目录
1.HTTP协议与WEB开发
(1)简介
(2)请求协议和响应协议
2. requests&反爬破解
(1)UA反爬
(2)referer反爬
3.请求参数
(1)get请求以及查询参数
(2)post请求以及请求体参数
4.爬虫图片和视频
(1)直接爬取媒体数据流
5.打码平台
获取验证码
打码平台:图鉴
1.模拟登陆(破解验证码)
2.抖音下载一个视频

1.HTTP协议与WEB开发
我们要知其然并知其所以然,在讲爬虫之前先把他的 “根” 说清楚
互联网是什么?
简单地说:互联网本身就是一种信息的分享和传递,我们上网的过程本质上就是一种下载资源的过程。
(1)简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网
(WWW:World Wide Web)服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
(2)请求协议和响应协议
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。用于HTTP协议交互的信被为HTTP报文。请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字文本。
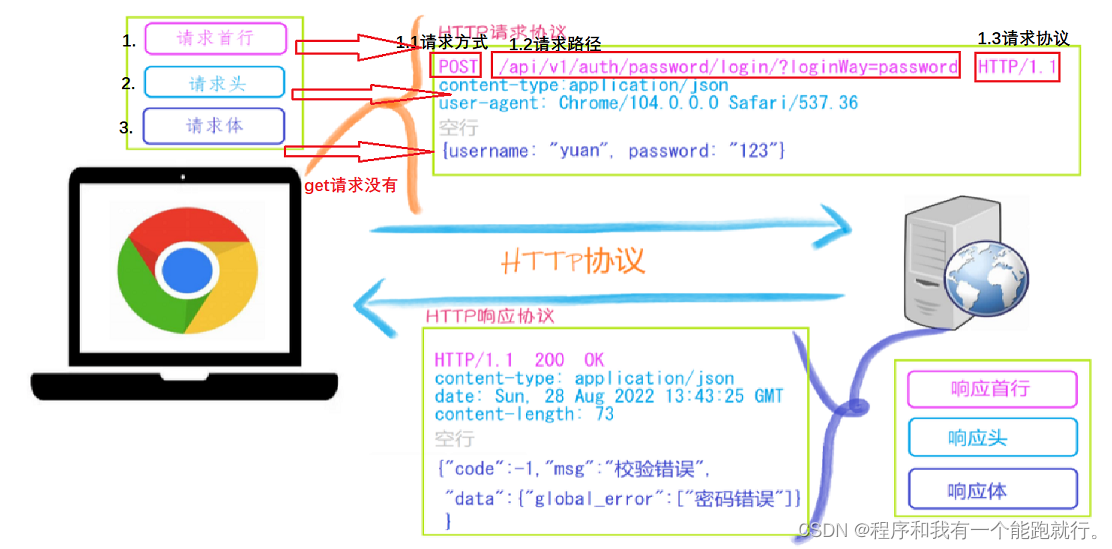
一个完整的URL包括:协议、ip、端口、路径、参数
URL: https://www.baidu.com/s?wd=yuan 协议://域名(IP)/路径?查询参数(a=1&b=2&c=3)请求方式:get与post请求
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
