大家好啊,我是董董灿。
最近,分组卷积帮我解决了一个大忙,事情是这样的。
这几天遇到一个头疼的问题,就是要在某一芯片上完成一个神经网络的适配,这个神经网络中卷积居多,并且有一些卷积的通道数很大,比如2048个输入通道。
问题是,该芯片是专用芯片,所对应的硬件模块无法直接支持这种通道数很大的卷积运算。
于是开始了头脑风暴,因为芯片中有良好的向量指令集来支持内积运算,因此第一反应便是拿内积运算来拼凑出卷积。
但实验结果表明,利用内积指令来拼凑的卷积效果不如人意,主要在于内积指令调用次数过多,导致神经网络的整体性能太差。
就在一筹莫展时,一个声音传过来,“我们改图吧”。
改图,指的是改神经网络的结构,很多推理框架都具备这个能力,比如pytorch,tvm等。
这些推理框架可以针对性的适配某些专用AI芯片加速器,为此魔改一些神经网络结构,通过增加一些优化节点(pass),来使原本不支持的运算变为可支持的运算。
比如这个卷积的例子,可以将一个大卷积(指的是通道数很大),魔改为两个或多个小卷积,分别计算,计算完成后再将结果合并。
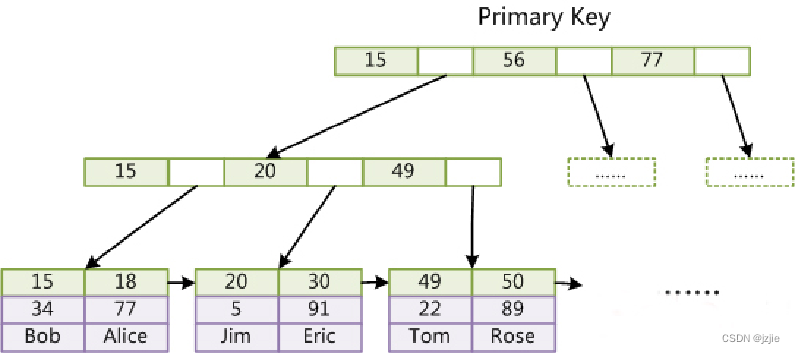
这就要提一下将卷积在通道维度分成多个卷积计算的操作——分组卷积(Group Convolution)了。
1、 什么是分组卷积
网上有很多关于分组卷积的资料。说的简单点,分组卷积是将卷积在channel 维度分组来计算,以达到将一个大卷积分成多个小卷积的目的。
为了清晰,我们将卷积操作简化为一次最简单的乘累加运算,channel维度只有2个数据,如下图。
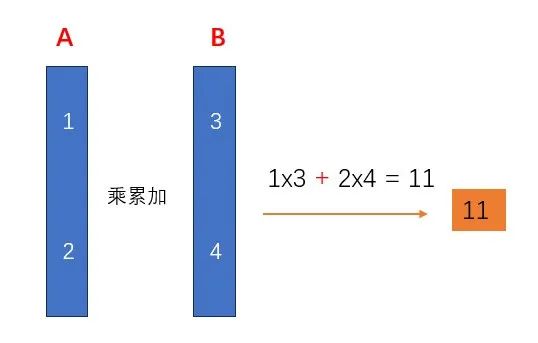
正常的卷积操作,A和B的乘累加,计算的是 1x3 + 2x4 = 11。
而如果将其在channel维度分组(例子中channel维度只有两个数据,我们就分成两组),那么会是这样
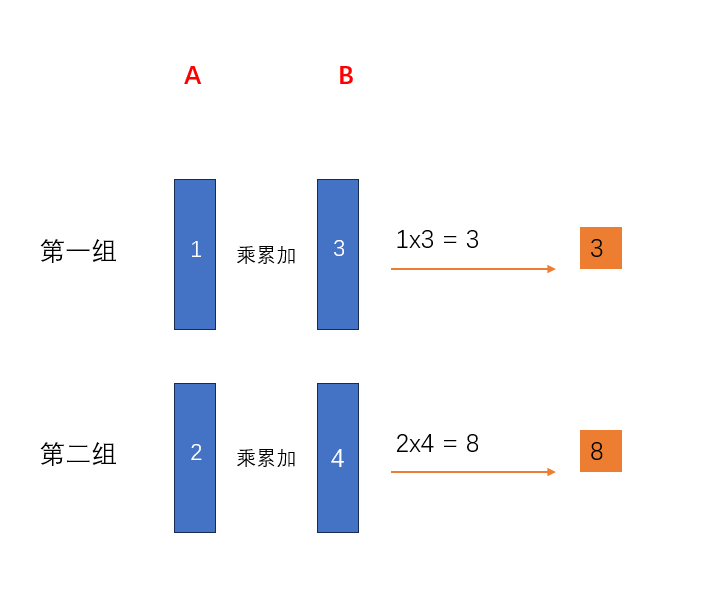
第一组只计算channel 维度的前半部分,第二组只计算channel维度的后半部分。
分组的过程是不是很好理解。
2、为什么需要分组卷积
分组卷积最早由Alex等人在2012年的ImageNet图像分类竞赛中提出并使用,提出的初衷是为了解决卷积神经网络训练期间的计算和内存开销问题。
2012年的GPU不像现在的GPU内存那么大,当初GPU内存还很有限,一个channel通道数很大的卷积直接计算,放在整个网络中,是很耗费内存的。
于是,他们把大卷积在通道方向拆分成多个小卷积来分别计算,这样可以让拆分出来的多个小卷积分别运行在多张GPU卡上,达到一个模型多卡并行计算的目的,从而提高训练性能。
需要说明的是,论文中的分组卷积不仅将输入通道进行了分组,同时将输出通道进行了分组。
由此而来的分组卷积,在计算量上变为原来的1/G,G为分组的组数。
3、分组卷积和原始卷积在数学上等价吗?
