文章目录
- 来源
- transformer的全局理解
- 位置编码
- 多头注意力机制
- 残差
- Batch Normal
- Layer Normal
- Decoder
来源
b站链接
transformer的全局理解
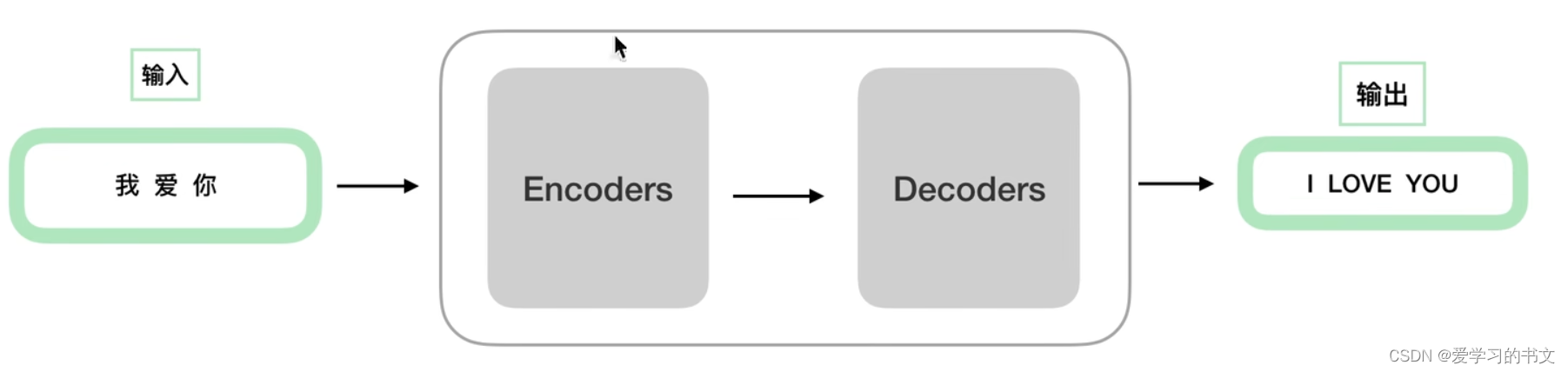
输入中文,输出英文
 细化容易理解的结构,就是先编码,再解码
细化容易理解的结构,就是先编码,再解码
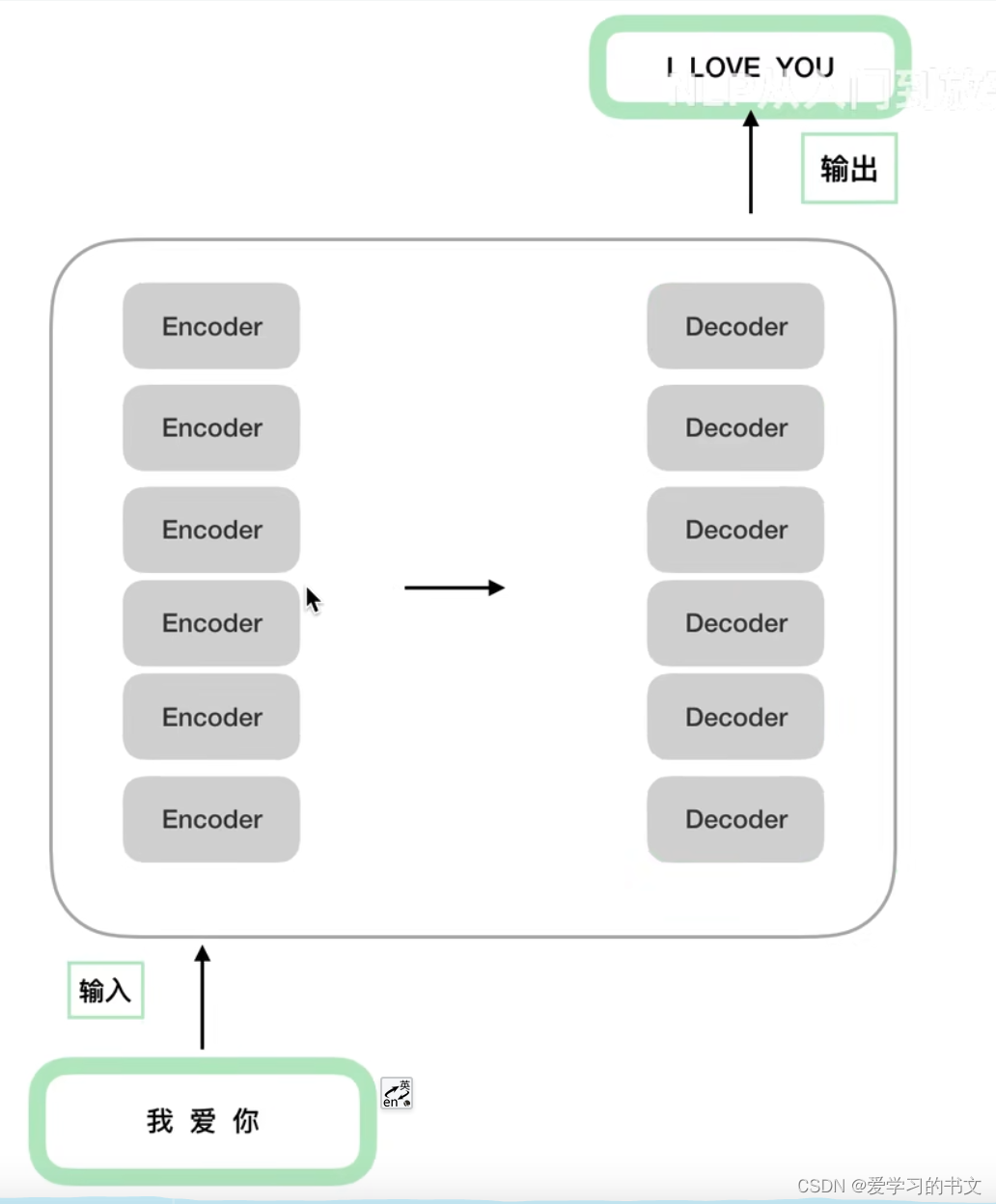
 进一步细化的结构,就是多个编码器和多个解码器,每个器件的结构一样,但是具体的参数可以不同,参数是独立训练的
进一步细化的结构,就是多个编码器和多个解码器,每个器件的结构一样,但是具体的参数可以不同,参数是独立训练的
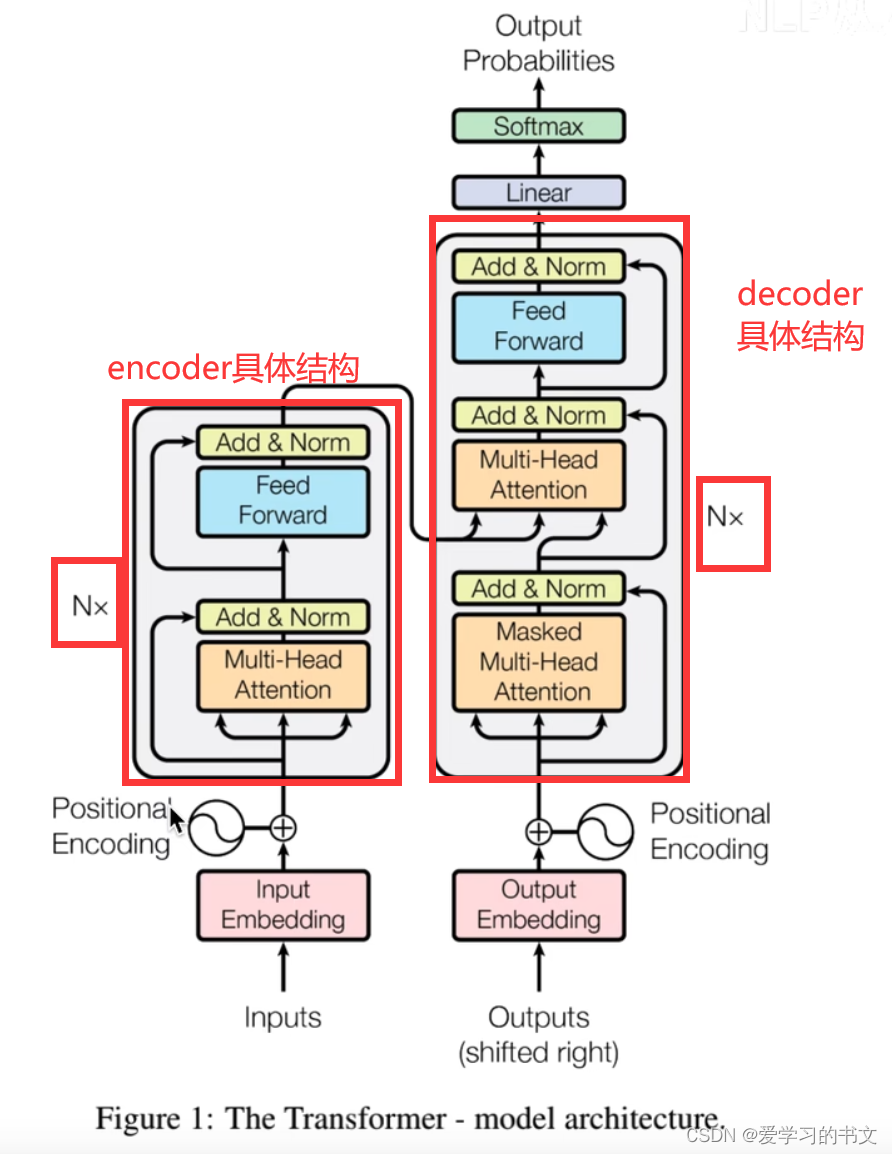
