Gemini: A Computation-Centric Distributed Graph Processing System
Gemini: 以计算为中心的分布式图处理系统 [Paper] [Slides] [Code]
OSDI’16
摘要
提出了 Gemini, 一个分布式图处理系统, 应用了多种针对计算性能的优化以在效率之上构建可扩展性.
Gemini 采用:
- 稀疏-稠密信号槽抽象, 将混合推拉计算模型扩展到分布式场景
- 基于分块的划分(chunk-based partition)方案, 可实现低开销的横向扩展和保留局部性的结点访问
- 压缩结点索引访问的双重表示方案
- 用于高效节点内内存访问的 NUMA 感知子划分
- 用于改善节点间和节点内的负载均衡的局部感知分块和细粒度工作窃取
1 介绍
许多分布式图处理系统被提出, 但与最先进的共享内存系统相比性能不尽人意.
为了获得更好的整体性能, 需要同时关注计算和通信组件的性能, 在隐藏通信开销的同时积极压缩计算时间.
提出了 Gemini, 一个在效率之上构建可扩展性的分布式图处理系统.
本文贡献:
- 对几个现有的共享内存和分布式的图并行系统进行了详细分析, 并发现了多个设计缺陷.
- 探索了自适应的运行时选择, 如密度感知的双模处理方案、多个局部性感知的数据分布和负载平衡机制, 使得系统在从多核到多节点的规模上提供具有竞争力的性能.
- 确定了一种简单但效果惊人的基于分块的图划分方案, 并提出了由这种新划分方法实现的多种优化.
- 大量实验评估表明 Gemini 显著优于现有的分布式实现.
2 动机
现有的分布式图处理系统可以扩展到比共享内存系统更大的处理规模, 但性能和开销不尽人意.
设计分布式图并行系统时, 通过在效率之上构建可扩展性, 而非只关注可扩展性.
3 Gemini 图处理抽象
3.1 双重更新传播模型
Gemini 使用了 PowerGraph 的 master-mirror(主镜) 概念:
- 每个结点被分配给一个分区, 结点在该分区为 master(主) 结点, 作为维护结点状态数据的主副本.
- 同一结点在拥有其至少一个邻结点的节点/分区上有副本, 称为 mirrors(镜像) 结点.
Gemini 采用稀疏-稠密双模式引擎设计, 使用信号-槽(signal-slot)抽象将结点状态(通信)与边处理(计算)分离.
信号和槽表示用户定义的以结点为中心的函数, 分别描述消息的发送和接收行为.
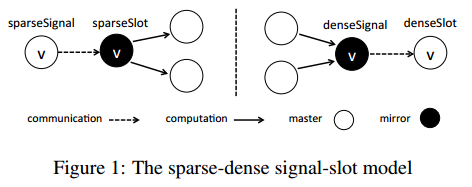
- 稀疏(推)模式:
- master 结点先通过
sparseSignal向 mirror 结点发送包含最新结点状态的消息 - mirror 结点通过
sparseSlot沿出边依次更新其邻结点
- master 结点先通过
- 稠密(拉)模式:
- mirror 结点先沿入边根据邻结点状态执行本地计算, 然后通过
denseSignal将包含结果的更新消息发送给 master 结点 - master 结点通过
denseSlot更新自身状态
- mirror 结点先沿入边根据邻结点状态执行本地计算, 然后通过
消息组合(message combining)自动启用:
每个结点的每个激活的 master-mirror 对只需要一条消息, 将消息数量从 O ( ∣ E ∣ ) O(|E|) O(∣E∣) 降低到 O ( ∣ V ∣ ) O(|V|) O(∣V∣).
允许在本地执行计算以聚合传出更新, 而无需采用额外的"组合过程(combining pass)".
3.2 Gemini API
核心 API:

- 并非所有的用户定义函数都是必须的.
- 双模式处理是可选的.
连通分量(Connected Components, CC)算法示例:


4 分布式图表示
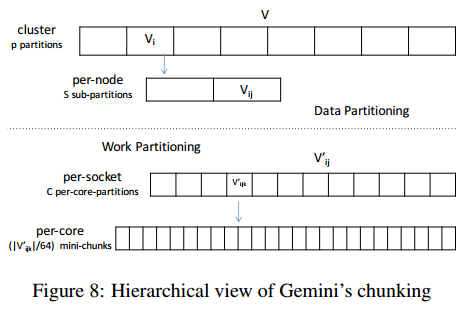
提出了一种轻量级、基于分块的多级划分方案, 并提出了几种关于图划分和内部表示的设计选择.
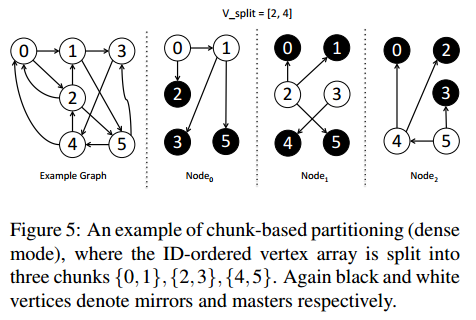
4.1 基于分块划分
划分结点集为连续的分块可以有效保留局部性.
