pom 文件
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency></dependencies>
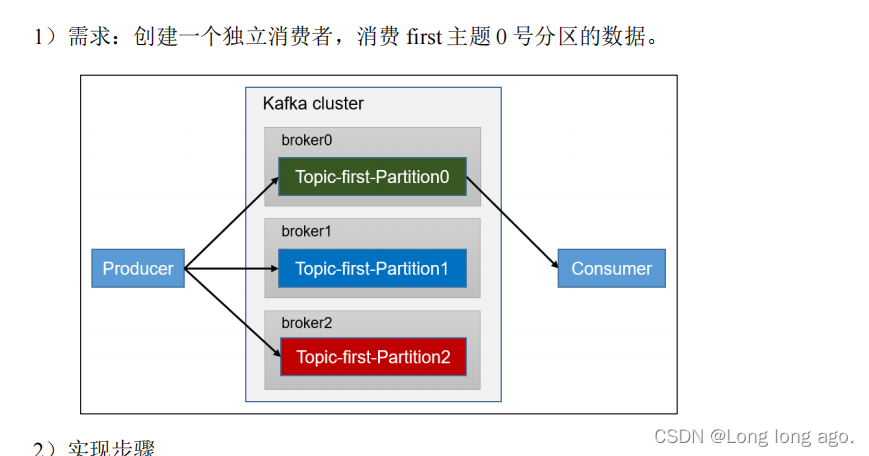
独立消费者案例(订阅主语)
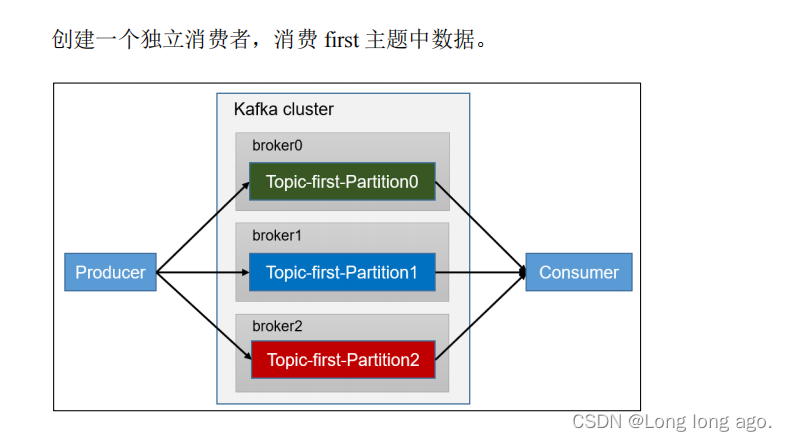
在消费者API代码中,必须配置消费者id。命令行启动消费者不填写消费者组id会被自动填写随机得消费者组id
package com.longer.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;public class CustomConsumer {public static void main(String[] args) {//创建消费者的配置对象Properties properties=new Properties();//2、给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");//配置序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//配置消费者组(组名任意起名)必须properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");//创建消费者对象KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);//注册要消费的主题ArrayList<String> topics=new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);while (true){//设置1s中消费一批数据ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));//打印消费到的数据for(ConsumerRecord<String,String> record:consumerRecords){System.out.println(record);}}}
