1.前言
普通的elk架构只适合数据量小的情景,而且也不安全,在瞬时数据量大的情况下可能会导致logstash崩溃,从而导致数据的丢失,对于数据安全有较高要求,可以在架构中加入消息队列,既可以防止瞬时的大流量并发,也可以防止在logstash挂掉的情况下数据的丢失
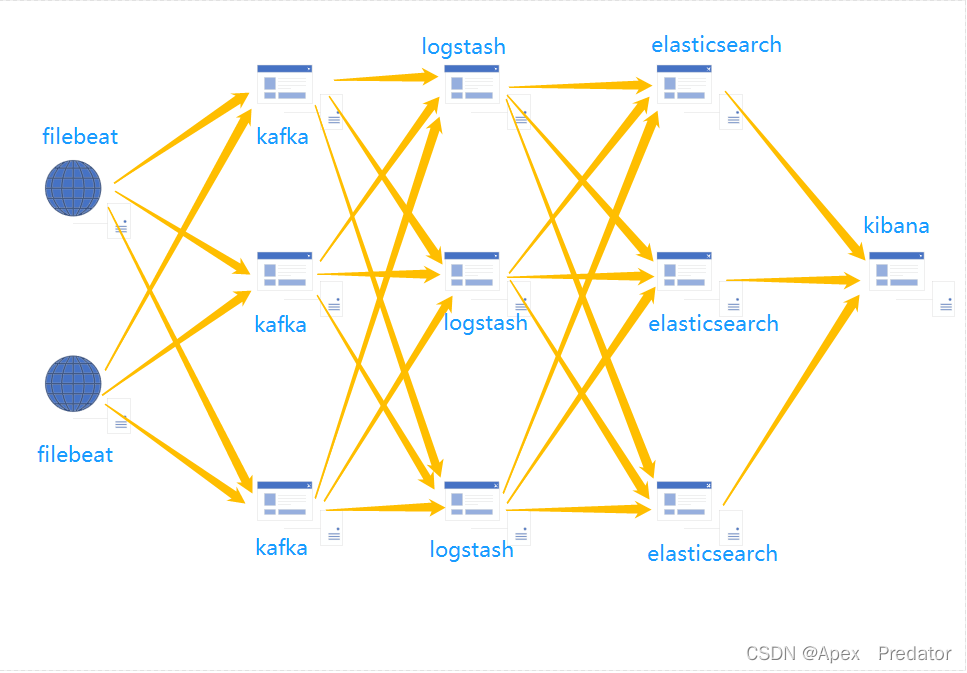
2.架构
给每个需要收集日志的主机部署filebeat服务,filebeat统一将日志输出到kafka集群对应的topic中,再由logstash去主动消费kafka集群topic中的日志数据,由于是logstash主动去消费,就不会发生logstash顶不住大并发数据量而崩溃的问题,但是如果数据量大,logstash消费不过来会导致kafka的消息堆积,一旦kafka堆积过多导致崩溃,所以logstash的数量也是很重要的,logstash消费后的数据写入到elasticsearch集群中,elasticsearch使用集群模式,可以保证数据的安全与高可用,最后再通过kibana展示数据
对于这个架构可能会有一些疑点,因为kafka的特殊性,主题的数据被消费后是不会立刻被删除的,所以使用多个logstash节点去消费主题会不会导致重复消费,logstash单节点宕机的情况下,kafka的主题还在写入数据,logstash恢复后会不会消费挂掉期间主题产生的数据,是否是从头消费导致重复消费以前的数据
已通过试验证明,试验中auto_offset_reset 配置为latest模式,logstash单节点宕机恢复后,会根据宕机之前offset的偏移量继续去消费主题中的数据,所以即使在宕机期间topic产生的数据,在logstash恢复后会继续去消费
已通过试验证明,试验中所有logstash节点都配置相同的消费者组,logstash配置多个节点也不会产生重复消费的情况,且每个logstash节点都是有消费topic数据的,每个logstash节点消费的数据量都差不多,相差不大,类似于负载均衡效果
3.主机信息
| name | ip | serivce | port |
| A | 10.1.60.114 | zookeeper、kafka、logstash、elasticsearch | 2181、2888、3888、9092、9200、9300 |
| B | 10.1.60.115 | zookeeper、kafka、logstash、elasticsearch、kibana | 2181、2888、3888、9092、9200、9300、5601 |
