爬虫的流程
第一步:获取网页内容
浏览器访问网页时也是一样,都是先发个请求获取网页内容,但是浏览器多了个渲染的步骤。
程序获取的内容都是网页源代码
第二步:解析网页内容

第三步:储存或分析数据
要做数据集就存起来,要做数据分析就形成图标之类的东西
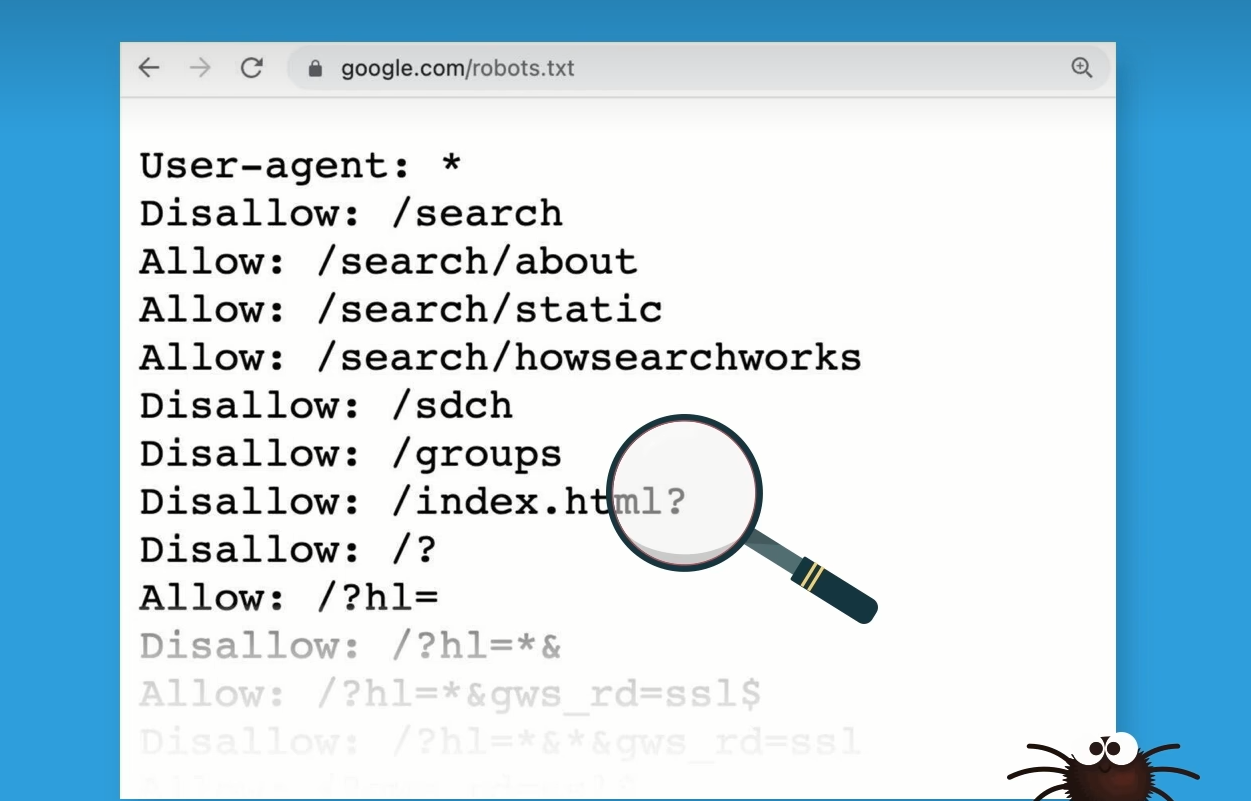
通过robots.txt文件查看可爬取的网页范围
HTTP请求和响应
请求
两个请求方式
完整HTTP请求例子

请求行包括请求的路径和HTTP协议,路径后面+?可以传递额外的查询参数,多用于Get请求,使用&进行分隔。
请求头包含给服务器的信息
Host指主机域名,通过DNS解析后可以找到主机IP,结合请求头里的资源路径就是一个完整的网址。
User-Agent用于告知服务器客户端的相关信息

Accept是告诉服务器客户端想接受的响应数据类型 响应
响应
组成

状态行
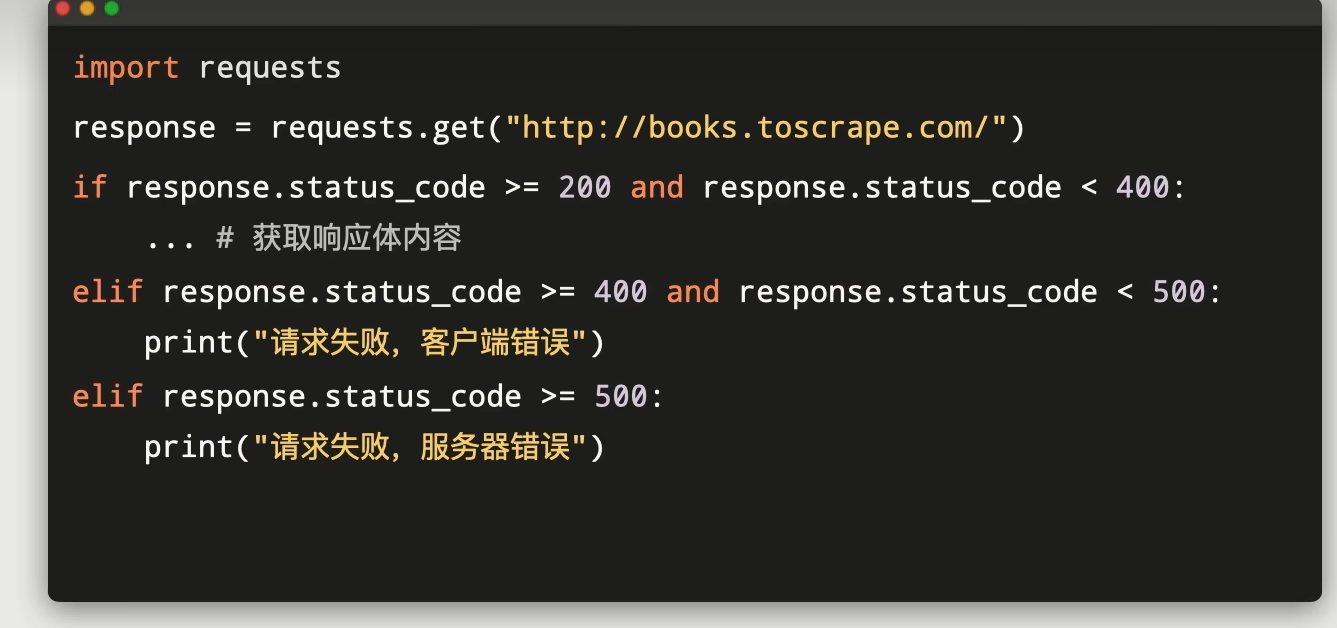
常见状态码
响应头
包含生成响应的时间和返回内容的类型和编码格式
响应体
类型是HTML就返回HTML内容,是JSON就返回json内容
使用Python Requests库发送请求和获取响应数据
首先要先安装Requests库
在终端输入
pip install requests使用requests发送请求,这里网站是我的博客网站
使用requests库发送请求时会自动生成请求头的其他信息,不需要手动指定
import requests
respose=requests.get("http://yhy2002.com/")
print(respose)
#响应的状态码
print(respose.status_code)
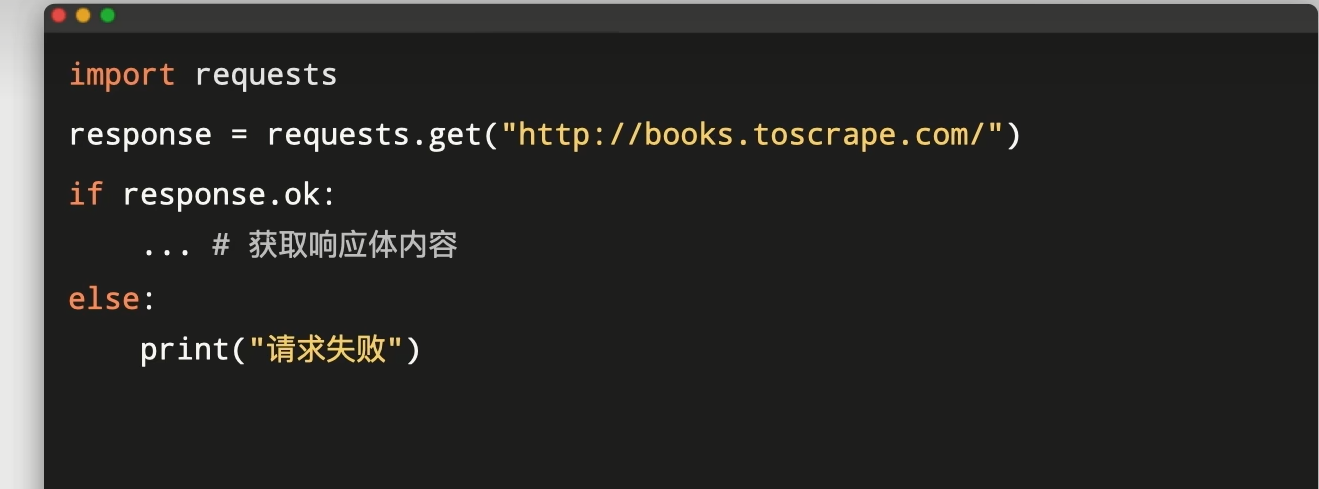
