目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 特征提取
- 1)常规赛特征提取
- 2)季后赛特征提取
- (1)常规赛球队得分
- (2)球员、教练数据及数据整合
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目使用了从NBA官方网站获得的数据,并运用了支持向量机(SVM)模型来进行NBA常规赛和季后赛结果的预测。此外,项目还引入了相关系数法、随机森林分类法和Lasso方法,以评估不同特征的重要性。最后,使用Python库中的webdriver功能实现了自动发帖,并提供了科学解释来解释比赛预测结果。
首先,项目采集了NBA官方网站上的各种数据,这些数据包括球队与对手的历史表现、球员数据、赛季统计等。这些数据用于构建常规赛或季后赛结果的预测模型。
其次,支持向量机(SVM)模型被用来分析这些数据以进行常规赛或季后赛结果的预测。SVM是一种强大的机器学习算法,可以通过分析数据来确定不同特征对比赛结果的影响。
项目还使用了相关系数法、随机森林分类法和Lasso方法,以评估每个特征对常规赛或季后赛结果的重要性。这有助于识别哪些因素对比赛胜负有更大的影响。
最后,项目利用Python中的webdriver库自动发帖,在开源中国论坛中发布关于比赛预测的帖子。这些帖子不仅提供了预测结果,还附带了科学解释,以便其他球迷能够理解模型如何得出这些预测。这对于NBA球迷和数据科学爱好者来说可能是一个非常有趣的项目,能够帮助他们更好地理解比赛和预测比赛结果。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
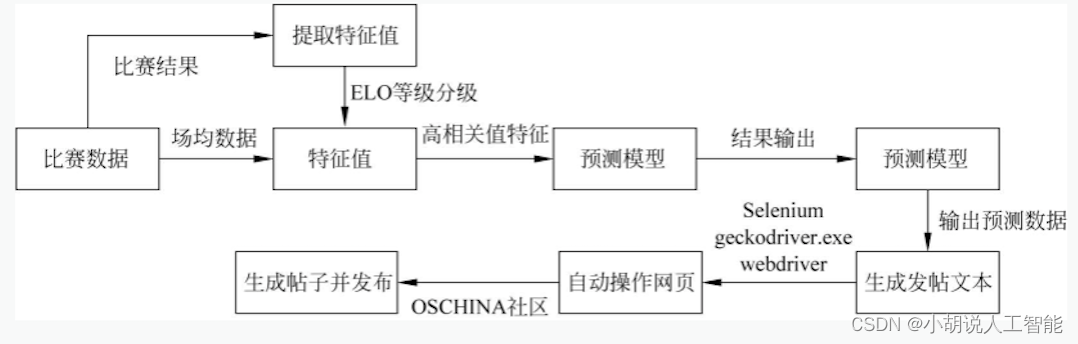
系统流程图
模型处理流程如图所示。
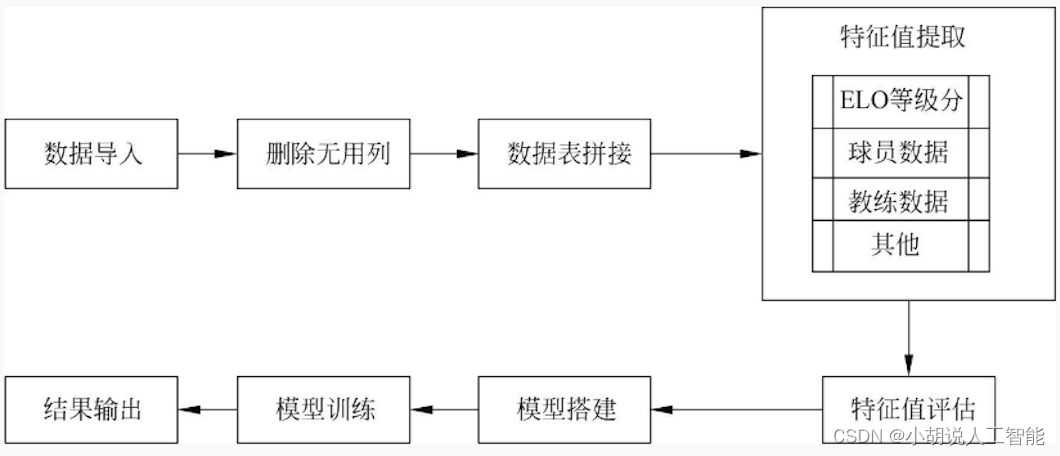
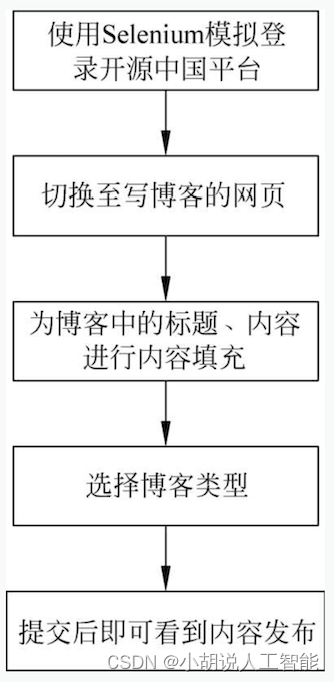
自动发帖流程如图所示。
运行环境
本部分包括Python环境、Jupyter Notebook环境、PyCharm环境和Matlab环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、特征提取、模型训练及评估、模型训练准确率,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
数据处理分为常规赛和季后赛。
详见博客。
2. 特征提取
本部分包括常规赛特征提取和季后赛特征提取。
1)常规赛特征提取
本部分为ELO等级分这一特征值的定义与应用。当每支队伍没有ELO等级分时,赋予其基础等级分:
base_elo = 1600
team_elos = {}
#定义ELO获取函数
def get_elo(team):try:return team_elos[team]except:#当最初没有ELO时,给每个队伍最初赋base_eloteam_elos[team]= base_eloreturn team_elos[team]
#定义ELO更新函数
def calc_elo(win_team, lose_team,HorV):#获取初始ELOelo_win_old=get_elo(win_team)elo_lose_old=get_elo(lose_team)#定义主客场ELO差值计算方法if HorV=='H':elo_diff=elo_lose_old-elo_win_old-50else:elo_diff=elo_lose_old-elo_win_old+50#定义胜败双方ELO计算方法E_win=1/(1+10**(elo_diff/400))E_lose=1/(1+10**(-elo_diff/400))#使用动态的K值,按照默认的K值得出的强队愈强,弱队愈弱,因为强队ELO高,输球代价小,虽然赢球增值也小,但输少赢多。