| C | 10.1.60.118 | zookeeper、kafka、logstash、elasticsearch | 2181、2888、3888、9092、9200、9300 |
3.架构搭建
zookeeper集群搭建(kafka需要使用zookeeper)
参考:zookeeper集群搭建_Apex Predator的博客-CSDN博客
kafka集群搭建
参考:kafka集群搭建_Apex Predator的博客-CSDN博客
elasticsearch集群搭建
参考:elasticsearch集群搭建_Apex Predator的博客-CSDN博客
kibana部署
安装kibana需要部署java环境,7版本以上的要使用jdk 11版本以上
参考:jdk1.8环境配置_Apex Predator的博客-CSDN博客
在官网下载kibana的安装包,本次搭建选择了7.17.10版本
Past Releases of Elastic Stack Software | Elastic
新建目录,将安装包上传到主机中并解压更改名称
mkdir /opt/kibana
cd /opt/kibana
tar -zxvf kibana-7.17.10-linux-x86_64.tar.gz
mv kibana-7.17.10-linux-x86_64 kibana
ls /opt/kibana
编辑kibana配置文件
vi /opt/kibana/kibana/config/kibana.yml
server.port: 5601 #配置监听端口
server.host: "0.0.0.0" #配置访问地址
server.name: "kibana" #kibana名称
elasticsearch.hosts: ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"] #配置elasticsearch集群地址
i18n.locale: "zh-CN" #更改界面为中文模式
kibana不能使用root用户启动,所以需要创建启动kibana服务用户
groupadd kibana
useradd kibana -g kibana -p kibana
授予权限给kibana目录
chown -R kibana.kibana /opt/kibana/kibana
