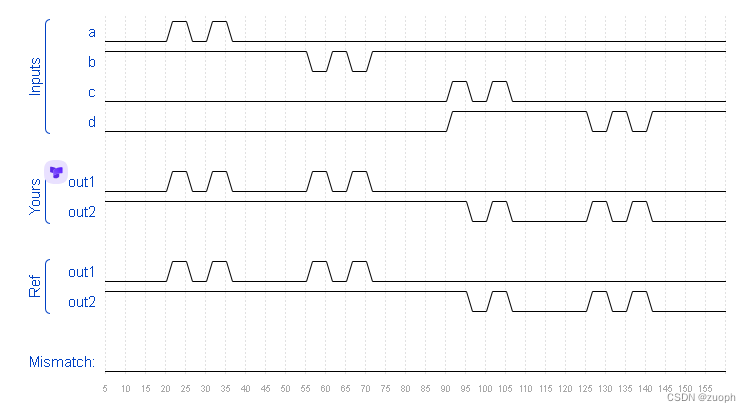
习题4-1
对于一个神经元![]() ,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢.
,并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢.
证明:
激活函数以sigmoid为例。
神经元:有两层,线性层和激活层:y=w*x+b,然后y‘=sigmoid(y),也就是。
梯度下降:在激活函数的导数方向进行更新【因为梯度方向下降速度最快】。
零均值化:对于一个样本特征,可以使用如下公式实现零均值化处理:x_new = (x - x_mean) / N,使得特征数据之间具有可比性。同时零均值化是一种常用的数据正则化方法,可以有效地防止模型过拟合和提高模型训练效果。
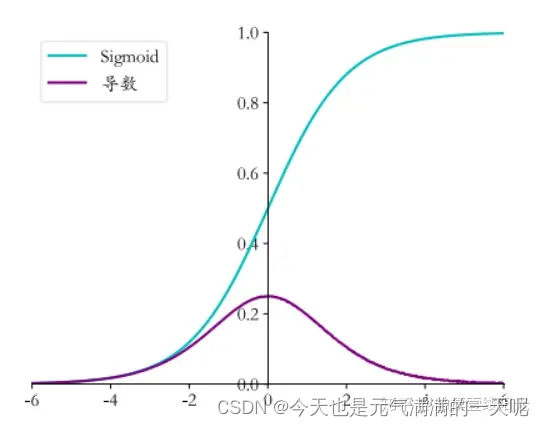