print(respose.ok)
#响应体
print(respose.text)成功获得响应
如果要修改请求头的话要指定一个header的参数
用处:把爬虫程序伪装成正常浏览器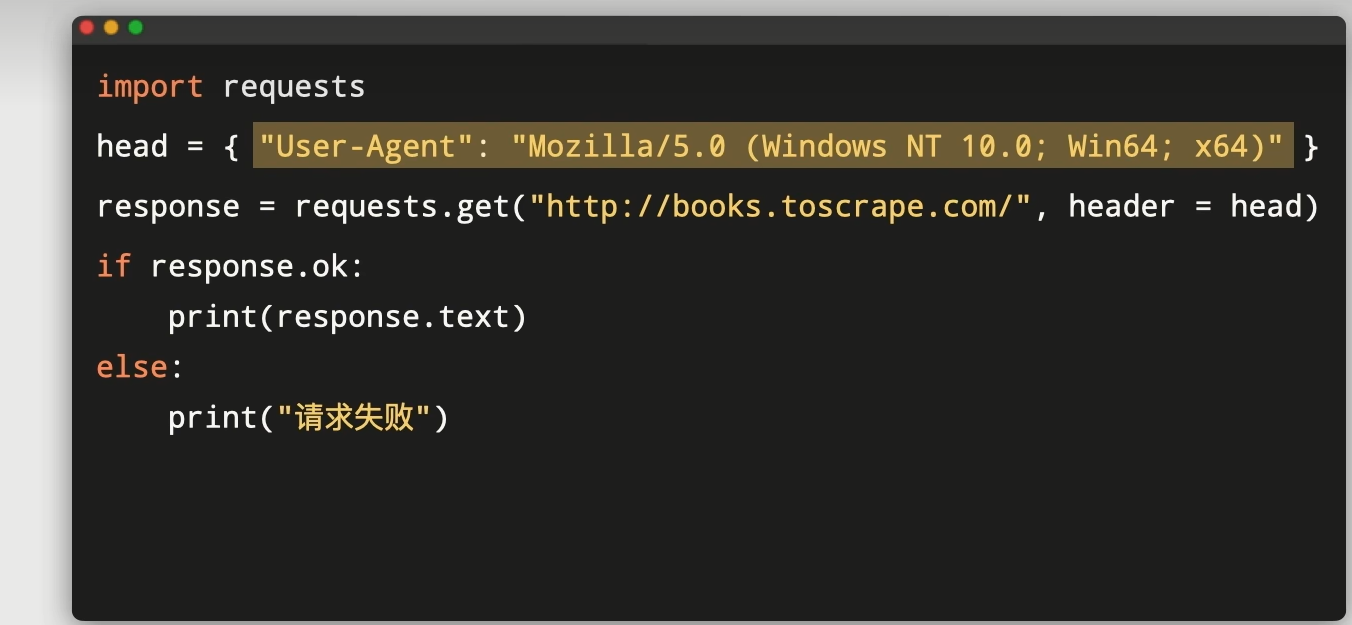
使用浏览器发送请求时请求头会自动带有浏览器类型和版本和电脑操作系统,用代码发送的话不会有。
对于一些网站会过滤非浏览器的请求,拒绝来自程序的请求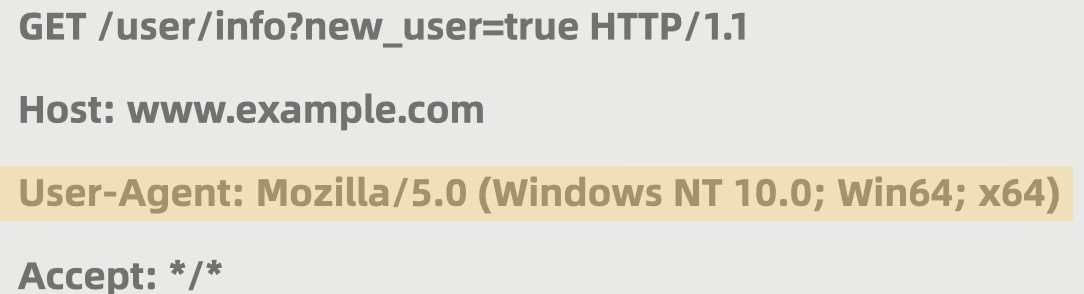

状态码用于判断请求是否成功
使用requests获取豆瓣电影top250的源码
豆瓣电影 Top 250
import requests
response = requests.get("https://movie.douban.com/top250")print(response.status_code)
输出418状态码:这里是因为豆瓣服务器针对爬虫做的处理
自动请求头伪装浏览器
使用f12可以看见右下角有User-Agent:

放到自定义请求头里面即可
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}response = requests.get("https://movie.douban.com/top250", headers=headers)print(response.status_code)
print(response.text)
正常输出
使用Beautiful Soup解析HTML内容
在终端输入
pip install bs4
Beautiful Soup是用到的类,要从bs4进行引入
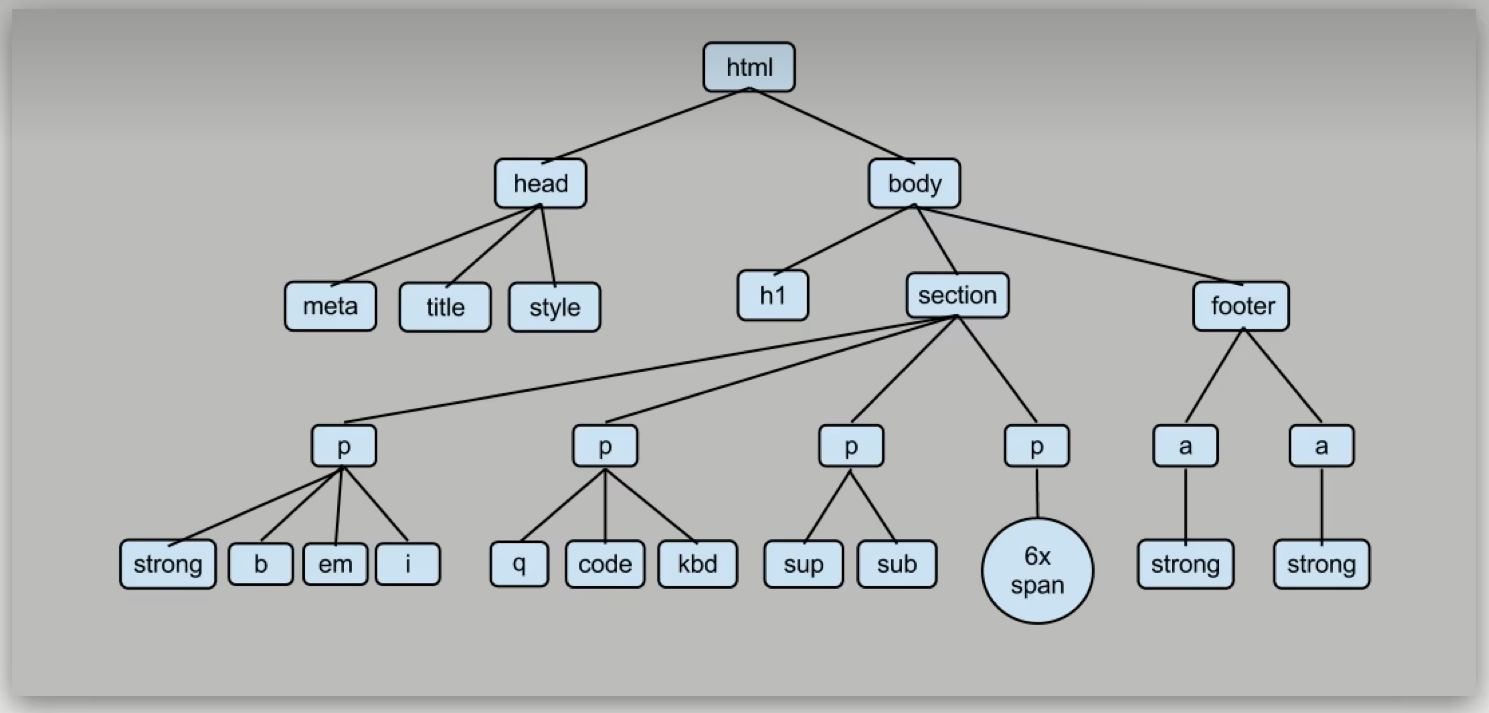
Beautiful Soup会把内容解析成一个树状结构