切换用户启动kibana服务
su kibana
nohup /opt/kibana/kibana/bin/kibana > /opt/kibana/kibana/kibana.log &
查看kibana服务是否正常
netstat -tlpn |grep 5601
logstash部署
安装logstash服务也需要java环境,因为和es在同一台机器上,就不需要再部署java环境了
在官网下载Logstash的安装包,本次搭建选择了7.17.10版本
Past Releases of Elastic Stack Software | Elastic
新建目录,将安装包上传到主机中并解压更改名称
mkdir /opt/logstash
cd /opt/logstatsh
tar -zxvf logstash-7.17.10-linux-x86_64.tar.gz
mv logstash-7.17.10-linux-x86_64 logstatsh
ls /opt/logstash
filebeat部署
在官网下载filebeat的安装包,本次搭建选择了7.17.10版本
Past Releases of Elastic Stack Software | Elastic
新建目录,将安装包上传到主机中并解压更改名称
mkdir /opt/filebeat
cd /opt/filebeat
tar -zxvf filebeat-7.17.10-linux-x86_64.tar.gz
mv filebeat-7.17.10-linux-x86_64 filebeat
ls /opt/filebeat
![]()
4.服务配置
先配置filebeat收集nginx日志
vi /opt/filebeat/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log #配置收集日志的路径fields: #为该日志定义一个字段,供后面调用topic: nginx-access-logtail_files: true- type: logenabled: truepaths:- /var/log/nginx/error.logfields:topic: nginx-error-logtail_files: true# ------------------------------ kafka Output -------------------------------