 transformer的具体结构和上面类似
transformer的具体结构和上面类似
位置编码
分为两部分:
- embedding
- 位置嵌入
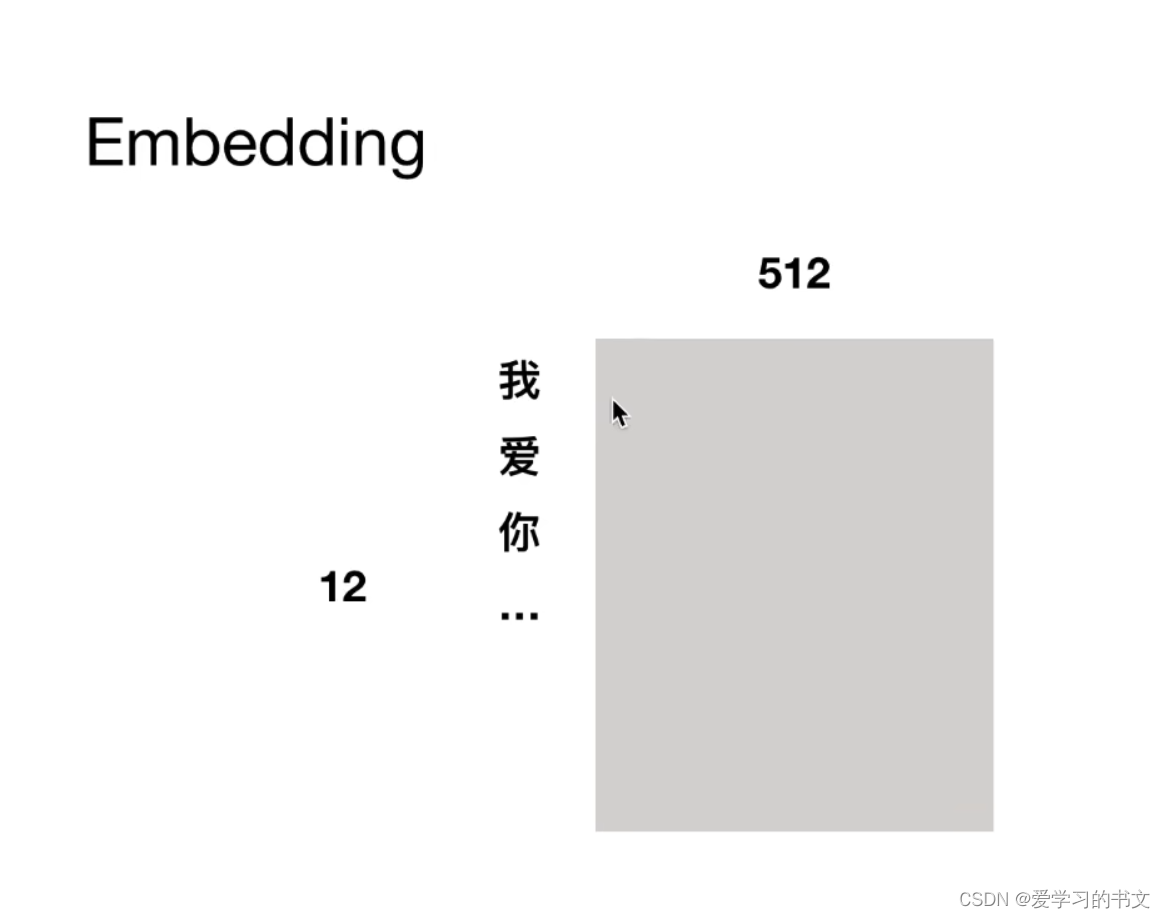
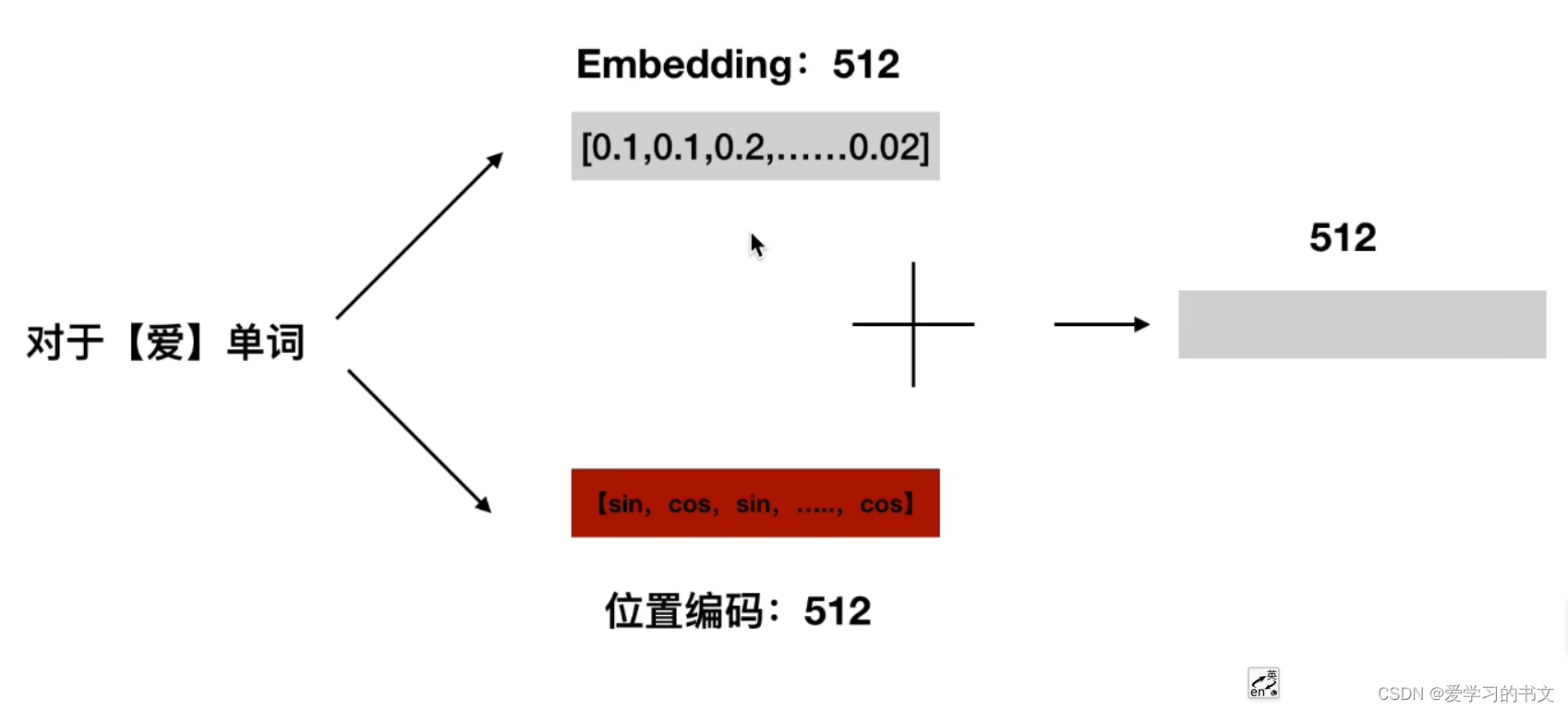
多个字,每个字对应一个512维的向量
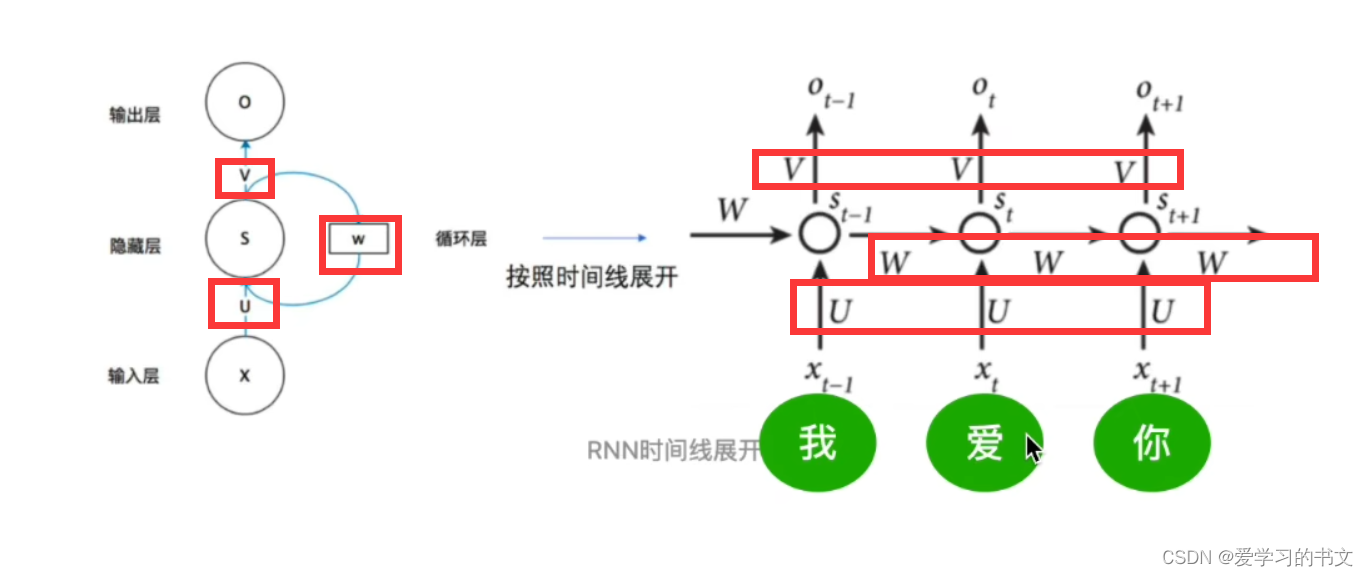
RNN是共享一套W、U、V参数的,所以只能等处理完“我”,才能接下来处理“爱”/“你”,时序的。
而transformer并行处理,则需要位置编码告诉网络,“我爱你”三个字之间的位置关系
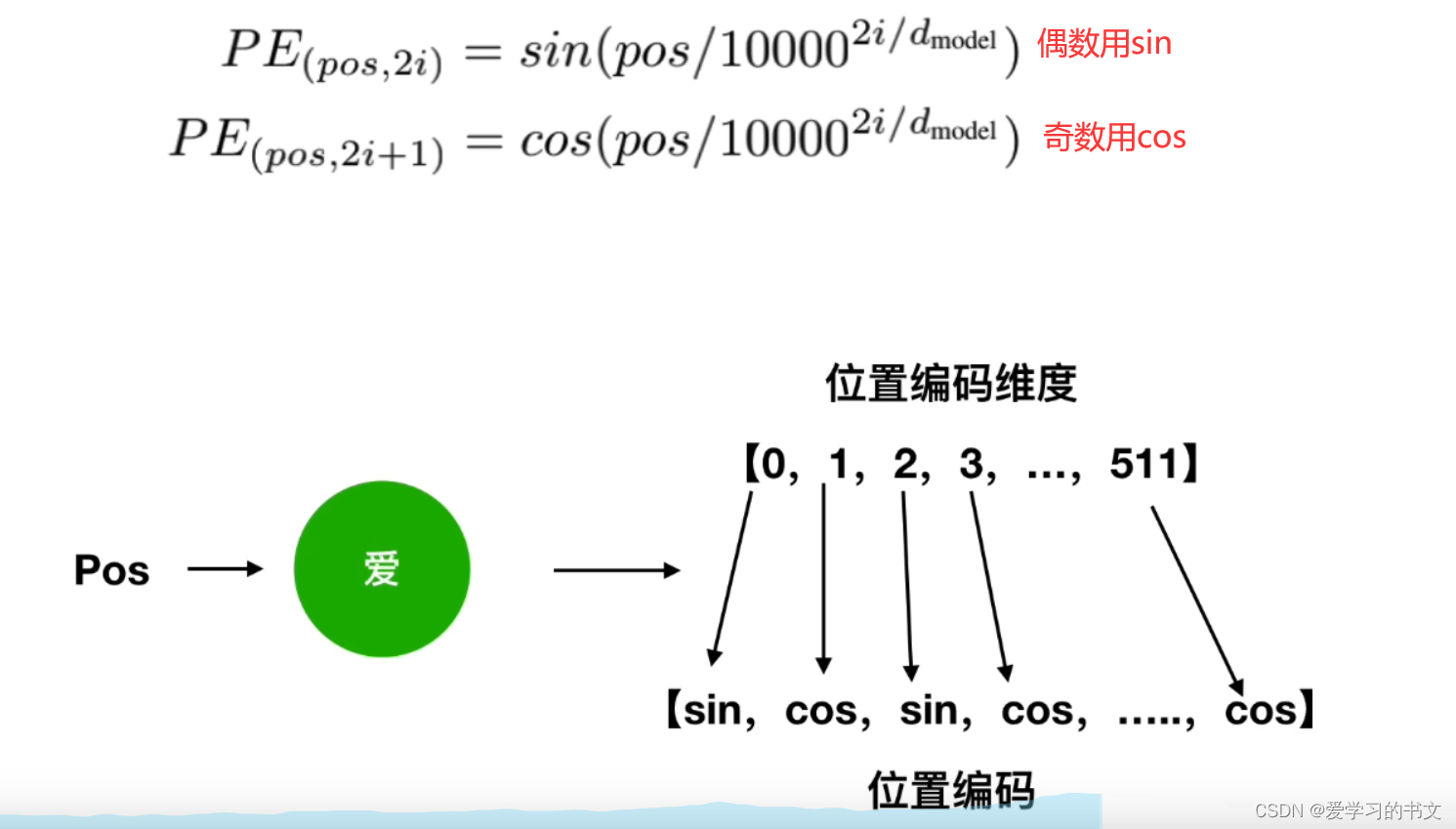
 原文的位置编码公式
原文的位置编码公式
 将embedding词向量和位置编码相加