响应状态码:状态码 是当客户端向服务器端发送请求时, 返回的请求结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出 现了 。状态码如200 OK,以3位数字和原因组成。
请求头:
-
Accept:能够接收的数据格式
- Accept-Encoding:能够接收的压缩方式
-
User-Agent:客户端代理
-
Content-Type:指定发送的请求体数据的编码类型和格式。
2. requests&反爬破解
(1)UA反爬
import requestsurl = 'https://www.baidu.com/'
my_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}resp = requests.get(url, headers=my_headers)
# print(resp.status_code) # 响应状态码
# print(resp.headers) # 响应头
# print(resp.text) # 响应返回的内容# 文档下载
with open('baidu.html', 'w', encoding='utf-8') as f:f.write(resp.text)(2)referer反爬
两种请求:
- text(html)
- AJAX/json(html、css、js)
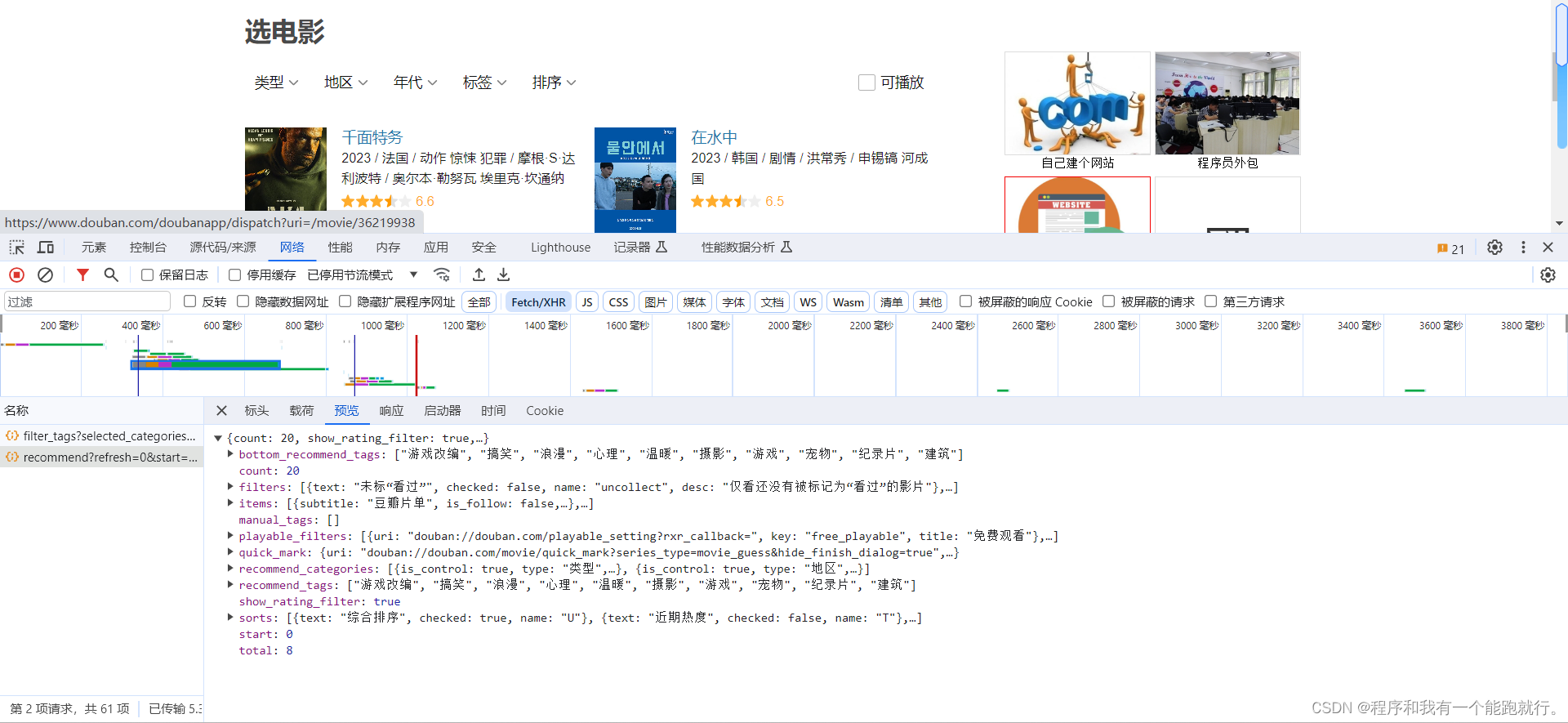
import requestsurl = 'https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags='
