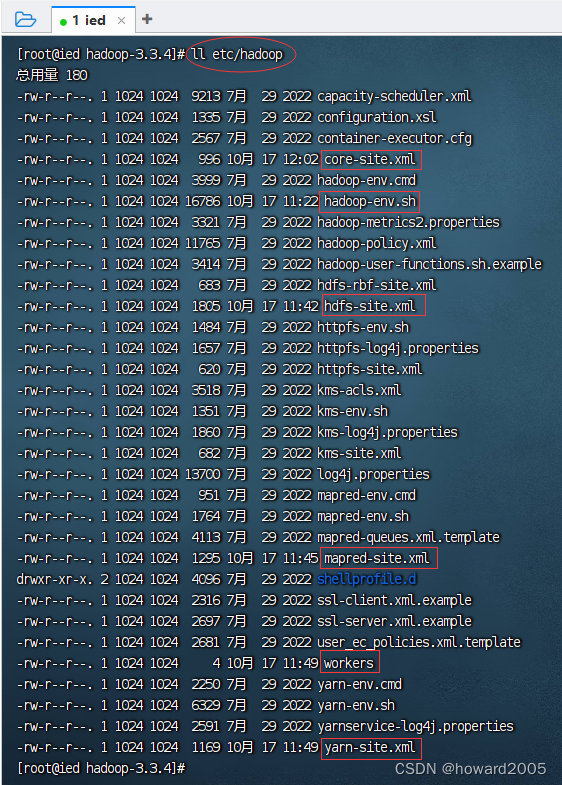
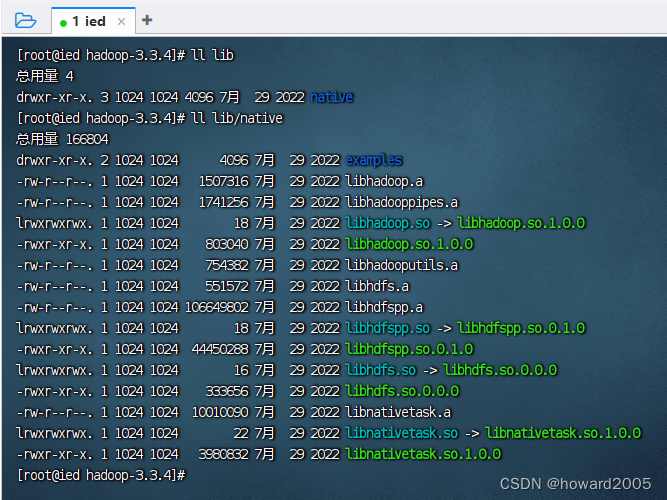
- lib目录 - 存放hadoop运行的依赖jar包
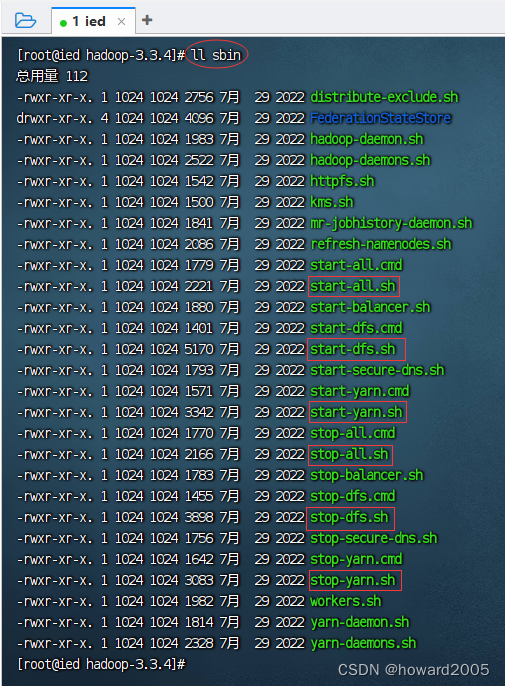
- sbin目录 - 存放启动和关闭Hadoop等命令
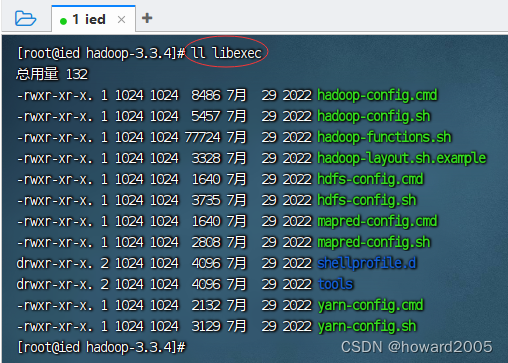
- libexec目录 - 存放的也是hadoop命令,但一般不常用
2、配置hadoop环境变量
- 执行命令:
vim /etc/profile
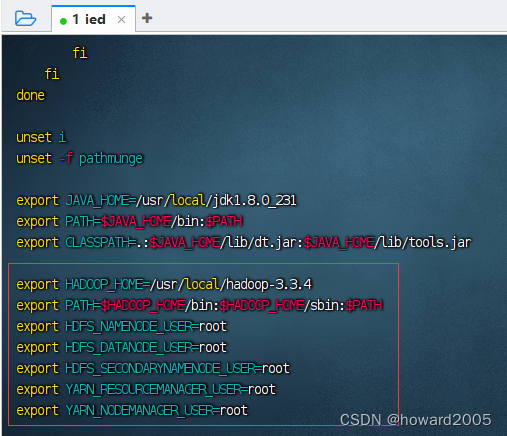
- 说明:hadoop 2.x用不着配置用户,只需要前两行即可
3、让环境变量配置生效
- 执行命令:
source /etc/profile
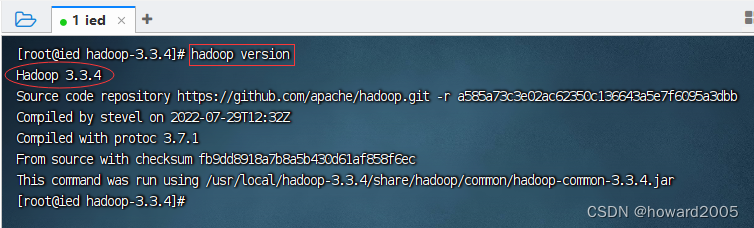
4、查看hadoop版本
- 执行命令:
hadoop version