在 p p p 个节点的集群上, 给定全局图 G = ( V , E ) G=(V,E) G=(V,E) 划分为 p p p 个子图 G i = ( V i ′ , E i ) , i from 0 to ( p − 1 ) G_i=(V'_i,E_i), i\text{ from }0\text{ to }(p-1) Gi=(Vi′,Ei),i from 0 to (p−1).
- V i ′ V'_i Vi′ 和 E i E_i Ei: 第 i i i 个分区的结点子集和边子集.
- V i V_i Vi: 第 i i i 个分区拥有的(master)结点子集.
Gemini 划分 G G G 使用一个简单的基于分块的方案, 将 V V V 划分为 p p p 个连续的结点分块 ( V 0 , V 1 , . . . , V p − 1 ) (V_0,V_1,...,V_{p-1}) (V0,V1,...,Vp−1).
每个分块 ( V i V_i Vi) 被分配给一个集群节点, 该节点拥有该分块的所有结点.
- 分区 i i i 的出边集 (用于稀疏模式): E i S = { ( s r c , d s t , v a l u e ) ∈ E ∣ d s t ∈ V i } E_i^S=\{(src,dst,value)\in E|dst\in V_i\} EiS={(src,dst,value)∈E∣dst∈Vi}
- 分区 i i i 的入边集 (用于稠密模式): E i D = { ( s r c , d s t , v a l u e ) ∈ E ∣ s r c ∈ V i } E_i^D=\{(src,dst,value)\in E|src\in V_i\} EiD={(src,dst,value)∈E∣src∈Vi}
(注: 此处的出/入边集与表达式中 d s t / s r c ∈ V i dst/src\in V_i dst/src∈Vi 看起来有冲突, 但实际上 V i V_i Vi 表示分区的 master 结点集, 并不在图结构 BCSR/DCSC 的索引数组中记录, 而是以邻接表的形式记录. 对于 BCSR/DCSC 中的索引数组, E i S E_i^S EiS/ E i D E_i^D EiD 分别是出/入边集.)
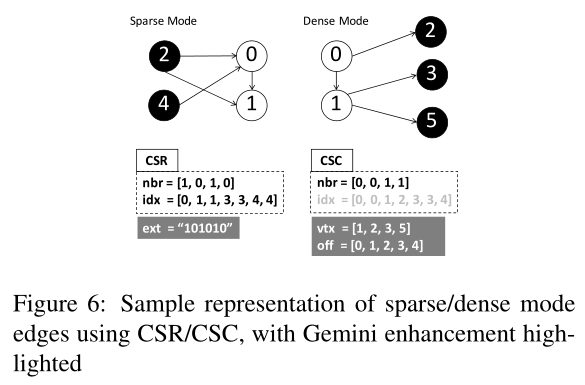
4.2 双模式边表示
CSR/CSC 格式索引数组 idx 可能成为扩展瓶颈.
使用两种方案分别增强两种模式的索引数组:
- 位图辅助压缩稀疏行(Bitmap Assisted Compressed Sparse Row, BCSR):
针对稀疏模式的边, 添加了一个标记每个结点在该分区是否有出边的存在位图ext. - 双压缩稀疏列(Doubly Compressed Sparse Column, DCSC):
针对稠密模式的边, 仅存储具有入边的结点(vtx)及其相应的边偏移(off,(off[i+1]-off[i])表示结点vtx[i]具有的本地入边数).
4.3 局部性感知分块
Gemini 采用了一种在设置平衡标准时同时考虑拥有的(master)结点和稠密模式边的混合度量.
划分结点数组 V V V 使得每个分区具有 α ⋅ ∣ V i ∣ + ∣ E i D ∣ \alpha\cdot|V_i|+|E^D_i| α⋅∣Vi∣+∣EiD∣ 的平衡值.
- α \alpha α 为可配置参数, 实验中根据经验设置为 8 ⋅ ( p − 1 ) 8\cdot(p−1) 8⋅(p−1).
4.4 NUMA 感知子划分
Gemini 基于分块的图划分允许系统以相同的方式递归地应用子划分, 并在每个特定级别都有适用不同的优化.
在一个节点中, Gemini 在多个 socket 之间应用 NUMA 感知的子划分:
对于每个包含 s s s 个 socket 的节点, 结点分块 V i V_i Vi 被进一步划分成 s s s 个子块, 每个 socket 一个; 边使用与节点间划分相同的规则(4.1 节)分配给相应的 socket.
5 任务调度
Gemini 遵循批量同步并行(Bulk Synchronous Parallel, BSP)模型.
5.1 计算与通信任务协同调度
Gemini 将集群节点组织成一个环, 以平衡的循环方式协调消息发送和接收操作.
在具有 c c c 个核的节点上, Gemini 维护一个具有 c c c 个线程的 OpenMP 线程池, 用于并行边处理、执行 signal 和 slot 任务; 每个线程使用 NUMA 感知的子划分绑定到特定 socket 上.