如上图所示,在激活函数的值为0时,导数最大,下降速度最快;两侧距离原点越远导数越小,下降速度越慢。 神经元对求导后的结果为
,由图可知
值大于0。
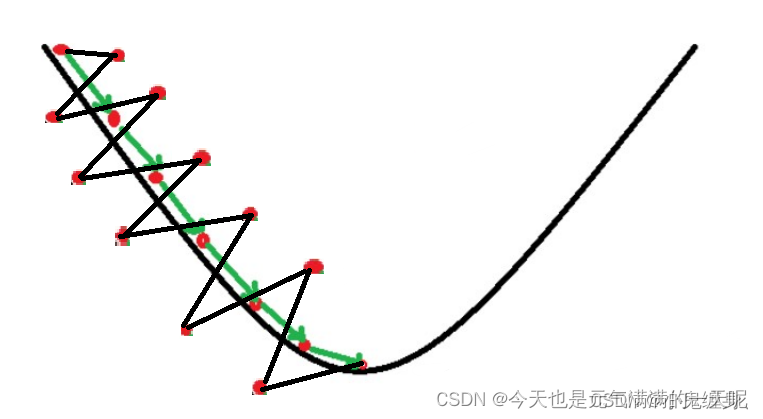
输入x恒大于0,其梯度也不会是最大值,接近0,所以收敛速度变慢。如果对输入进行了0均值化处理,可以使得线性层的值y_mean为0,这样在y'=sigmoid(y),优化w参数时收敛速度快,得到最优w的效率更高,如下图所示,绿线是对x进行零均值后的梯度下降效果,黑线是未进行零均值化的下降效果。【图来自神经网络与深度学习第四章前馈神经网络习题解答-CSDN博客】
习题4-5
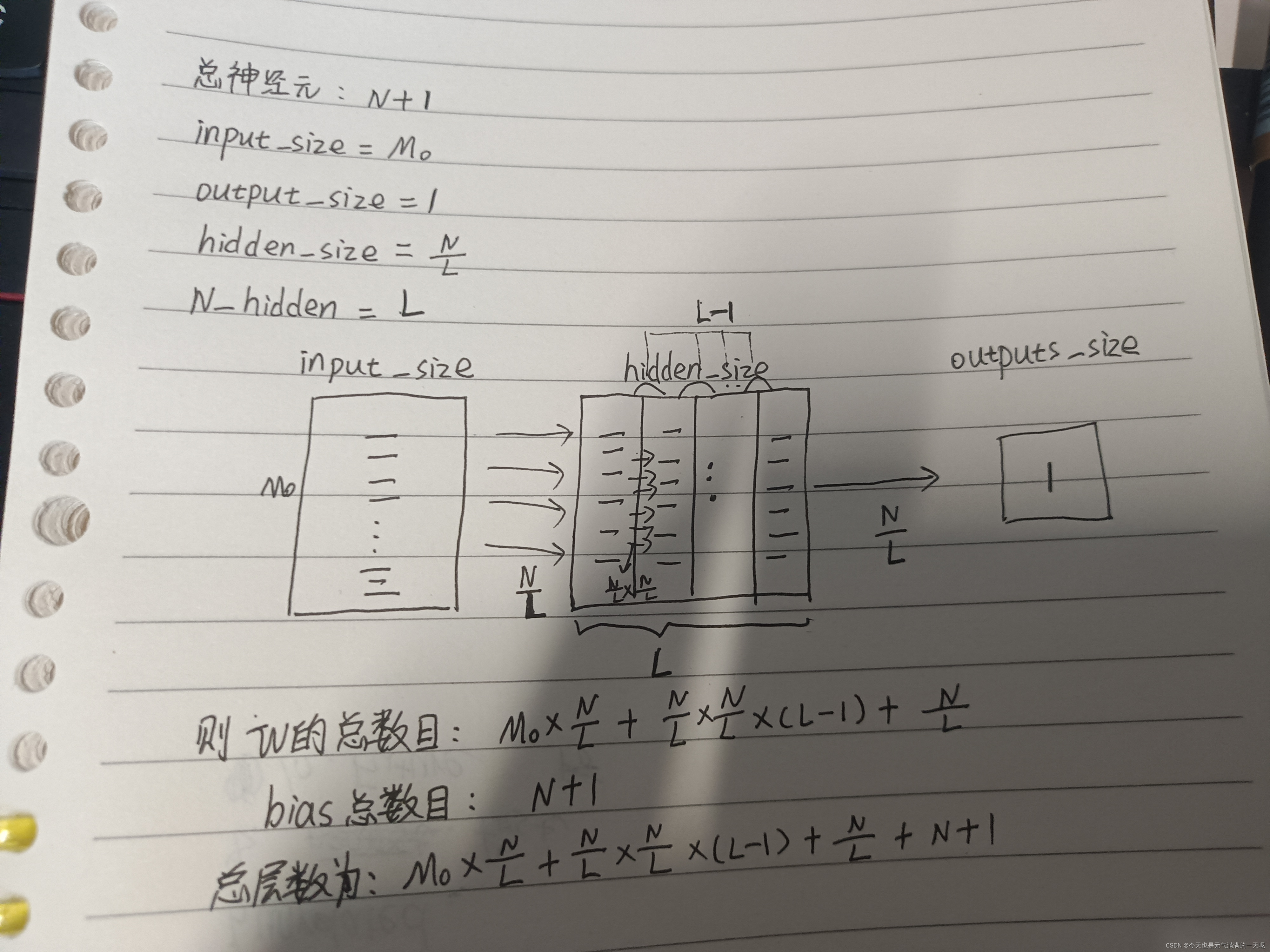
如果限制一个神经网络的总神经元数量(不考虑输入层)为N+1,输入层大小为,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为
,试分析参数数量和隐藏层层数L的关系.