5、编辑Hadoop环境配置文件 - hadoop-env.sh
- 执行命令:
cd etc/hadoop,进入hadoop配置目录
- 执行命令:
vim hadoop-env.sh,添加三条环境变量配置
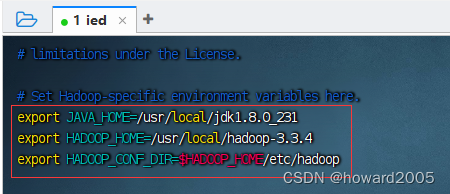
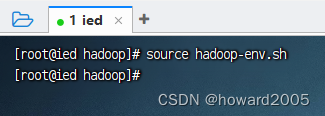
- 存盘退出后,执行命令
source hadoop-env.sh,让配置生效
6、编辑Hadoop核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml
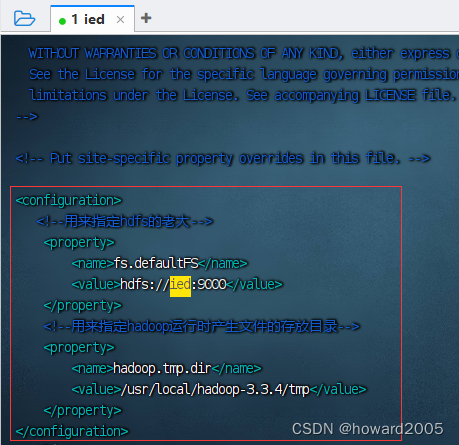
<configuration><!--用来指定hdfs的老大--><property><name>fs.defaultFS</name><value>hdfs://ied:9000</value></property><!--用来指定hadoop运行时产生文件的存放目录--><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-3.3.4/tmp</value></property>