每个节点创建两个助手线程用于通过 MPI 进行节点间的消息发送/接收操作.
基于分块的划分和 CSR/CSC, 可以以稀疏和稠密模式批处理发往同一分区的消息; 并以面向分区的方式调度任务.
每轮迭代分为 p p p (集群节点数)个 mini-step(小步骤), 每个 mini-step 中 n o d e i node_i nodei 按照从 n o d e i + 1 node_{i+1} nodei+1 到自己的顺序与每个对等节点通信.
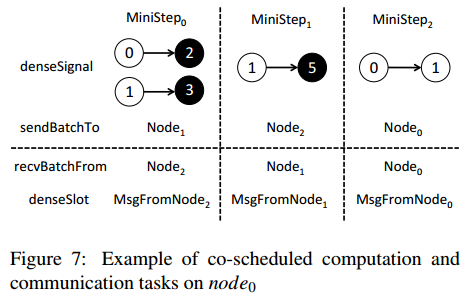
5.2 细粒度工作窃取
Gemini 利用共享内存采用细粒度的工作窃取调度程序进行节点内边处理.
每个线程在 OpenMP 并行区域内仅获取待处理(signal / slot)结点的一小个分块(mini-chunk), mini-chunk 大小默认设置为 64 个结点.
每个线程首先完成自己所在核心的分区, 然后开始从其他线程的分区中窃取 mini-chunk.
Gemini 基于多级分块的划分:
6 实现
约 2800 行 C++ 代码, 使用 MPI 进行进程间通信, 使用 libnuma 进行 NUMA 感知的内存分配.
图加载:
从输入文件加载图时, 每个节点并行读取其分配的连续部分, 边按顺序分批加载到边缓冲区中.
图划分:
加载边时计算每个结点的度数并使用 AllReduce 收集, 用于划分结点集.
然后每个节点先进行本地划分, 再从文件中重新加载边并分发到目标节点构建局部子图.
内存分配:
所有节点共享节点间消息传递的节点级分区边界, 而 socket 级子分区信息保持节点私有.
每个节点在共享内存中分配整个结点数组.
Gemini 划分每个节点的结点分区为子分块, 并置于相应的 socket 上. 数据图的边和结点索引也采用 NUMA 感知的分配.
模式选择:
对于每个 ProcessEdges 操作, Gemini 首先调用一个(基于 ProcessVertices 接口的)内部操作获取激活边数, 并由此确定处理模式(稀疏或稠密).
并行处理:
每个 OpenMP 线程固定到特定 socket 上防止线程迁移.
对于工作窃取, 每个线程维护状态(WORKING 或 STEALING)、当前 mini-chunk 起始偏移、预先计算的结束偏移; 并可供其他线程访问并以 NUMA 感知的对齐方式分配. 每个线程从自己的分区开始工作, 完成更改状态, 并尝试以循环方式从高序号线程窃取工作.
并发控制通过 OpenMP 隐式同步机制实现.
消息传递:
每个节点运行一个进程, 使用 MPI 进行节点间消息传递.
在 socket 间, 每个 socket 通过其对应的发送和接收缓冲区生成/使用消息.
7 评估
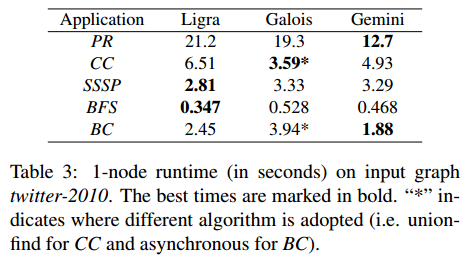
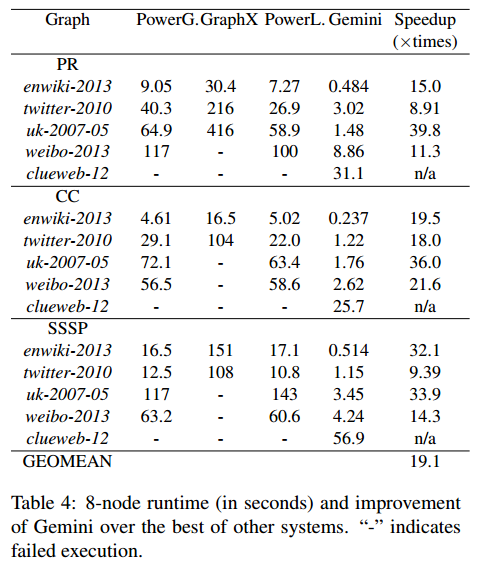
性能: Table 3(共享内存), Table 4(分布式)
内存消耗: Table 5
扩展性: Figure 9, Figure 10, Table 6
设计选择: Figure 11 ~ 14, Table 7 ~ 9
笔者总结
本文的核心是提出了一个在效率之上构建可扩展性的分布式图计算系统, 通过稀疏-稠密信号槽抽象、双模式边表示(BCSR/DCSC)以及多级图划分(节点级、socket 级、线程级)等方法提高了分布式图计算系统的计算性能.
Gemini 属于分布式图计算系统.