【最后一行汉字写错了,是总参数数量】
习题4-7
为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
正则化目的:为了减少过拟合风险,通过引入正则化惩罚项,可以限制模型参数的大小,可以提高模型的泛化能力。
不对bias正则化的原因:
1.函数y=w*x+bias中bias只影响函数的向上向下平移,它对输入x的变化并不敏感。
2.对bias正则化并不会减少模型的过拟合风险,反而要为它选择合适的正则化系数,使得训练过程更加复杂。
3.对b进行正则化,会减少模型的复杂度,会造成欠拟合情况。
习题4-8
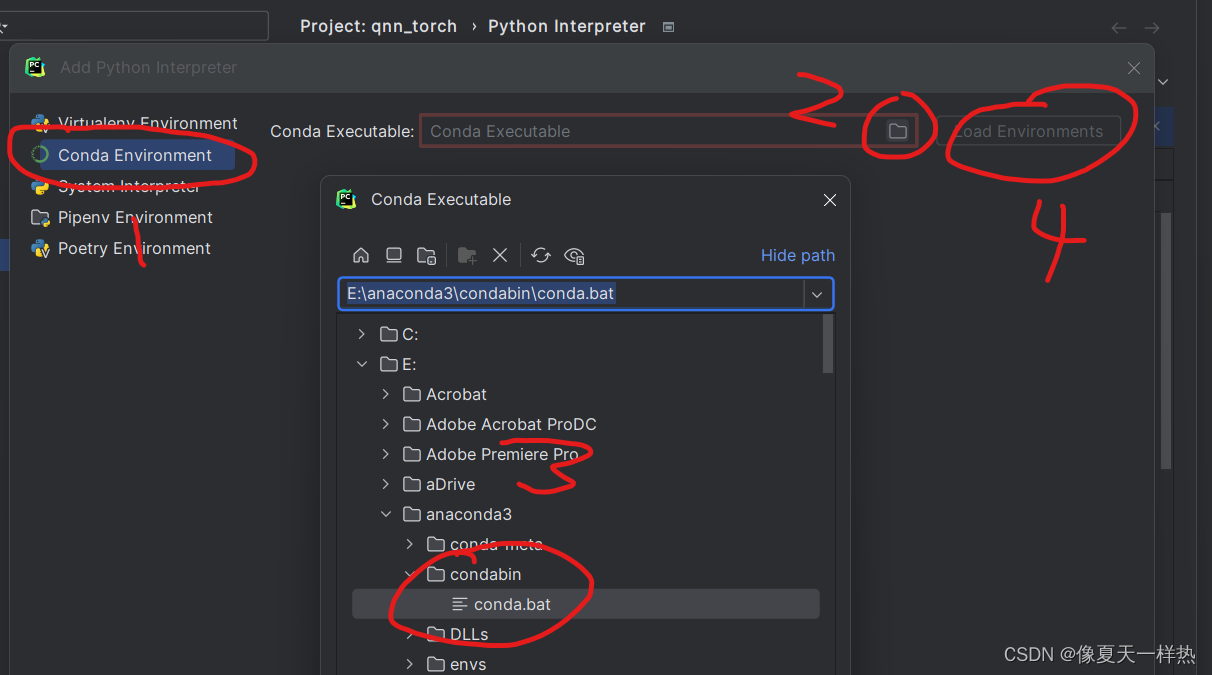
为什么在用反向传播算法进行参数学习时要采用随即参数初始化的方式而不是直接令W=0,b=0?
