人类理解自然语言的方式有很多,但是绝大多数用的还是通过上下文来推断某些词的含义。现代自然语言处理也是基于这个方式来进行建模的
我们来看一个例子,如下

可以知道,in,large是修饰crate的,look是修饰in the crate的,in the kitchen是修饰crate的,by the door也是修饰crate的
语言中存在歧义现象,如下
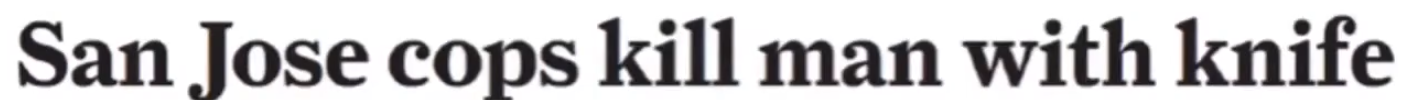
这个句子可以理解为警察用刀杀了人,也可以理解为警察杀了持刀的人
还比如
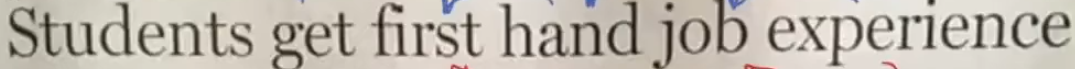
这个句子人类一般都不会发生歧义了,但是其实是有两种解读方法的,除了一眼看上去的那种,还有一种是Students get first / hand job / experience.
那么我们人类的大脑是有非常好的辨识歧义的能力的,比如这里肯定就是后一种意思。对于模型来说,他也需要具备我们人类这种能力,而他则是通过概率来选择/理解最有可能的情况的
接下来介绍树库的概念。首先是一棵树,只有一个根节点,表示句子的中心词,如下
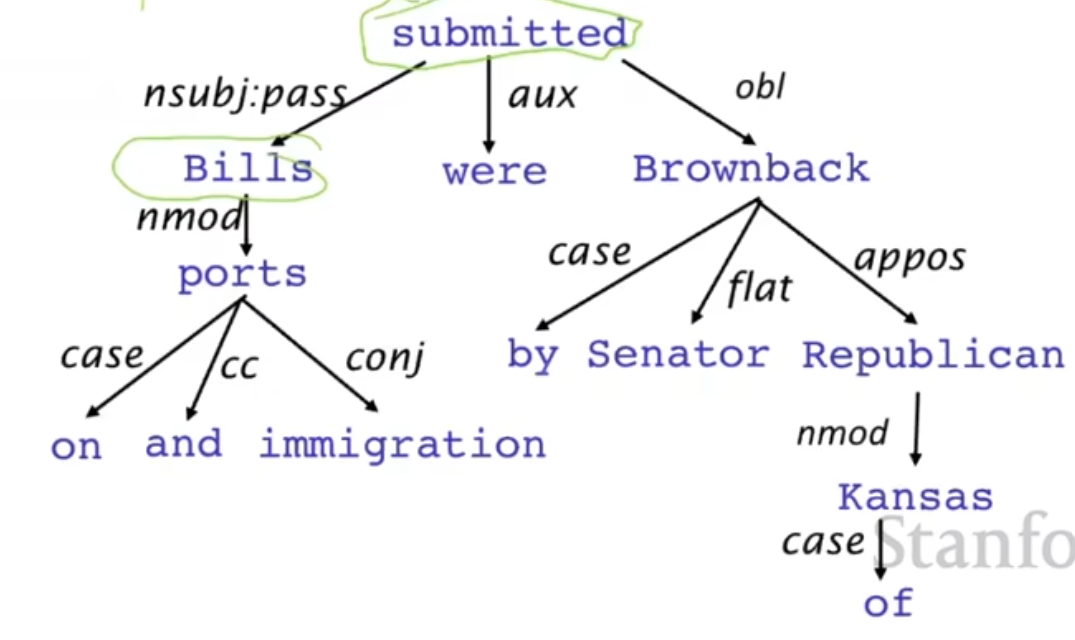
树库就是由这些树组成的库,有许多好处,如下
树库(Treebank)是一种带有句法结构标注的语料库,为自然语言处理(NLP)和语言学研究提供了重要支持。以下是其核心优势的具体解释及示例:
1. 复用劳动成果(Reusability of the labor)
树库的标注需要大量人工劳动,但一旦完成,即可被多次重复利用。研究者无需重复标注,可直接在不同项目中共享资源。
示例:英语的 Penn Treebank 是早期经典树库,被广泛用于句法分析、词性标注等任务,节省了后续研究的时间和成本。
2. 支持构建多种工具(Parsers, taggers, etc.)