</configuration>
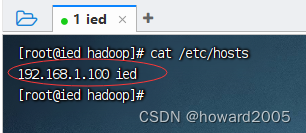
- 由于配置了IP地址主机名映射,因此配置HDFS老大节点可用
hdfs://ied:9000,否则必须用IP地址hdfs://192.168.1.100:9000
7、编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml
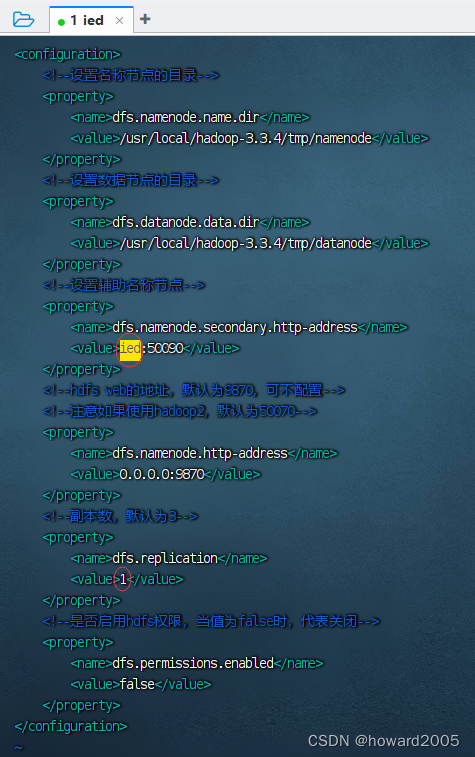
<configuration><!--设置名称节点的目录--><property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop-3.3.4/tmp/namenode</value></property><!--设置数据节点的目录--><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop-3.3.4/tmp/datanode</value></property><!