反向传播算法进行参数学习的过程,就是将最后的误差一层层传入到输入层。
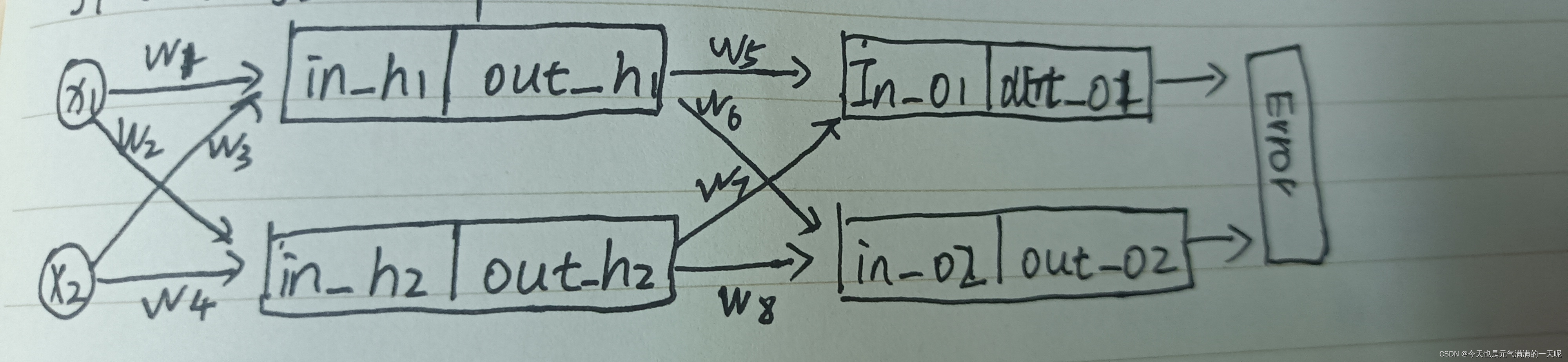
上图可知,在w=0和b=0,前向传播计算得到的隐藏层值都一样,再反向传播中计算得到的梯度一样,那么每层的参数都一样,即相当于中间只有一层隐藏层。多层神经网络就没有意义了。
习题4-9
梯度消失问题是否可以通过增加学习率来缓解
不可以。
梯度消失举个例子,以sigmoid函数为例,在本文的前边的图中可以看到,当值过大过小时,梯度都非常接近于0,更新参数不明显,这就是梯度消失现象。
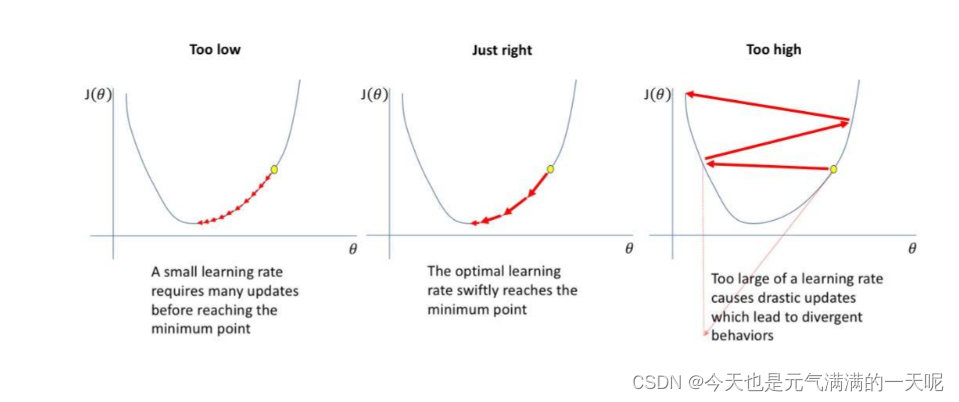
增加学习率并不会缓解梯度消失,学习率变大时,会使得参数跳过最优值点,然后梯度方向改变,最终导致参数优化时无法收敛。如下图所示【图来自学习率 | 机器之心 (jiqizhixin.com)】。
想要解决梯度下降问题可以使用导数比较大的激活函数,所以可以改成别的激活函数来解决梯度下降问题。【图来自【深度学习】梯度消失和梯度爆炸原因及解决 - 知乎 (zhihu.com)】: