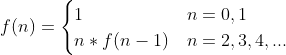随着信息时代的迅猛发展,每天有无数文本、声音、图片和视频不断涌入互联网。如何从海量数据中提炼有意义信息成为学术界和工业界迫切需要解决的问题。在此背景下,自然语言处理(NLP)应运而生,成为人工智能领域最为活跃的研究领域之一。
NLP的目标是让计算机理解和生成人类语言,从而实现与人自然交流。这包括了基础的语言理解任务,如词性标注、句法分析,以及更复杂的应用,如情感分析、机器翻译和语音识别等。为了让机器更好地理解人类语言,研究者们开发了大量的算法和模型。然而,无论算法多么先进,如果没有大规模、高质量的数据支持,其效果都会受限。这就是为什么数据集在NLP领域如此至关重要。
数据集是NLP研究的基石,它们为研究者提供了评估和验证算法性能的基准,也是训练机器学习模型的关键资源。随着NLP领域的不断进展,涌现出大量数据集,涵盖了从基础到前沿的各种NLP任务。选择适当的数据集对于研究的成功至关重要。
在本文中,我们将详细介绍多种当前热门的NLP数据集。这些数据集包括文本分类、命名实体识别、机器翻译等各种任务。我们希望通过这篇文章,让您全面了解NLP数据集,以便为您的研究或项目选择合适的数据集提供指导。
一
数据集评估维度及其重要性

随着NLP领域的不断发展,出现了众多开源数据集,以支持各种研究任务。在选择和使用这些数据集时,了解它们的各种关键维度至关重要,这些维度不仅帮助我们理解数据集的特点和用途,还为我们提供了评估其适用性和质量的依据。以下是一些关键维度:
1
首先,我们应该了解数据集的名称和发布者。数据集的名称是其独特标识,有助于查找和引用。同时,了解数据集的发布者有助于评估数据集的可靠性和权威性。通常,来自知名机构或研究组的数据集更具可信度和认可度。
其次,我们需要了解数据集的内容、特点以及其对行业的影响。根据数据集的内容和特点,我们可以确定数据集适用的NLP任务类型,并了解数据集的设计目标和要求。这有助于判断数据集是否适合特定的研究或应用,以满足特定需求和挑战。此外,了解数据集的影响力可以告诉我们它在某些任务或领域中的广泛使用程度以及已被验证有效的程度。
2
3
此外,数据集的数据量和数据来源也是关键信息。数据量是评估数据集规模和深度的关键因素。大规模的数据集通常更适合用于训练复杂的模型,而小规模的数据集可能更适合特定任务或快速实验。了解数据的来源,即数据是如何生成和收集的,有助于评估其可靠性和代表性。选择来源可靠、具有代表性的数据集可以帮助避免偏见和误差。
综合而言,深入了解数据集的各个关键维度对于评估其适用性、可靠性和质量至关重要。选择合适的数据集是确保研究或项目成功的基础,因此我们应该花时间仔细研究并理解这些维度,以做出明智的决策。
二
NLP任务分类与数据集推荐的你

自然语言处理领域包含了多个子领域和任务,为了帮助研究者和开发者更便捷地找到适用于他们需求的数据集,我们将根据不同的NLP任务进行分类,并为每个任务推荐相关的数据集。
01
问答任务
问答任务主要关注模型对特定问题的答案生成或选择能力。
1.1 二值问题回答
这是一个特定类型的问题回答任务,主要关注于二值(是/否)答案。
推荐数据集:
BoolQ:由Google AI发布,是一个二值问题(是或否的问题)及其答案,包含约超过9k条数据,来源于从Wikipedia抽取。
下载地址(https://huggingface.co/datasets/boolq)
1.2 对话式问答
这是一个涉及对话上下文的问题回答任务。
推荐数据集:
CoQA:由斯坦福大学发布,是一个对话式的问答数据集,包含约12.7w+个问题答案对,来源于不同的来源,如维基百科、小说、新闻等。
下载地址(https://stanfordnlp.github.io/coqa/)
1.3 开放领域的问答
这个任务要求模型回答开放领域的问题。
推荐数据集:
WebQA:由百度发布,是一个开放领域的问答数据集,包含约42k个问题和566k个问题相关文本条数据,来源于基于Web的问答对。
下载地址(https://huggingface.co/datasets/suolyer/webqa)
TriviaQA:由University of Washington发布,是一个开放领域的问题和答案对,包含约65w条数据,来源于TriviaQA网站和其他Trivia游戏。
下载地址(https://huggingface.co/datasets/trivia_qa)
1.4 信息寻求对话
这个任务涉及与模型进行对话,以获得特定信息。
推荐数据集:
QuAC:由Allen Institute of Artificial Intelligence & DARPA CwC program发布,是一个模拟学生与教师之间的信息寻求对话,包含约1.4w多对话条数据,来源于隐藏的维基百科文本。
下载地址(https://huggingface.co/datasets/quac)
02
语言理解
2.1 预测段落最后一个单词
本任务用于评估模型对文本生成和连续性的理解。
推荐数据集:
