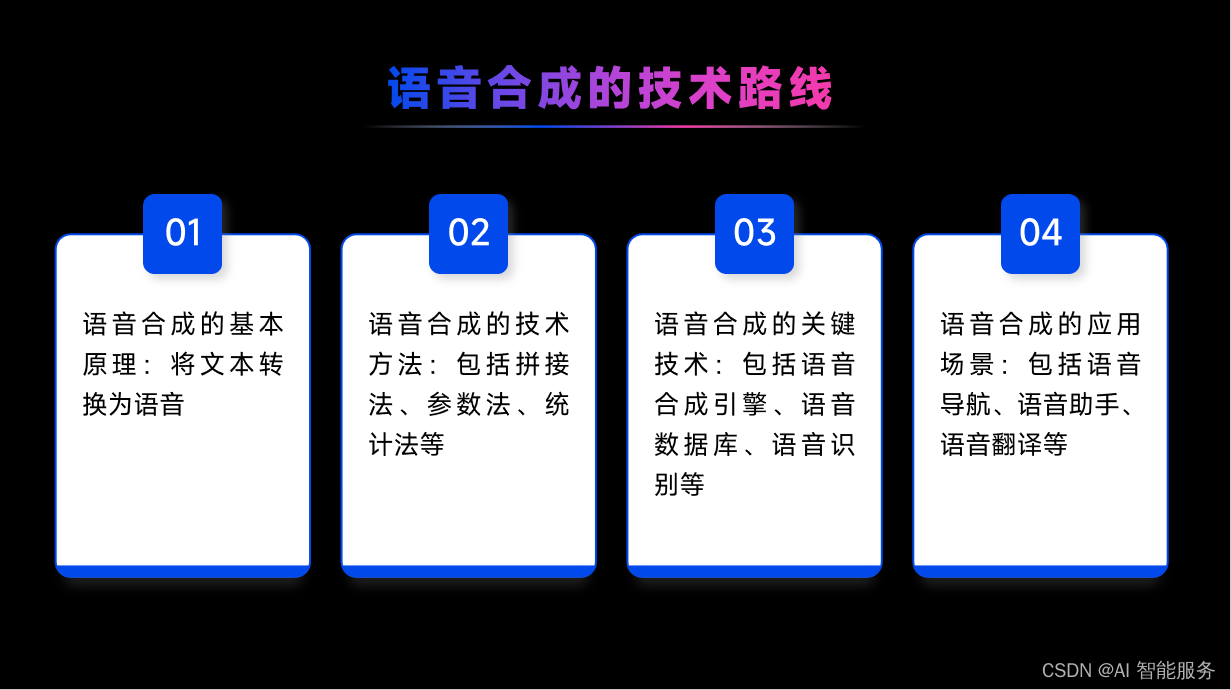
TTS是语音合成技术的简称,也称为文语转换或语音到文本。它是指将文本转换为语音信号,并通过语音合成器生成可听的语音。TTS技术可以用于多种应用,例如智能语音助手、语音邮件、语音新闻、有声读物等。
TTS技术通常包括以下步骤:
- 文本预处理:首先将输入的文本进行预处理,包括分词、词性标注、语法分析等操作,以识别出文本中的单词和短语。
- 语音合成:将预处理后的文本转换为语音信号,通过语音合成器生成语音。语音合成器可以使用不同的语音库和算法来生成不同声音和语种的语音。
- 语音后处理:对生成的语音进行后处理,包括音调调节、音质改善、噪声消除等操作,以提高生成的语音质量。
1.语音合成的定义

TTS的语音合成过程中常见的声学模型训练方法包括以下几种:
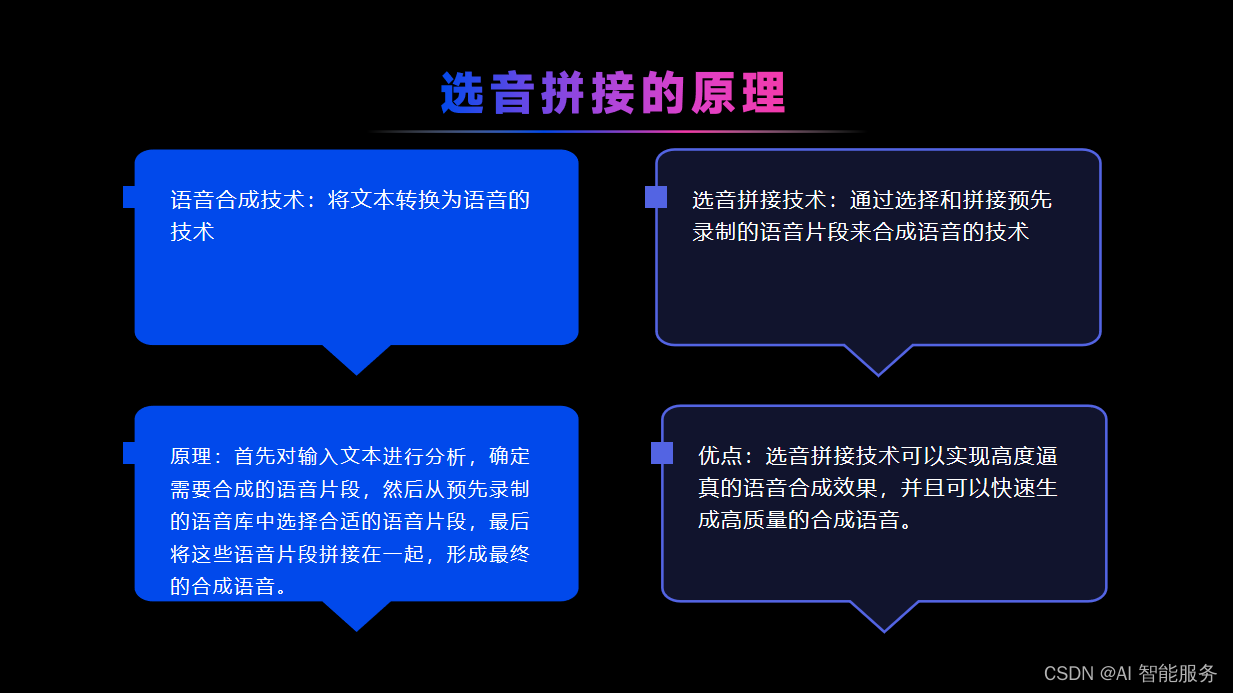
- 拼接法:将预先录制的语音片段进行拼接,以合成自然、流畅的语音。这种方法的优点是语音质量较高,但缺点是数据库要求较大,需要几十个小时的成品录音,成本较高。
- 参数法:根据统计模型生成语音参数,如基频、共振峰频率等,然后将这些参数转化为波形。这种方法对数据库需求较小,但生成的语音质量较为粗糙。
- 波形合成法:将声学模型训练出来的声码器转化为波形,然后将波形进行拼接以合成语音。这种方法对数据库需求较小,但生成的语音质量较为粗糙。
- 多层声码器法:将多个声码器进行组合使用,以合成更高质量的语音。这种方法可以在一定程度上提高语音质量,但需要消耗更多的计算资源和时间。
下面介绍一下拼接法:

2.参数合成技术
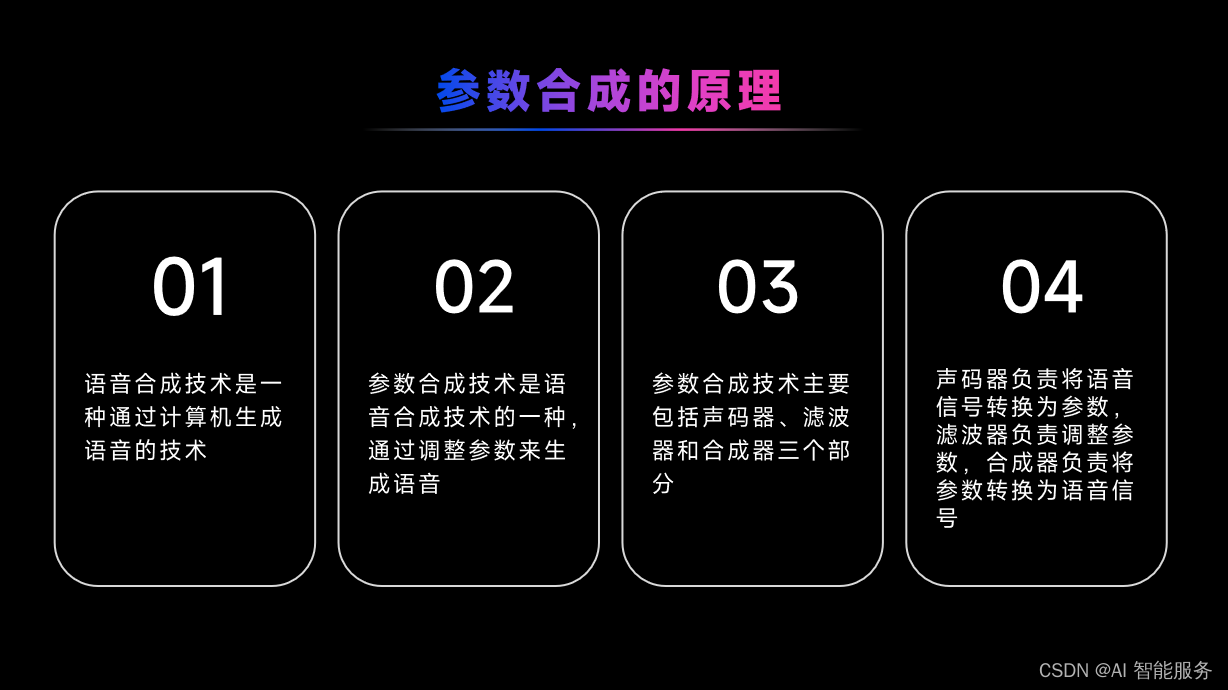
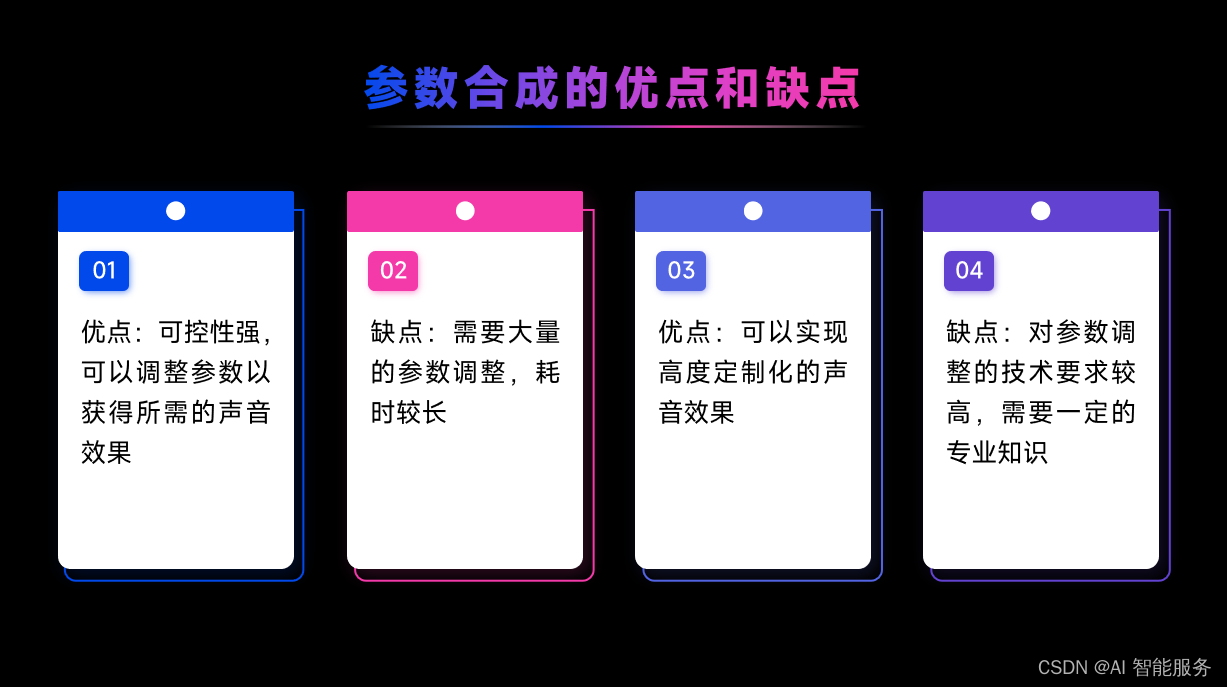
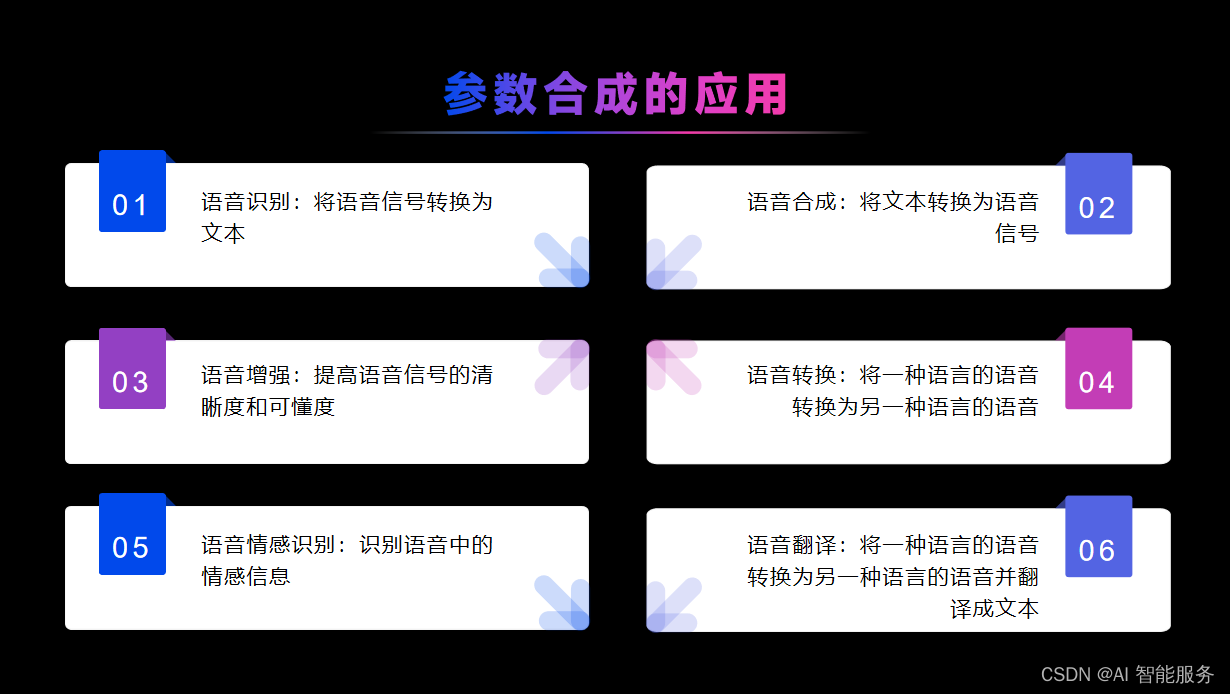