}
发送的信息
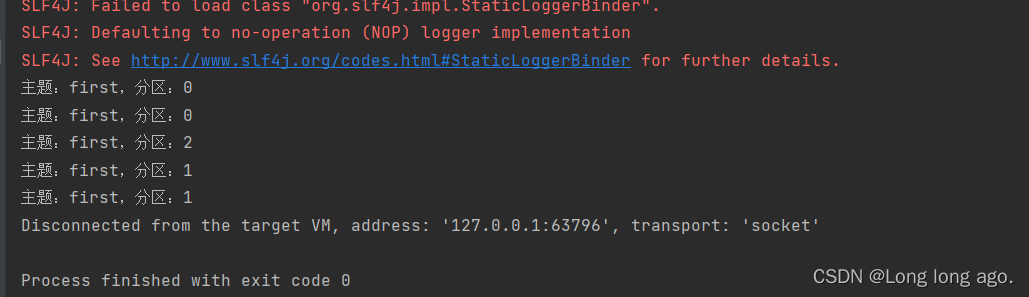
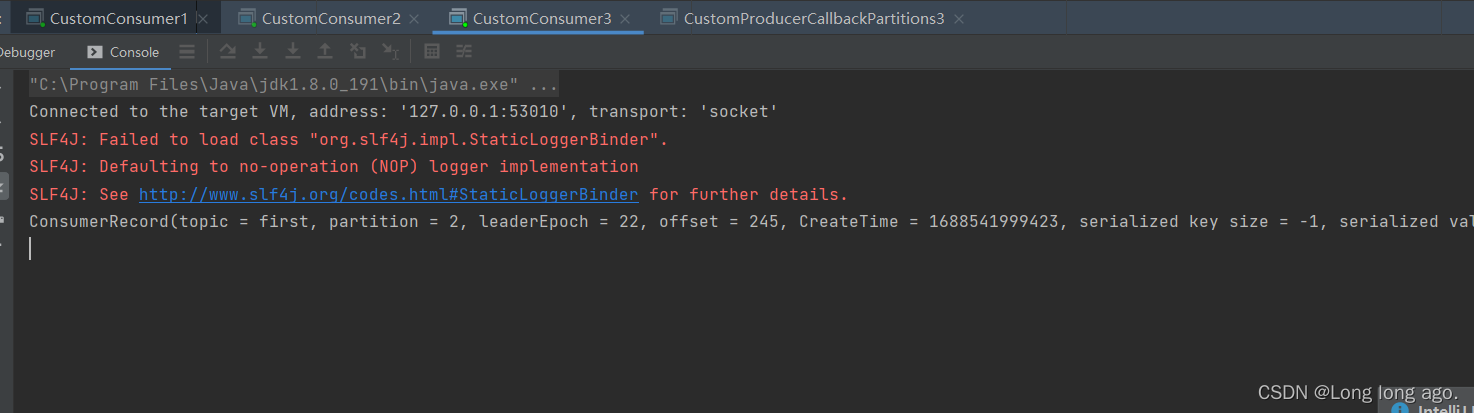
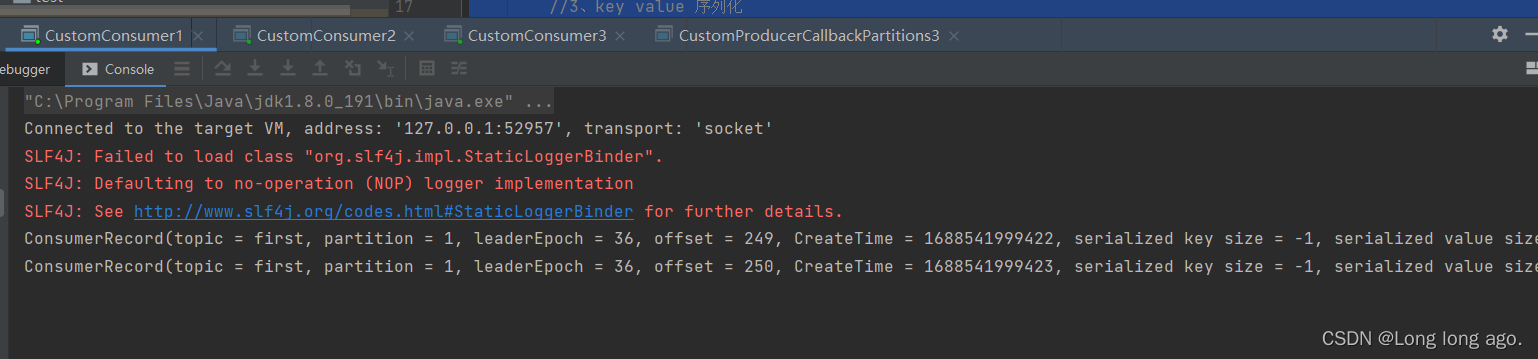
消费信息(因为我发了好多次)
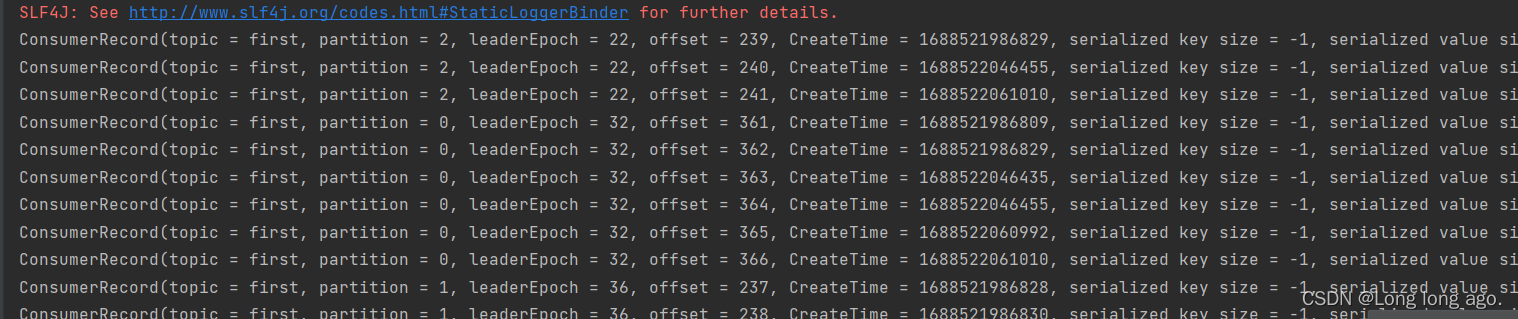
独立消费者案例
package com.longer.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
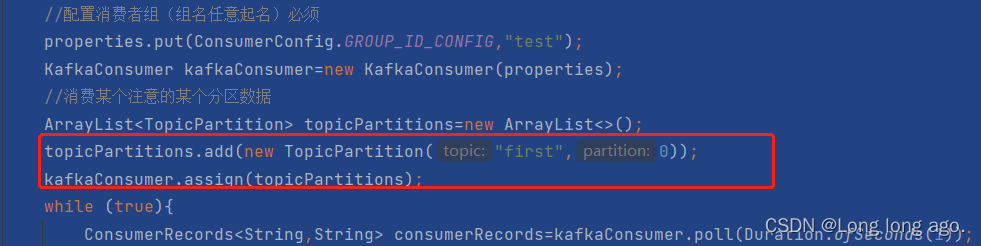
import java.util.Properties;public class CustomConsumerPartition {public static void main(String[] args) {Properties properties=new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//配置消费者组(组名任意起名)必须properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");KafkaConsumer kafkaConsumer=new KafkaConsumer(properties);//消费某个注意的某个分区数据ArrayList<TopicPartition> topicPartitions=new ArrayList<>();topicPartitions.add(new TopicPartition("first",0));kafkaConsumer.assign(topicPartitions);while (true){ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}