output.kafka:enabled: true hosts: ["10.1.60.112:9092","10.1.60.114:9092","10.1.60.115:9092"] #kafka集群地址topic: '%{[fields][topic]}' #调用前面的日志字段,来自动写入对应的主题先不启动filebeat,等启动了logstash再启动filebeat
编辑logstash配置文件
input {kafka {bootstrap_servers => "10.1.60.112:9092,10.1.60.114:9092,10.1.60.115:9092"client_id => "nginx"group_id => "nginx" #配置消费者组,避免重复消费的关键auto_offset_reset => "latest" #配置偏移策略,latest当消费者发现分区的偏移量无效或不存在时,将从分区的最新可用偏移量开始消费。这意味着消费者将只消费从订阅时刻之后发布的消息,之前的消息将被忽略,earliest当消费者发现分区的偏移量无效或不存在时,将从分区的最早可用偏移量开始消费。这意味着消费者将从分区的开头开始消费消息,无论之前是否有消费记录consumer_threads => 1 #配置消费线程decorate_events => truetopics => ["nginx-access-log","nginx-error-log"] #配置kafka存储数据的主题codec => json #将kafka数据格式转换成json格式}
}filter {if [fields][topic] == "nginx-access-log" { #通过判断主题名称去将指定主题中的日志转化为结构化日志grok {match => {"message" => "%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_url} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{DATA:http_agent}\" \"(%{DATA:forwarded}|-)\""}}}else if [fields][topic] == "nginx-error-log" {grok {match => {"message" => "%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}"}}}
