1.论文题目
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2.论文摘要
本文引入了一种名为 BERT 的新语言表示模型,它代表 Transformers 的双向编码器表示。与最近的语言表示模型(Peters et al., 2018a;Radford et al., 2018)不同,BERT 旨在通过联合调节所有层中的左右上下文来预训练未标记文本的深度双向表示。因此,只需一个额外的输出层即可对预训练的 BERT 模型进行微调,从而为问答和语言推理等各种任务创建最先进的模型,而无需对特定于任务的架构进行大量修改。
BERT 概念简单,经验强大。它在 11 项自然语言处理任务上获得了最新的结果,包括将 GLUE 分数提高到 80.5%(绝对提高 7.7%)、MultiNLI 准确率提高到 86.7%(绝对提高 4.6%)、SQuAD v1.1问答测试 F1 达到 93.2(绝对提高 1.5 分),SQuAD v2.0 测试 F1 达到 83.1(绝对提高 5.1 分)。
3. 整体介绍与研究动机
两种将预训练的语言表示用于下游任务的策略:
- 基于特征(feature-based):例如 ELMo 模型,将包含预训练表示作为附加特征的特定任务架构。
- 微调(fine-tuning):例如 GPT 模型,引入了最少的特定于任务的参数,并通过简单地微调所有预训练参数来对下游任务进行训练。
这两种方法在预训练期间共享相同的目标函数,使用单向语言模型来学习通用语言表示。
作者认为,当前的技术限制了预训练表示的能力,特别是对于微调方法。主要限制是标准语言模型是单向的,这限制了在预训练期间使用的架构的选择。例如,在 OpenAI GPT 中,作者使用从左到右的架构,其中每个标记只能关注 Transformer 的自注意力层中的先前标记。这种限制对于句子级(sentence-level)任务来说是次优的,并且在将基于微调的方法应用于标记级(token-level)任务时可能非常有害,在这些任务中,从两个方向合并上下文至关重要。
在本文中,作者通过提出 BERT:Transformers 的双向编码器表示来改进基于微调的方法。 BERT 通过使用受 完形填空任务 (Taylor, 1953) 启发的 掩码语言模型 (Masked Language Model,MLM) 预训练目标来缓解前面提到的单向约束。掩码语言模型从输入中随机掩蔽一些标记,目标是仅根据其上下文来预测被掩蔽词的原始词汇表 id。与从左到右的语言模型预训练不同,MLM 目标使表示能够融合左右上下文,这使我们能够预训练一个深度双向 Transformer。除了掩码语言模型之外,我们还使用了 下一句预测任务,该任务联合预训练文本对表示。论文的贡献如下:
- 作者证明了双向预训练对语言表示的重要性。BERT 使用掩码语言模型来实现预训练的深度双向表示。
- 作者证明了预训练的表示减少了对许多精心设计的任务特定架构的需求。 BERT 是第一个基于微调的表示模型,它在大量句子级和标记级任务上实现了最先进的性能,优于许多特定于任务的架构。
- 源码和预训练模型下载: https://github.com/google-research/bert
4. 研究背景
4.1 Unsupervised Feature-based Approaches
