- 新建类
package test01;import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;public class TestConnection {public static void main(String[] args) throws Exception {StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(new Configuration());executionEnvironment.setParallelism(1);//Connect可以将不同数据类型的流进行合并,但形成的是ConnectedStream,并不是DataStream,也就是说对外是一个整体的合并后的流,但其实内部是各自处理各自的数据。//创建流1:数字流,但是由于我们输入时是字符串,所以这里需要将字符串进行类型转换,转换为数值类型的.SingleOutputStreamOperator<Integer> dataSource = executionEnvironment.socketTextStream("localhost", 7777).map(value -> Integer.parseInt(value));//创建流2:字符串流DataStreamSource<String> stringSource = executionEnvironment.socketTextStream("localhost", 8888);//合并流,与union不同的是,union可以在一个source的后面多次调用union()合并多个stream,但是在connect中只能单次调用connect()进行合并ConnectedStreams<Integer, String> connect = dataSource.connect(stringSource);/*** 注意ConnectedStreams中没有print(),有map()、process()等方法用来对合并后的流中得到不同类型流进行分别处理.* 这里使用map(),CoMapFunction的参数一指的是调用connect()方法的数据流类型,参数二指的是被调用的数据流类型,* 也就是connect()括号中的数据流类型,参数三是最终合并后的数据流类型,可以看到参数一和参数二已经根据前面我们调用connect时的两个数据流类型* 自动帮我们获取到了数据类型,参数三初始是Object类型,这里我们想要使合并后的数据流类型变成String类型,所以参数三设置为String。*/SingleOutputStreamOperator<String> outputStream = connect.map(new CoMapFunction<Integer, String, String>() {//重写map1()和map2(),map1()指的就是参数一对应的数据流,map2()指的是参数二对应的数据流@Overridepublic String map1(Integer integer) throws Exception {//在map1()方法中对数据进行处理,使之返回值为Stringreturn "原始的数值流:" + integer.toString();}@Overridepublic String map2(String s) throws Exception {return "原始的字符串流:" + s;}});outputStream.print();executionEnvironment.execute();}
}
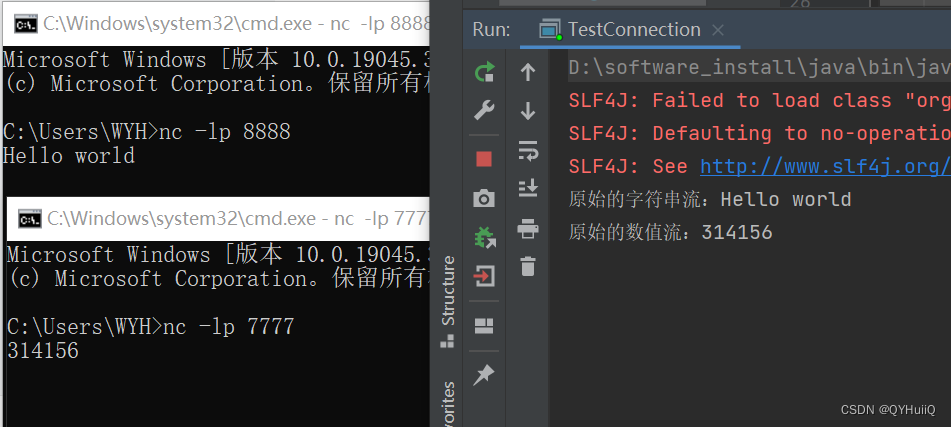
- 启动两个窗口
- 启动程序
此时在窗口中输入数据,注意在7777端要输入数字,8888端输入字符串,然后观察控制台输出。