}output {
# stdout{
# codec => rubydebug
# }elasticsearch {hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]index => "%{[@metadata][kafka][topic]}-%{+YYYY.MM.dd}" #通过主题名称和时间去规定索引的名称,使用主题的变量去自动获取不同主题的数据}
}关于多节点logstash的配置,配置文件也是和以上的相同即可,只是kafka的client_id项需要配置不同的值,这里我没有配置日志过滤,需要过滤的可以参照以下链接中的文章去配置,grok的说明也可以看以下的文章去理解
mutate使用:mutate使用(日志过滤)_Apex Predator的博客-CSDN博客
grok使用: grok使用(将日志结构化)_Apex Predator的博客-CSDN博客
启动所有logstash服务
nohup /opt/logstash/logstash/bin/logstash -f /opt/logstash/logstash/config/logstash.conf > /opt/logstash/logstash/logstash.log &
启动所有filebeat服务
nohup /opt/filebeat/filebeat/filebeat -e -c /opt/filebeat/filebeat/filebeat.yml > /opt/filebeat/filebeat/filebeat.log &
5.生成日志查看效果
访问nginx服务,需要访问filebeat收集的nginx日志的服务
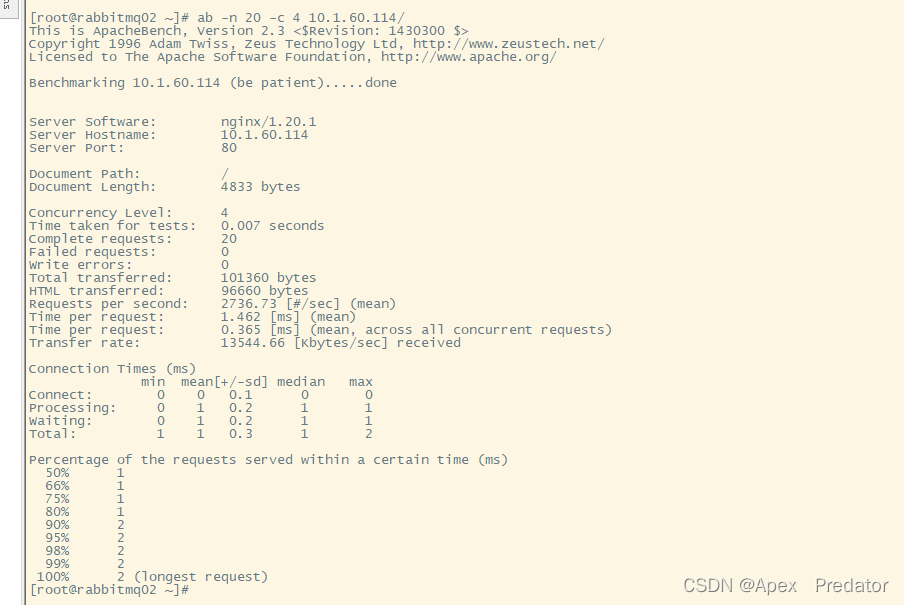
安装压测工具,使用压测工具去测试
yum -y install httpd-tools
ab -n 20 -c 4 10.1.60.114/
使用kibana查看是否生成对应的索引与收集的日志数量是否正确
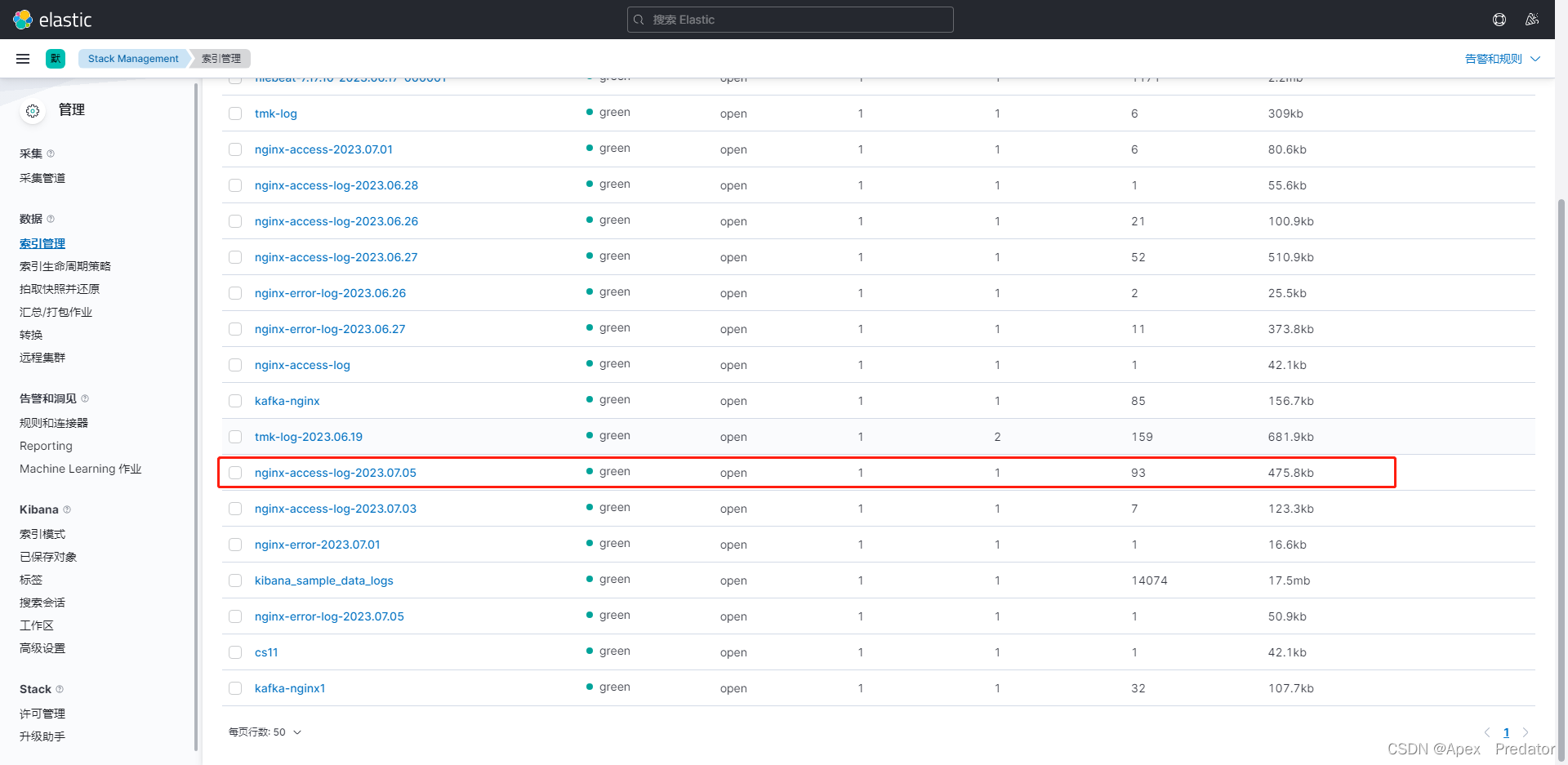
因为我是已经使用过了,所以本身是有数据的,但是新的话,会看到创建了这个索引,并且收集到了20条日志数据
也可以观察kafka的topic数据情况
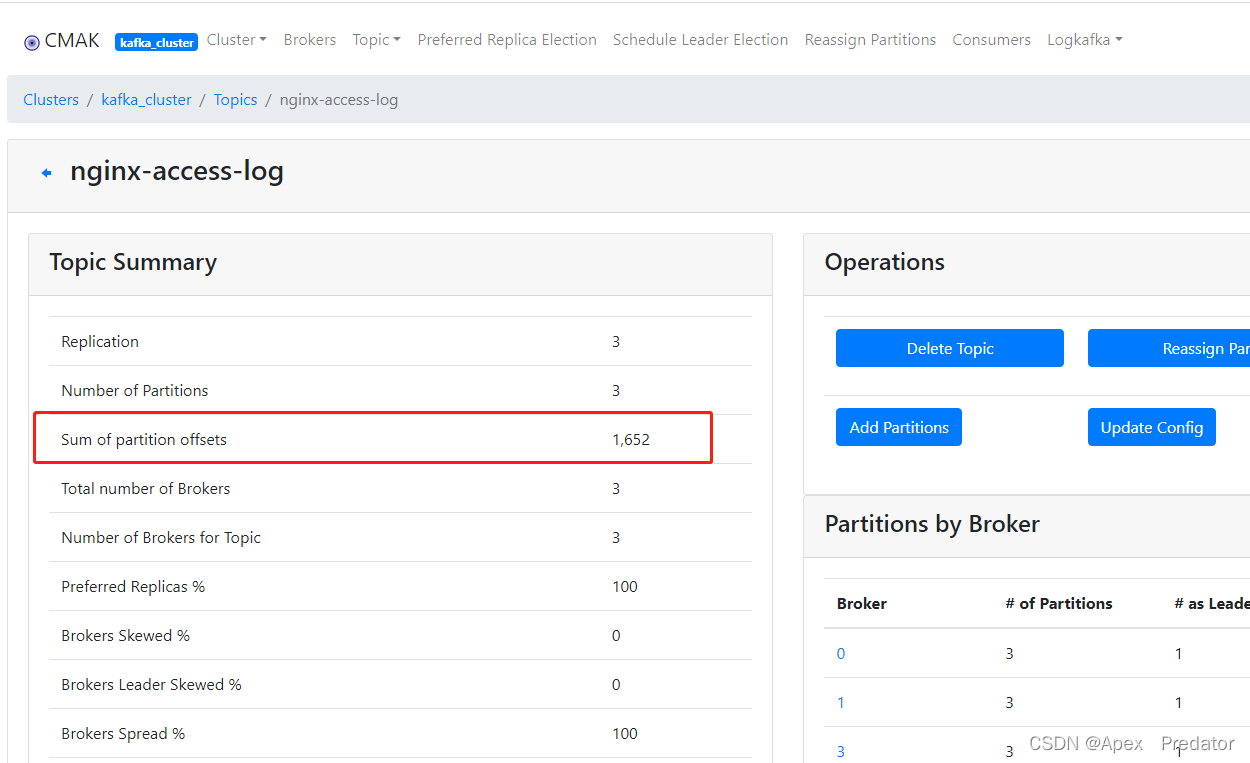
查看日志数据也可以发现,日志是没有问题的