ELMo 及其前身 (Peters et al., 2017, 2018a) 将传统的词嵌入研究沿不同的维度进行了推广。他们从从左到右和从右到左的语言模型中提取上下文相关的特征。每个标记(token)的上下文表示是从左到右和从右到左表示的连接(concatenation)。
在将上下文词嵌入与现有的特定任务架构集成时,ELMo 提升了几个主要 NLP 基准的最新技术水平,包括问答,情感分析和命名实体识别 。有研究提出通过使用 LSTM 从左右上下文预测单个单词的任务来学习上下文表示。与 ELMo 类似,他们的模型是基于特征的,而不是深度双向的。有研究表明完形填空任务可用于提高文本生成模型的鲁棒性。
4.2 Unsupervised Fine-tuning Approaches
最近,产生上下文标记表示的句子或文档编码器已经从未标记的文本中进行了预训练,并针对有监督的下游任务进行了微调。这些方法的优点是只需要从头开始学习很少的参数。至少部分由于这一优势,OpenAI GPT 在 GLUE 基准的许多句子级任务上取得了先前最先进的结果。
4.3 Transfer Learning from Supervised Data
这方面的研究有很多,比较著名的是计算机视觉领域,其证明了从大型预训练模型进行迁移学习的重要性,其中一个有效的方法是微调使用 ImageNet 预训练的模型。
5.解决思路
BERT模型的框架有两个步骤:
预训练(pre-training):BERT 模型通过不同的预训练任务在未标记数据上进行训练。
微调(fine-tuning):BERT 模型首先使用预训练的参数进行初始化,然后所有参数都使用来自下游任务的标记数据进行微调。
每个下游任务都有单独的微调模型,即使它们使用相同的预训练参数进行初始化。
BERT 的一个显着特点是其跨不同任务的统一架构。预训练架构和最终的下游架构之间相差无几。
BERT 的模型架构是基于原始实现的多层双向 Transformer 编码器。其实现几乎与原始版本的 Transformers 相同,具体可以参考Transformer论文和代码实现。
符号标记:
- L:层数(即 Transformer blocks)
- H:隐藏大小
- A:自注意力头的数量
模型架构有两种:
BERT(BASE): L= 12,H=768,A=12,总参数=110M
BERT(LARGE) :L=24,H=1024,A=16,总参数=340M
为方便比较,BERTBASE 与 OpenAI GPT 有相同的模型大小。重要的区别是,BERT Transformer 使用双向自注意力,而 GPT Transformer 使用受限自注意力,其中每个标记只能关注其左侧的上下文。
为了使 BERT 处理各种下游任务,输入表示能够在一个标记序列中明确表示单个句子和一对句子(例如问题 h、答案 i)。在整个工作中,“句子”可以是连续文本的任意跨度,而不是实际的语言句子。一个 “序列”是指输入到 BERT 的标记序列,它可能是一个句子,也可能是两个打包在一起的句子。
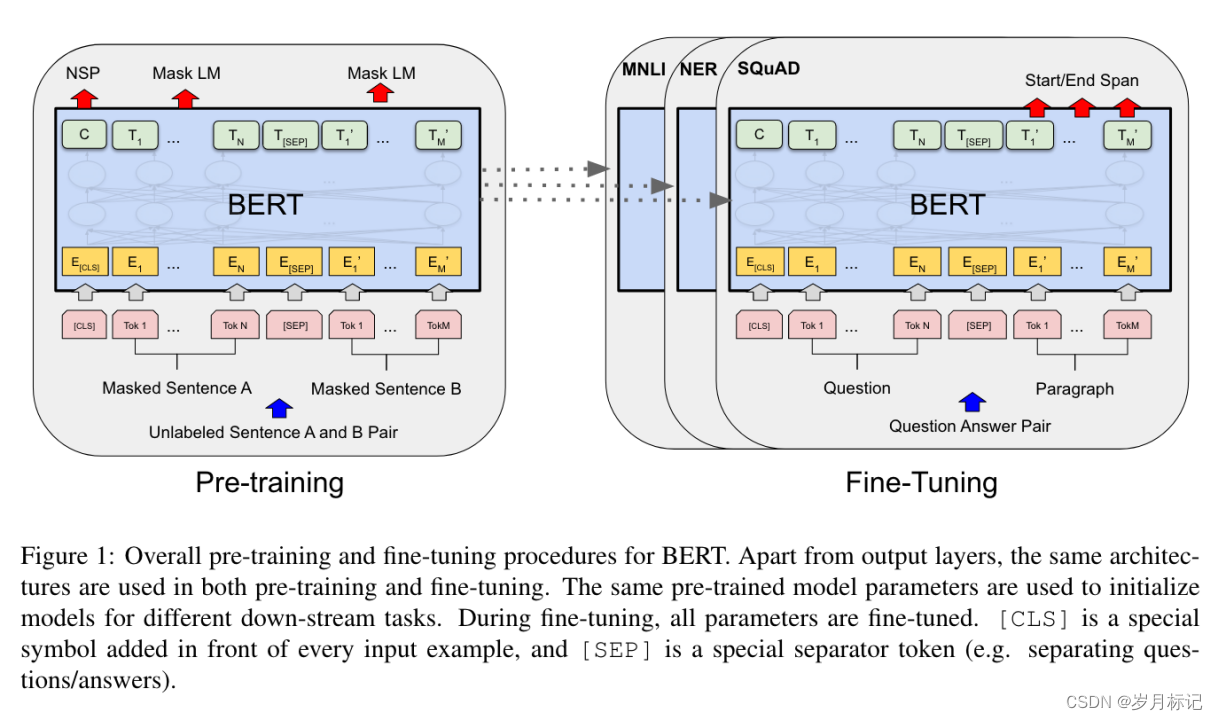
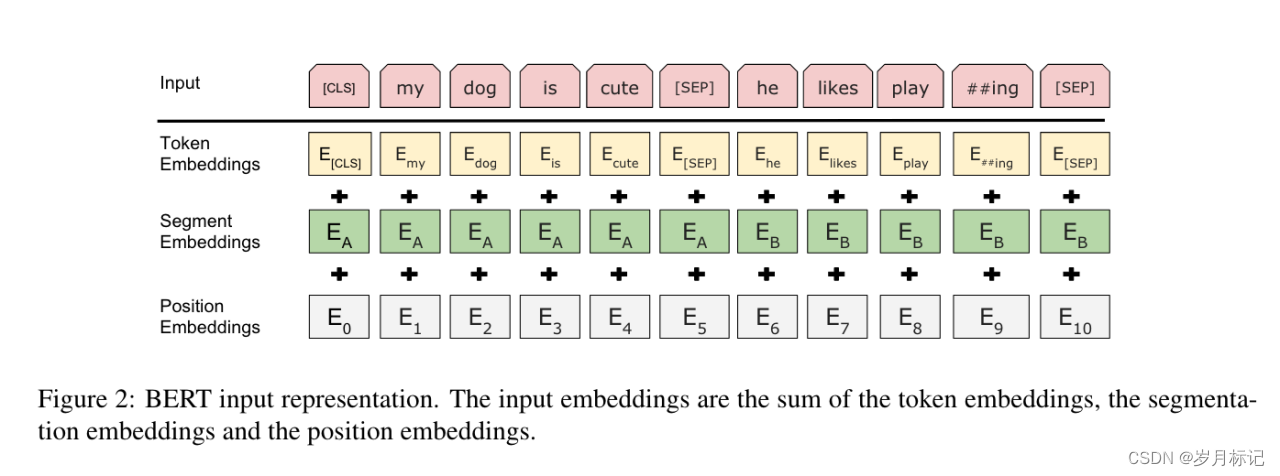