基于树库的标注数据,可以训练或优化多种自然语言处理工具。
示例:
- 句法分析器:如 Stanford Parser 使用 Penn Treebank 训练,能够自动分析句子结构。
- 词性标注器:如 SpaCy 的部分模型依赖树库数据提升标注准确性。
3. 语言学研究的资源(Valuable resource for linguistics)
树库为语言学家提供了真实的语法结构数据,支持对语言现象的定量分析。
示例:通过分析树库中的疑问句标注,语言学家可以研究英语倒装结构的分布规律(如 "What did you see?" vs. "You saw what?")。
4. 广泛的覆盖范围(Broad coverage)
树库通常包含多样化的语料(如新闻、对话、学术文本),而非局限于少量人工构造的例句。
示例:Universal Dependencies (UD) Treebanks 涵盖 100+ 种语言的多样化语料,包括社交媒体文本和正式文献。
5. 频率与分布信息(Frequencies and distribution)
树库能统计语法结构在实际使用中的频率,揭示语言规律。
示例:通过分析树库数据,可发现英语中被动语态在学术文本中的使用频率显著高于口语(如 "The experiment was conducted" vs. "Someone did the experiment")。
6. 评估 NLP 系统(Evaluation of NLP systems)
树库作为“黄金标准”,可量化评估 NLP 工具的性能。判断模型是否能够像人类一样解析句子结构。
示例:句法分析器的准确率常通过在 Penn Treebank 上的测试结果衡量(如标注匹配率或依存关系准确率)。
树库的上述优势使其成为 NLP 和语言学研究的基石,既推动了技术发展,也深化了人类对语言本质的理解。
那么模型如何从树库中获取信息呢?有四种方法

- 第一种方法就是在树上一条边的两个端点是很相似的
- 第二种方法就是树上距离不远的点是很相似的
- 第三种方法就是依存(相似)关系基本上不会跨过动词
- 第四种方法就是,举个例子,the只会出现在名词前面,不会出现在名词后面
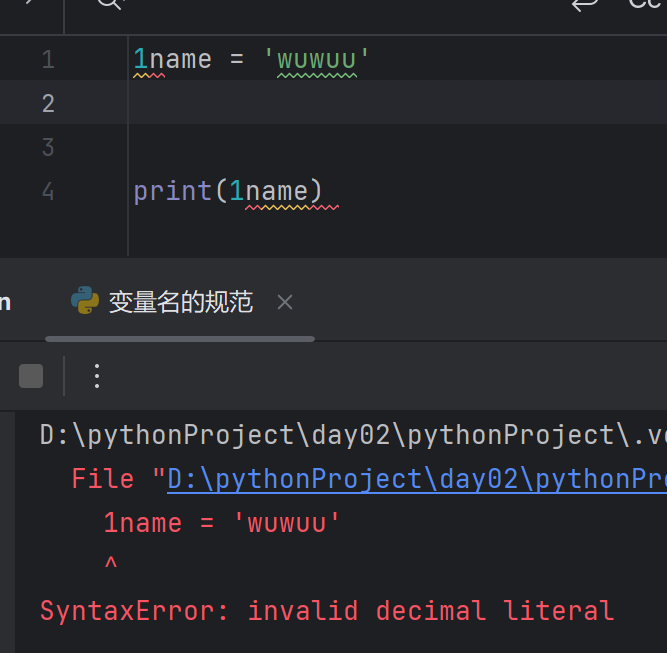
视频01:04:00的时候讲了如何构建解析器,但是看不懂,之后去看一下
不知道是不是翻译的问题,没怎么看懂。可以在B站搜索一下其他的课程看一下