弱队赢球增值高,但输球代价大,输多赢少,这种方式,强队一旦输给弱队,ELO下降会比较多if elo_win_old>=1650:K=16elif 1550<=elo_win_old<1650:K=24else:K=32elo_win_new=elo_win_old+K*(1-E_win)if elo_lose_old>=1650:K=32elif 1550<=elo_lose_old<1650:K=24else:K=16elo_lose_new=elo_lose_old+K*(0-E_lose)#赋值team_elos[win_team]=round(elo_win_new)team_elos[lose_team]=round(elo_lose_new)return team_elos[win_team],team_elos[lose_team]
#定义相关特征数组创建函数
def build_dataSet(result_data):X = []y = []skip = 0for index, row in result_data.iterrows():Wteam = row['WTeam']Lteam = row['LTeam']#获取最初的ELO或是每个队伍最初的ELO值team1_elo=get_elo(Wteam)team2_elo=get_elo(Lteam)#if row['WLoc'] == 'H':#team1_elo += 40#else:#team2_elo += 40# 把ELO作为评价每个队伍的第一个特征值team1_features = [team1_elo]team2_features = [team2_elo]#把是否主场作为评价每个队伍的第二个特征值,采用实验楼方法时(主场优势加在ELO中),都改为0即可if row['WLoc']=='H':team1_features.append(1)team2_features.append(0)else:team1_features.append(0)team2_features.append(1)#添加从basketball reference.com获得每个队伍的统计信息for key,value in team_stats.loc[Wteam].iteritems():team1_features.append(value)for key,value in team_stats.loc[Lteam].iteritems():team2_features.append(value)#将两支队伍的特征值随机分配在每场比赛数据的左右两侧#并将对应的0/1赋给y值if random.random()<0.5:X.append(team1_features+team2_features)y.append(0)else:X.append(team2_features+team1_features)y.append(1)#根据这场比赛的数据更新队伍的ELO值calc_elo(Wteam,Lteam,row['WLoc'])return X,y
本部分引入相关系数法、随机森林分类法和lasso方法对特征进行重要性评估,并综合3种方法删除重要性排名较低的特征。
相关代码如下:
feature_df.corr()
#计算相关系数矩阵
corr_ss=feature_df.corr().Win.map(abs).sort_values(ascending=False)
#去除后缀_和数字[1-2],算出特征前缀一致的相关系数均值