参数合成技术是一种通过数学方法对已有录音进行频谱特性参数建模,构建文本序列映射到语音特征的映射关系,生成参数合成器的方法。当输入一个文本时,先将文本序列映射出对应的音频特征,再通过声学模型(声码器)将音频特征转化为我们听得懂的声音。参数合成技术具有录音量小、可多个音色共同训练、字间协同过渡平滑、自然等优点,但音质没有波形拼接的好,机械感强,有杂音等缺点。常见的参数合成技术包括基于统计参数合成技术和基于端到端语音合成技术。基于统计参数合成技术的方法包括隐马尔科夫模型(HMM)和声码器重构等。
3.深度学习端到端合成技术
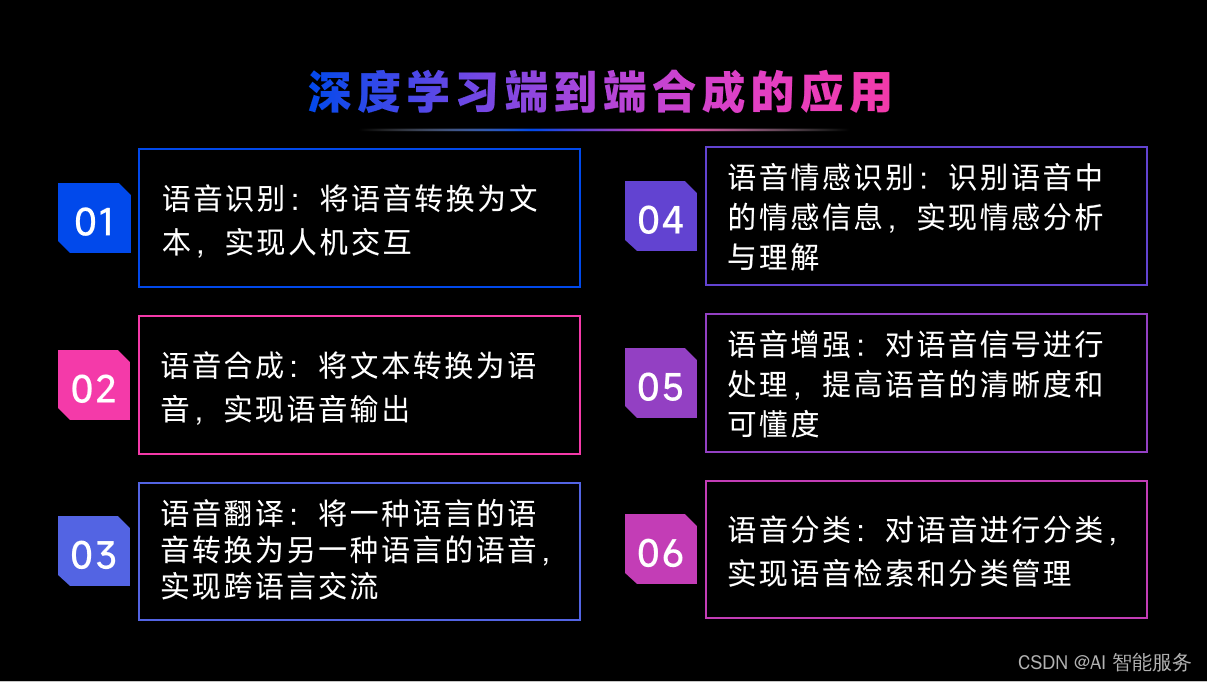
深度学习端到端合成技术是指利用深度学习模型将文本直接转换为语音波形,不需要进行中间的语音参数提取,实现文本到语音的“端到端”合成。近年来基于神经网络架构的深度学习方法崛起,使得原本在传统专业领域门槛极高的TTS应用上更接地气。端到端合成系统相比于传统语音合成,降低了对语言学知识的要求,可以方便的在不同语种上复制,批量实现几十种甚至更多语种的合成系统。