from bs4 import BeautifulSoup
import requests
content=requests.get("https://www.yhy2002.com/").text
#使用BeautifulSoup解析获取的网页内容,要指定解析器
#并返回一个实例对象
soup=BeautifulSoup(content,"html.parser")#打印第一个title标签内容
print(soup.title)
#打印第一个img标签
print(soup.img)#根据标签和属性造出所有符合要求的元素
list=soup.findAll("img",attrs={})
#attrs={"class":"p_color"},这个可选可不选
for a in list:print(a)#string属性可以把标签包围的文字返回print(a.string)#打印string中索引值大于2的部分print(a.string[2:])输出
查找包含在同一类标签下的子元素

使用findall方法进行两重循环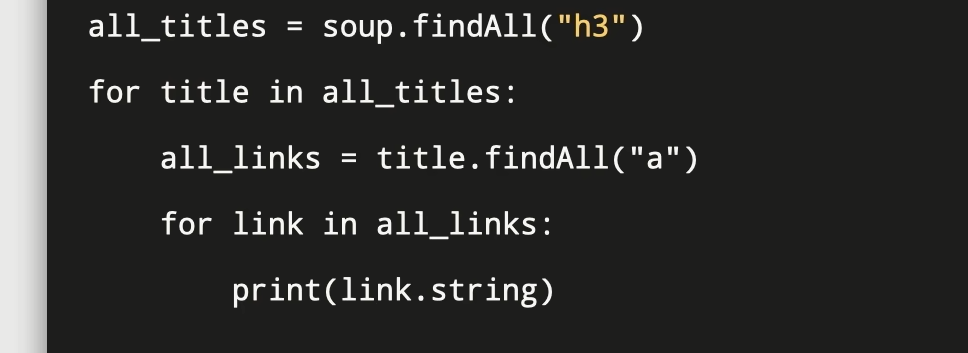
提取豆瓣电影top250的所有标题
可以看见所有标题都是一个span元素,并且class的值都是一个title
from bs4 import BeautifulSoup
import requestsheaders={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
html=requests.get("https://movie.douban.com/top250" , headers=headers).text#获得解析后的实例对象
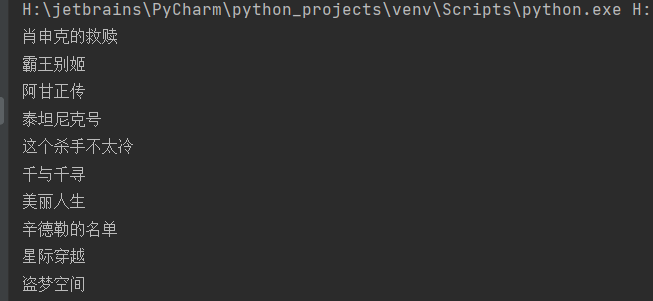