将embedding词向量和位置编码相加
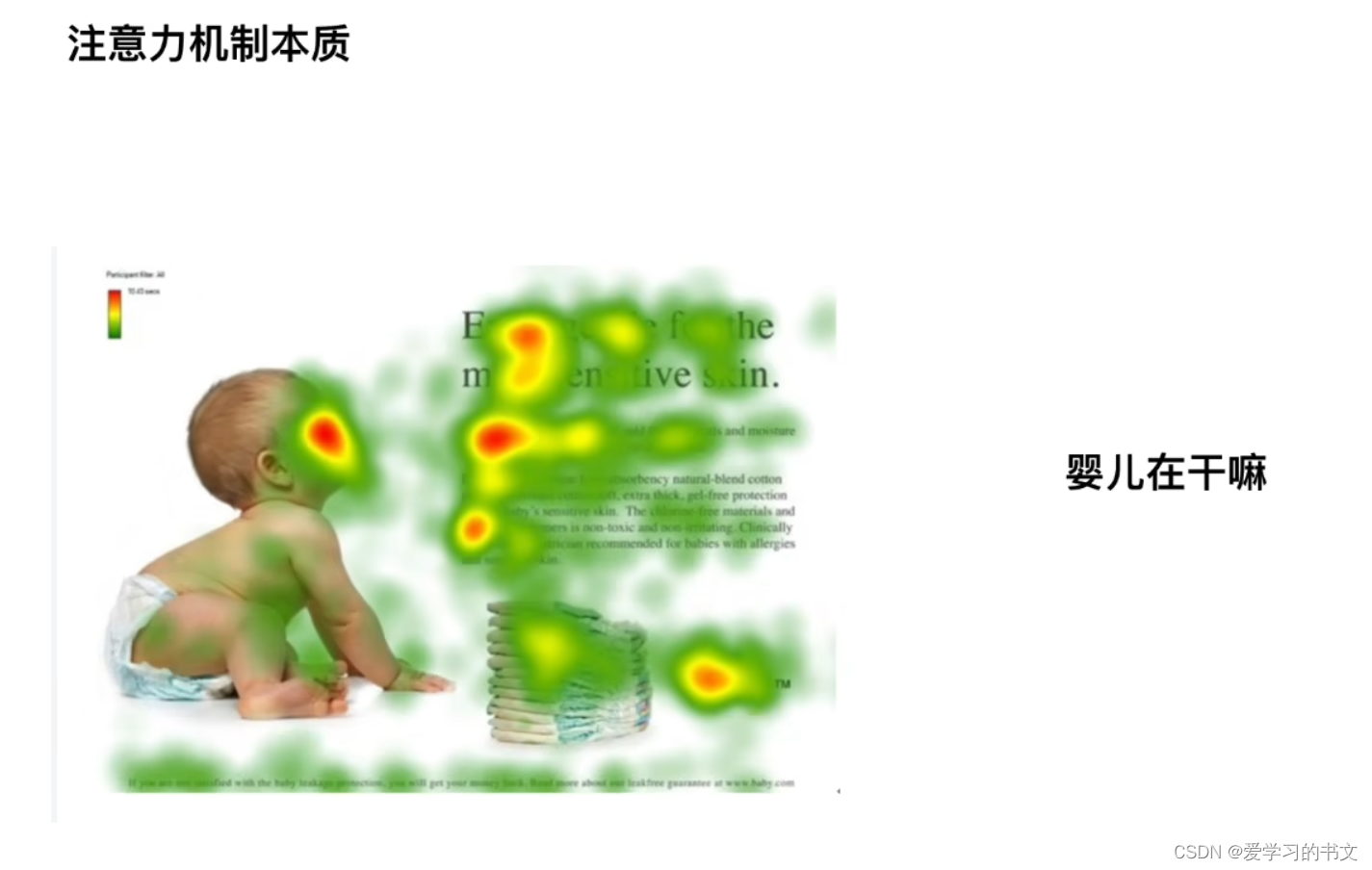
 有用的原因
有用的原因

多头注意力机制
 原文的公式
原文的公式
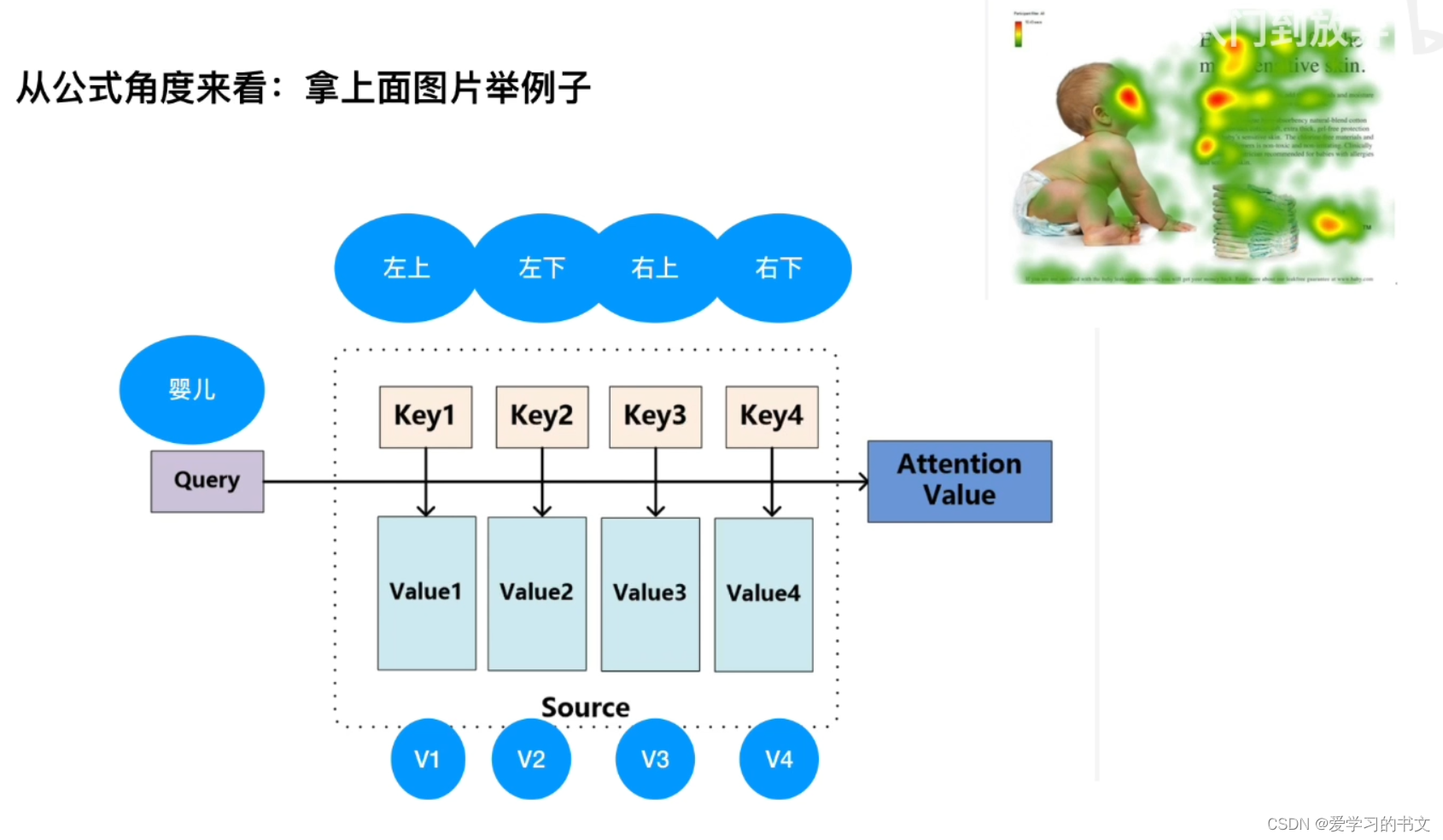
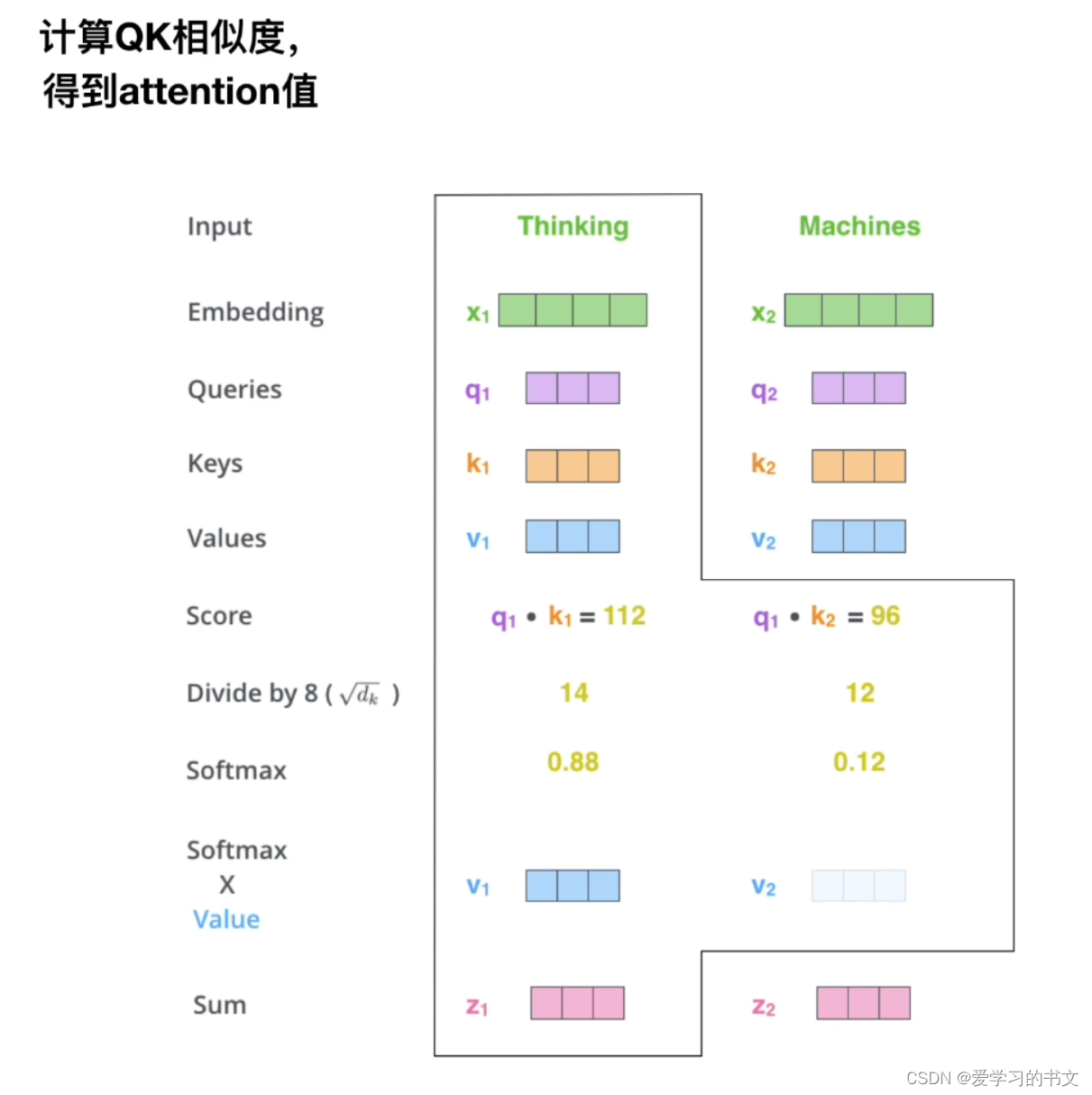
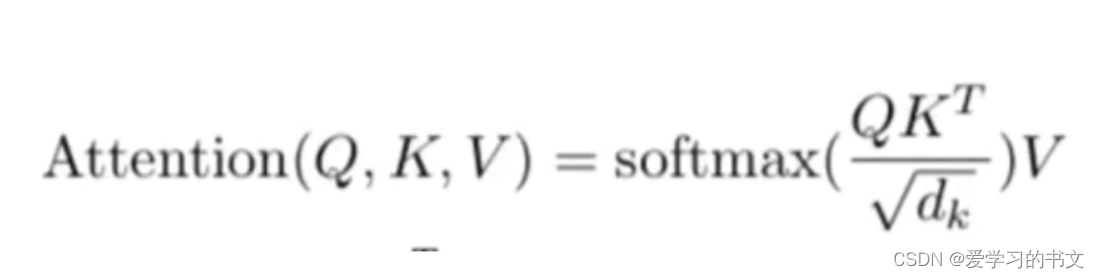 可视化例子如图所示,要关注的内容是query,也就是本文中的婴儿,接着,字是k。q和k点乘可以得到相似度。通过qk相乘得到每个部分,最后乘v,权重,得到最终的关注程度
可视化例子如图所示,要关注的内容是query,也就是本文中的婴儿,接着,字是k。q和k点乘可以得到相似度。通过qk相乘得到每个部分,最后乘v,权重,得到最终的关注程度
如何获取QKV,获得了单词向量之后,将其于qkv大小一个矩阵相乘
