双向链表
双向链表的特点是它有两个指针,一个指针指向前置节点,一个指针指向后继节点。所以,双向链表可以支持 常量 O(1) 时间复杂度的情况下找到前驱结点,基于这样的特点。双向链表在插入和删除操作的时候,要比单向链表简单、高效。
AQS使用双向链表
因此,从双向链表的特性来看,我认为 AQS 使用双向链表有三个方面的考虑:
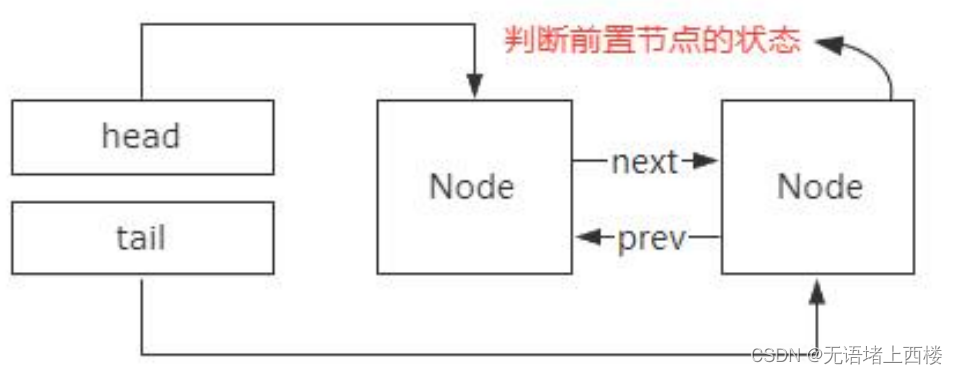
第一个方面,没有竞争到锁的线程加入到阻塞队列,并且阻塞等待的前提是,当前线程所在节点的前置节点是正常状态,这样设计是为了避免链表中存在异常线程导致无法唤醒后续线程的问题(如图)所以线程阻塞之前需要判断前置节点的状态,如果没有指针指向前置节点,就需要从 head 节点开始遍历,性能非常低。
第二个方面,在 Lock 接口里面有一个,lockInterruptibly()方法,这个方法表示处于锁阻塞的线程允许被中断。也就是说,没有竞争到锁的线程加入到同步队列等待以后,是允许外部线程通过interrupt()方法触发唤醒并中断的。这个时候,被中断的线程的状态会修改成 CANCELLED。(如图)被标记为 CANCELLED 状态的线程,是不需要去竞争锁的,但是它仍然存在于双向链表里面。意味着在后续的锁竞争中,需要把这个节点从链表里面移除,否则会导致锁阻塞的线程无法被正常唤醒。在这种情况下,如果是单向链表,就需要从 Head 节点开始往下逐个遍历,找到并移除异常状态的节点。同样效率也比较低,还会导致锁唤醒的操作和遍历操作之间的竞争
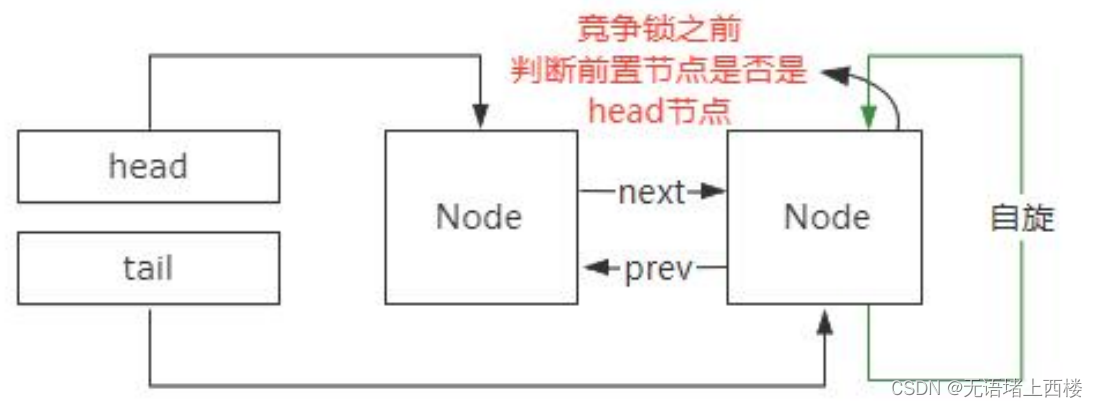
 第三个方面,为了避免线程阻塞和唤醒的开销,所以刚加入到链表的线程,首先会通过自旋的方式尝试去竞争锁。但是实际上按照公平锁的设计,只有头节点的下一个节点才有必要去竞争锁,后续的节点竞争锁的意义不大。否则,就会造成羊群效应,也就是大量的线程在阻塞之前尝试去竞争锁带来比较大的性能开销。所以,(如图)为了避免这个问题,加入到链表中的节点在尝试竞争锁之前,需要判断前置节点是不是头节点,如果不是头节点,就没必要再去触发锁竞争的动作。所以这里会涉及到前置节点的查找,如果是单向链表,那么这个功能的实现会非常复杂。
第三个方面,为了避免线程阻塞和唤醒的开销,所以刚加入到链表的线程,首先会通过自旋的方式尝试去竞争锁。但是实际上按照公平锁的设计,只有头节点的下一个节点才有必要去竞争锁,后续的节点竞争锁的意义不大。否则,就会造成羊群效应,也就是大量的线程在阻塞之前尝试去竞争锁带来比较大的性能开销。所以,(如图)为了避免这个问题,加入到链表中的节点在尝试竞争锁之前,需要判断前置节点是不是头节点,如果不是头节点,就没必要再去触发锁竞争的动作。所以这里会涉及到前置节点的查找,如果是单向链表,那么这个功能的实现会非常复杂。