端到端合成系统不需要考虑如何从语音的声学特征中恢复出原始的音频信号,而是直接将文本转换为音频信号,因此具有更高的效率和更好的音质。同时,端到端合成系统还可以直接使用原始文本作为输入,不需要进行文本分析等预处理操作,简化了系统的复杂度和处理流程。
目前,基于深度学习的端到端语音合成技术主要分为两类:统计参数合成(Statistical Parametric Speech Synthesis, SPSS)和神经网络声码器(Neural Vocoder)。其中,统计参数合成是一种基于统计模型的语音合成方法,通过建立文本特征到语音参数的映射关系来生成语音,而神经网络声码器则是一种基于深度神经网络的语音合成方法,通过训练神经网络模型将文本特征直接转换为语音波形。

4.语音合成效果评估
TTS的效果评估可以从两个方面进行:主观评估和客观评估。
主观评估主要是通过人工听测的方式进行。具体来说,可以按照以下步骤进行:
- 选取语料库:选取一定量的语音合成测试语料库,其中包括不同的情感、语气、说话人等,以全面评估TTS系统的性能。
- 测试人员:组织一定数量的测试人员,包括语音识别专家和普通用户,来进行主观评测。
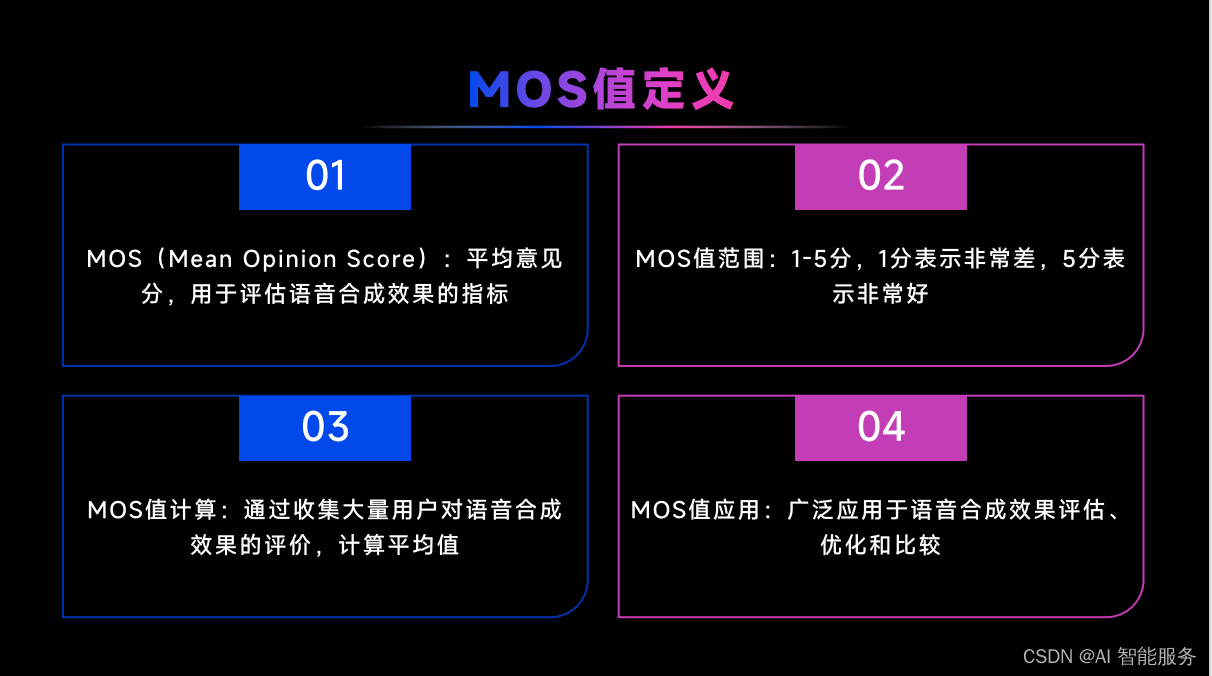
- 测试方法:采用类似于MOS分(Mean Opinion Score)的主观测试方法,让测试人员听取合成语音并对其音质、自然度、可用性等方面进行评分。
- 数据处理:统计每个测试人员的评分,并计算出平均值,得出最终的主观评估结果。
客观评估则是通过仪器或软件进行测试,常用的方法包括但不限于以下两种:
- PESQ(Perceptual Evaluation of Speech Quality)方法:使用专门的仪器或软件对TTS系统的输出语音进行质量评估。该方法提供了一种定量的、客观的评估方式,结果可以在不同系统之间进行比较。