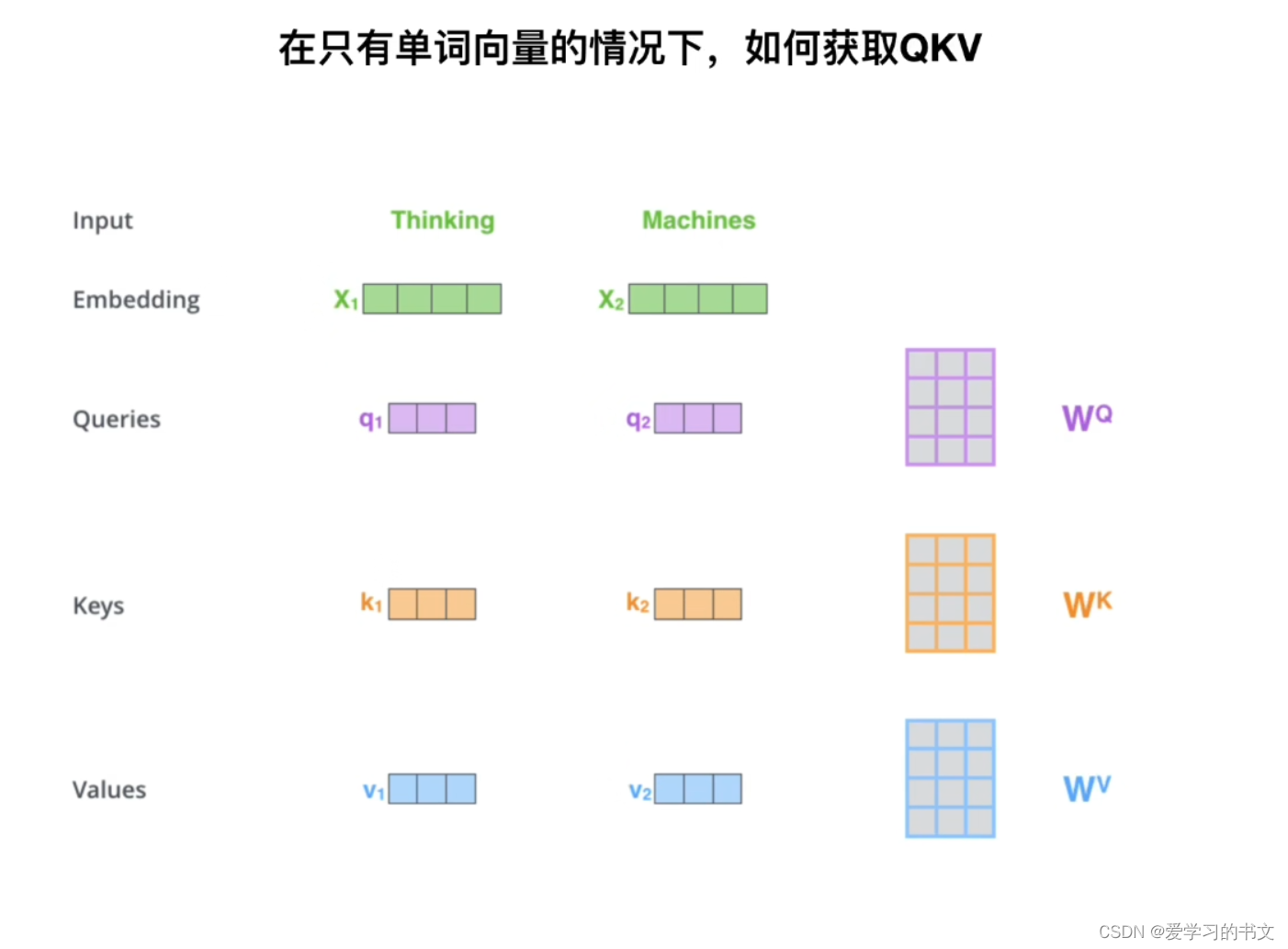
除以 d k \sqrt{d_k} dk,可以控制方差为一,除以这个是为了防止softmax之后的值太小导致梯度消失
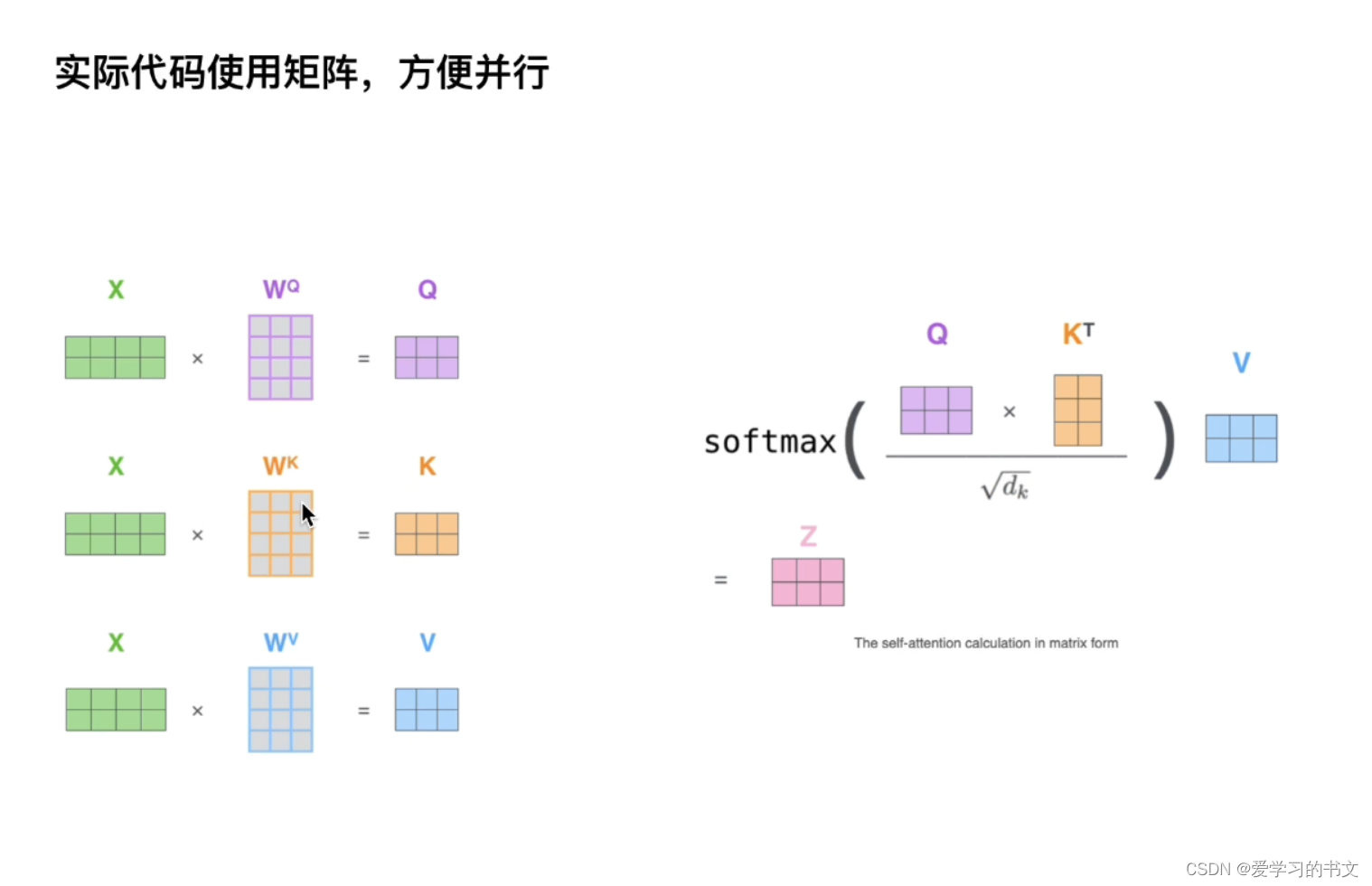
实际使用矩阵
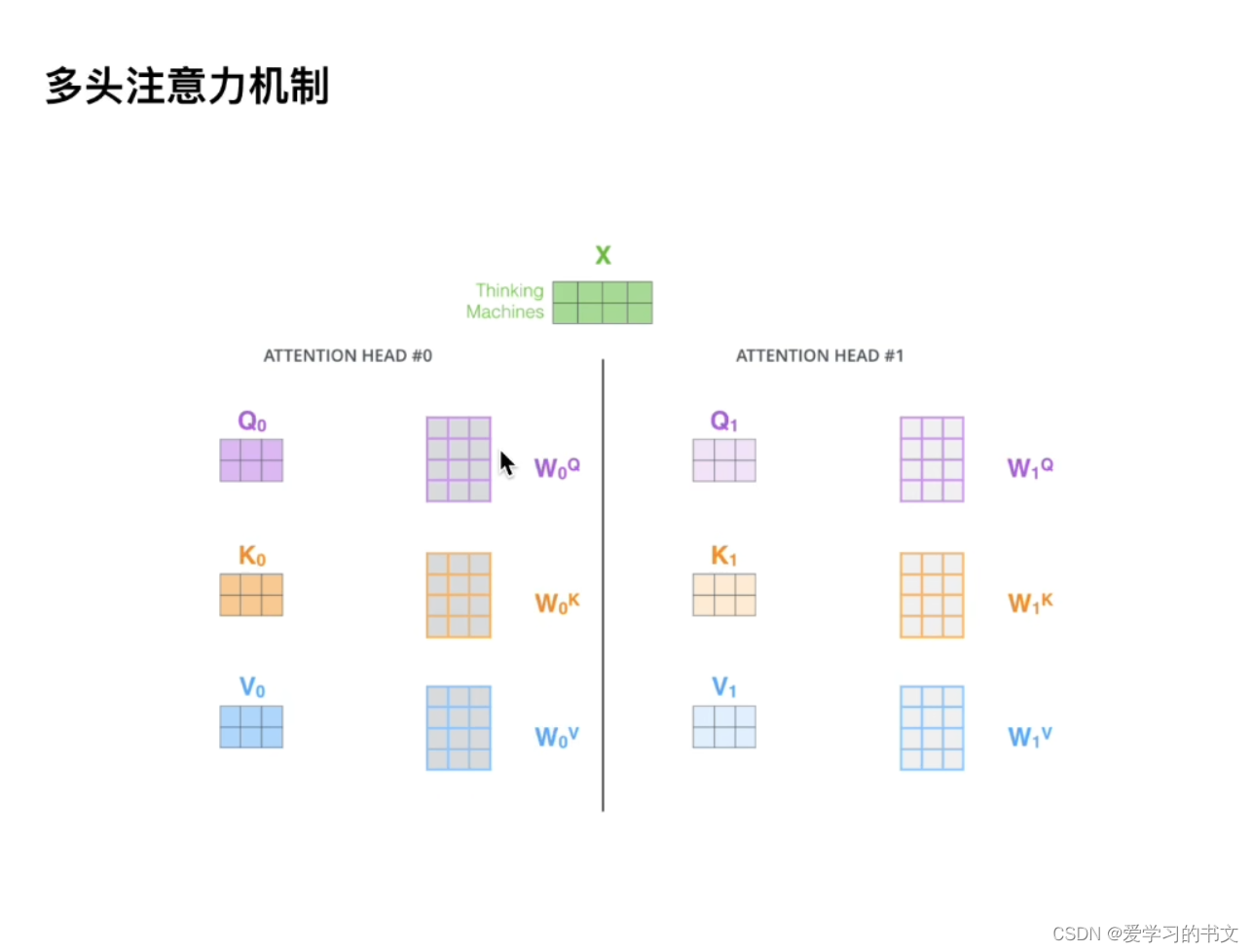
多头指的是用多套qkv,也就是会让网络关注到不同子空间的信息
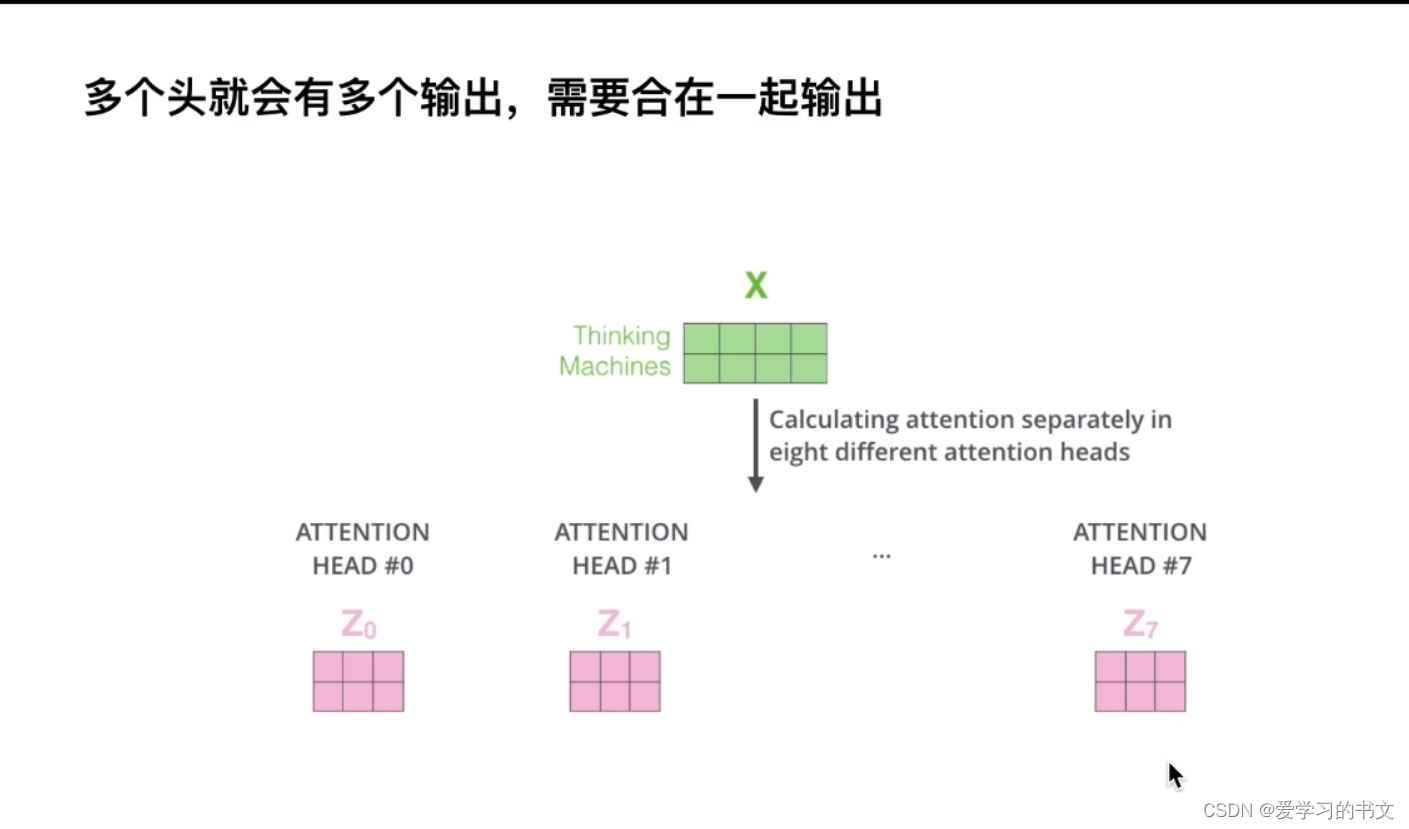
残差
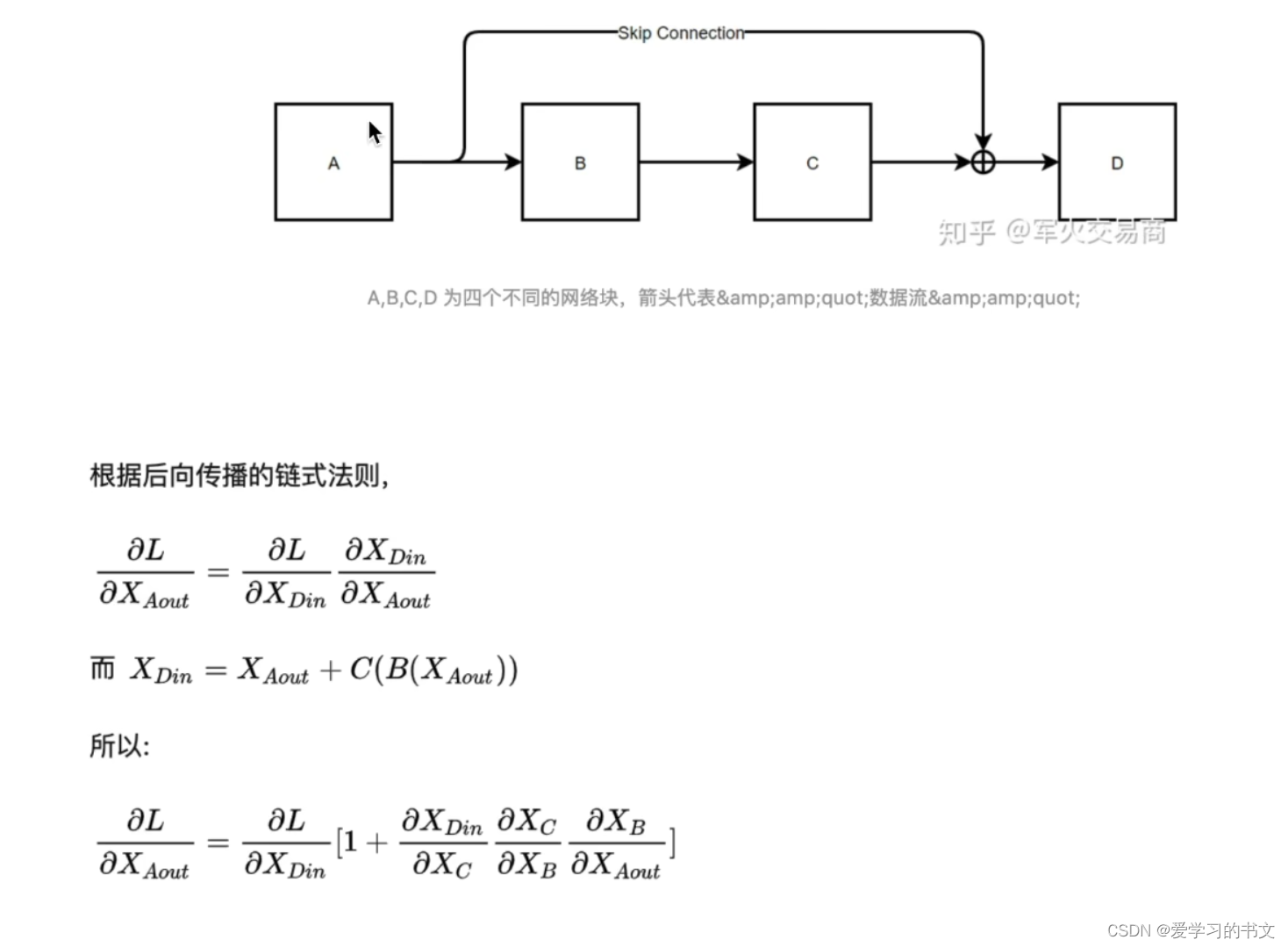
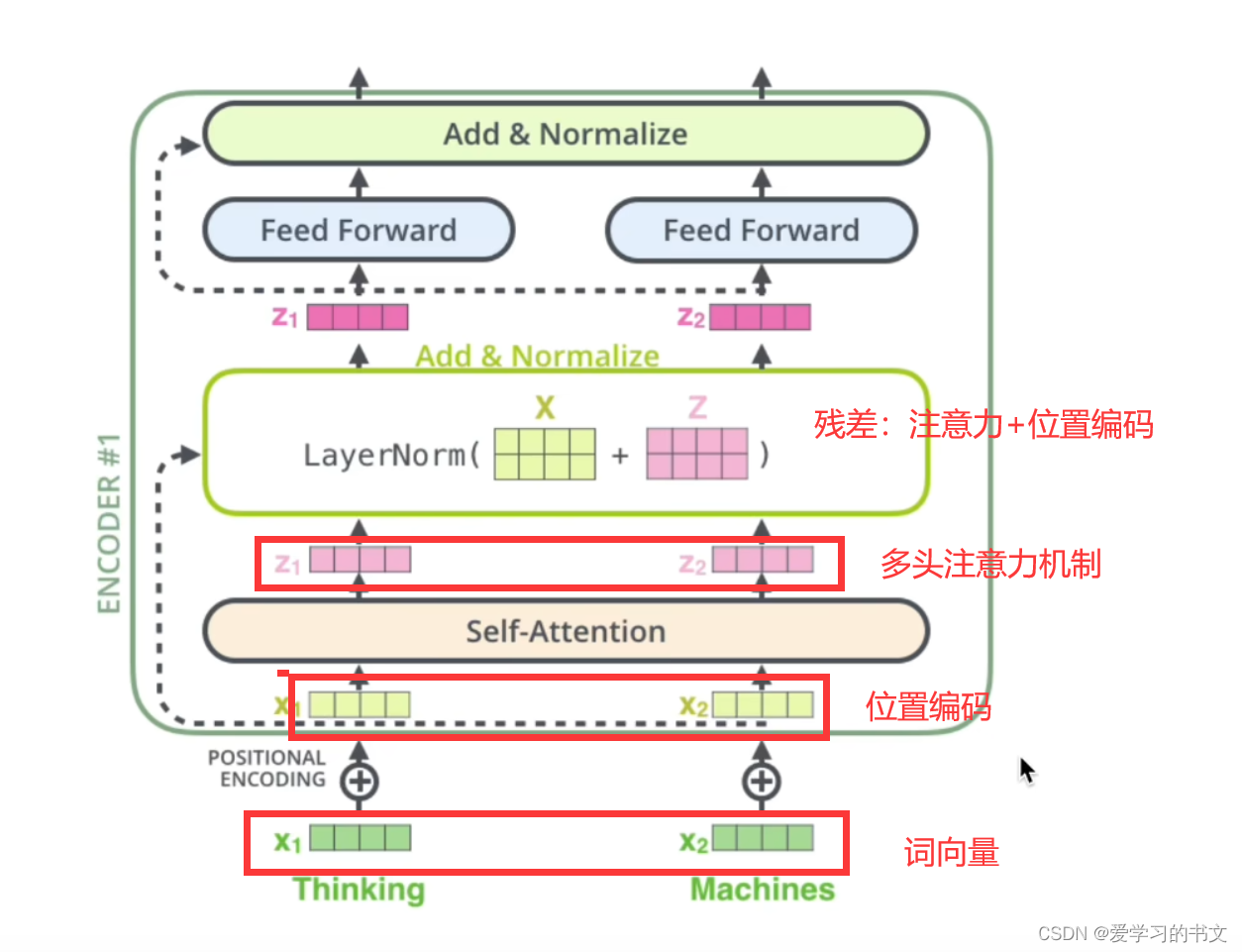 残差的意义:传播后的梯度往往因为连乘而消失,加入残差就加入了1,所以可以缓解梯度消失的问题。
