目录
一、目标1:使用etree解析数据
二、目标2:使用xpath爬取指定数据
三、目标3:提取指定数据
四、网络安全小圈子
一、目标1:使用etree解析数据
其余的不用过多介绍,前面的练习都给大家已经过了一遍
def get_page():url = 'https://www.chinaz.com/'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0",}res1 = requests.get(url, headers=headers, timeout=10)res = res1.content.decode('utf-8') tree = etree.HTML(res)其中数据解析代码如下
tree = etree.HTML(res)对返回的内容进行UTF-8解码,不然会出现乱码
res = res1.content.decode('utf-8') 二、目标2:使用xpath爬取指定数据
我们来爬一下这几个标题
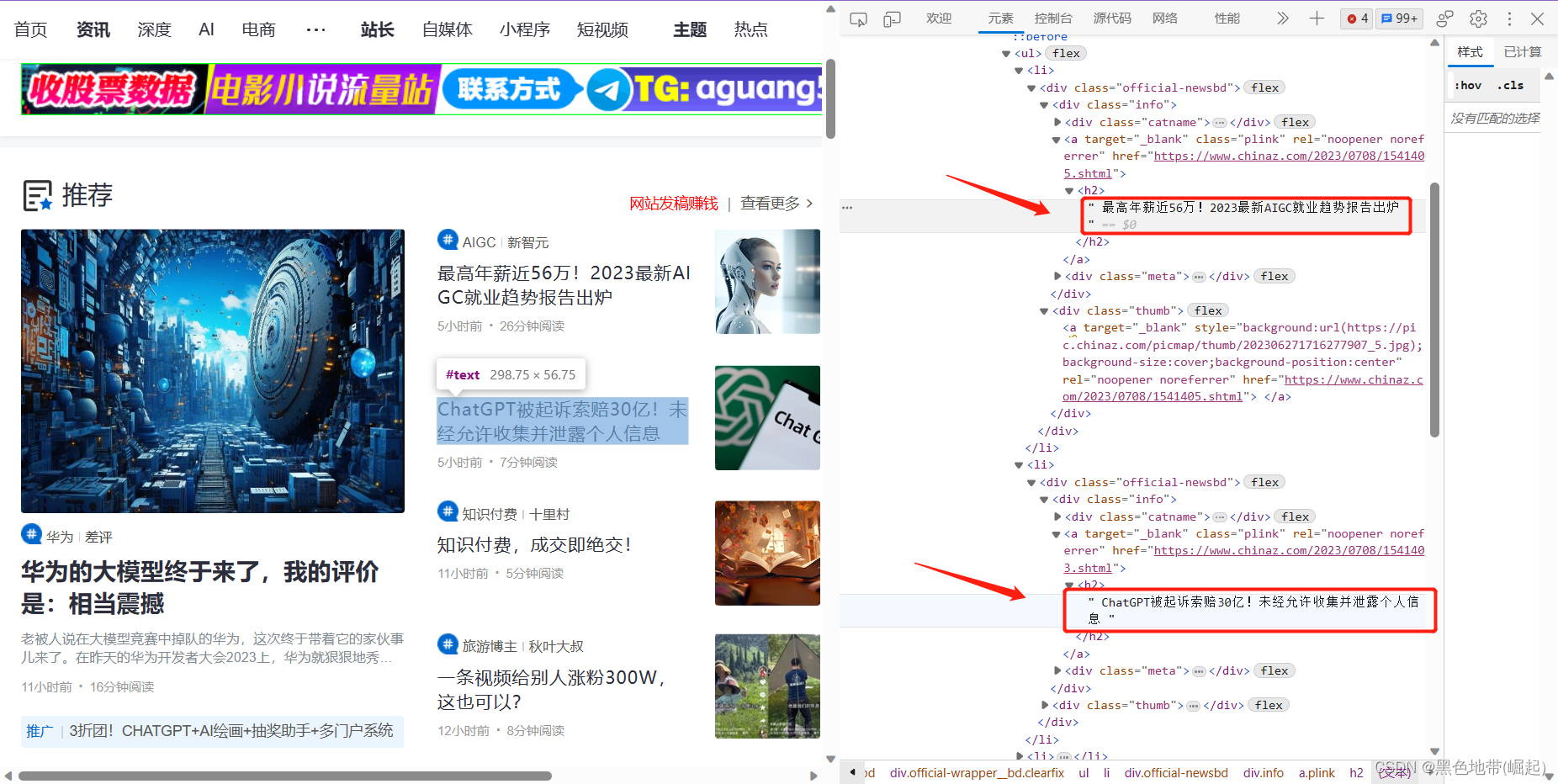
找上一级
可以看到他们都在不同li标签下
所以他们的上一级标签ul相当于是我们的列表合集

定位xpath路径
定位li的xpath路径
因为我们要获取到ul下所有li列表
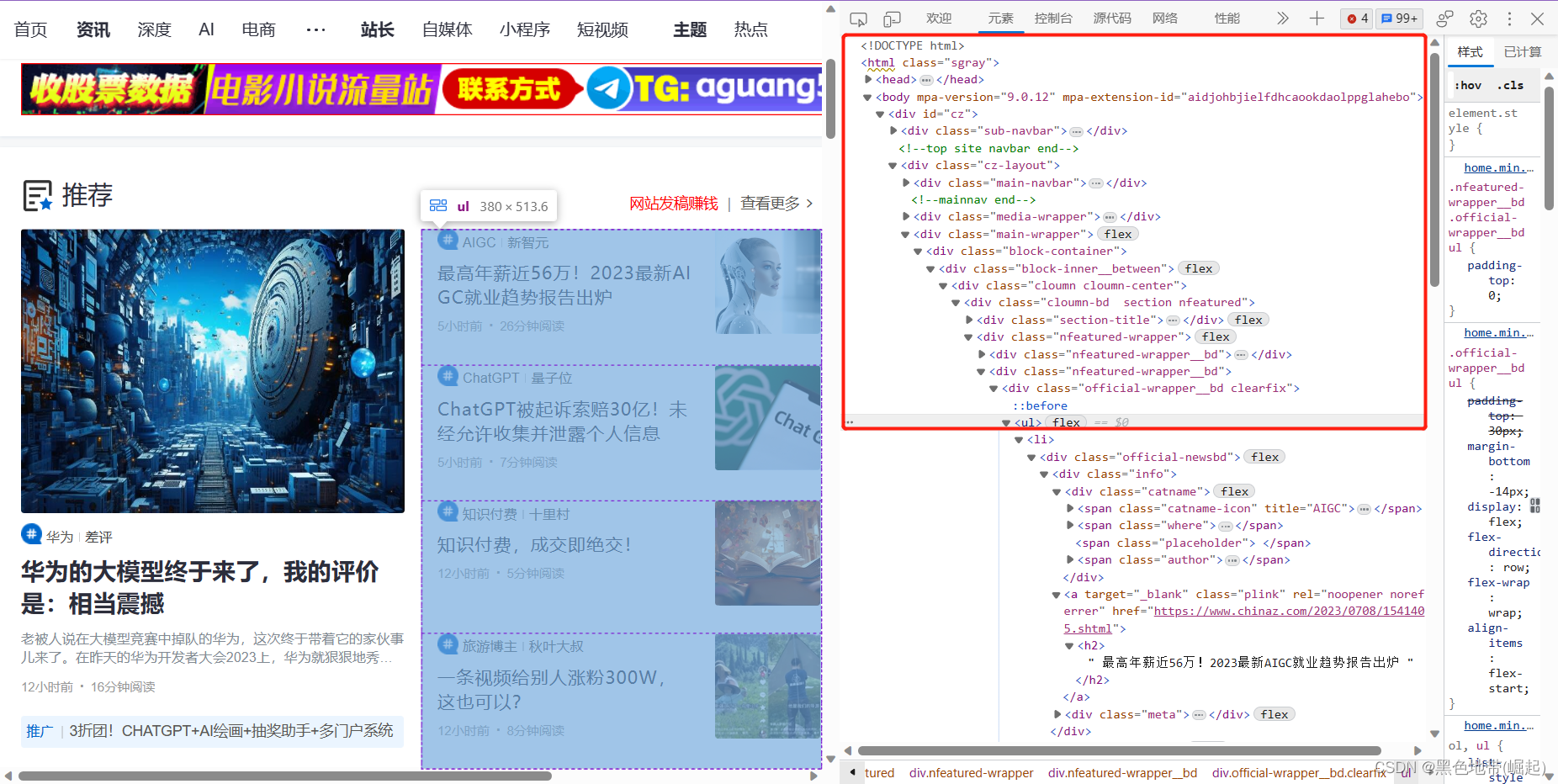
xpath路径如下
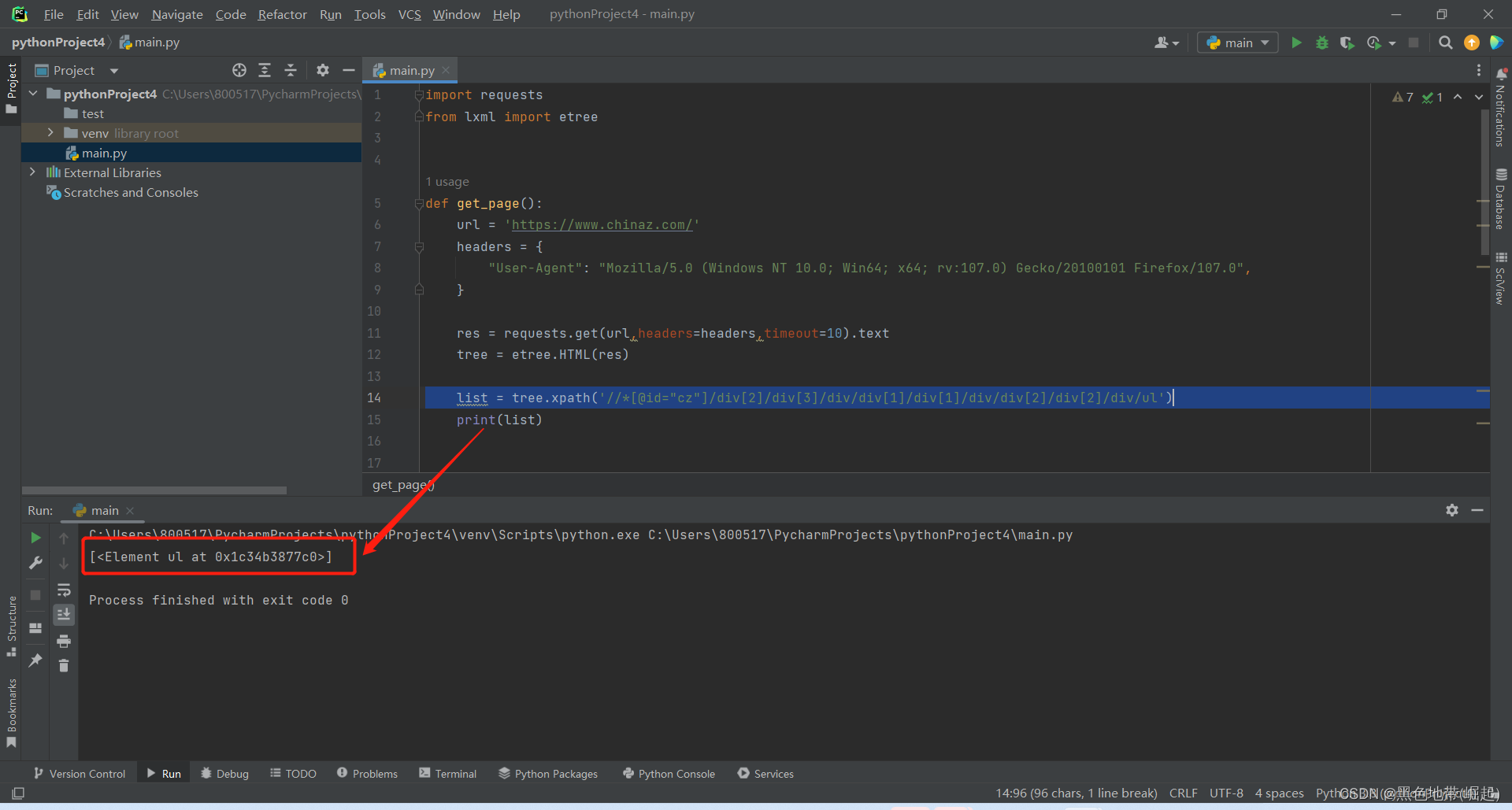
list = tree.xpath('//*[@id="cz"]/div[2]/div[3]/div/div[1]/div[1]/div/div[2]/div[2]/div/ul/li')
打印出来可以看见
三、目标3:提取指定数据
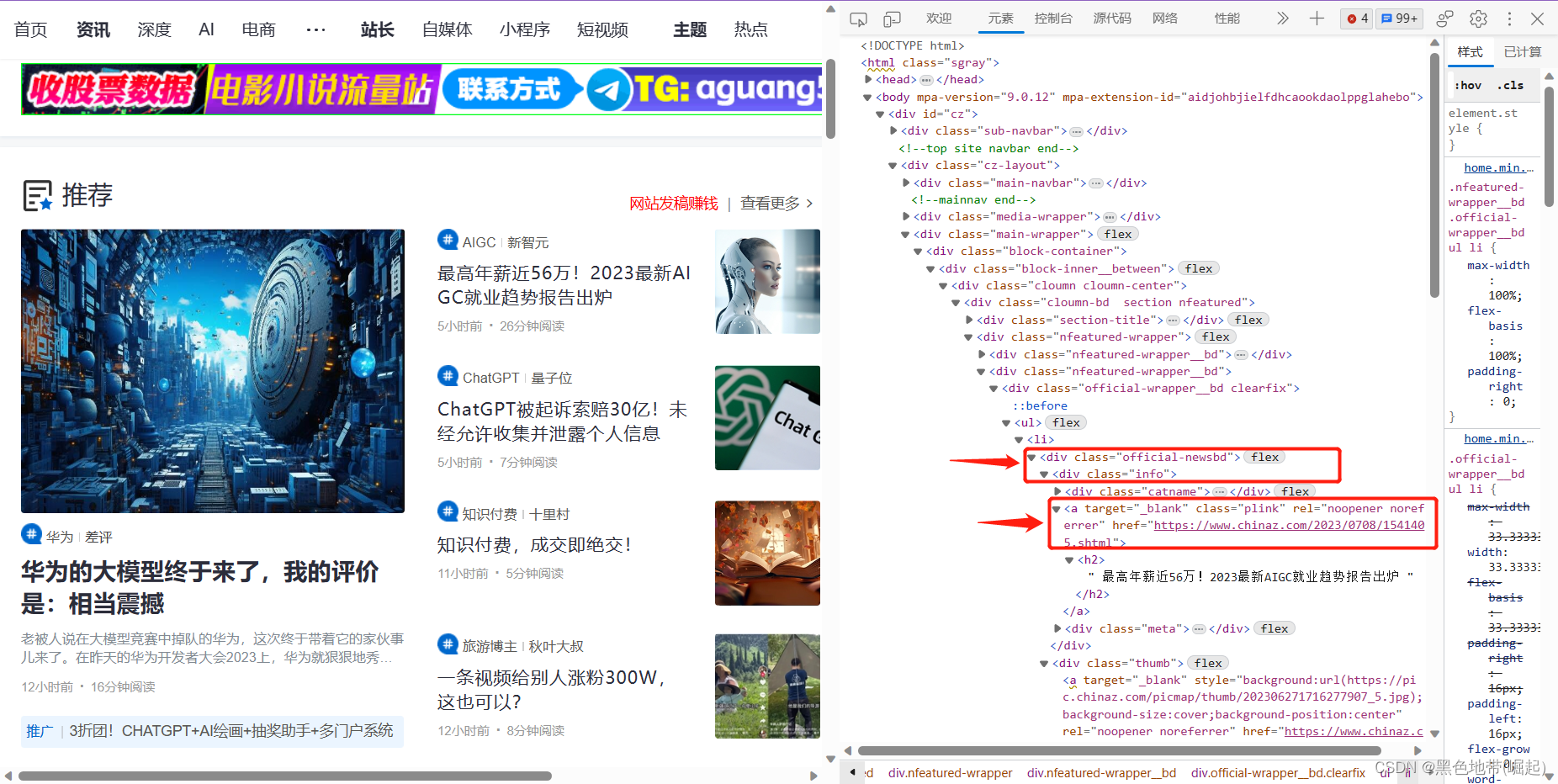