my_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/explore'
}resp = requests.get(url, headers=my_headers)
# print(resp.json())with open('douban.json','w') as f:f.write(resp.text)(3)cookie反爬
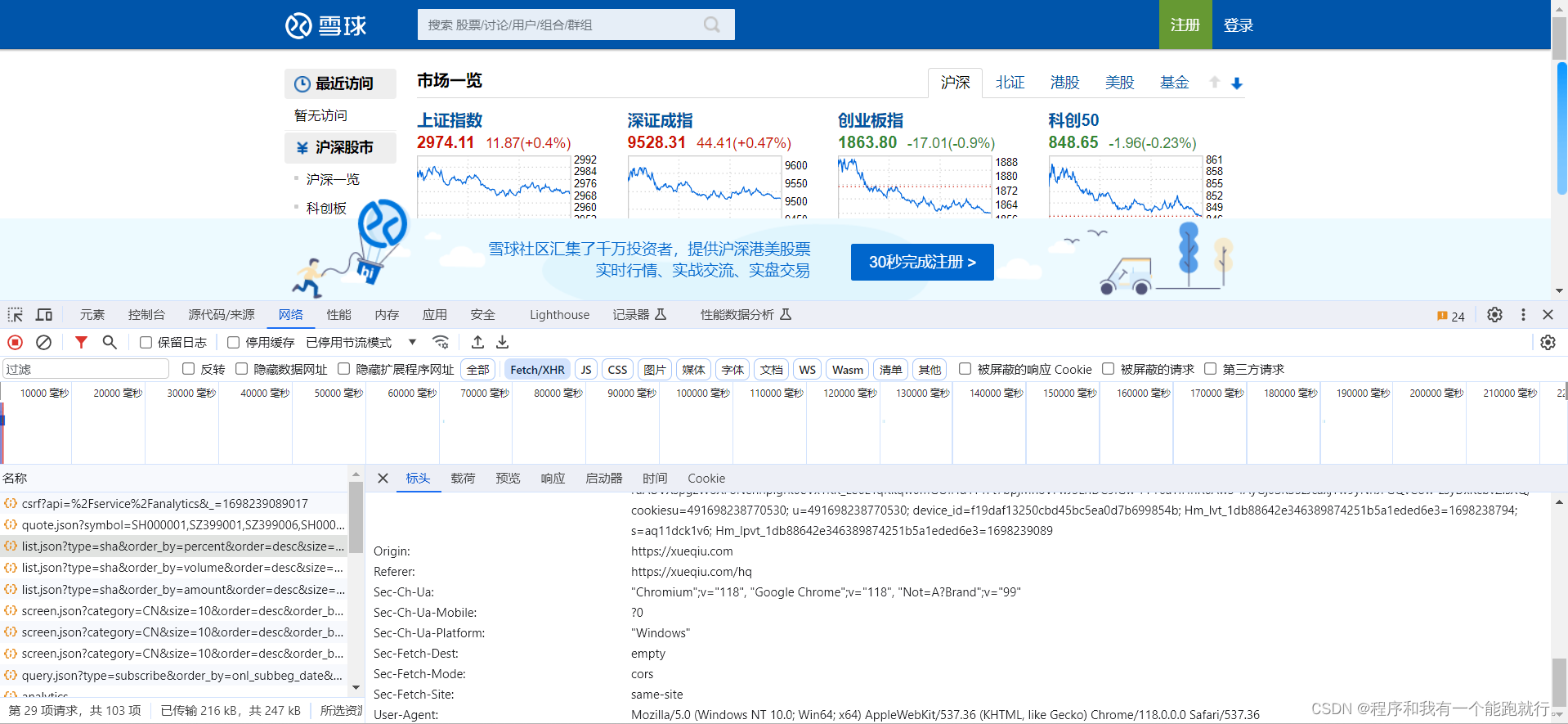
import requestsurl = 'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?type=sha&order_by=percent&order=desc&size=10&page=1'
cookie='xq_a_token=e2f0876e8fd368a0be2b6d38a49ed2dd5eec7557; xqat=e2f0876e8fd368a0be2b6d38a49ed2dd5eec7557; xq_r_token=2a5b753b2db675b4ac36c938d20120660651116d; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwMDY5OTg3NSwiY3RtIjoxNjk4MjM4NzE0MTc3LCJjaWQiOiJkOWQwbjRBWnVwIn0.aqSRg4NSgDo_B0rpAi6IqTX6bgyfKElHCAOhVKAovoNkn7v2os2QhkK1A-1nw5GmGxPFIRIN63rdl_ucw7SFDtAKfXHq24XpmicjGTz-UA4Z0ec70opumo4apOqENC84064mCh21ODMI5stVImrWjWdMrsylJjAe8DpB0SiNbbYZeUdSHXY1XyyqR-WCVh58etJhusilb4HYS-ruAUVXspgzW8XF8Nehnplgrk0eVx1KK_Le6EYqKkqw0mGOlHd1T1Ft7bpjMn8VFwJ5LriDC9IGw-PFT6aTIHnR6Aw3-fAyGj0SK35zJcaxjYw9yNhJFGQvCow-zsyDxKcbvZisXQ; cookiesu=491698238770530; u=491698238770530; device_id=f19daf13250cbd45bc5ea0d7b699854b; Hm_lvt_1db88642e346389874251b5a1eded6e3=1698238794; s=aq11dck1v6; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1698239089'my_headers = {'User-Agent': 'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?type=sha&order_by=percent&order=desc&size=10&page=1','Referer': 'https://xueqiu.com/hq','Cookie': cookie}
resp=requests.get(url,headers=my_headers)print(resp.text)
3.请求参数
(1)get请求以及查询参数
import requestsurl = 'https://m.douban.com/rexxar/api/v2/movie/recommend'my_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/explore'
}my_params = {'start': 0,'count': 60,'tags': '爱情'
}resp = requests.get(url, headers=my_headers, params=my_params)
# print(resp.json())with open('douban1.json','w') as f:f.write(resp.text)(2)post请求以及请求体参数
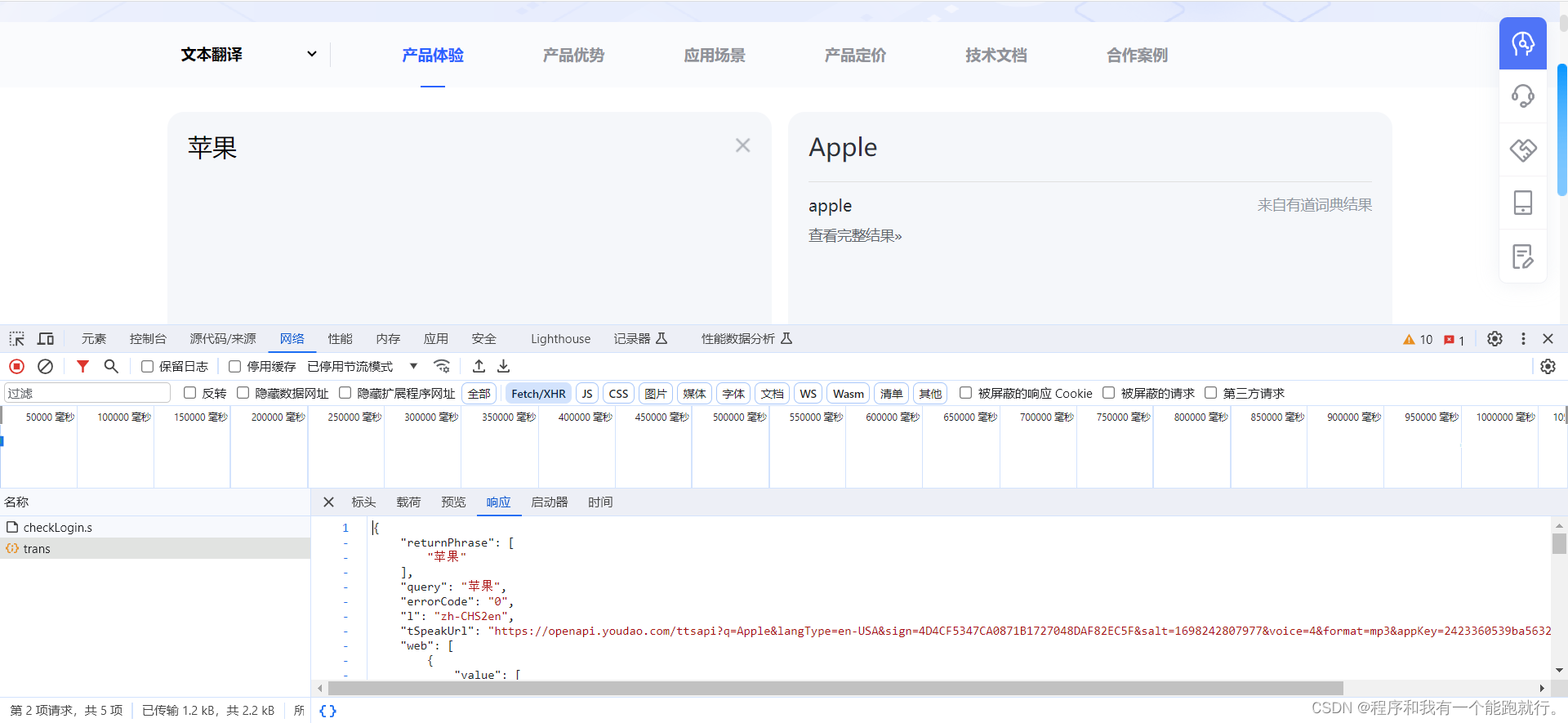
import requestsurl='https://aidemo.youdao.com/trans'my_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36','Referer': 'https://ai.youdao.com/'
}while 1:wd = input('请输入翻译的内容>>>')my_data={'q': wd,'from': 'Auto','to': 'Auto'}resp = requests.post(url,headers=my_headers,data=my_data)print(resp.json().get('translation')[0])
4.爬虫图片和视频
(1)直接爬取媒体数据流
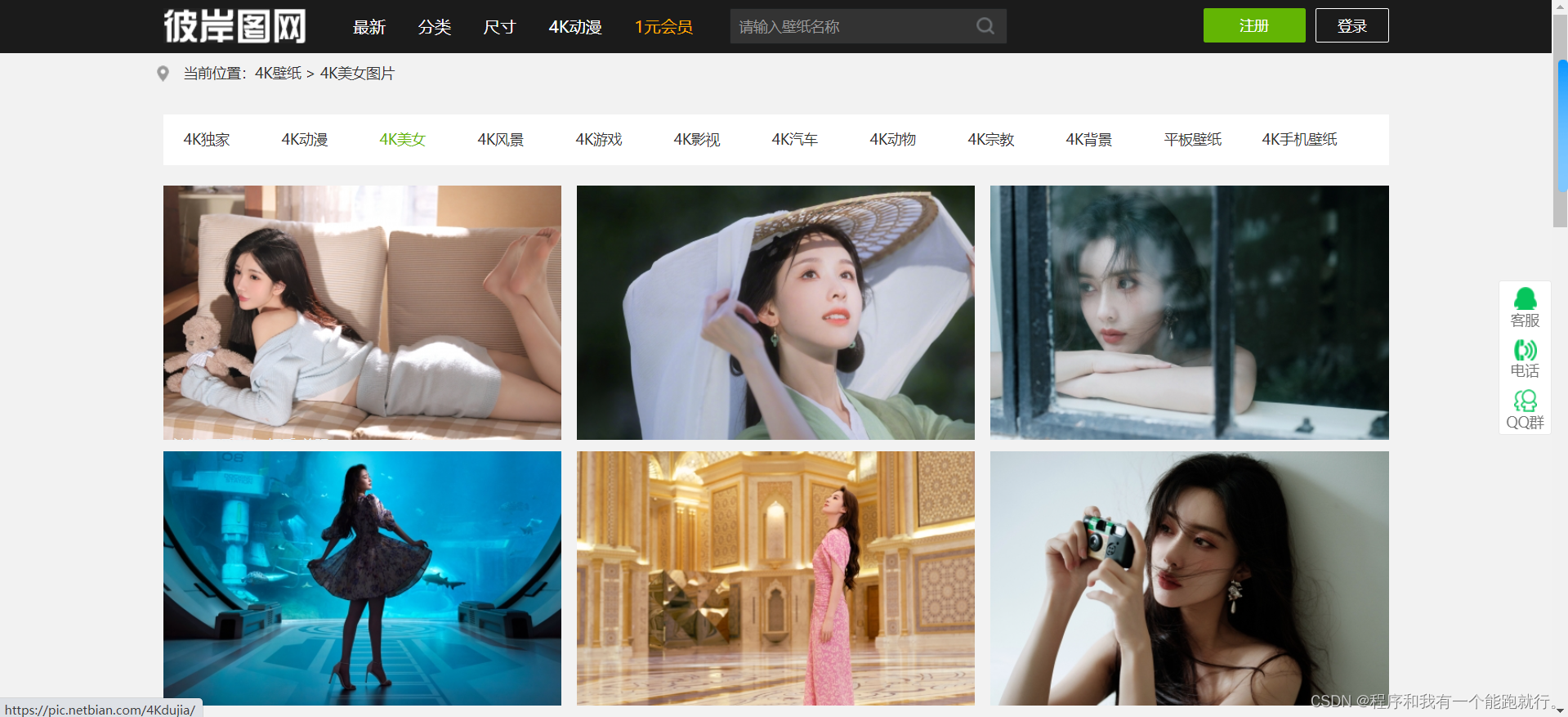