残差的意义:传播后的梯度往往因为连乘而消失,加入残差就加入了1,所以可以缓解梯度消失的问题。
Batch Normal
首先了解一下BN和LN的区别:
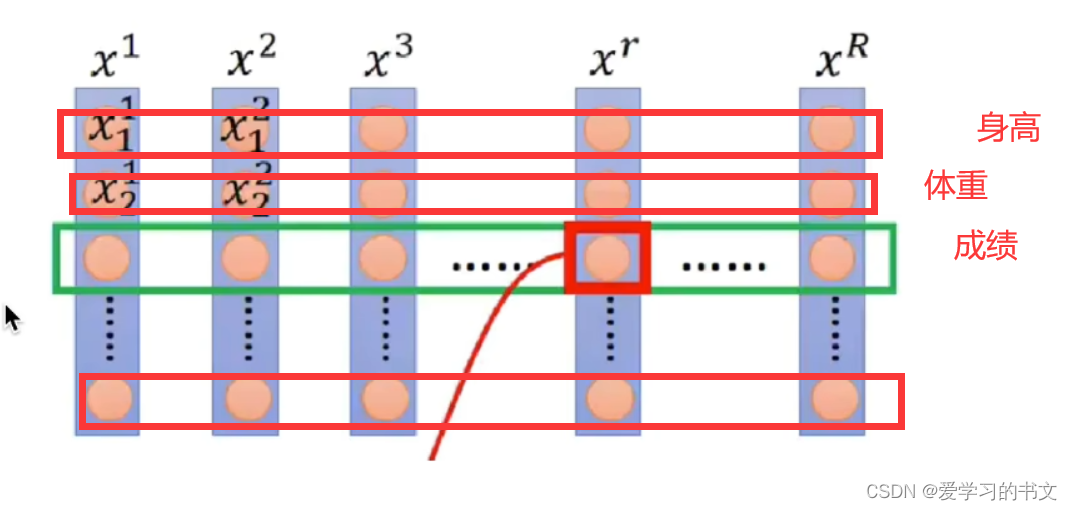
- BN 对不同输入样本在同一个神经元上的值进行归一化
- LN 对单个输入样本在同一层的所有神经元的值进行归一化
在NLP中,BN的效果差,所以不用,一般使用LN
在CV中,BN是对一行计算,都是身高特征、都是体重特征等,对一类的特征做归一化是合理的。
BN优点
- 解决内部协变量偏移
- 缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
BN缺点
- batch_size较小的时候,效果差。
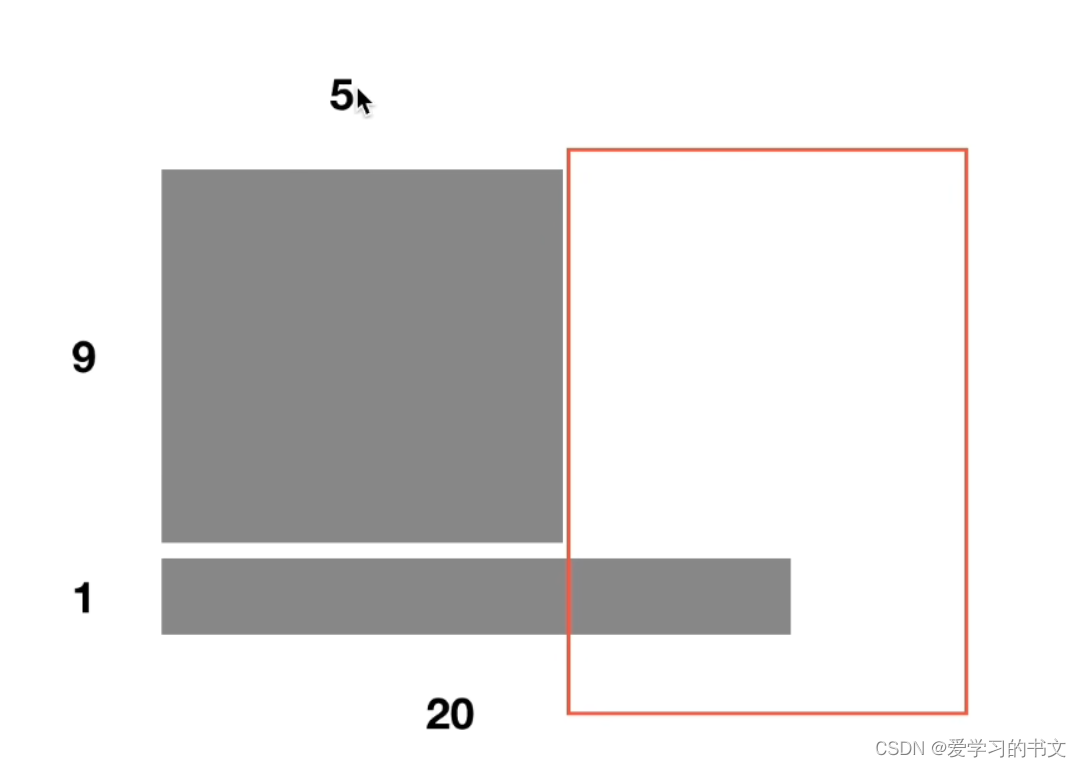