soup = BeautifulSoup(html,"html.parser")all_titles = soup.findAll("span", attrs={"class":"title"})for title in all_titles:title_string=title.stringif("/" not in title_string):print(title.string)
输出获取的第一页25个电影的值
在第二页的链接只是增加了一个https://movie.douban.com/top250?start=25&filter=
start=25&filter=
因此使用for循环+range获取对应页面的电影
from bs4 import BeautifulSoup
import requestsheaders={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
for start_num in range(0,250,25):html=requests.get(f"https://movie.douban.com/top250?start={start_num}" , headers=headers).text#获得解析后的实例对象soup = BeautifulSoup(html,"html.parser")all_titles = soup.findAll("span", attrs={"class":"title"})for title in all_titles:title_string=title.stringif("/" not in title_string):print(title.string)输出:成功获取完整电影名单
H:\jetbrains\PyCharm\python_projects\venv\Scripts\python.exe H:\jetbrains\PyCharm\python_projects\demo.py
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
这个杀手不太冷
千与千寻
美丽人生
辛德勒的名单
星际穿越
盗梦空间
楚门的世界
忠犬八公的故事
海上钢琴师
三傻大闹宝莱坞
放牛班的春天
机器人总动员
无间道
疯狂动物城
控方证人
大话西游之大圣娶亲
熔炉
教父
触不可及
当幸福来敲门
龙猫
怦然心动
末代皇帝
寻梦环游记
活着
蝙蝠侠:黑暗骑士
哈利·波特与魔法石
指环王3:王者无敌
乱世佳人
我不是药神
飞屋环游记
素媛
哈尔的移动城堡
十二怒汉
何以为家
摔跤吧!爸爸
让子弹飞
鬼子来了
天空之城
猫鼠游戏
少年派的奇幻漂流
海蒂和爷爷
钢琴家
大话西游之月光宝盒
指环王2:双塔奇兵
闻香识女人
罗马假日
天堂电影院
死亡诗社
绿皮书
大闹天宫
黑客帝国
指环王1:护戒使者
教父2
狮子王
辩护人
饮食男女
搏击俱乐部
美丽心灵
本杰明·巴顿奇事
穿条纹睡衣的男孩
窃听风暴
情书
两杆大烟枪
西西里的美丽传说
音乐之声
看不见的客人
阿凡达
拯救大兵瑞恩
小鞋子
飞越疯人院
哈利·波特与死亡圣器(下)
沉默的羔羊
布达佩斯大饭店
禁闭岛
蝴蝶效应
致命魔术
功夫
心灵捕手
海豚湾
哈利·波特与阿兹卡班的囚徒
低俗小说
春光乍泄
超脱
美国往事
摩登时代
喜剧之王
致命ID
杀人回忆
七宗罪
红辣椒
加勒比海盗
哈利·波特与密室
一一
狩猎
唐伯虎点秋香
7号房的礼物
被嫌弃的松子的一生
请以你的名字呼唤我
断背山
剪刀手爱德华
入殓师
爱在黎明破晓前
勇敢的心
蝙蝠侠:黑暗骑士崛起
第六感
重庆森林
幽灵公主
超能陆战队
爱在日落黄昏时
菊次郎的夏天
甜蜜蜜
天使爱美丽
阳光灿烂的日子
借东西的小人阿莉埃蒂
小森林 夏秋篇