corr_gr_ss=corr_ss.groupby(corr_ss.index.str.split('_').str[0].str.replace('\d$','')).mean().sort_values()
#删除Win行向量
corr_gr_ss=corr_gr_ss.drop('Win')
#随机森林分类法
model_test=RandomForestClassifier()
model_test.fit(feature_df.iloc[:,:-1],feature_df['Win'])
rfc_ss=pd.Series(index=feature_df.columns[:1],data=model_test.feature_importances_).sort_values()
#去除后缀_和数字[1-2],算出特征前缀一致的重要性均值
rfc_gr_ss=rfc_ss.groupby(rfc_ss.index.str.split('_').str[0].str.replace('\d$','')).mean().sort_values()
#lasso方法
model_test2=Lasso()
model_test2.fit(feature_df.iloc[:,:-1],feature_df['Win'])
lasso_ss=pd.Series(index=feature_df.columns[:1],data=model_test2.coef_).sort_values()
#去除后缀_和数字[1-2],算出特征前缀一致的系数均值
lasso_gr_ss=lasso_ss.groupby(lasso_ss.index.str.split('_').str[0].str.replace('\d$','')).mean().sort_values()
tscore_df=pd.concat([corr_df,rfc_df,lasso_df],axis=1).sort_values('crank')
tscore_df
特征评估结果如下表所示。
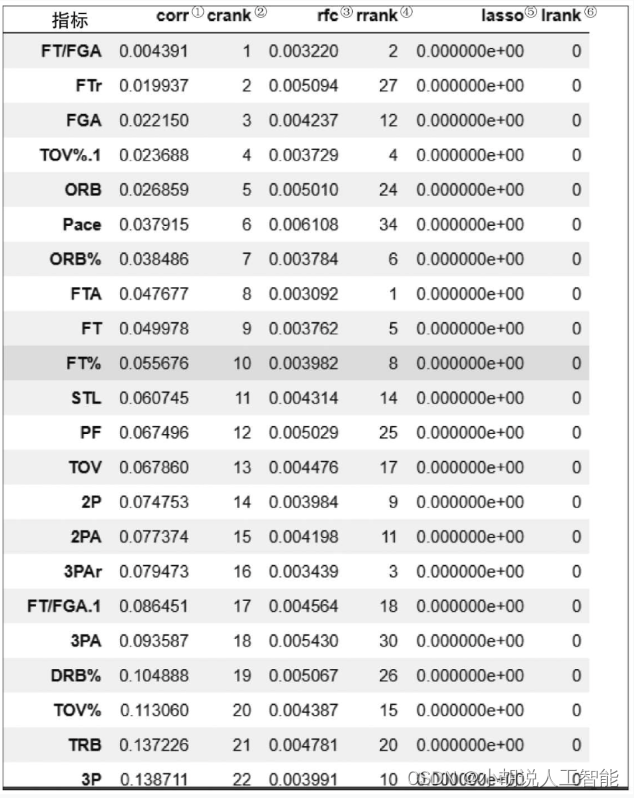
①各特征和标注的相关系数;②相关性排名,越小越不相关;③各特征重要性;④重要性排名,越小则重要性越小;⑤对特征用lasso拟合的相关系数;⑥代表相关系数是否为0,1代表不为0。
相关系数与随机森林排名特征如下表所示。
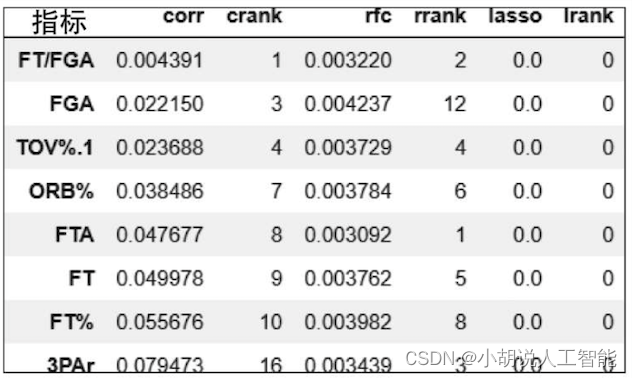
删除相关系数排名与随机森林分类排名之和小于等于20的变量:
tscore_df.loc[(tscore_df.crank+tscore_df.rrank)/2<=10]
#将所有特征名转化为它的前缀名
map_df=pd.Series(feature_df.columns[:-1].str.split('_').str[0].str.replace('\d$',''))
#将所有特征名赋值给map_df的索引
map_df.index=feature_df.columns[:-1]
X=feature_df.drop('Win',axis=1)
#定义特征删除函数
def processdf(X):if 'Win' in X.columns:X.drop('Win',axis=1,inplace=True)for name in X.columns:if map_df[name] in del_name:X.drop(name,axis=1,inplace=True)return(X)
X=processdf(X) #删除显著性较低的特征
2)季后赛特征提取
本部分包括常规赛球队得分、球员、教练数据及数据。
(1)常规赛球队得分
本部分对常规赛场均数据进行处理,形成9个季后赛队伍常规赛得分数据。