因为BN是用batch_size个样本的均值和方差来模拟所有样本的均值和方差。 - BN在RNN中效果比较差。
因为RNN是动态输入的,对于20长度的词,后面空白部分的batch_size就变成1了。
Layer Normal
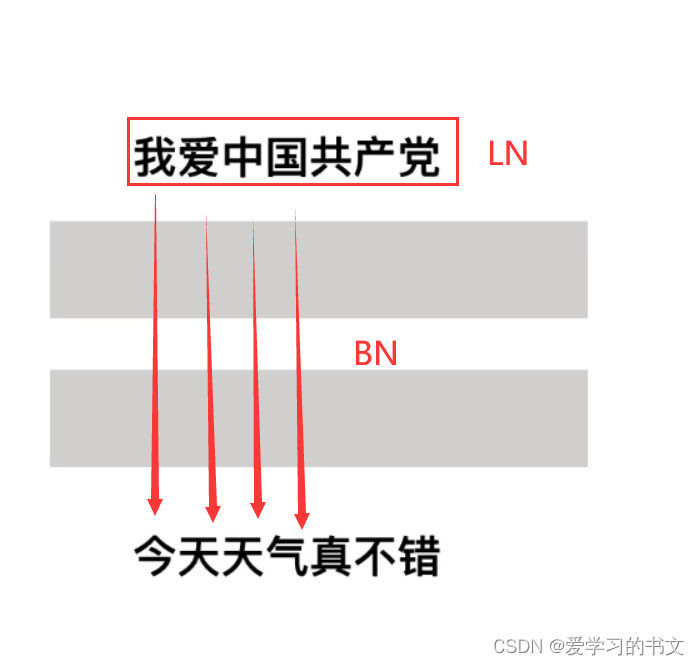
LayerNorm单独对一个样本的所有单词做缩放可以起到效果。
如下图,LN是认为“我爱中国共产党”,这句话具有同样的语义信息;但是BN认为 “我-今”、“爱-天”这样一对对的具有同样的语义信息,这显然是不合理的
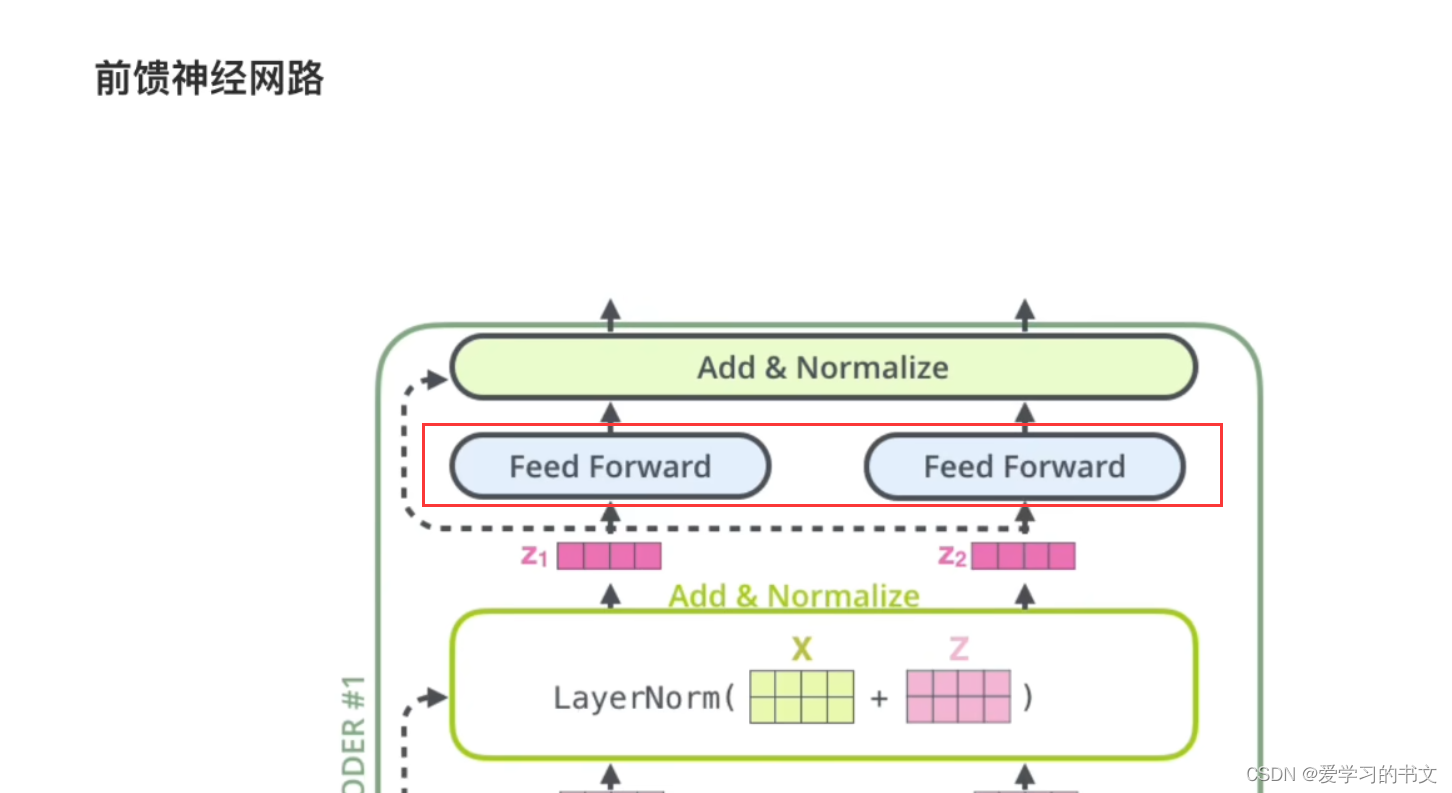
之后就是归一化的向量通过一个前馈神经网络。
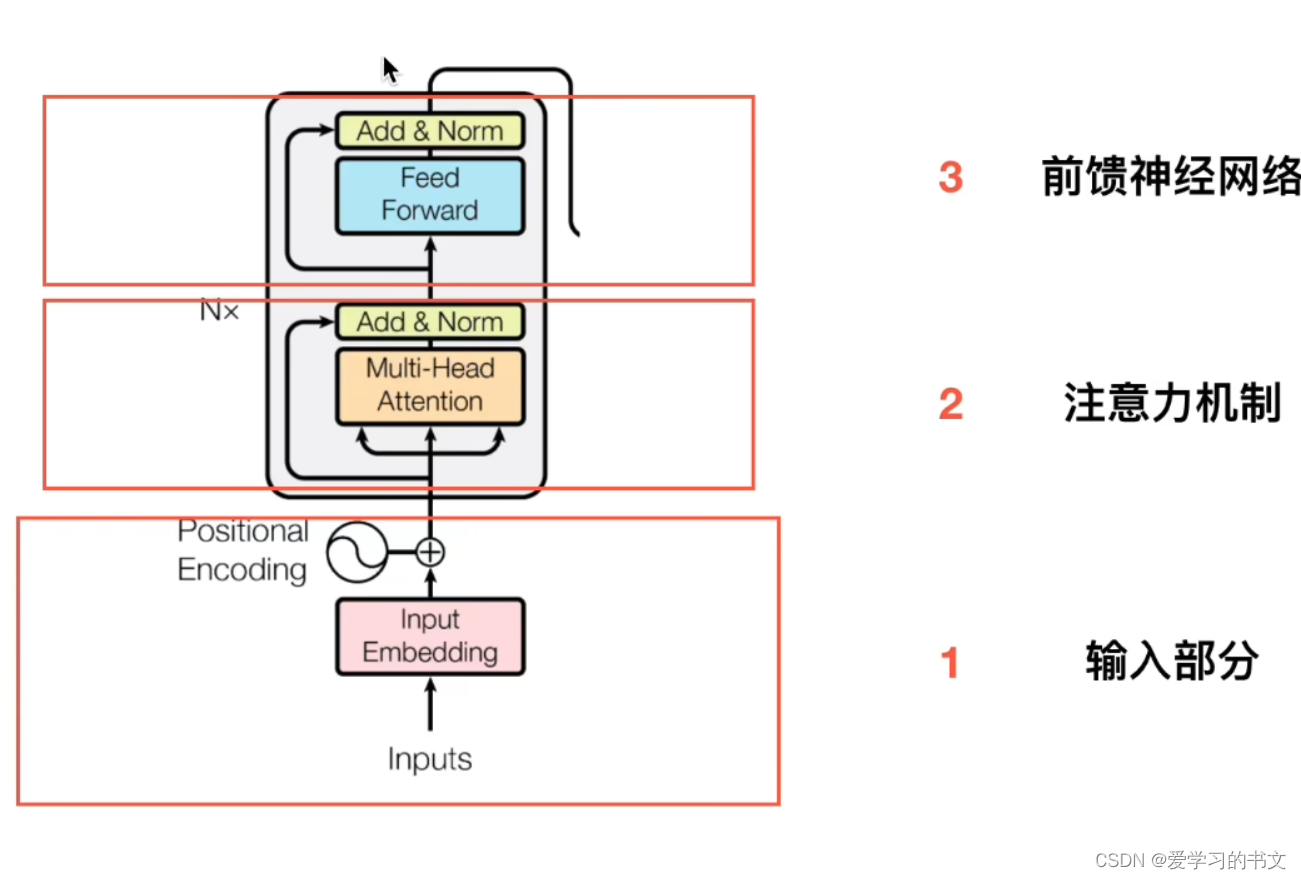