完美的世界
消失的爱人
无人知晓
倩女幽魂
寄生虫
时空恋旅人
侧耳倾听
小森林 冬春篇
幸福终点站
驯龙高手
一个叫欧维的男人决定去死
教父3
未麻的部屋
萤火之森
怪兽电力公司
哈利·波特与火焰杯
傲慢与偏见
玩具总动员3
新世界
釜山行
神偷奶爸
被解救的姜戈
玛丽和马克思
告白
大鱼
哪吒闹海
射雕英雄传之东成西就
喜宴
茶馆
头号玩家
模仿游戏
阳光姐妹淘
九品芝麻官
我是山姆
花样年华
色,戒
血战钢锯岭
恐怖直播
七武士
头脑特工队
惊魂记
黑客帝国3:矩阵革命
你的名字。
电锯惊魂
三块广告牌
达拉斯买家俱乐部
疯狂原始人
心迷宫
谍影重重3
上帝之城
英雄本色
卢旺达饭店
纵横四海
风之谷
海街日记
爱在午夜降临前
绿里奇迹
记忆碎片
岁月神偷
忠犬八公物语
疯狂的石头
荒蛮故事
雨中曲
小丑
背靠背,脸对脸
小偷家族
2001太空漫游
爆裂鼓手
无敌破坏王
无间道2
心灵奇旅
贫民窟的百万富翁
冰川时代
恐怖游轮
东邪西毒
牯岭街少年杀人事件
魔女宅急便
遗愿清单
东京教父
你看起来好像很好吃
真爱至上
大佛普拉斯
黑天鹅
可可西里
城市之光
源代码
雨人
海边的曼彻斯特
恋恋笔记本
初恋这件小事
人工智能
波西米亚狂想曲
虎口脱险
青蛇
终结者2:审判日
疯狂的麦克斯4:狂暴之路
罗生门
萤火虫之墓
新龙门客栈
千钧一发
末路狂花
崖上的波妞
无耻混蛋
奇迹男孩
彗星来的那一夜
二十二
花束般的恋爱
黑客帝国2:重装上阵
爱乐之城
血钻
战争之王
房间
步履不停
芙蓉镇
魂断蓝桥
火星救援
哈利·波特与死亡圣器(上)
千年女优
谍影重重2
弱点
阿飞正传
谍影重重
燃情岁月
朗读者
白日梦想家
再次出发之纽约遇见你
哈利·波特与凤凰社
蜘蛛侠:平行宇宙
香水
穿越时空的少女
扩展:
使用正则表达式可以更加精确的匹配一个或者多个目标字符

使用多线程可以同时爬取多个页面