import requestsresp=requests.get('https://pic.netbian.com/uploads/allimg/231012/200615-1697112375eae9.jpg')print(resp.content) # 响应字节串
# print(resp.text) # 响应字符串# 写文件
with open('meinv.png','wb') as f:f.write(resp.content)
5.打码平台
获取验证码
先清空一下数据包
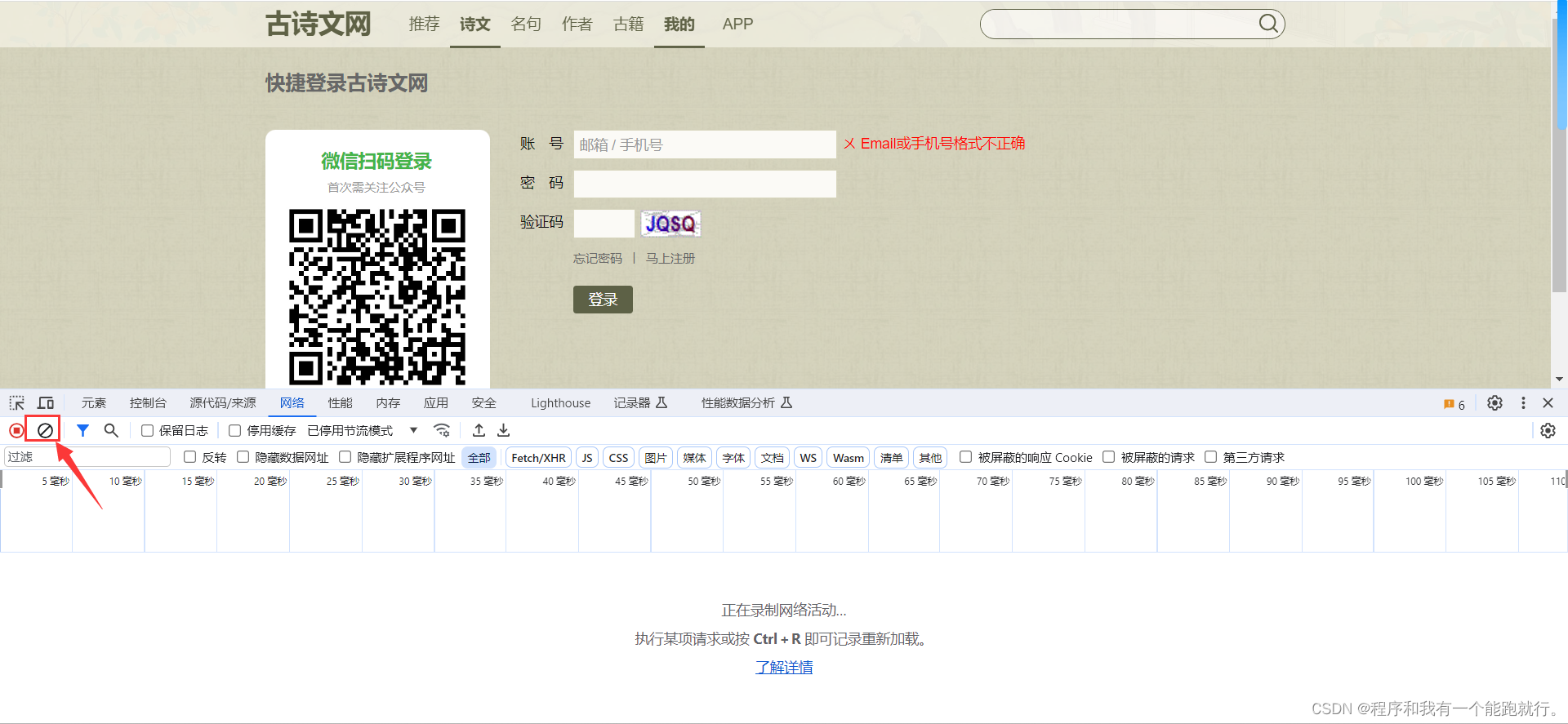
点击刷新验证码,找到携带验证码图片的数据包(可以预览一下)
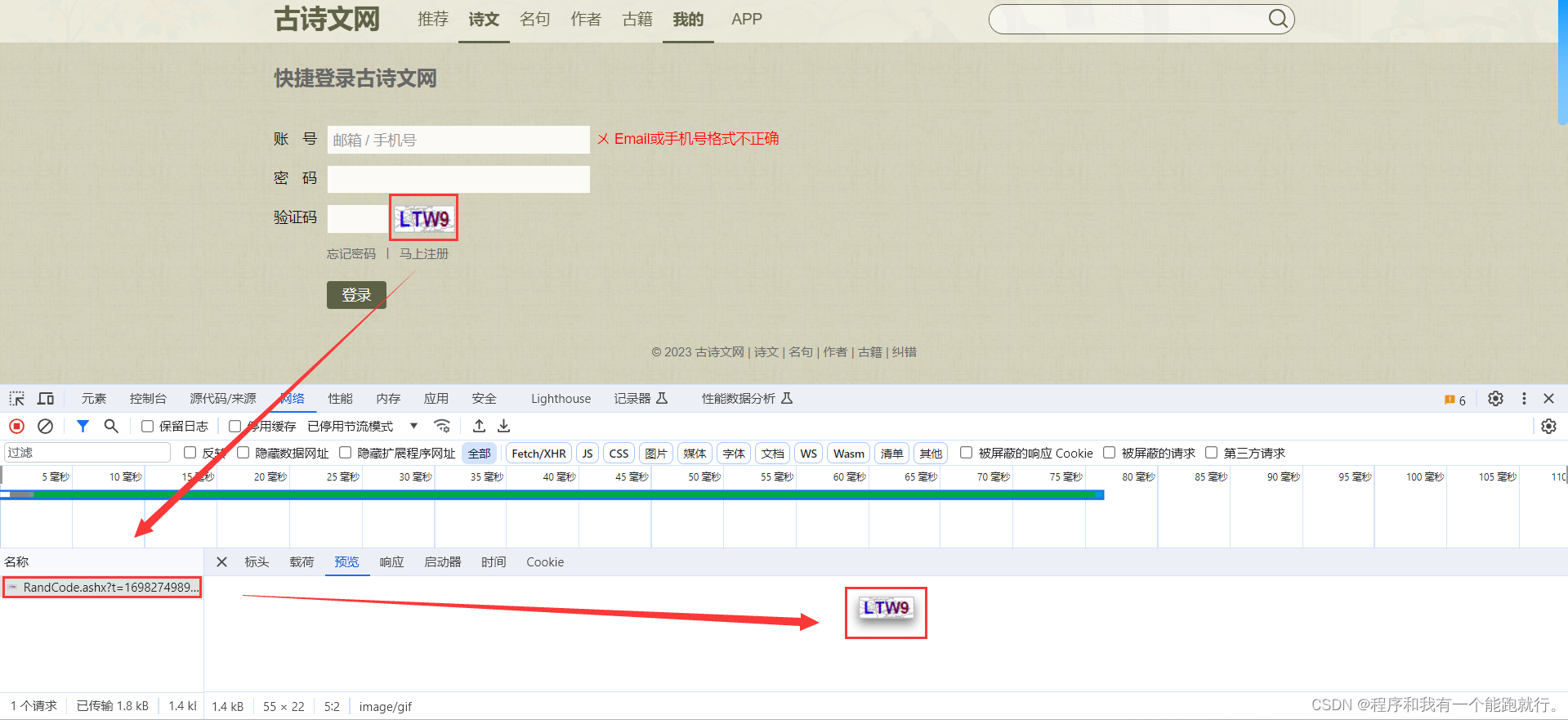
试一下请求网址能否搜索到验证码,并刷新页面,看一下是否每次刷新验证码都会随之改变

编写爬虫代码,下载验证码
import requestsurl = 'https://so.gushiwen.cn/RandCode.ashx?t=1698274193608?t=1698274440797?t=1698274448532'resp = requests.get(url)with open('code.png', 'wb') as f:f.write(resp.content)看一下是否成功下载,并重新执行代码,看一下验证码是否刷新
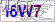
打码平台:图鉴
点击开发文档
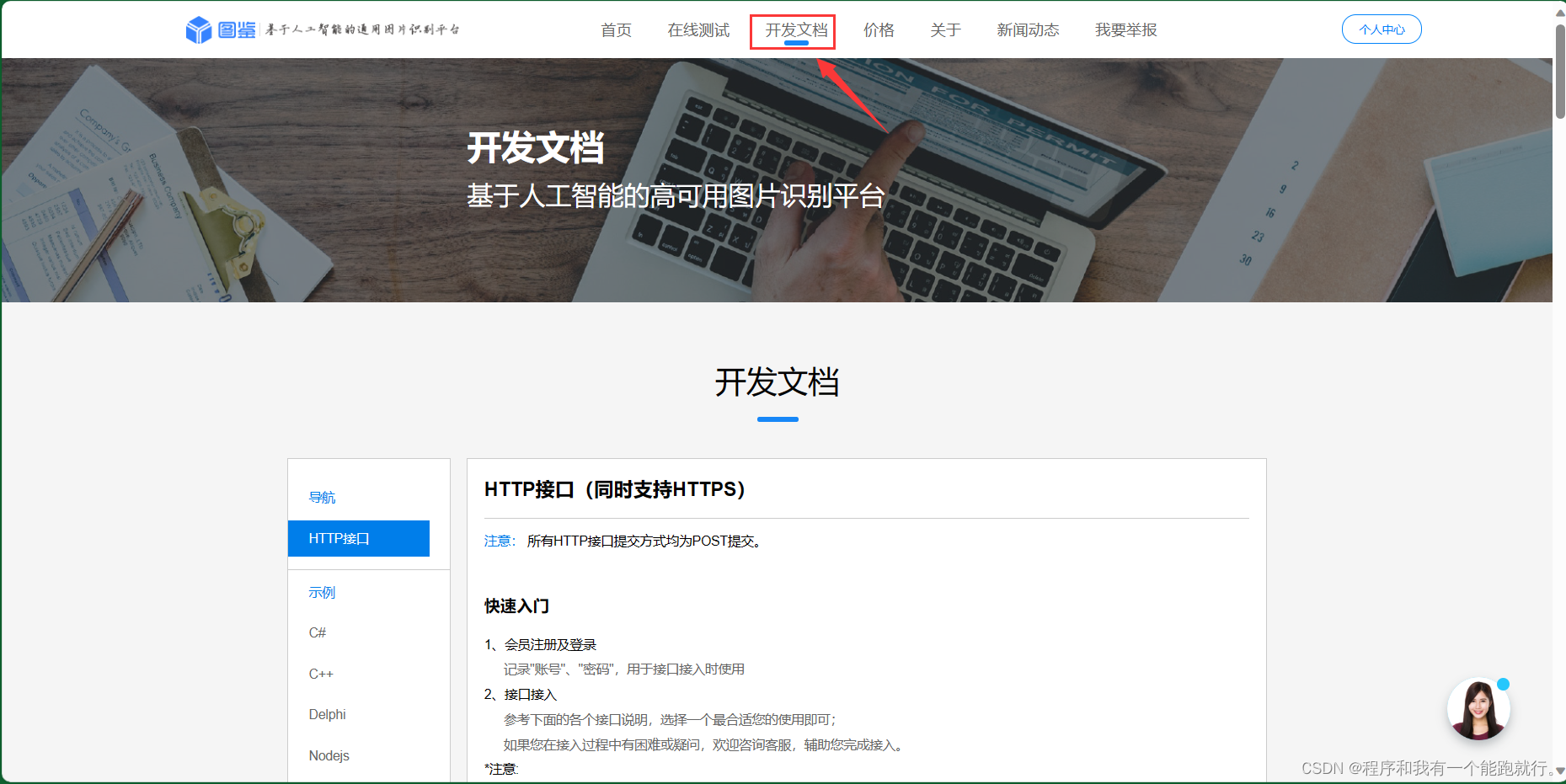
选择Python