 整体重新过一遍就是,首先输入,然后输入映射到高纬的embedding,接着加入位置编码,然后加入多头注意力机制,位置编码和多头注意力结果融合,输入归一化,接着进行前馈神经网络,再次归一化。
整体重新过一遍就是,首先输入,然后输入映射到高纬的embedding,接着加入位置编码,然后加入多头注意力机制,位置编码和多头注意力结果融合,输入归一化,接着进行前馈神经网络,再次归一化。
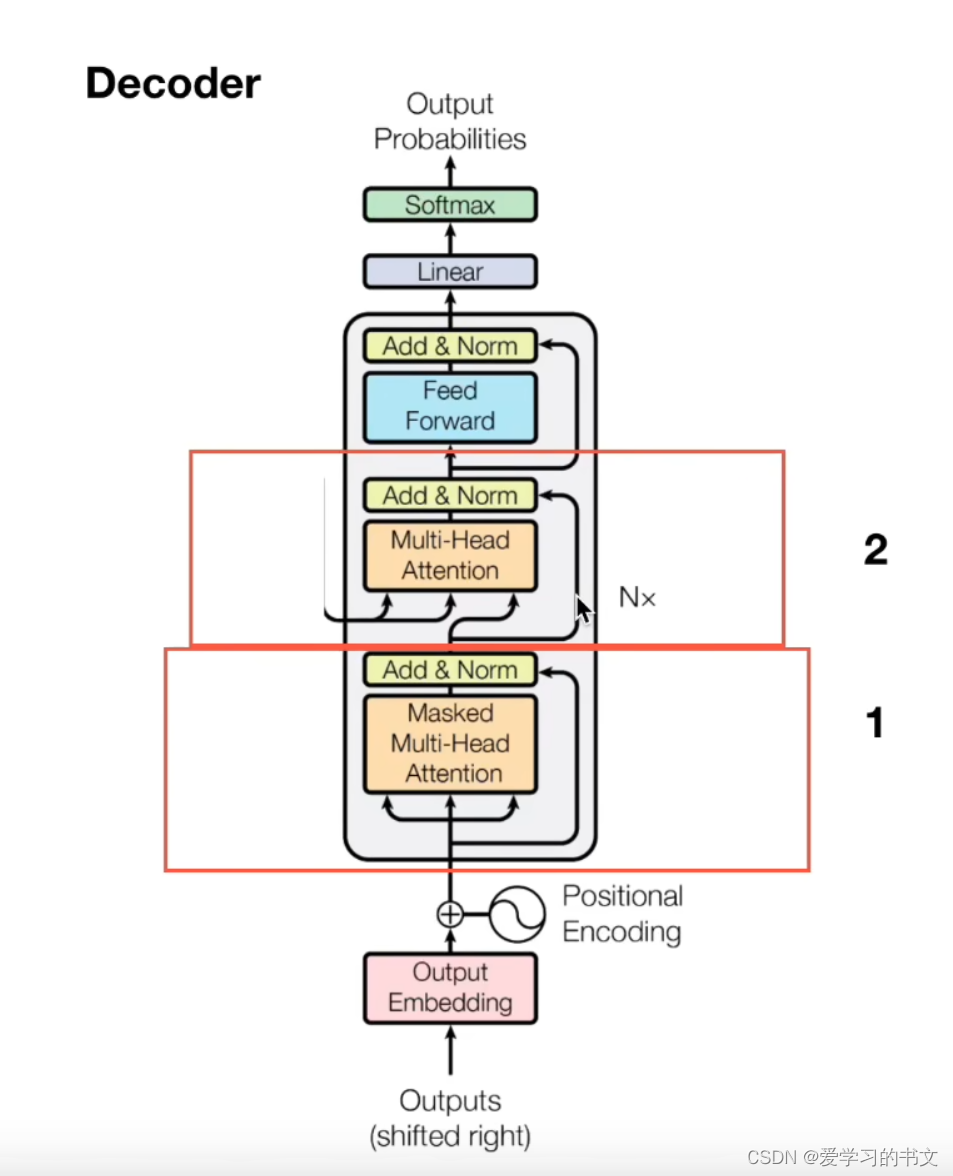
Decoder
解码主要分为两步,第一步是mask的多头注意力机制,第二步是进行交互。
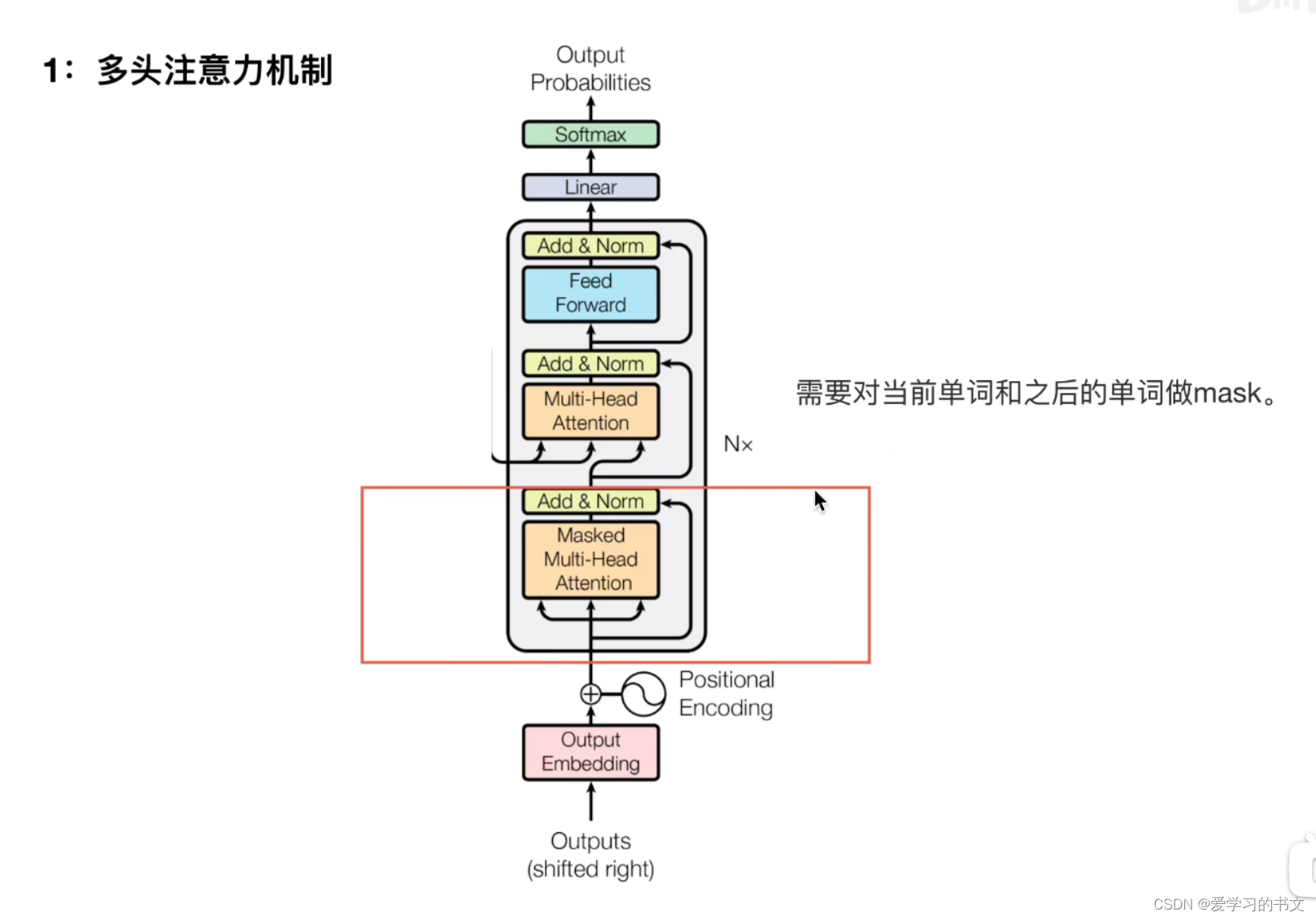
 第一步中,需要对当前单词和之后的单词做mask
第一步中,需要对当前单词和之后的单词做mask
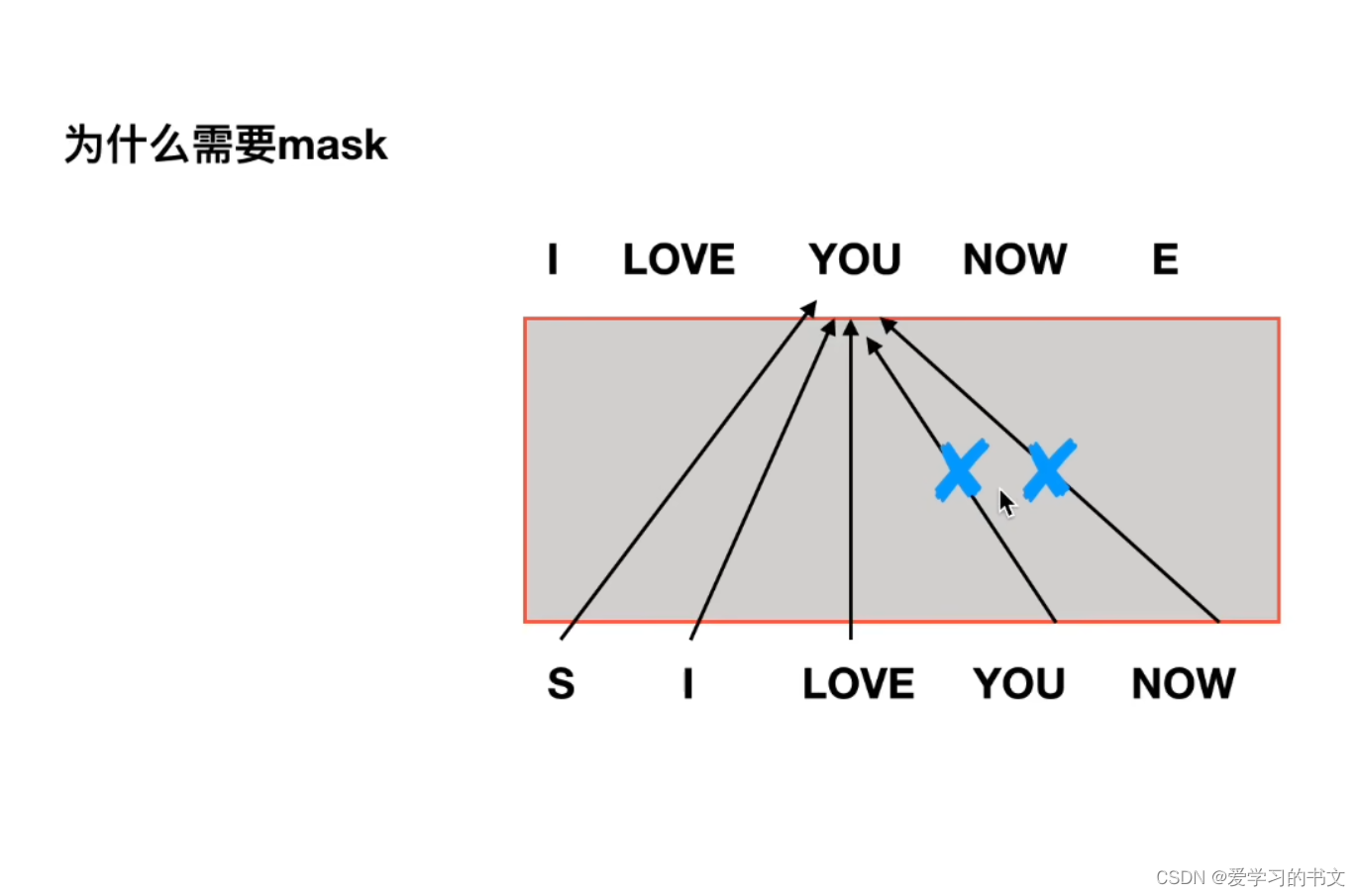
 也就是在下图中,因为测试中是不知道后面的词的,所以也要在训练的时候把后面的词隐藏掉。