--设置辅助名称节点--><property><name>dfs.namenode.secondary.http-address</name><value>ied:50090</value></property><!--hdfs web的地址,默认为9870,可不配置--><!--注意如果使用hadoop2,默认为50070--><property><name>dfs.namenode.http-address</name><value>0.0.0.0:9870</value></property><!--副本数,默认为3--><property><name>dfs.replication</name><value>1</value></property><!--是否启用hdfs权限,当值为false时,代表关闭--><property><name>dfs.permissions.enabled</name><value>false</value></property>
</configuration>
8、编辑MapReduce配置文件 - mapred-site.xml
- 执行命令:
vim mapred-site.xml
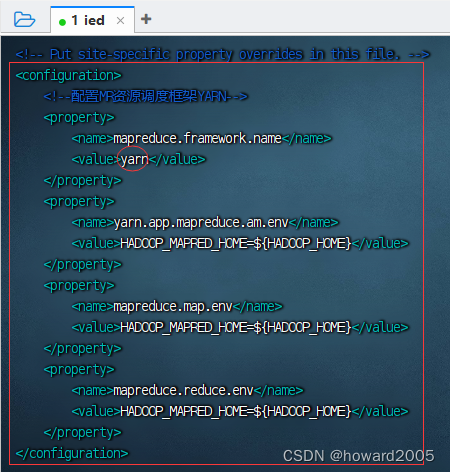
<configuration><!--配置MR资源调度框架YARN--><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
- 后三个属性如果不设置,在运行Hadoop自带示例的词频统计时,会报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
9、编辑YARN配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml
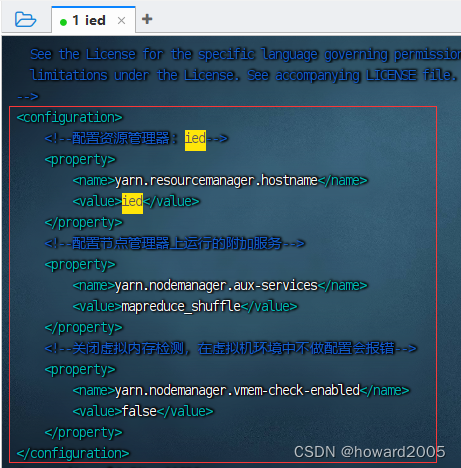
<configuration><!--配置资源管理器:ied--><property><name>yarn.resourcemanager.hostname</name><value>ied</value></property><!--配置节点管理器上运行的附加服务--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--关闭虚拟内存检测,在虚拟机环境中不做配置会报错--><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
10、编辑workers文件确定数据节点
- 说明:hadoop-2.x里配置
slaves文件,hadoop-3.x里配置workers文件 - 执行命令:
vim workers
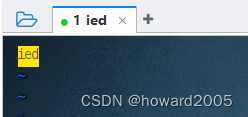
- 只有1个数据节点,正好跟副本数配置的1一致
(六)格式化名称节点
- 执行命令:
hdfs namenode -format
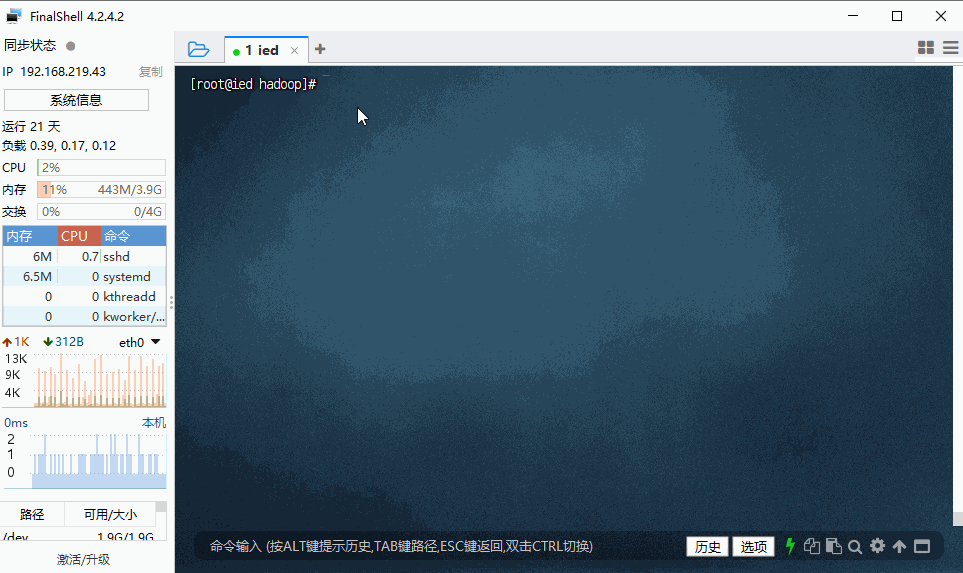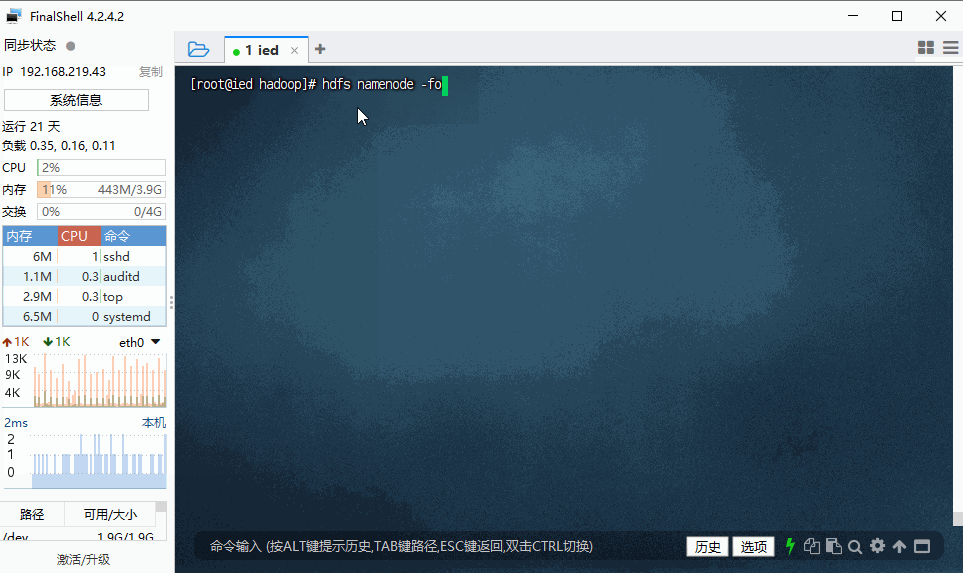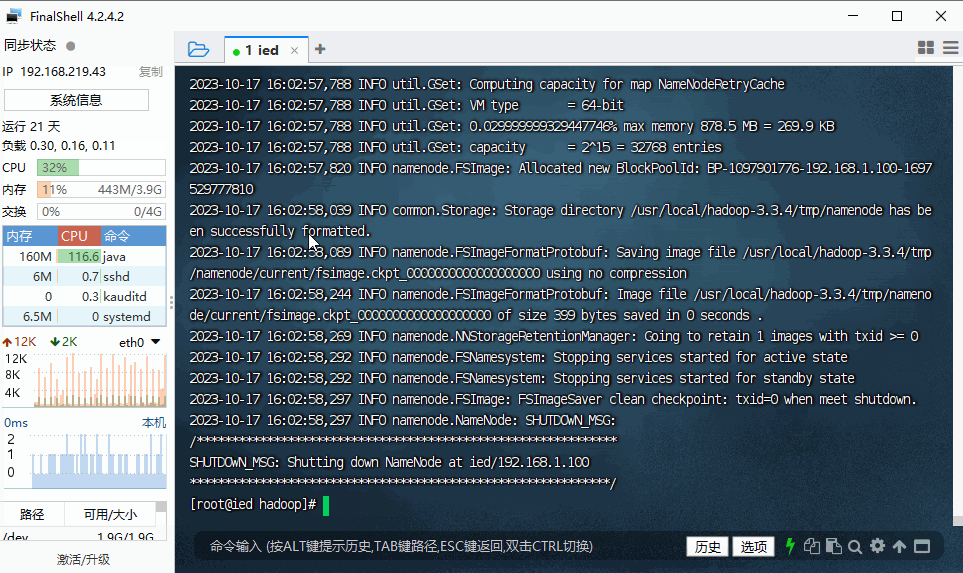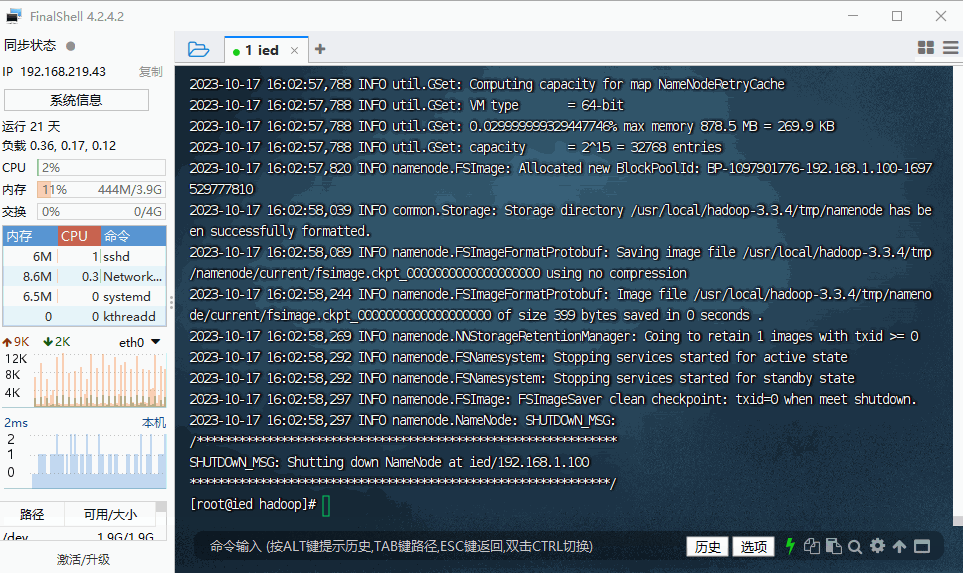