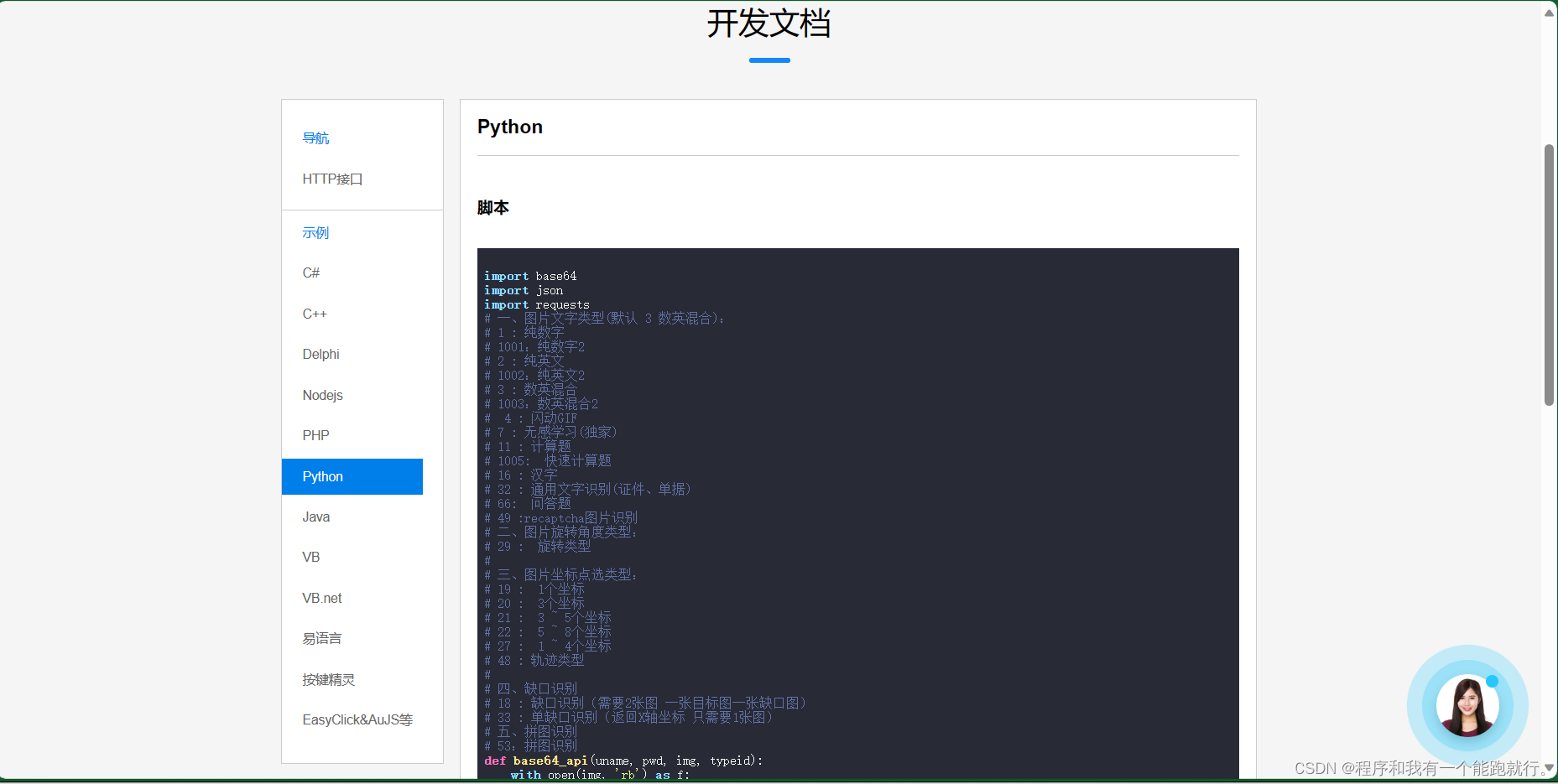
分析一下脚本内容
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别return result["message"]return ""if __name__ == "__main__":img_path = "C:/Users/Administrator/Desktop/file.jpg"result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3)print(result)修改脚本参数
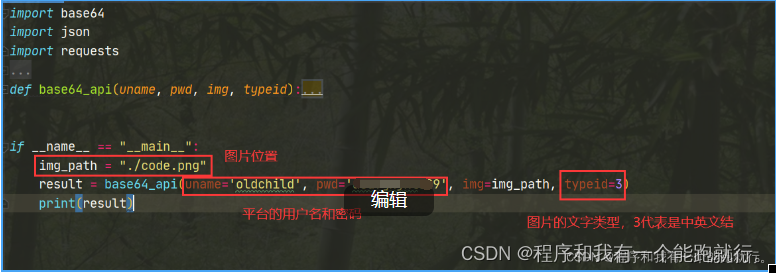
运行程序,对比运行结果和图片验证码是否一样

6.今日作业
1.模拟登陆(破解验证码)
要求:
- 目标网站:古诗文网
2.抖音下载一个视频
要求:
- 目标网站:抖音
- 用户:刘浩存
先清空一下数据包
慢慢滑动下拉框,找到此种数据包
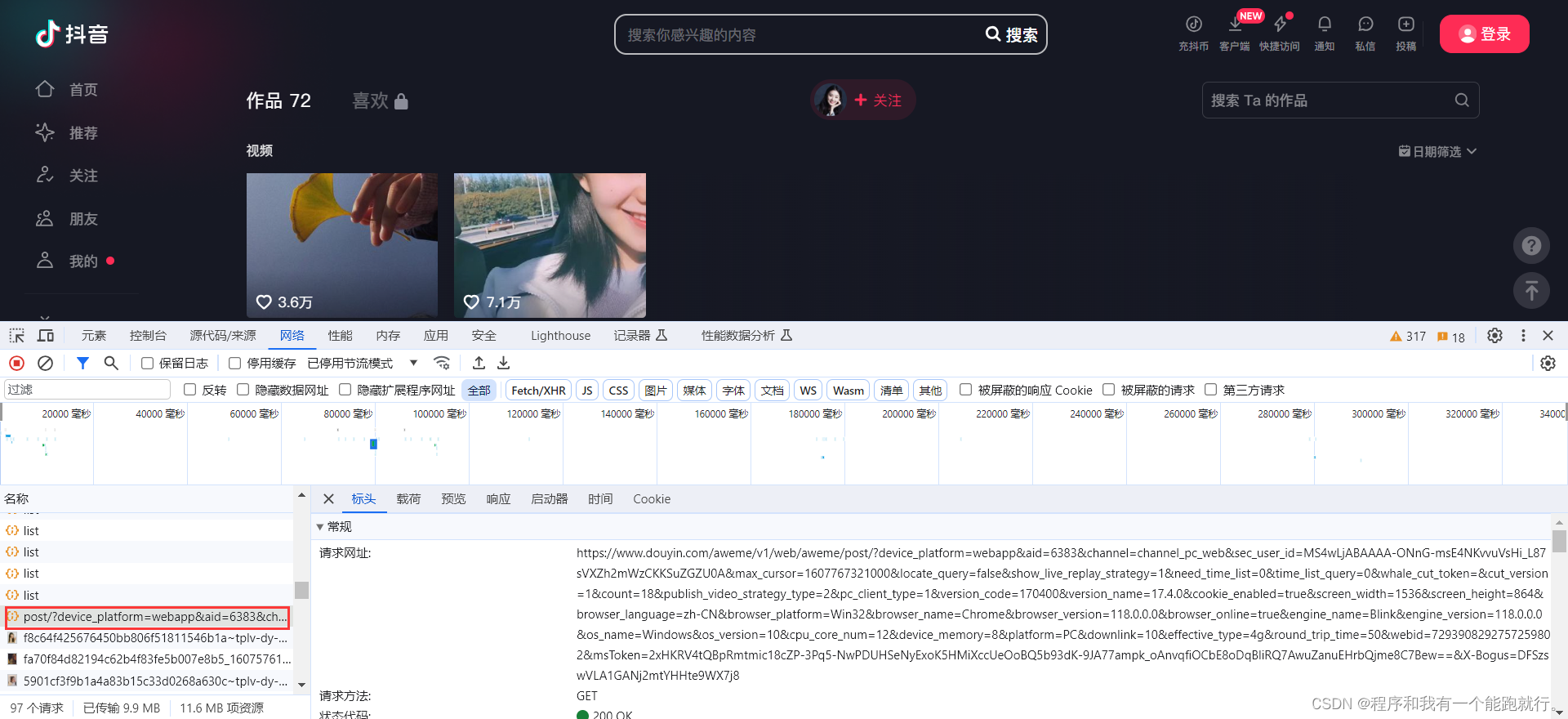
也可以筛选一下
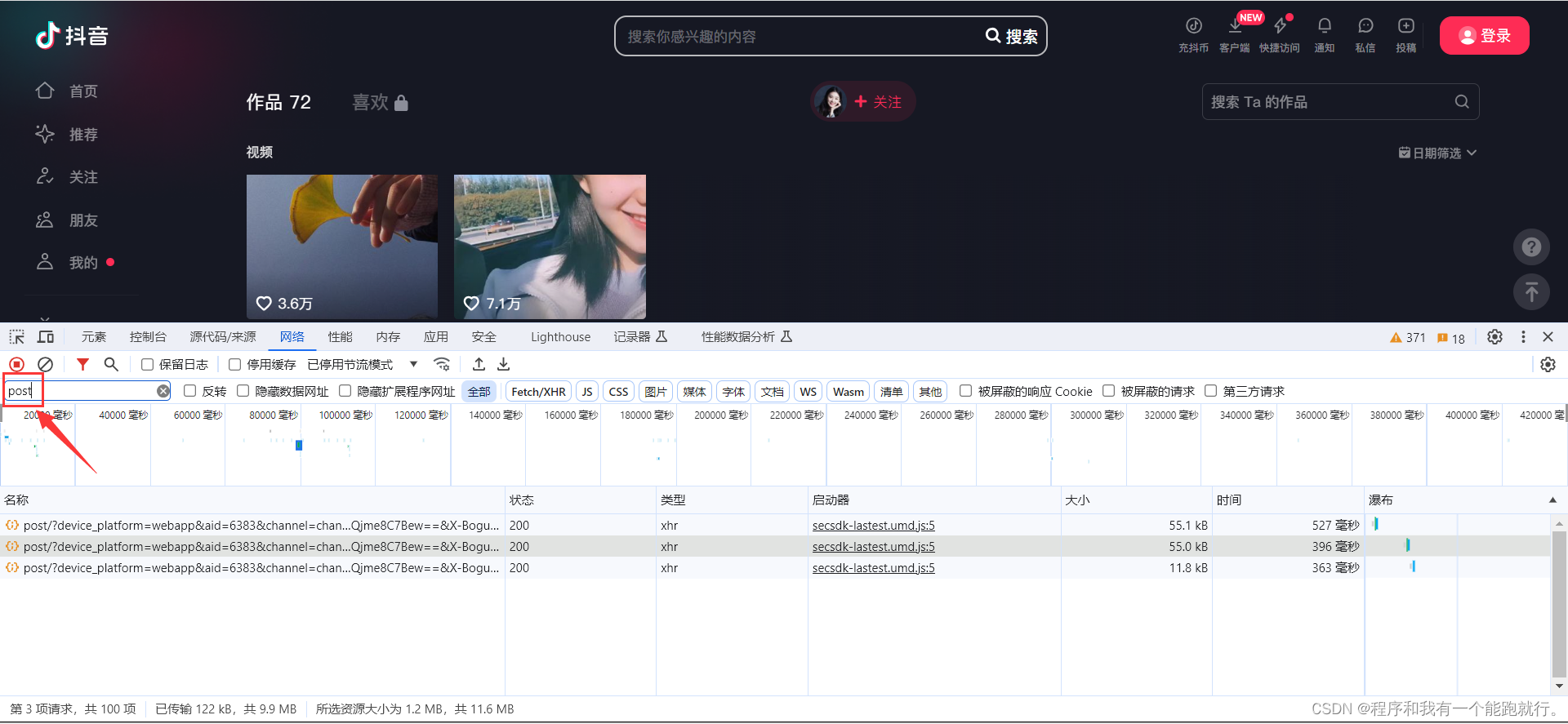
找到图片的绝对网址
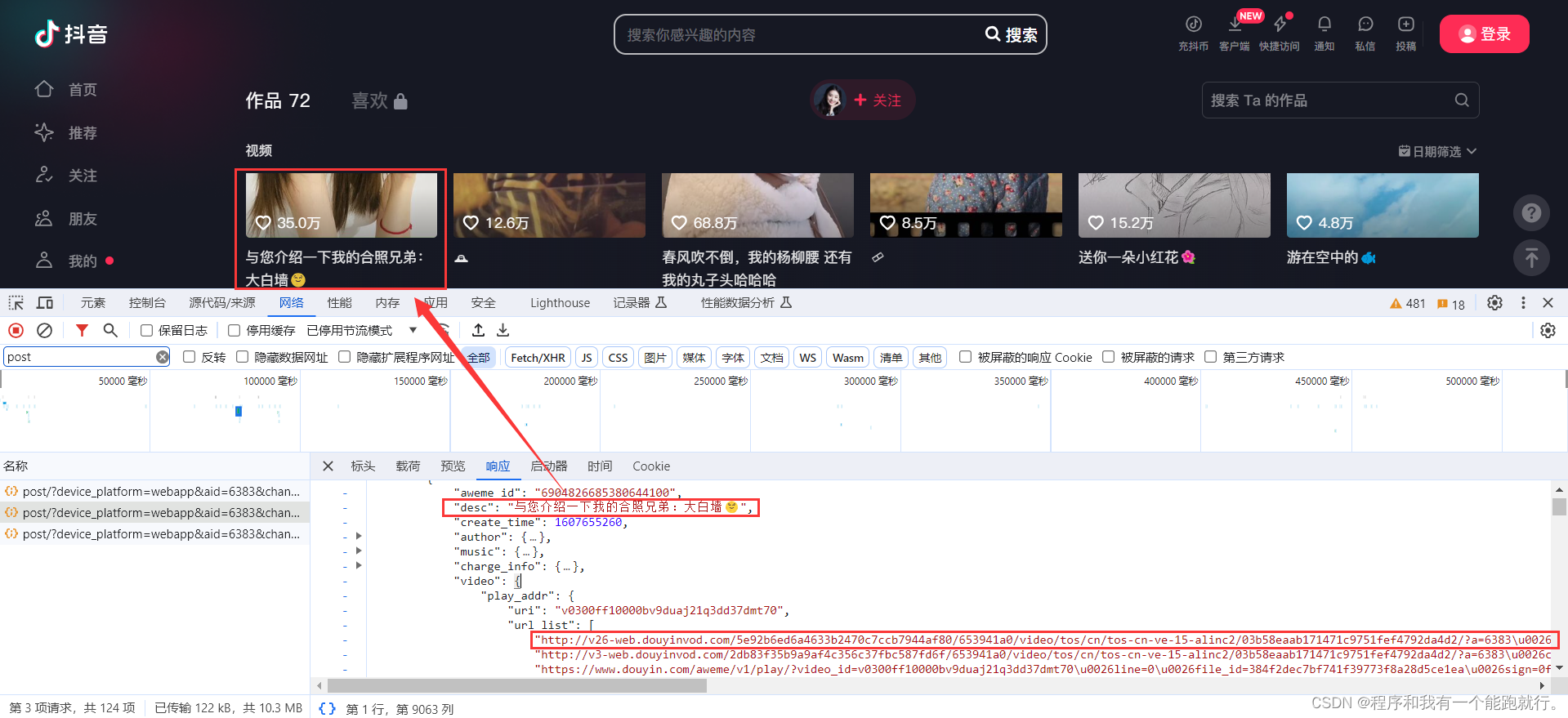
试一下能否播放

编写爬虫代码,下载视频
import requestsresp=requests.get('http://v26-web.douyinvod.com/5e92b6ed6a4633b2470c7ccb7944af80/653941a0/video/tos/cn/tos-cn-ve-15-alinc2