细心的小伙伴可能会问这个问题。
如果仅仅说分组卷积,那么结果肯定和原始大卷积不等价,因为把channel维度给拆开了。
并且如果不做处理,还会影响最终的推理精度,对于这个问题,有个很好的解决办法。
我们知道,卷积算法的核心是特征提取和融合:5分钟理解什么是卷积的特征提取。
如果不进行其他操作,那么分组卷积仅仅进行了组内小卷积的特征融合,而缺少了分组间的特征融合,这样对于最终的训练推理结果会有影响。
为了解决这个问题,往往在分组卷积前在channle维度进行 shuffle 操作,也就是洗牌,使得特征可以随机的分配到每一个组内,能够更好的完成组间的特征融合。
4、“分组卷积“”的思想神了
回到上面我遇到的问题,我们需要在自己的需求下,利用分组卷积的思想,魔改大卷积运算。
如下示意图:一个输入channel 为 ci 的卷积,通过 split 在输入 channel 维度拆成两个 ci/2 的卷积,然后“分组”进行卷积操作,然后通过加法进行相加。
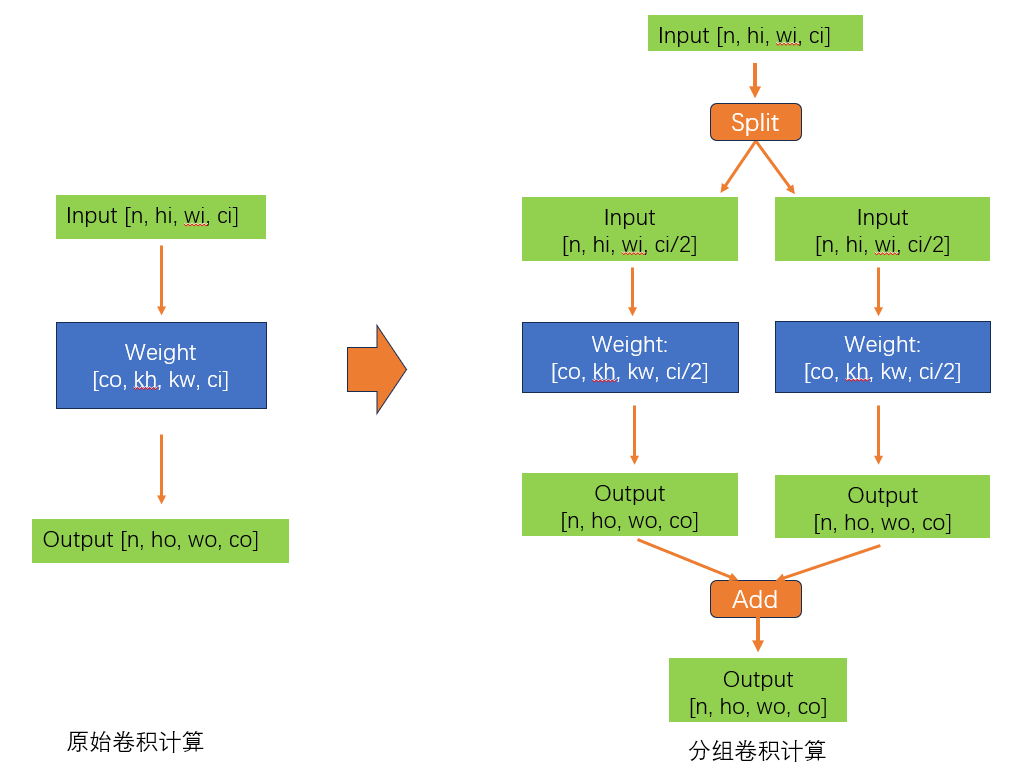
这里并没有对输出channel 进行分组,因为我们解决的问题不一样,内存对我们来说不是问题,问题仅仅在于输入channel太大。
而通过上面的魔改变换,便可以使得最终的结果和原始卷积计算一致,借用“分组卷积”的思想,可以很好的解决我遇到的问题。