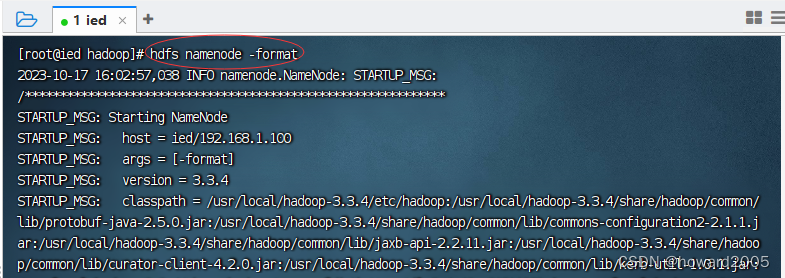
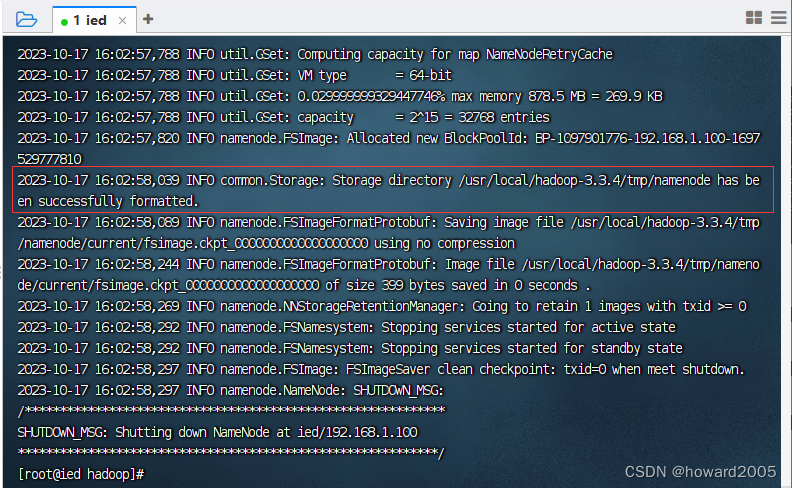
Storage directory /usr/local/hadoop-3.3.4/tmp/namenode has been successfully formatted.表明名称节点格式化成功。
(七)启动Hadoop服务
1、启动hdfs服务
- 执行命令:
start-dfs.sh
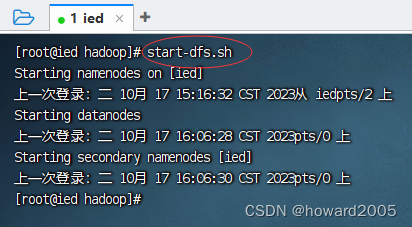
2、启动yarn服务
- 执行命令:
start-yarn.sh
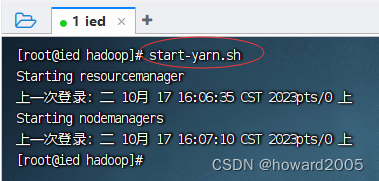
3、查看Hadoop进程
-
执行命令:
jps
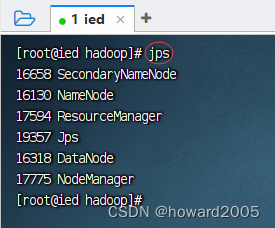
-
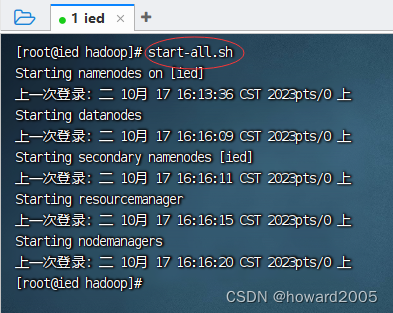