作者使用 WordPiece Embedding 和 30,000 个标记词汇。每个序列的第一个标记始终是一个特殊的分类标记 ([CLS])。与该标记对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被打包成一个单一的序列。作者以两种方式区分句子。首先,用一个特殊的标记([SEP])将它们分开。其次,向每个标记添加一个学习嵌入,指示它属于句子 A 还是句子 B。如图 1 所示,将输入嵌入表示为 E ,特殊 [CLS] 标记的最终隐藏向量表示为 C 。对于给定的标记,其输入表示是通过对相应的标记、段和位置嵌入求和来构造的。这种结构的可视化可以在图 2 中看到。
5.1 Pre-training BERT
Task #1: Masked LM
为了训练深度双向表示,我们简单地随机屏蔽一定百分比的输入标记,然后预测那些被屏蔽的标记。我们将此过程称为“Masked LM”(MLM),它在文献中通常被称为完形填空任务(Taylor,1953)。所有的实验中,我们随机屏蔽了每个序列中所有 WordPiece 标记的 15%。
尽管这使我们能够获得双向预训练模型,但缺点是我们在预训练和微调之间造成了不匹配,因为在微调期间不会出现 [MASK] 标记。为了缓解这种情况,我们并不总是用实际的 [MASK] 标记替换“masked”单词。训练数据生成器随机选择 15% 的标记位置进行预测。如果选择第 i 个标记,我们通过三种方式将第 i 个标记进行替换替换: 1) 80% 的时间用 [MASK] 标记 ;2) 10% 的时间用一个随机标记 ;3) 10% 的时间标记不变。然后,最终的隐藏向量 Ti ,通过softmax激活函数,预测原始标记。具体地:
- 80% 的时间将单词替换为 [MASK] 标记,例如,my dog is hairy → my dog is [MASK]
- 10% 的时间将单词替换为随机单词,例如,my dog is hairy → my dog is apple
- 10% 的时间保持单词不变,例如,my dog is hairy → my dog is hairy。这样做的目的是使表示偏向于实际观察到的单词。
Task #2: Next Sentence Prediction (NSP)
许多重要的下游任务,例如问答 (Question Answering,QA) 和自然语言推理 (Natural Language Inference,NLI),都是基于对两个句子之间关系的理解,而语言建模无法直接捕捉到这一点。为了训练一个理解句子关系的模型,我们预先训练一个二值化的下一个句子预测任务(binarized next sentence prediction task),该任务可以从任何单语语料库(monolingual corpus)中轻松生成。具体来说,在为每个预训练示例选择句子 A 和 B 时,50% 的时间 B 是 A 之后的实际下一个句子(标记为 IsNext),50% 的时间是语料库中的随机句子(标记为作为NotNext)。如图 1 所示,C 用于下一个句子预测 (NSP)。尽管它很简单,但我们在第 5.1 节中证明了针对此任务的预训练对 QA 和 NLI 都非常有益。
在之前的工作中,只有句子嵌入被转移到下游任务,但 BERT 转移所有参数来初始化最终任务模型参数。