- 语音识别率:通过使用语音识别引擎对合成语音进行识别,可以得到合成语音的识别率。识别率越高,说明TTS系统的效果越好。
4.1主观测试方法MOS值评测介绍
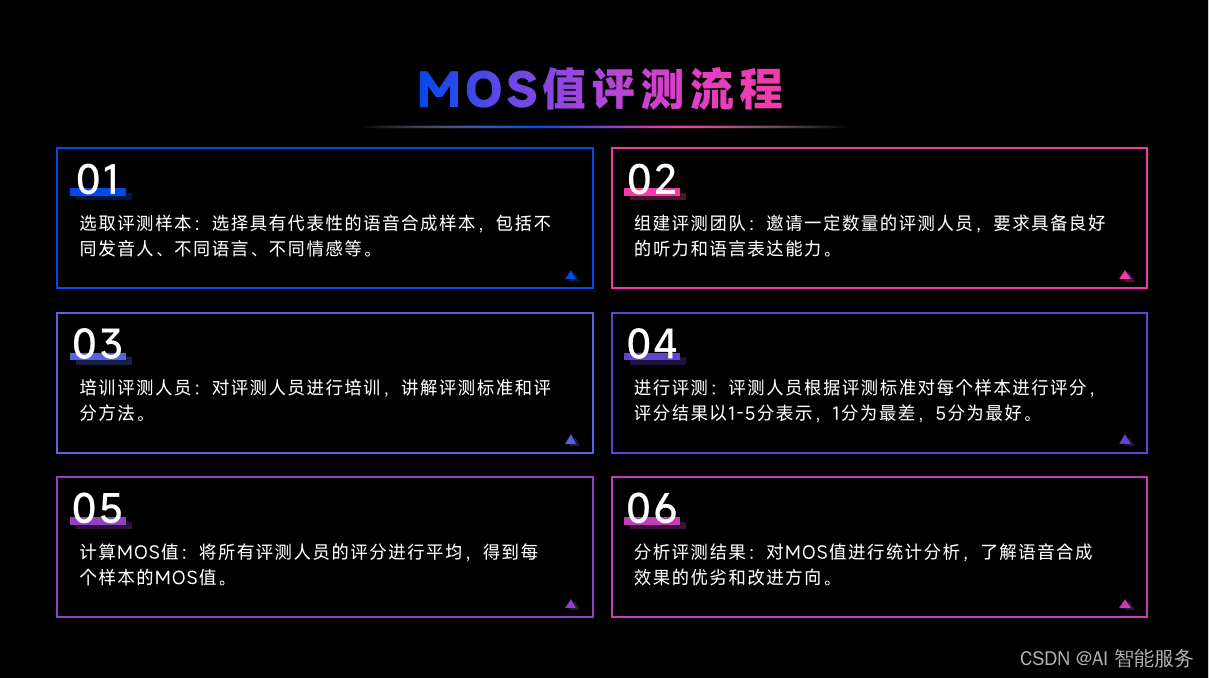
4.2MOS值评测标准
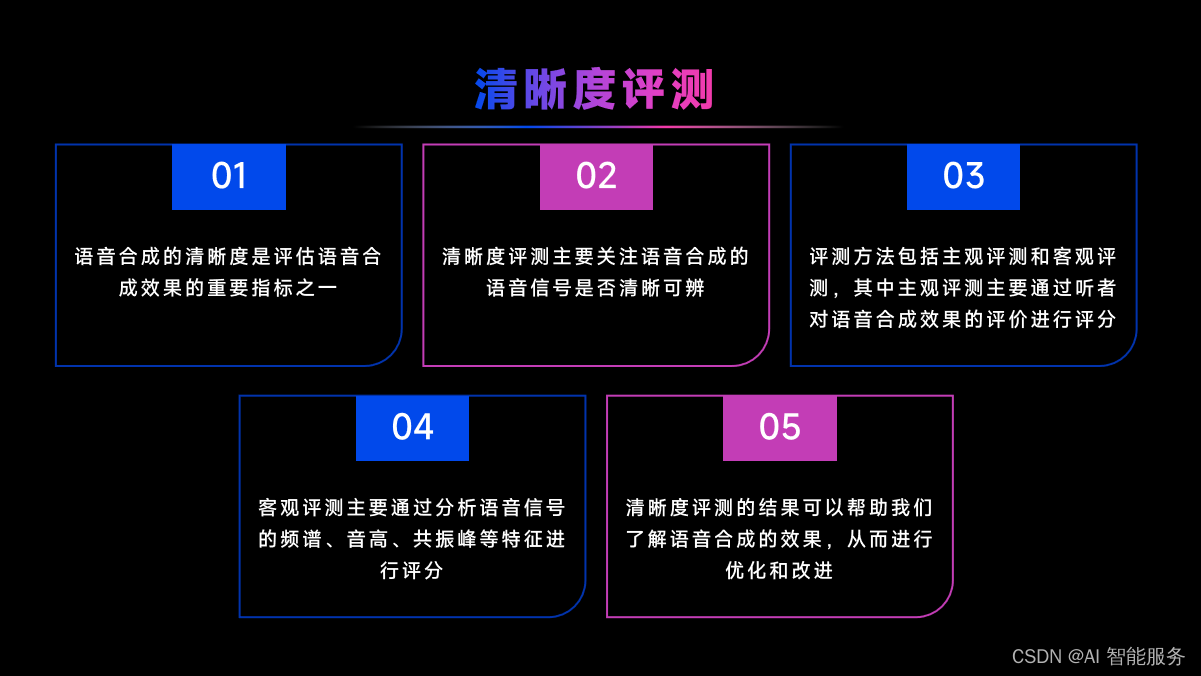


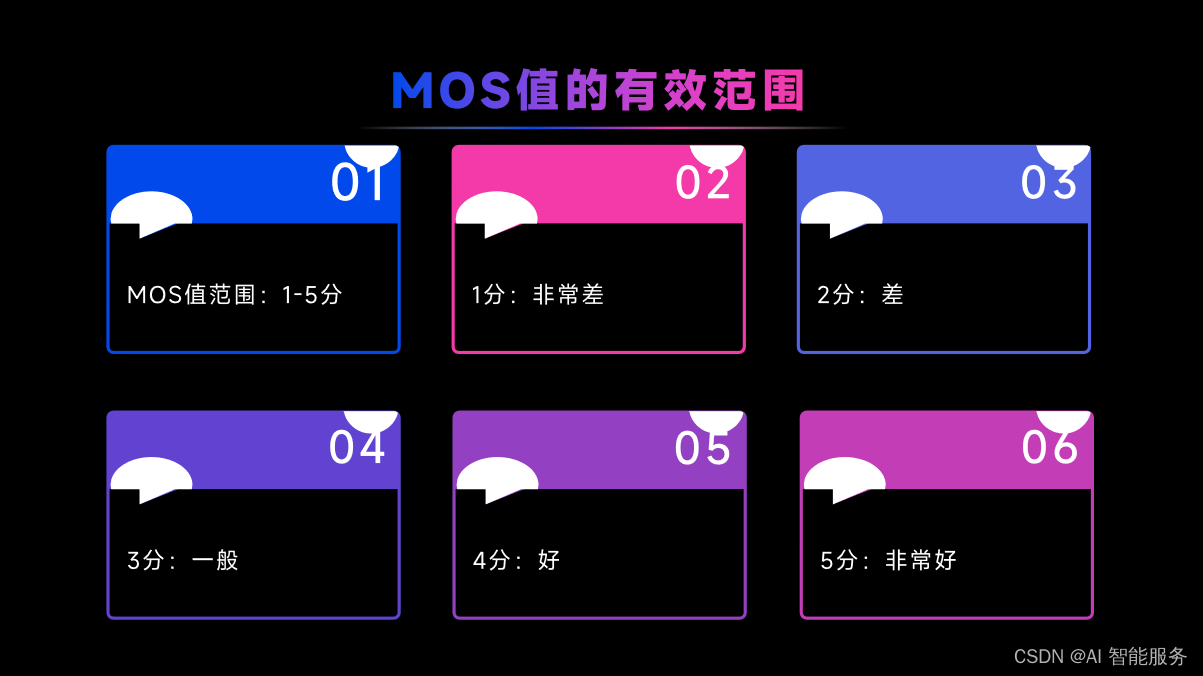
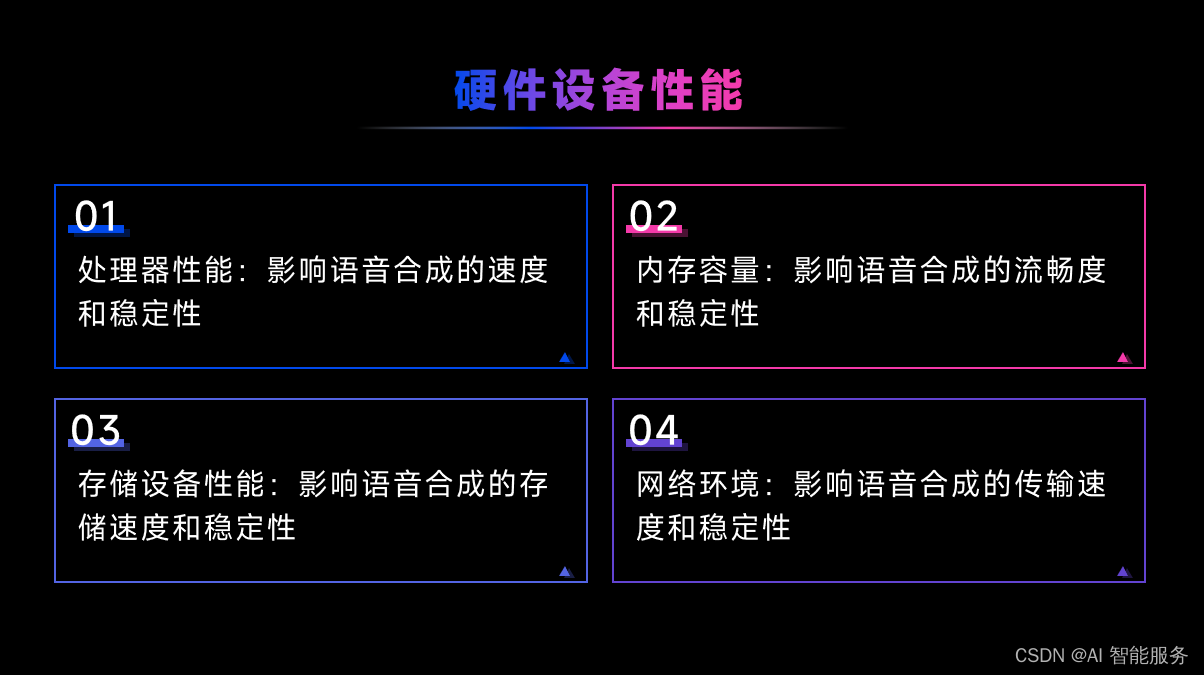
4.3影响MOS值评测结果的因素
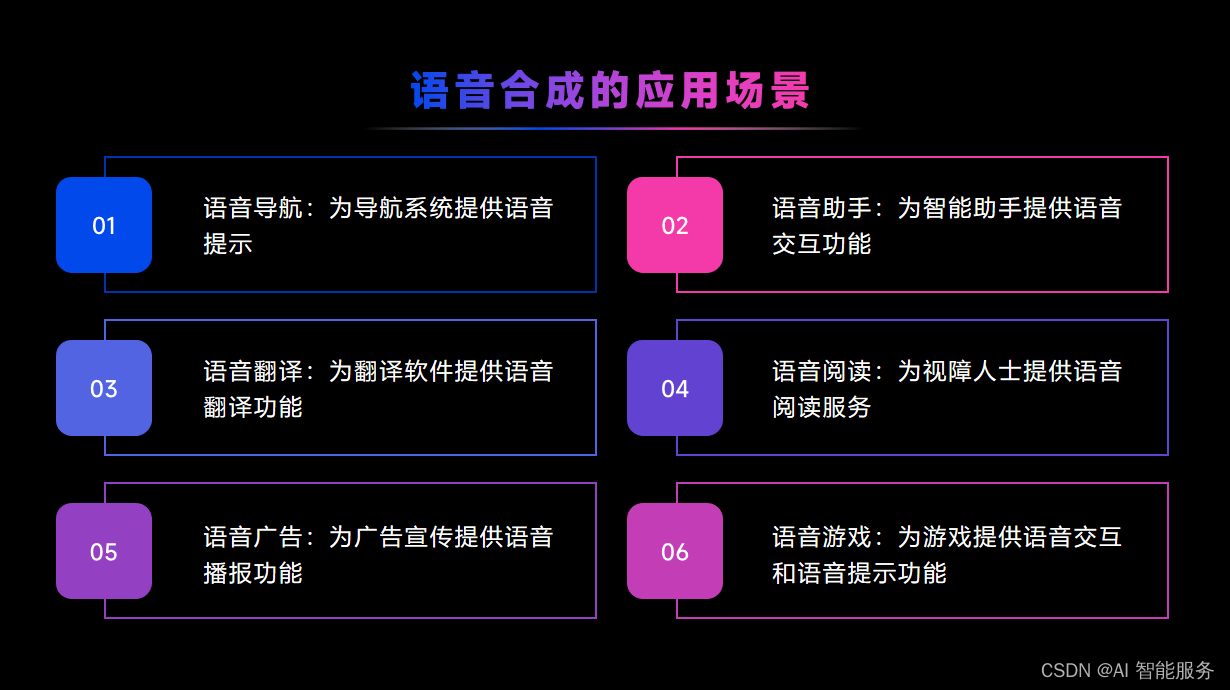
5.TTS的应用
TTS技术在人机交互中有着广泛的应用,以下是其中的几个具体示例:
- 语音助手:语音助手是TTS技术应用最广泛的领域之一。通过语音助手,用户可以通过语音与机器进行交互,实现查询信息、播放音乐、设定提醒、导航等各种功能。例如,用户可以通过语音唤醒手机中的语音助手,询问天气情况,或者让语音助手提醒自己待办事项。