/03b58eaab171471c9751fef4792da4d2/?a=6383\u0026ch=10010\u0026cr=3\u0026dr=0\u0026lr=all\u0026cd=0%7C0%7C0%7C3\u0026cv=1\u0026br=936\u0026bt=936\u0026cs=0\u0026ds=4\u0026ft=bvTKJbQQqUisf_0ZPo0OW_EklpPiXXb0rFVJEFNiYRCPD-I\u0026mime_type=video_mp4\u0026qs=0\u0026rc=ZDRmZzU7Njo2NDplZmdpO0BpM3dnNmd0NWRneTMzNGkzM0BiYjI1XmM0NmMxYzRiLzEwYSM0ajRhMC5ncjZfLS1jLTBzcw%3D%3D\u0026btag=e00010000\u0026dy_q=1698247554\u0026l=20231025232554EFBDF4DD234ADE2761D5')with open('liuhaocun.mp4','wb') as f:f.write(resp.content)检查是否下载成功
liuhaocun.mp4
本文所涉及的他人内容包括但不限于文字、图片、音频、视频等,来源于各个渠道和资源,并非本文作者原创。在使用他人内容时,本文作者已经尽力确保遵循适用的版权法律和相关规定,并尽力寻找和确认素材的合法来源。在此声明中的他人内容的使用,仅出于分享和传播信息的目的,并不代表本文作者对其内容的观点或立场进行支持或认可。本文作者对他人内容的准确性、完整性或时效性不承担责任,并且不保证这些素材没有侵犯任何第三方的知识产权。
素材来源:
- 路飞学城
- 等