对于预训练语料库,BERT 使用 BooksCorpus(8 亿单词)和英语维基百科(25 亿单词)进行预训练。
5.2 Fine-tuning BERT
微调很简单,因为 Transformer 中的自注意力机制允许 BERT 通过交换适当的输入和输出来对许多下游任务(无论它们涉及单个文本还是文本对)进行建模。对于涉及文本对的应用程序,一种常见的模式是在应用双向交叉注意之前独立编码文本对。但 BERT 使用自注意力机制来统一这两个阶段,因为使用自注意力对连接的文本对进行编码有效地包括了两个句子之间的双向交叉注意力。
6.实验过程和结果
本节展示了 11 个 NLP 任务的 BERT 微调结果。
6.1 GLUE
通用语言理解评估(General Language Understanding Evaluation ,GLUE)基准是各种自然语言理解任务的集合。
对于 BERTLARGE,作者发现微调有时在小型数据集上不稳定,因此我们运行了几次随机重启并在开发集上选择了最佳模型。通过随机重启,我们使用相同的预训练检查点,但执行不同的微调数据打乱(shuffle)和分类器层初始化。
6.2 SQuAD v1.1
斯坦福问答数据集 (Stanford Question Answering Dataset ,SQuAD v1.1) 是 10 万个众包问答对的集合。给出一个问题和一段来自维基百科的回答,任务是预测文章中的答案文本跨度。
6.3 SQuAD v2.0
SQuAD 2.0 任务扩展了 SQuAD 1.1 的问题定义,允许在提供的段落中不存在简短答案的可能性,使问题更加现实。
6.4 SWAG
Situations With Adversarial Generations (SWAG) 数据集包含 113k 句对完成示例,用于评估基于常识的推理。给定一个句子,任务是在四个选项中选择最合理的延续。
7.结论
由于语言模型的迁移学习而取得的实证改进表明,丰富的、无监督的预训练是许多语言理解系统不可或缺的一部分。特别是,这些结果甚至使低资源任务也能从深度单向架构中受益。本文的主要贡献是将这些发现进一步推广到深层双向架构,从而使相同的预训练模型能够成功处理广泛的 NLP 任务。
8.对 BERT 的总结与理解
- BERT 本质上是 Transformer 的 Encoder 端,Bert 在预训练时最基本的任务是:
- 判断输入的两个句子是否真的相邻
- 预测被 [MASK] 掉的单词
- 通过这两种任务的约束,可以让 Bert 真正学到:
- 上下句子之间的语义关系的关联关系,
- 一个句子中不同单词之间的上下文关系
- 所以通过 BERT 在大量文本中有针对的学习之后,BERT 可以真正做到对给定的句子进行语义层面的编码,所以他才能被广泛用于下游任务。
- BERT 是不需要大量人工标注数据的,这也是为什么他可以大规模训练预训练模型。
- 对于第一种训练任务,我们只需要在给定的段落中随机挑选两句相邻的句子就可以组成正样本,而随机挑选两个不相邻的句子就可以组成负样本。
- 对于第二种训练任务,只需要对于给定的句子语料,对其中的单词按照一定比例的 mask 操作即可,因为 mask 的部分只是模型不知道其存在,但是我们还是知道 mask 的部分的真实标签的,所以还是可以做监督学习的任务,而且还是自监督。