说明:
start-dfs.sh与start-yarn.sh可以用一条命令start-all.sh来替换
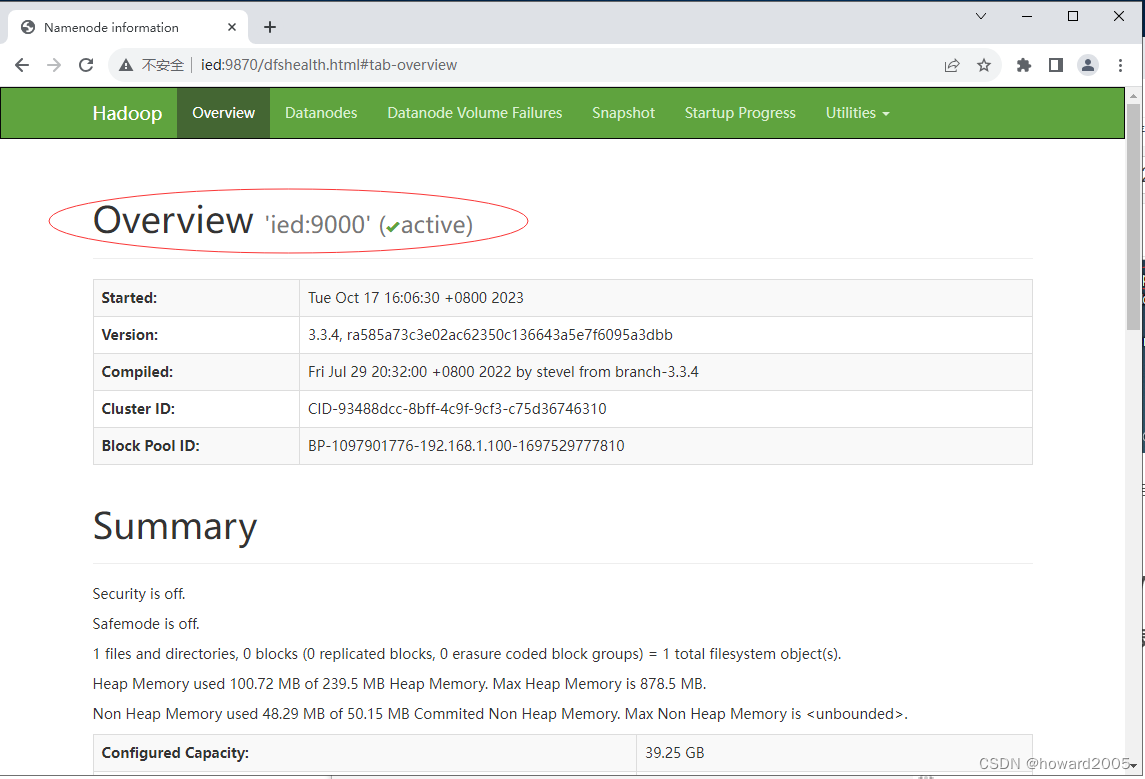
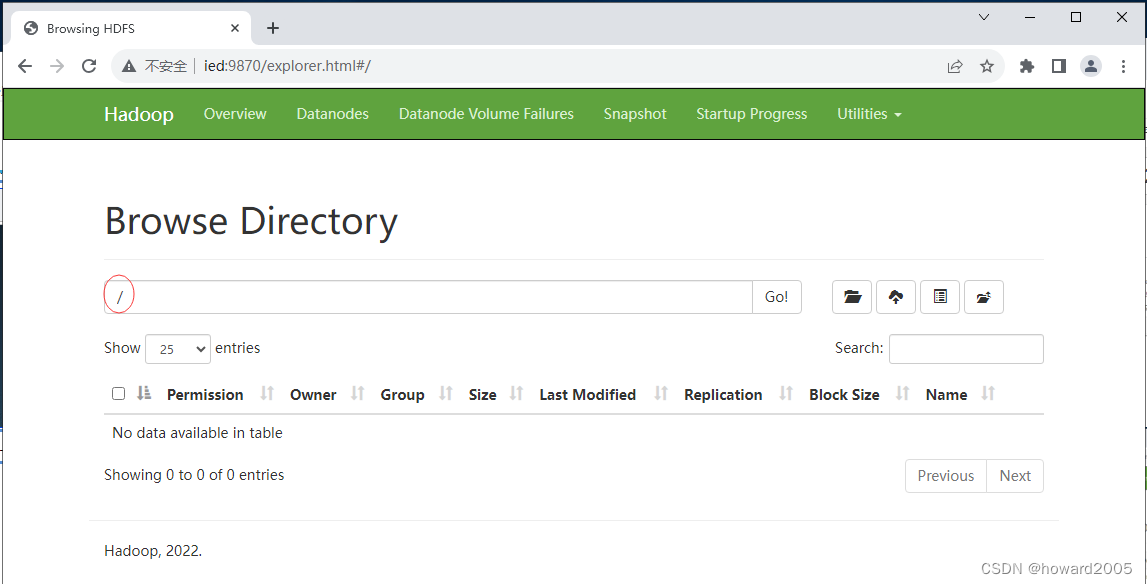
(八)查看Hadoop WebUI
- 在浏览器里访问
http://ied:9870
- 查看文件系统
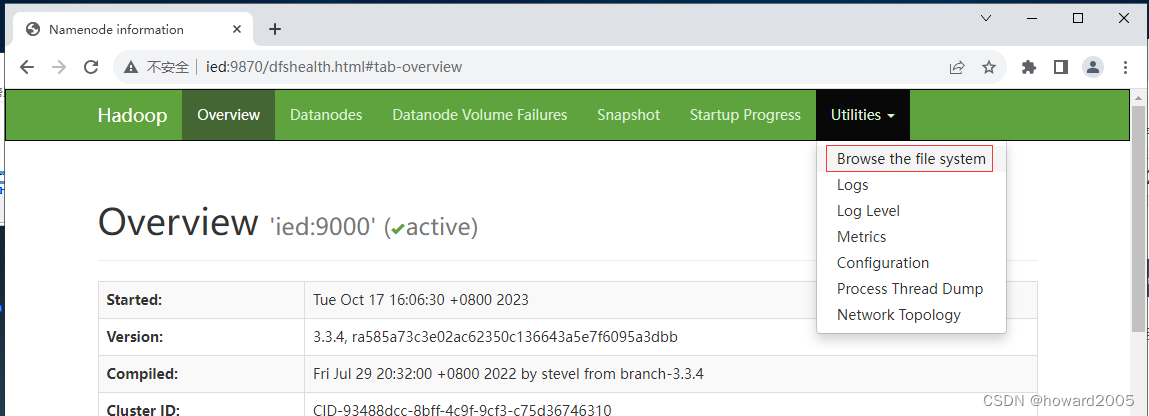
- 根目录下没有任何内容
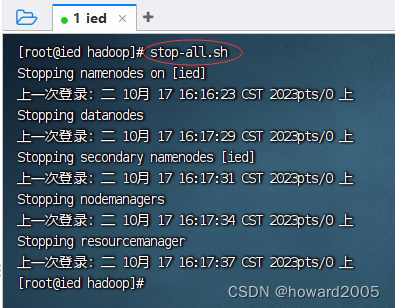
(九)关闭Hadoop服务
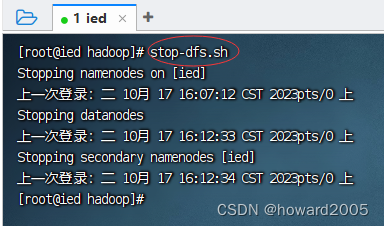
1、关闭hdfs服务
- 执行命令:
stop-dfs.sh
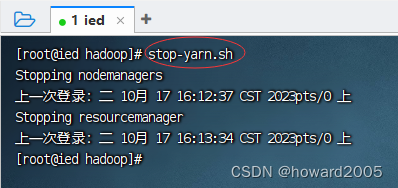
2、关闭yarn服务
-
执行命令:
stop-yarn.sh
-
说明:
stop-dfs.sh与stop-yarn.sh可以用一条命令stop-all.sh来替换