相关代码如下:
#引用库
import pandas as pd
import glob
#初始化数据列表
tlist = []
olist = []
#获取数据文件名
tfname = glob.glob('data/team_and_op/*t.csv')
ofname = glob.glob('data/team_and_op/*o.csv')
playfname = glob.glob('data/playoff/*playoff.xlsx')
#初始化赛季标签,从10~11赛季开始
season = 1011
#循环遍历9个赛季的数据
for tname, oname, playoff in zip(tfname, ofname, playfname):#读取队伍数据df = pd.read_csv(tname)#读取队伍对手数据df_ = pd.read_csv(oname)#数据中有的队名随机带*,将其除去读取队伍数据df = pd.read_csv(tname)
#读取队伍对手数据df_ = pd.read_csv(oname)#读取季后赛结果数据tnstats = pd.read_excel(playoff)
#对读取后的对象用replace方法进行处理,代码不再展示
#将队伍数据和对手数据按照排名对齐Rk_index = list(df.columns).index('Rk')Team_index = list(df.columns).index('Team')for i in range(len(df)):for j in range(len(df_)):if df_.iloc[j, Team_index] == df.iloc[i, Team_index]:df_.iloc[j, Rk_index] = df.iloc[i, Rk_index]#队伍对手数据按排名排序df_ = df_.sort_values(by='Rk')#更改DataFrame索引df_.index = range(0, len(df_))#得到十六支季后赛队伍的队名team16 = []team16.extend(tnstats['Teamw'].values)team16.extend(tnstats['Teaml'].values)team16 = list(set(team16))#筛选出16支季后赛队伍的数据,并添加“season”列
df = df[df['Team'].isin(team16)]df_ = df_[df_['Team'].isin(team16)]df['season'] = seasondf_['season'] = season
#将季后赛队伍的常规赛数据添加到列表中
tlist.append(df)
olist.append(df_)
#得到9个赛季季后赛队伍的常规赛场均数据tlist和olist,将列表转化成DataFrame对象
Ostats = pd.concat(olist)
Ostats.index = range(0, len(Ostats))
Tstats = pd.concat(tlist)
Tstats.index = range(0, len(Tstats))
#去掉非数值数据列
newOstat = Ostats.drop(['Rk', 'G', 'MP', 'Team', 'season'], axis=1)
newTstat = Tstats.drop(['Rk', 'G', 'MP', 'Team', 'season'], axis=1)
#得到队伍数据和对手数据的比值
result = newTstat / newOstat
#数据写入文件,包括常规赛队伍对手比值数据和对应的球队、赛季
