前言
前面三章将数据初步整理出来:
1.安卓恶意应用识别(一)(Python批量爬取下载安卓应用)
2.安卓恶意应用识别(二)(安卓APK反编译)
3.安卓恶意应用识别(三)(批量反编译与属性值提取)
未涉及到任何机器学习部分,我们知道机器学习中特征选择是一个重要步骤,需要筛选出显著特征,摒弃非显著特征,这样可以提高训练速度,减少噪声干扰,提升模型效果。
1. 特征生成的方法
关于如何生成特征,我在一文归纳Python特征生成方法(全)中找到了相关信息。
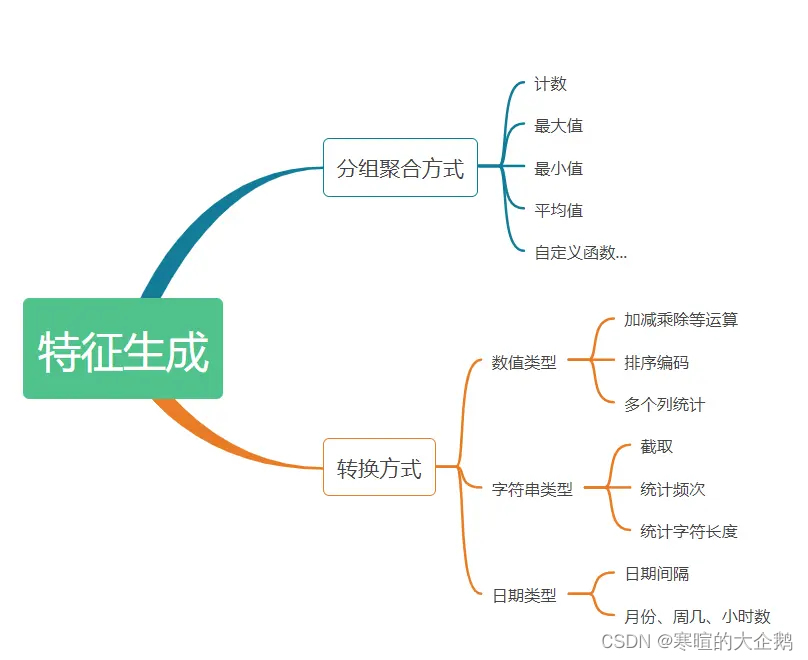
如上图所示,根据生成方式可以分为分组聚合方式和转换方式。其中,分组聚合方式就是求原始数据的相关数学统计量,而转换方式就是将原始数据根据数据类型进行转换从而生成特征。
2. 字符串特征生成
由于上三篇基础得到的属性值为字符串,因此本章仅对字符串类型的数据进行特征生成,引用文献数据特征处理之文本型数据(特征值化一)。
先装一下sklearn包,发现仍然no moudle,于是查阅运行报错no module named sklearn,再安装一个模块叫scikit-learn,就没报错了。
这里仅仅对benign1中.xml文件的uses-permission的属性值做了特征生成,可以看到下图生成了稀疏矩阵(特征值矩阵)
上代码理解:
import re
from collections import Counter
from xml.dom.minidom import parse
from sklearn.feature_extraction.text import CountVectorizer
from character_handle.frequency_order import sample_get
def counter(arr):return Counter(arr)
list_uses_permission = []
# 加载XML,并提取属性值xmldom = parse(sample_get.get_file("benign1"))for element in xmldom.getElementsByTagName("uses-permission"):a = element.getAttribute("android:name")b = re.findall(r'\w{1,}', a)[-1]list_uses_permission.append(b)
count_v = CountVectorizer()
data = count_v.fit_transform(list_uses_permission)
# 输出标签为uses-permission的属性值(顺序)
print(list_uses_permission)
# 输出属性值列表(汇按照英文字母表的顺序排列)
print(count_v.get_feature_names())# 输出词条列表对应的值化数据
print(data.toarray())
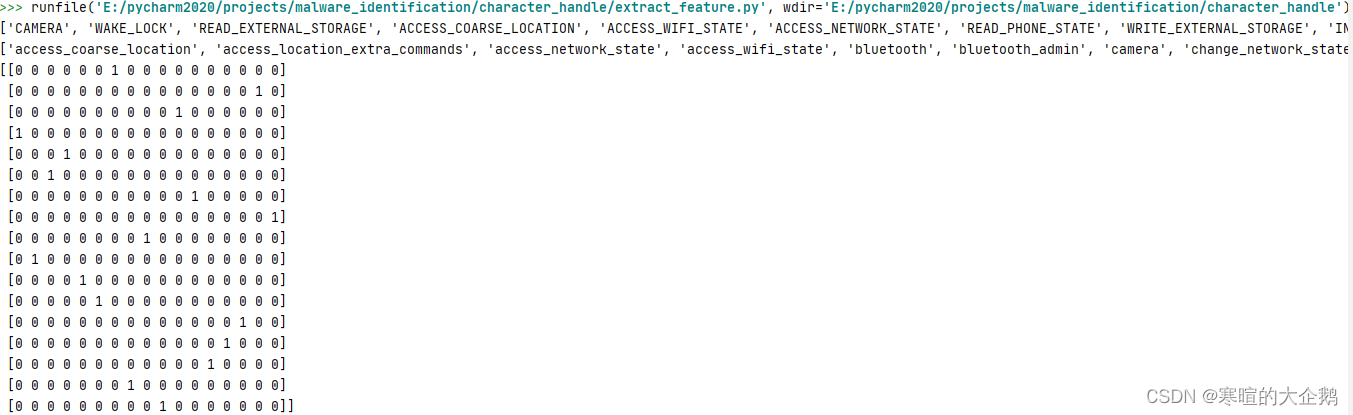
当然了,上面的只是在benign1中一个例子,因而每个属性值在这个矩阵中只会出现一次。但在实际训练之前,我们在确定了需要用到哪些经典特征值后,是需要以一个xml文件中是否出现这些经典特征值为依据来保存特征向量集合的。
3. 数据处理
首先说一下,目前我处理获取这些样本是需要比较大的内存的,我也不知道如何去改善他,除非反编译一个.xml文件后就将其他文件删除,这样全部获得的就是.xml文件,不需要占用很大空间,这种方法就自己去自动化实现了。本文主要基于大内存,我买了一张1个T的移动硬盘,所以这些样本,包括安装包等等都能装下,以便以后需要分析不同的文件使用,如果只是学方法,看到前面这些就够了。
3.1 原数据获取
