一、编写wordcount案例
1、新建java项目
2、添加storm的jar包
storm软件包中lib目录下的所有jar包
3、编写java类
WordCountTopology.java
package com.bjsxt.storm.wc;import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.utils.Utils;public class WordCountTopology {public static void main(String[] args) {// 拓扑封装了计算逻辑TopologyBuilder builder = new TopologyBuilder();// 设置lineSpout:该spout负责向拓扑发送句子builder.setSpout("lineSpout", new LineSpout());// 设置切分闪电,该闪电处理从水龙头lineSpout通过随机分组发送过来的元组builder.setBolt("splitBolt", new SplitBolt()).shuffleGrouping("lineSpout");// 定义一个计数闪电,该闪电从splitBolt闪电通过按字段分组的方式分发过来的元组// 按照元组中word的值进行分组。要保证相同的单词一定发送给同一个闪电。builder.setBolt("countBolt", new CountBolt()).fieldsGrouping("splitBolt", new Fields("word"));// 通过建造者创建一个拓扑的实例StormTopology wordCountTopology = builder.createTopology();// 本地模拟集群LocalCluster cluster = new LocalCluster();Config config = new Config();// 将拓扑提交到本地模拟集群cluster.submitTopology("wordCountTopology", config, wordCountTopology);// 睡眠10s,也就是让本地模拟集群运行10sUtils.sleep(10000);// 关闭本地模拟集群cluster.shutdown();}}LineSpout.java
package com.bjsxt.storm.wc;import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;import java.util.Map;public class LineSpout extends BaseRichSpout {private SpoutOutputCollector collector;private String[] lines = {"The logic for a realtime application is packaged into a Storm topology","A stream is an unbounded sequence of tuples that is processed and created in parallel in a distributed fashion","A spout is a source of streams in a topology","Bolts can do anything from filtering, functions, aggregations, joins, talking to databases, and more.","A stream grouping defines how that stream should be partitioned among the bolt's tasks.","Storm guarantees that every spout tuple will be fully processed by the topology","Each spout or bolt executes as many tasks across the cluster","Each worker process is a physical JVM and executes a subset of all the tasks for the topology"};private int index = 0;@Overridepublic void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {// 在该组件在集群中初始化的时候调用一次this.collector = collector;}@Overridepublic void nextTuple() {// 由storm的线程不停地调用,以便从数据源获取元组// 该方法不需要自己写循环和遍历// 该方法不能阻塞// 负责从数据源获取元组,向DAG发送元组// 轮询取出句子String lingStr = lines[index % lines.length];// 将句子封装为元组发射collector.emit(new Values(lingStr));index++;Utils.sleep(10);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {// 用于声明元组的结构以及流
// declarer.declareStream("s1", new Fields("key1", "key2", "key3"));
// declarer.declareStream("s2", new Fields("key21", "key22"));// 发送元组的时候就有一个字段,是line,它的值是句子// 可以将元组想象为map集合,只不过其key是固定的几个declarer.declare(new Fields("line"));}
}SplitBolt.java
package com.bjsxt.storm.wc;import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;import java.util.Map;public class SplitBolt extends BaseRichBolt {private OutputCollector collector;@Overridepublic void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {this.collector = collector;}@Overridepublic void execute(Tuple input) {String lineStr = input.getStringByField("line");String[] wordStrs = lineStr.split(" ");for (String wordStr : wordStrs) {// <hello, 1>this.collector.emit(new Values(wordStr, 1));}}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word", "count"));}