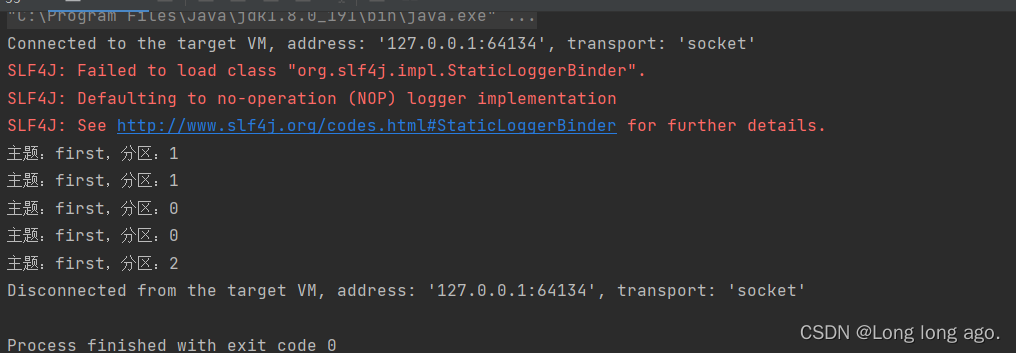
发送信息发现只消费0分区的信息

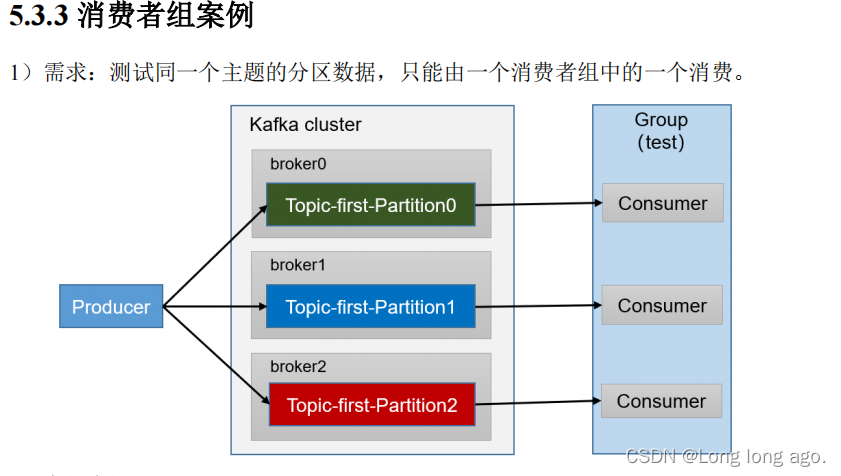
消费者组案例
package com.longer.consumer.group;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;public class CustomConsumer1 {public static void main(String[] args) {//创建消费者的配置对象Properties properties=new Properties();//2、给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");//配置序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//配置消费者组(组名任意起名)必须properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");//创建消费者对象KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);//注册要消费的主题ArrayList<String> topics=new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);while (true){//设置1s中消费一批数据ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));//打印消费到的数据for(ConsumerRecord<String,String> record:consumerRecords){System.out.println(record);}}}
}复制三分,然后运行