result.to_csv('./data_regular.csv', sep=',', header=False, index=False)
Tstats.loc[:, ['Team', 'season']].to_csv('./data_regular_team_season.csv', sep=',', header=True, index=False)
队伍的常规赛数据按最大方差旋转法做因子分析,使用Matlab自带的factoran 函数,载荷阵和因子权重,相关代码如下:
clc;
clear all;
data=csvread('E:/pyproject/lpl/data_regular.csv');
[lambda,psi,T,stats,F]=factoran(data,7,'rotate','orthomax');
lambda包含m个公共因子模型的载荷矩阵。m是一个正整数,表示模型中公共因子的个数,本项目选择的公共因子个数为7。lambda是一个d行m列的矩阵,第i行第j列元素表示第i个变量在第j个公共因子上的载荷。
W=sum(lambda.^2);%求权重
%计算因子得分
score=F*W';
%结果输出到文件
f=fopen('E:/pyproject/lpl/factor.csv','a');
for i=1:size(score)fprintf(f,'%f\t',score(i));fprintf(f,'\r\n');
end
载荷阵和因子权重如下表所示。
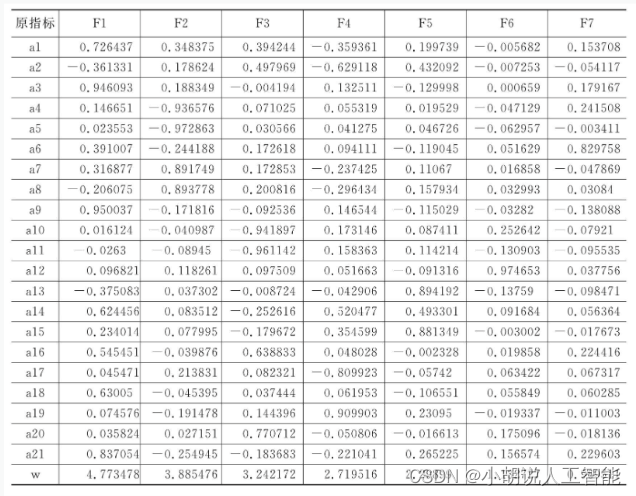
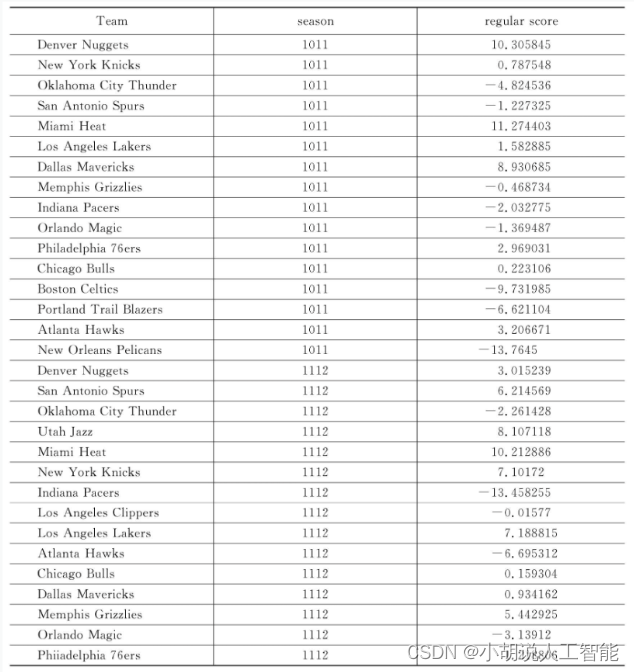
常规赛得到的数据如下表所示。
(2)球员、教练数据及数据整合
本部分代码对赛季球员数据和本赛前的教练执教数据进行处理,整合之前获得的常规赛得分数据,得到9个赛季的季后赛特征Dataframe对象,并写入文件。
相关代码如下:
#引用库
import pandas as pd
import glob
import numpy as np
#赛季标签
season = 1011
#初始化数据列表
player_score = []
coach_score = []
#循环遍历9个赛季的数据
for fname_player, fname_team, fname_coach in \
zip(glob.glob('data/player_score/*player.xlsx'),glob.glob('data/playoff/*playoff.xlsx'),glob.glob('data/coach/*coach.xlsx')):#读取球员数据pstats = pd.read_excel(fname_player)#读取教练数据costats = pd.read_excel(fname_coach)#读取季后赛队伍数据tnstats = pd.read_excel(fname_team)#计算球员得分p1 = pstats['PTS']p2 = pstats['FG']p3 = pstats['FGA']p4 = pstats['FTA']p5 = pstats['FT']p6 = pstats['ORB']p7 = pstats['DRB']p8 = pstats['STL']p9 = pstats['AST']p10 = pstats['BLK']p11 = pstats['PF']p12 = pstats['TOV']pstats['player_score'] = p1 + 0.4 * p2 - 0.7 * p3 - 0.4 * (p4- p5)+0.7*p6 +0.3*p7+p8+0.7 * p9 + 0.7 * p10 - 0.4 * p11 - p12pstats.sort_values(by='player_score', ascending=False, inplace=True)pstats.index = range(0, len(pstats))#得到16支季后赛队伍team16 = []team16.extend(tnstats['Teamw'].values)team16.extend(tnstats['Teaml'].values)team16 = list(set(team16))#获得n和palyer_score特征a = pstats.loc[int(0.1 * len(pstats)), 'player_score']for team in team16:pt = pstats.loc[pstats['Tm'] == team]pt.index = range(0, len(pt))pt_ = pt.loc[pt['player_score'] > a]#如果没有球员达到核心标准,则令player_score第一的为核心if pt_.empty:player_score.append([1, pt.loc[0].player_score, team, season])else:player_score.append([pt_.shape[0], pt_['player_score'].sum(axis=0), team, season])#获得教练数据costats = costats[costats['Tm'].isin(team16)]costats = costats.drop('Coach', axis=1)costats['season'] = seasoncoach_score.extend(costats.values.tolist())
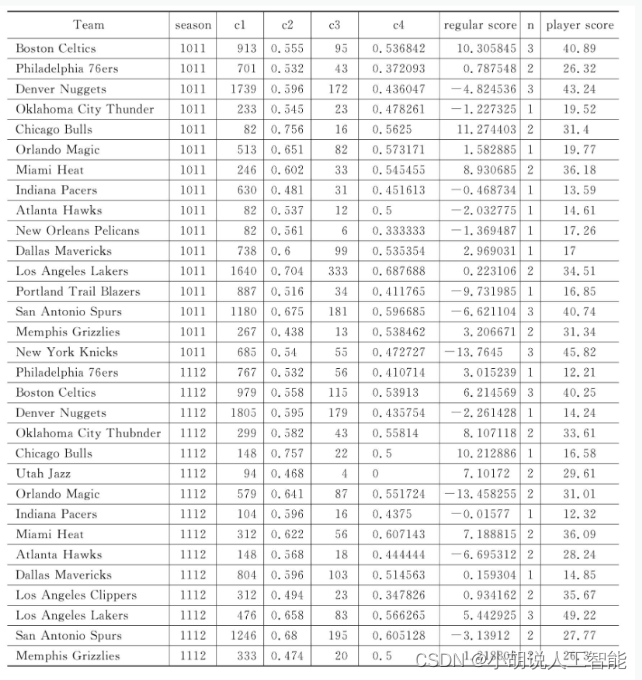
得到9个赛季季后赛队伍的球员数据、教练数据列表player_score和coach_score,将列表转化成DataFrame对象final_data,并与常规赛得分按照队名及赛季进行拼接。
df_player = pd.DataFrame(player_score, columns=['n', 'player_score', 'Team', 'season'])
df_coach = pd.DataFrame(coach_score, columns=['Team', 'c1', 'c2', 'c3', 'c4', 'season'])
final_data = pd.merge(df_player, df_coach, on=['Team', 'season'])
#读取常规赛因子分析数据
regular_score = pd.read_csv('data_regular_team_season.csv')
regular_score['regular_score'] = np.loadtxt('data_factor.csv')
#形成最后的数据框
final_data = pd.merge(final_data, regular_score, on=['Team', 'season'])
#数据写入文件
final_data.to_csv('data_final.csv', header=True, index=False)
最后得到的是9个赛季144支季后赛队伍的特征数据,如下表所示。
相关其它博客
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(一)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(三)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。