}CountBolt.java
package com.bjsxt.storm.wc;import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;import java.util.HashMap;
import java.util.Map;public class CountBolt extends BaseRichBolt {private Map<String, Integer> counts;@Overridepublic void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {counts = new HashMap<>();}@Overridepublic void execute(Tuple input) {
// new Fields("word", "count")String wordStr = input.getStringByField("word");Integer count = input.getIntegerByField("count");Integer sum = counts.get(wordStr);if (sum == null) {counts.put(wordStr, count);} else {counts.put(wordStr, sum + count);}counts.forEach((k, v) -> {System.out.println(k + "_________" + v);});System.out.println("========================================");}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}
}4、运行
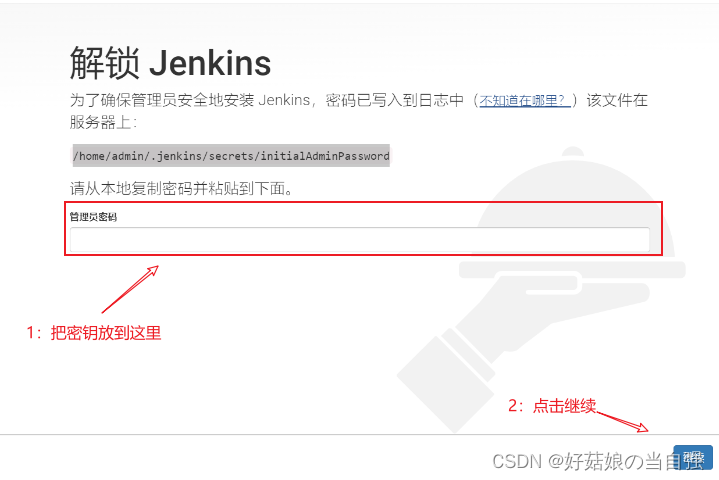
右键运行WordCountTopology
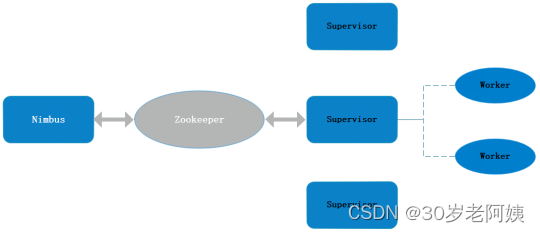
二、Storm整体架构
| Storm配置项 | 说明 |
| java.library.path | Storm本身依赖包的路径,存在多个时用冒号分隔 |
| storm.local.dir | Storm使用的本地文件系统目录(必须存在并且storm进程可读写)。默认是storm的根目录下的storm-local。 |
| storm.zookeeper.servers | storm集群对应的zookeeper集群的主机列表 |
| storm.zookeeper.port | storm集群对应的zookeeper集群的服务端口,zookeeper默认端口为2181 |
| storm.zookeeper.root | storm的元数据在zookeeper中存储的根目录,默认值是/storm |
| storm.cluster.mode | storm运行模式,local或distributed。集群模式需设置为distributed |
| storm.messaging.transport | storm的消息传输机制,使用netty作为消息传输时设置为backtype.storm.messaging.netty.Context |
| nimbus.host | 整个storm集群的nimbus节点 |
| nimbus.supervisor.timeout.secs | storm中每个被发射出去的消息处理的超时时间,该时间影响到消息的处理,同时在storm ui上杀掉一个拓扑时的默认时间(kill动作发出后多长时间才会真正将该拓扑杀掉)。默认值是60 |
| ui.port | storm自带UI,以http服务形式支持访问,此处设置该http服务的端口(非root用户端口号需要大于1024) |
| ui.childopts | storm UI进程的java参数设置(对java进程的约束都可以在此设置,如内存等) |
| logviewer.port | 此处用于设置该Log Viewer进程的端口(Log Viewer进程也是http形式,需要运行在每个storm节点上)。默认值8000 |
| logviewer.childopts | Log Viewer进程的参数设置 |
| logviewer.appender.name | storm log4j的appender,设置的名字对应于文件storm/log4j2/cluster.xml中设置的appender,cluster.xml可以控制storm logger的级别 |
| supervisor.slots.ports | storm的slot,最好设置为OS核数的整数倍;同时由于storm是基于内存的实时计算,slot数不要大于每台物理机可运行slot个数:(物理内存-虚拟内存)/单个java进程最大可占用内存数 |
| worker.childopts | storm的worker进程的java限制,有效地设置该参数能够在拓扑异常时进行原因分析: -Xms1024m -Xmx1024m -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+HeapDumpOnOutOfMemoryError 其中:Xms为单个java进程最小占用内存数,Xmx为最大占用内存数,设置HeapDumpOnOutOfMemoryError的好处是,当内存使用量超过Xmx时,java进程将被JVM杀掉同时会生成java_pid<pid数字>.hprof文件,使用MemoryAnalyzer分析hprof文件将能分析出内存使用情况从而进行相应的调整、分析是否有内存溢出等情况 |
| storm.messaging.netty.buffer_size | netty传输的buffer大小,默认为5MB,当spout发射的消息较大时,此处需要对应调整 |