LAMBADA:由University of Amsterdam&University of Trento发布,是一个预测文本的下一个词,包含约12,684条数据,来源于书籍和其他文学作品。
下载地址(https://huggingface.co/datasets/lambada/tree/main)
2.2 故事结束预测
这个任务需要模型预测故事的可能结束。
推荐数据集:
StoryCloze:由University of Rochester发布,是一个预测故事的正确结尾,包含约超过3,700条数据,来源于故事文本。
下载地址(https://huggingface.co/datasets/story_cloze)
2.3 阅读理解
阅读理解任务要求模型从给定的文本中提取或推断信息。
推荐数据集:
RACE:由CMU发布,是一个英语阅读理解数据集,包含约超过2.8w篇文章和近10w个问题,来源于中国的英语考试。
下载地址(https://www.cs.cmu.edu/~glai1/data/race/)
RACE-Middle:由CMU发布,是一个初中级阅读理解题目,包含约25,421条数据,来源于中国中学生英语考试。
下载地址(https://huggingface.co/datasets/race)
RACE-High:由CMU发布,是一个高中级阅读理解题目,包含约62,445条数据,来源于中国中学生英语考试。
下载地址(https://huggingface.co/datasets/race)
SQUADv2:由斯坦福大学发布,是一个阅读理解任务。该数据集包含约15w+个问题答案对,还有一些没有答案的问题。数据来源是维基百科,由众包人员对抗生成。
下载地址(https://huggingface.co/datasets/squad_v2)
CMRC2018:由哈工大讯飞联合实验室发布,是一个中文阅读理解任务,包含约近2w个真实问题条数据,来源于人类专家在维基百科的段落中注释。
下载地址(https://github.com/ymcui/cmrc2018)
2.4 多模态语言理解
这个任务关注于结合多种模式(如文本、图像和声音)来理解语言。
推荐数据集:
MMLU:由UC Berkele&Columbia University&Uchicago&UIUC发布,是一个多模态语言理解数据集,包含约5,822,552条数据,来源于研究生和本科生从免费的在线来源手动收集。包括研究生学历考试和美国医学执照考试等考试的练习题、为本科生课程设计的问题和为牛津大学出版社书籍读者设计的问题。
下载地址(https://huggingface.co/datasets/cais/mmlu)
03
推理模块
3.1常识推理
常识推理是测试模型对常识和逻辑的理解能力的任务。这个任务要求模型具备尝试推理能力,理解和推理因果关系。
推荐数据集:
HellaSwag:由University of Washington发布,是一个常识推理数据集,要求模型预测句子的正确结尾,包含约超过70,000条数据,来源于来自各种源,如教学视频、故事,但由研究人员进行修改。
下载地址(https://huggingface.co/datasets/hellaswag)
WinoGrande:由University of Washington发布,是一个常识推理挑战,基于Winograd模式,包含约44,000条数据,来源于人工构建。
下载地址(https://huggingface.co/datasets/winogrande/tree/main)
COPA:由Indiana University & University of Southern California发布,是一个评估模型在开放领域常识因果推理的进展,包含约1000个选择问题条数据,来源于人工设计。
下载地址(https://people.ict.usc.edu/~gordon/copa.html)
CSQA:由CommonsenseQA团队发布,是一个需要常识知识来回答的问答数据集,包含约20,000篇对话,大约1.6M个QA对,来源于注释员相互交流生成。
下载地址(https://amritasaha1812.github.io/CSQA/download/)
3.2 自然语言推理
这个任务要求模型根据给定的前提推断出结论。
推荐数据集:
ANLI:由Facebook AI发布,是一个人工生成的自然语言推理数据集,包含约超过120,000条数据,来源于众包平台。
下载地址(https://huggingface.co/datasets/anli)
XNLI:由Facebook AI发布,是一个多语言自然语言推理数据集,包含约超过390,000条数据,来源于15种语言的翻译。
下载地址(https://huggingface.co/datasets/xnli)
StrategyQA:由Tel Aviv University、Allen Institute for AI & University of Pennsylvania发布,是一个需要对多个证据进行推理的问答数据集,包含约约2700样例,来源于workers生成。
下载地址(https://storage.googleapis.com/ai2i/strategyqa/data/strategyqa_dataset.zip)