本节主要把之前缺少的数据处理给补上,我又继续在360助手网站上爬取下载了安卓应用928个(其中有两个被腾讯管家报风险软件),暂且将其全部视为良性应用。然后,在github中(自行查看)下载了501个恶意应用暂且当作实验。
把恶意应用全部重命名,方法见Python 文件夹批量重命名,和良性应用相统一。
3.2 反编译数据获取
同样的,批量反编译良性和恶性应用的apk:
import datetime
import os
import subprocess
import threadingdef execCmd(cmd):try:print("命令%s开始运行%s" % (cmd, datetime.datetime.now()))# os.system(cmd)subprocess.Popen(cmd, shell=True, stdout=None, stderr=None).wait()print("命令%s结束运行%s" % (cmd, datetime.datetime.now()))except:print('%s\t 运行失败' % (cmd))def batchDecompile(cmds):if cmds:# if if_parallel:# 并行threads = []for cmd in cmds[0:20]:th = threading.Thread(target=execCmd, args=(cmd,))print("start !!!!!!!!")th.start()threads.append(th)# 等待线程运行完毕for th in threads:# 现在有 A, B, C 三件事情,只有做完 A 和 B 才能去做 C,而 A 和 B 可以并行完成。th.join()print("OK!!!!!!!!!!!")del cmds[0: 20]return batchDecompile(cmds)# 需要执行的命令
cmds = ["F: & cd F:\\benign_apk & " + "apktool.bat d -f " + "benign" + str(i) + ".apk" for i in range(276,929)]
# 良性应用有929个,因为我之前不会彻底批量化,只能手动批量化处理了275个,现在这个程序是能够直接批量化处理到底的
batchDecompile(cmds)
这是一个漫长的时间,等待二者都全部反编译完成后。
3.3 特征获取
我们在上述批量化反编译中已经得到了500个良性和500个恶意样本,接着对其进行权限属性提取(代码在第2节有),每个样本都是一个列表,其中包含多个(可能重复)的属性值
# 如下
benign_samples = [ ["send_msg","call"..."call" .. ], [ samples2 ], ... ,[samples n] ]
malicious_samples = [ ["send_msg","call"..."call" .. ], [ samples2 ], ... ,[samples n] ]
然后,再对其进行特征向量获取,我在这里使用了改进的TF-IDF算法[1](见参考引文)对特征进行提取:
# 计算单个特征属性在正例样本中和在反例样本中的TF-IDF平均值差异
def compute_feature_difference(positive_samples, negative_samples):vectorizer = TfidfVectorizer()# 将文档转换为TF-IDF特征向量positive_tfidf_matrix = vectorizer.fit_transform([" ".join(sample) for sample in positive_samples])negative_tfidf_matrix = vectorizer.transform([" ".join(sample) for sample in negative_samples])# 计算平均值positive_avg_tfidf = positive_tfidf_matrix.mean(axis=0)negative_avg_tfidf = negative_tfidf_matrix.mean(axis=0)# 计算差异tfidf_difference = np.abs(positive_avg_tfidf - negative_avg_tfidf)return tfidf_difference# 选择差异绝对值前5%的特征作为特征子集
def select_top_features(tfidf_difference):# 计算前5%特征属性的数量top_percentage = 0.05num_top_features = int(tfidf_difference.shape[1] * top_percentage)# 获取前5%特征属性的索引top_feature_indices = np.argsort(tfidf_difference.A1)[::-1][:num_top_features]return top_feature_indices# 使用你的改进版TF-IDF算法将文档转换为TF-IDF矩阵
tfidf_difference = compute_feature_difference(positive_samples, negative_samples)
selected_features = select_top_features(tfidf_difference)# 使用选定的特征子集构建TF-IDF特征矩阵
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([" ".join(sample) for sample in positive_samples + negative_samples])
tfidf_matrix_selected = tfidf_matrix[:, selected_features]# 标签:1表示正例,0表示负例
labels = [1] * len(positive_samples) + [0] * len(negative_samples)
构建好样本之后,就可以开始带入机器学习模型进行分类了:
# 创建SVM分类器
svm_classifier = SVC(kernel='linear', random_state=42)# 定义交叉验证的评估指标(这里使用准确度)
scoring = make_scorer(accuracy_score)# 进行十折交叉验证
cross_val_scores = cross_val_score(svm_classifier, tfidf_matrix_selected, labels, cv=10, scoring=scoring)# 打印每折交叉验证的准确度
print("Cross-Validation Accuracy Scores:", cross_val_scores)# 打印平均准确度
print("Mean Accuracy:", np.mean(cross_val_scores))
以下为十折交叉验证得到平均的准确率,因为我跑的时候只用了200个样本(良性100,恶意100),所以可能结果不尽如人意,你们可以尝试自己修改样本个数,筛选前百分之k,作为特征子集,以提高分类器的效率。

以上算法的思想来自于:
[1]潘建文,张志华,林高毅等.基于特征选择的恶意Android应用检测方法[J/OL].计算机工程与应用:1-10[2023-10-25].http://kns.cnki.net/kcms/detail/11.2127.tp.20221104.1411.008.html