定位xpath
然后还有3个标签才到h2标签
遍历每一个目标标签,并转为text()格式
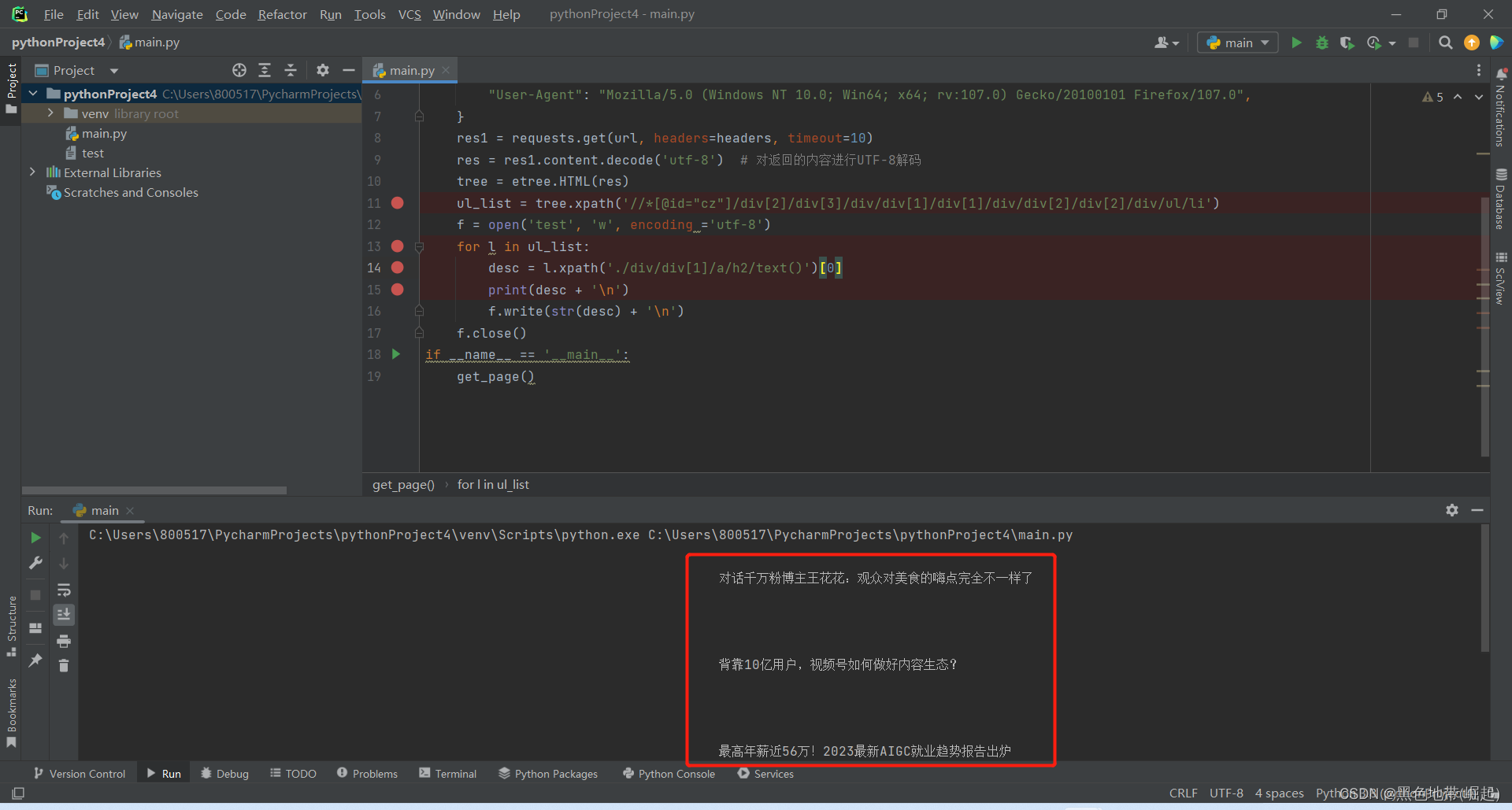
f = open('test', 'w', encoding ='utf-8')for l in ul_list:desc = l.xpath('./div/div[1]/a/h2/text()')[0]print(desc + '\n')f.write(str(desc) + '\n')f.close()运行结果
完整代码
import requests
from lxml import etree
def get_page():url = 'https://www.chinaz.com/'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0",}res1 = requests.get(url, headers=headers, timeout=10)res = res1.content.decode('utf-8') tree = etree.HTML(res)ul_list = tree.xpath('//*[@id="cz"]/div[2]/div[3]/div/div[1]/div[1]/div/div[2]/div[2]/div/ul/li')f = open('test', 'w', encoding ='utf-8')for l in ul_list:desc = l.xpath('./div/div[1]/a/h2/text()')[0]print(desc + '\n')f.write(str(desc) + '\n')f.close()
if __name__ == '__main__':get_page()四、网络安全小圈子
README.md · 书半生/网络安全知识体系-实战中心 - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/shubansheng/Treasure_knowledge/blob/master/README.md
https://gitee.com/shubansheng/Treasure_knowledge/blob/master/README.md
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge


![[论文笔记] Gemini: A Computation-Centric Distributed Graph Processing System](https://img-blog.csdnimg.cn/7ca38389aa1744bfaa608ee97e1490a7.png)