也就是在下图中,因为测试中是不知道后面的词的,所以也要在训练的时候把后面的词隐藏掉。
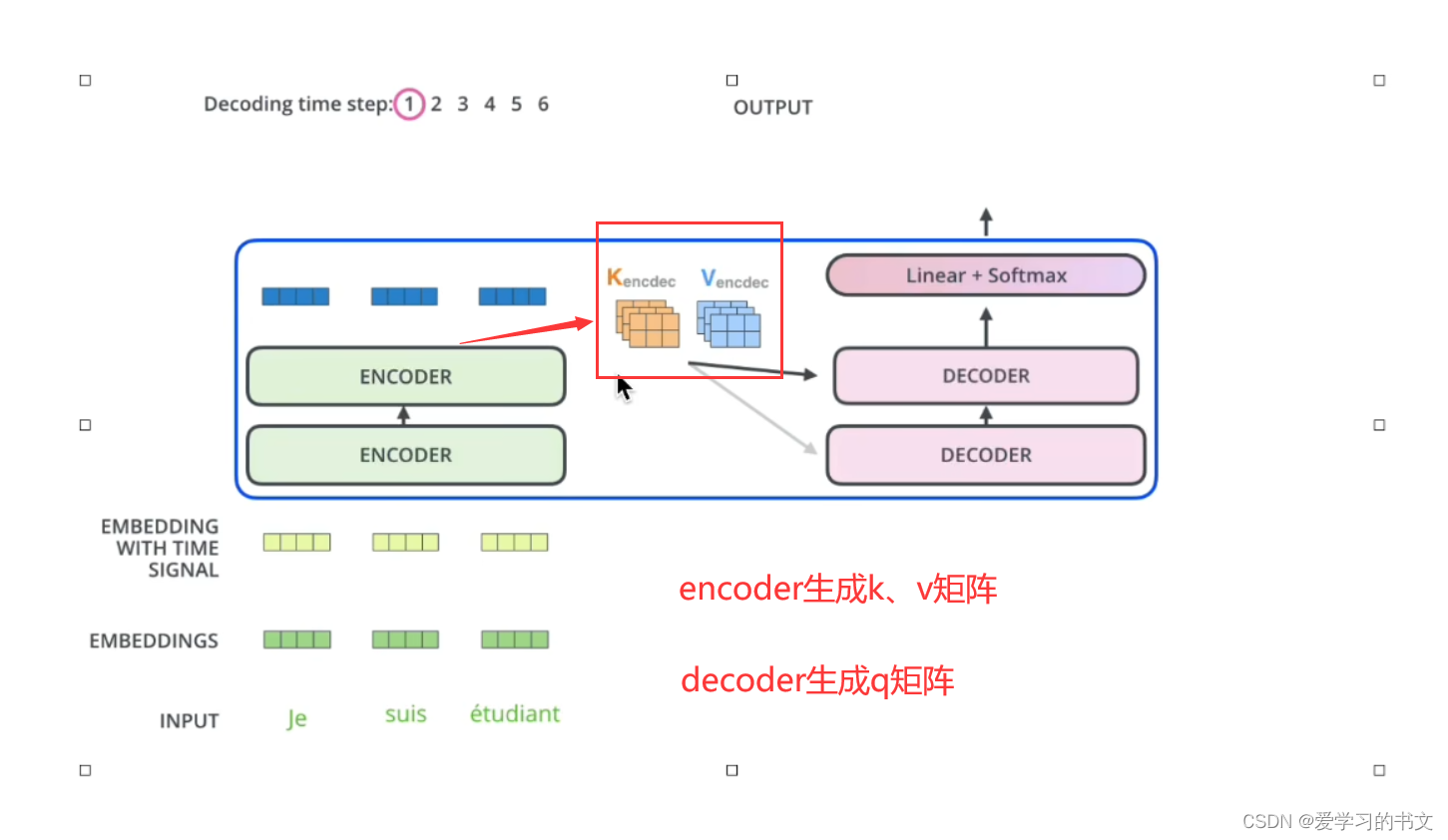
 交互方面
交互方面
每个encoder的结果要和每个decoder的结果做交互
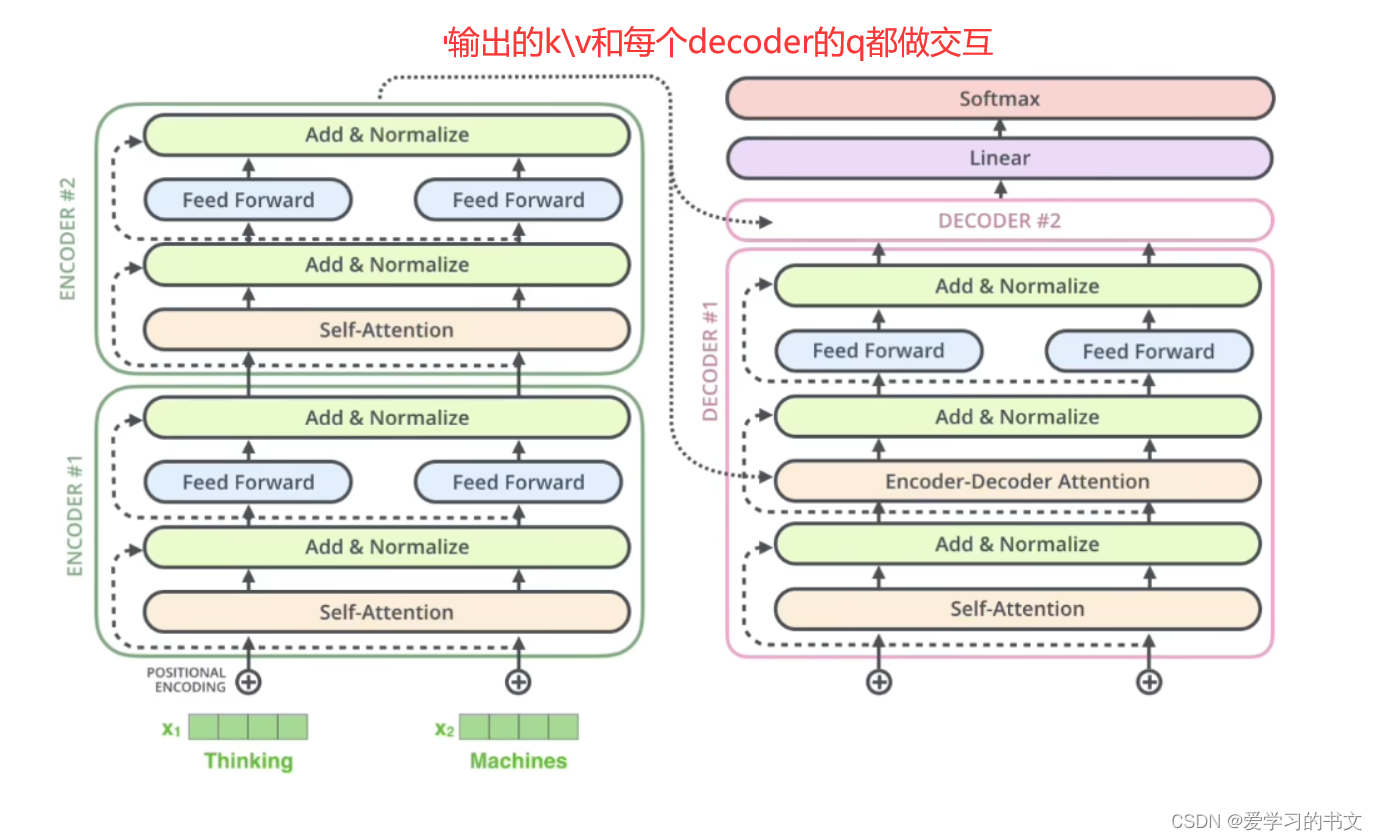
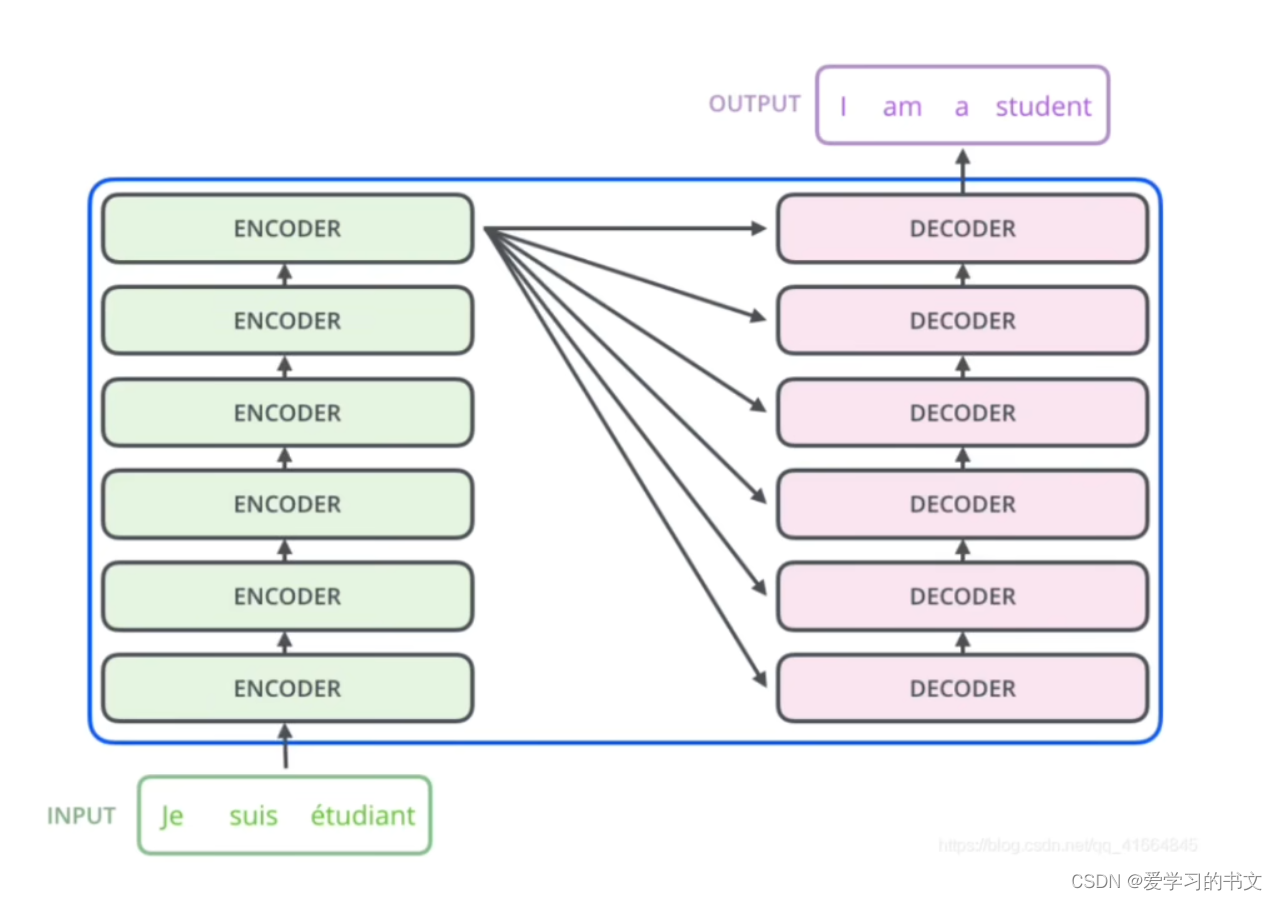 具体来说,就是encoder的k、v矩阵和decoder的q矩阵做交互
具体来说,就是encoder的k、v矩阵和decoder的q矩阵做交互
通过DASOU的视频,对transformer整体概念和各个知识点都又了一个直观上的概念,接着有助于继续看其他视频,进行更加深度的学习。(本来一开始看霹雳吧的视频,就是没看懂,一上来直接qkv,直接给我干懵了,哈哈哈哈