- 智能客服:TTS技术可以用于智能客服系统,让机器能够自动回答用户的问题。通过语音识别和语音合成技术,智能客服可以理解用户的语音输入,并给出相应的回答。这种应用场景可以大大提高客户服务的效率和质量。
- 车载导航:车载导航是TTS技术的另一个应用领域。在车载导航系统中,TTS技术可以实现语音导航功能,司机可以通过语音指令来启动导航、查询路线、设定目的地等操作。这种应用场景可以提高驾驶安全性,减少司机在驾驶过程中分心的情况。
- 娱乐和媒体:TTS技术也被广泛应用于娱乐和媒体领域。例如,在视频游戏、动画和电影中,TTS技术可以实现角色或旁白的配音。同时,TTS技术还可以用于虚拟现实(VR)应用,提供更加真实的沉浸式体验。
- 语言学习:TTS技术可以帮助语言学习者提高发音和听力技能。通过TTS技术,学习者可以听到标准的语音发音,并跟读模仿。这种应用场景可以提高学习效率,帮助学习者更快地掌握正确的发音和语调。
- 自动化和客户服务:TTS技术可以用于自动化电话系统和客户服务应用。例如,在电话客服系统中,TTS技术可以根据来电者的语音或文字信息,提供语音提示、指示和回应。这种应用场景可以提高客户服务的效率和质量。
- 辅助性交流:TTS技术可以用于辅助和替代性交流(AAC)设备中,帮助有语言障碍或残疾的人表达自己的意愿。这种应用场景可以帮助他们更好地融入社会,提高生活质量。
基础课4——智能识别技术-CSDN博客ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是一种将人类语音转换为文本的技术。ASR 系统可以处理实时音频流或已录制的音频文件,并将其转换为文本。它是一种自然语言处理技术,广泛应用于许多领域,包括电话语音助手、语音转文本、语音搜索等。https://blog.csdn.net/2202_75469062/article/details/133891557?spm=1001.2014.3001.5501