| storm.messaging.netty.max_retries | 这几个参数是关于使用netty作为底层消息传输时的相关设置,需要重视,否则可能由于bug而引起错误: java.lang.IllegalArgumentException: timeout value is negative |
| storm.messaging.netty.max_wait_ms | |
| storm.messaging.netty.min_wait_ms | |
| topology.debug | 该参数可以在拓扑中覆盖,表示该拓扑是否运行于debug模式。运行于debug模式时,storm将记录拓扑中收发消息等的详细信息,线上环境不建议打开 |
| topology.acker.executors | storm通过acker机制保证消息不丢失,此参数用于设置每个拓扑的acker数量,由于acker基本消耗的资源较小,强烈建议将此参数设置在较低的水平,可以在拓扑中进行覆盖 |
| topology.max.spout.pending | 一个spout任务中处于pending状态的最大元组数量。该配置应用于单个任务,而不是整个spout或拓扑,可在拓扑中进行覆盖。 |
此外,storm/log4j2/cluster.xml文件中可以配置storm的日志级别矩阵信息等。
操作系统的配置,其中有两项需要配置(通过ulimit -a查看):
1、open files:当前用户可以打开的文件描述符数。
2、max user processes:当前用户可以运行的进程数,此参数太小将引起storm的一个错误:
java.lang.OutOfMemoryError: unable to create new native thread
部署注意事项:
- 在storm根目录下有一个lib目录,存放storm本身依赖的jar包,此处的所有jar会被storm worker进行启动时加载,个人编写的jar包不能放在此处,以免包更新带来不便
- 向storm集群提交拓扑时,建议将该拓扑所有依赖的jar包和业务源代码打到一个jar包中(fat jar),如此则业务需要的jar包都和拓扑在同一个jar包中,否则当拓扑依赖的jar包更新时需要将该更新包放到所有的storm节点上。如果是在一个集群中,fat jar可以保证不同业务的jar包是独立的,不会混淆。
nimbus
- 接收jar包:提交应用拓扑
- 任务分配:将拓扑的任务分配给worker
- 资源调度:监控各个supervisor节点的状态进行负载均衡等。
- Nimbus不需要像supervisor节点那么高的配置,storm ui也不需要高配置,可以和nimbus节点运行在同一台服务器节点上。
supervisor
- 监听nimbus的任务分配,启动分配到的worker来对相应的任务进行处理。
- 监控本地的worker进程,如果发现状态不正常会杀死worker并重启,超过一定次数后将分配给该错误状态的worker的任务交还给nimbus进行再次分配。
- 删除本地不再运行的任务
worker
完成拓扑中定义的业务逻辑,即执行拓扑的进程。
一个worker的基本执行步骤:
- 根据zookeeper中拓扑的组件分配变化,创建或移除worker到worker的链接
- 创建executor(执行器)的输入队列receive-queue-map和输出队列transfer-queue
- 创建worker的接收线程receive-thread和发送线程transfer-thread
- 根据组件分配关系创建executor
- executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务
- 在executor中执行具体的任务(spout或者bolt)来执行具体的业务逻辑。
- 检查需要运行的task信息
- 获取相应的task信息,即spout/bolt信息
每个任务对应一个线程或多个任务对应一个线程
线程称为executor
executor在worker中运行
worker是一个JVM进程
在supervisor中运行
worker中的数据流:
worker中线程间通信使用的是Disruptor,进程间通信可能是netty也可以是zmq。默认使用netty。
数据流:
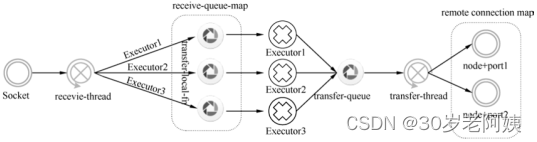
- 每个worker绑定一个socket端口作为数据的输入,此端口作为socket的服务器端一直监听运行。
- 根据拓扑的关系,确定需要向外通信的任务所在的worker地址,并同该worker也创建好socket连接,此时该worker是作为socket的客户端。
- receive thread负责将每个executor所需要的数据放入对应的receive-queue-map中,然后由executor来获取自己所需要的数据,这个过程通过disruptor进行通信。
- executor执行完操作需要对外发送数据时,首先kryo将数据序列化,然后通过disruptor将数据放入对外的transfer-queue中。
- transfer thread完成数据的发送工作。
- 如果executor需要对外发送的数据接收方和executor在同一个worker节点,则不需要执行序列化操作,调用disruptor的publish方法直接放到接收方的executor对应的队列中即可。
与MapReduce架构的对比:

提交作业过程
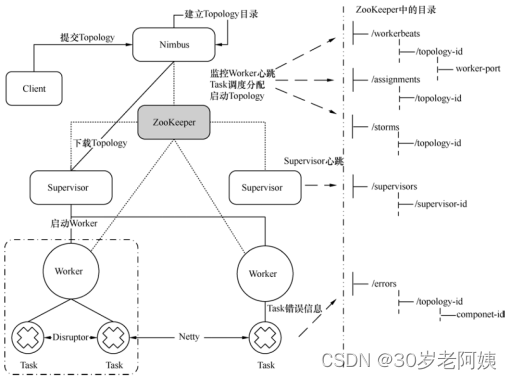
- 客户端提交拓扑代码到nimbus的nimbus/inbox目录下。
- nimbus对topology进行校验、处理
- nimbus针对该拓扑建立本地目录:nimbus/stormdist/topology-id
该目录下有三个文件:
-
- stormjar.jar 从nimbus/inbox移动来的topology的jar包
- stormcode.ser 对topology对象的序列化
- stormconf.ser topology的运行配置信息
- nimbus的调度器根据拓扑的配置计算task,并把task分配到不同的worker上,调度的结果写入zookeeper的/task节点下。
- zookeeper上建立assignments节点,存储task和supervisor中worker的对应关系。
- zookeeper上创建workerbeats节点监控worker的心跳。
- supervisor去zookeeper上获取分配的task信息,启动一个或多个worker来执行。
- 每个worker上运行多个task,task由executor来执行。
- worker根据拓扑信息初始化建立task之间的连接
- 相同worker内的task通过DisruptorQueue通信,不同worker间默认采用netty通信