K8S高可用集群节点规划
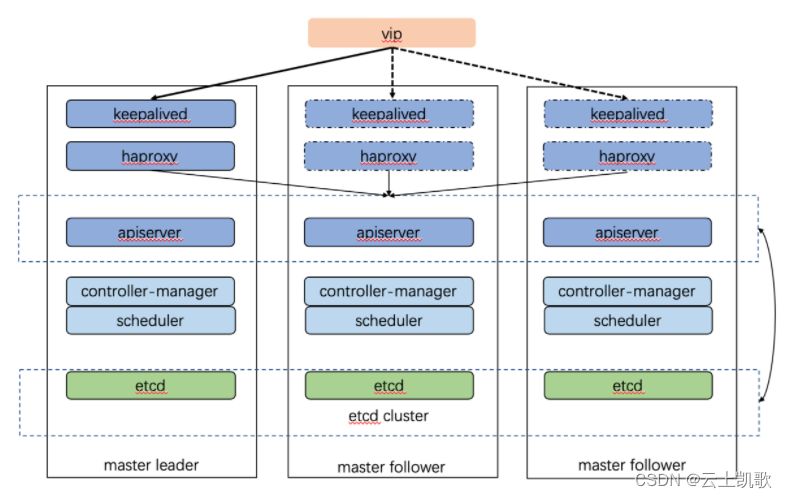
1、部署拓扑图
2、master节点数(物理机数)
| 总数 | 最少存活 | 失败容忍 | 说明 |
|---|---|---|---|
| 1 | 1 | 0 | 单个主节点时使用 |
| 2 | 2 | 0 | 不推荐 |
| 3 | 2 | 1 | 推荐 |
| 4 | 3 | 1 | 不推荐 |
| 5 | 3 | 2 | 推荐 |
| 6 | 4 | 2 | 不推荐 |
| 7 | 4 | 3 | 可以考虑,但会导致确定集群成员和仲裁的开销加大 |
| 8 | 5 | 3 | 不推荐 |
| 9 | 5 | 4 | 可以考虑,但会导致确定集群成员和仲裁的开销加大 |
说明:
-
k8s的一致性算法是RAFT,要求集群需要数量
(n/2)+1的正常主节点才能提供服务 -
脑裂现象:集群中的Master或Leader节点往往是通过选举产生的。
在网络正常的情况下,可以顺利的选举出
Leader。但当两个机房之间的网络通信出现故障时,选举机制就有可能在不同的网络分区中选出两个Leader。当网络恢复时,这两个Leader该如何处理数据同步?又该听谁的?这也就出现了“脑裂”现象。为了避免脑裂的问题,给出了一个规定:集群中存活的节点数必须要超过总节点数的半数才能继续提供服务,而正是由于这个规定,导致集群中n台和n+1台你的容灾能力是一样的(n为奇数),都只能坏一台。
-
奇数的原因是防止资源的浪费,因此3个主节点有1个节点的容错率,而4个主节点也只有1个节点的容错率
-
3或5则是因为1个没有容错率,7个主节或更多将导致确定集群成员和仲裁的开销加大,不建议这样做
3、worker节点数量
- Kubernetes 支持最多 5000 个节点的集群
- 可以按照需求追加worker节点,但是如果计划使用超过 500 个节点,需要考虑主节点性能瓶颈