GLUE的MNLI、QNLI和 WNLI子数据集:GLUE是由纽约大学和华盛顿大学发布,是一个一组用于评估和分析多种NLP任务的数据集,包含约一共多个任务,不同任务有不同的数据量条数据,来源于各种NLP数据集的集合。
下载地址(https://gluebenchmark.com/)
3.3 深度推理
这个任务要求模型进行更深入的推理以回答问题。
推荐数据集:
DROP:由Allen Institute for Artificial Intelligence发布,是一个需要深入推理的问答数据集,包含约77,409个问题答案对,来源于从维基百科中选择的段落。
下载地址(https://opendatalab.com/DROP/download)
3.4 数学推理
数学推理任务测试模型在数学问题上的推理能力。
推荐数据集:
GSM8K:由OpenAI发布,是一个由8.5K高质量的语言多样化的小学数学单词问题组成的数据集,包含约8500个问题条数据,来源于人类创造。
下载地址(https://github.com/openai/grade-school-math)
MATH:由UC Berkeley和UChicago发布,是一个初级代数、代数、计数与概率、数论与微积分等数学题,包含约12500道数学题条数据,来源于美国中学数学竞赛试题。
下载地址(https://huggingface.co/datasets/math_dataset)
Math23k:由Tencent AI Lab发布,是一个数学问题解决数据集,包含约约23,000个问题条数据,来源于从中文网站收集的数学题。
下载地址(https://ai.tencent.com/ailab/nlp/dialogue/datasets/Math_data.zip)
3.5 科学推理
科学推理任务要求模型对科学概念和事实进行推理。
推荐数据集:
ARC-Challenge:由AI2发布,是一个科学问题及其答案,需要深入推理,包含约2590条数据,来源于学科教育资源。
下载地址(https://huggingface.co/datasets/vietgpt/ARC-Challenge_en)
ARC:由AI2发布,是一个数据集分为简单和挑战两部分,包含约7787个问题,来源于学生科学挑战中的问题。
下载地址(https://opendatalab.com/ARC/download)
PIQA:由University of Washington&AI2发布,是一个针对物理互动的问题回答,包含约超过16,000条数据,来源于众包产生。
下载地址(https://huggingface.co/datasets/piqa/tree/main)
04
文本生成
文本生成任务是指让机器自动产生连贯、有意义的文本,通常基于给定的上下文或提示。代码生成也属于此列。
推荐数据集:
Wikitext103: 由Salesforce研究发布,是一个包含100多万的维基百科文章令牌,包含约103M令牌条数据,来源于维基百科的顶级文章。
下载地址(https://huggingface.co/datasets/wikitext)
PG19: 由DeepMind发布,是一个古腾堡书籍中1919年前出版制品集合,包含约28752篇文章条数据,来源于项目古腾堡。
下载地址(https://huggingface.co/datasets/pg19)
C4: 由DeepMind发布,是一个清洁的、多语言的数据集,包含约数百万篇文章,数十亿的令牌条数据,来源于网络爬取数据。
下载地址(https://huggingface.co/datasets/c4)
HumanEval:由OpenAI、Anthropic AI发布,是一个评估AI模型的问题解决能力,包含约164个手写编程问题,平均每个问题有7.7个测试条数据,来源于Openai员工手写。
下载地址(https://huggingface.co/datasets/openai_humaneval)
05
基础任务类
5.1句子对比
这个任务关注于比较两个句子的语义相似性或差异性。
推荐数据集:
PAWS-X:由Google Research发布,是一个多语言对比词序数据集,包含约49,401条数据,来源于Wikipedia和其他源的翻译。
下载地址(https://huggingface.co/datasets/paws-x)
LCQMC:由哈尔滨工业大学发布,是一个判断中文句子对是否具有相同的意图,包含约238,766个句子对条数据,来源于社交媒体平台、问答网站等。
下载地址(https://opendatalab.com/LCQMC/download)
5.2 词义消歧
这个任务关注于确定一个词在特定上下文中的正确含义。
推荐数据集:
WiC:由卡迪夫大学发布,是一个词义消歧的数据集,判断两个句子中的同一个词是否有相同的意思,包含约5428个问题条数据,来源于多语言资源。
下载地址(https://pilehvar.github.io/wic/)
5.3 代词消除歧义
这个任务关注于正确解决代词的歧义。
推荐数据集:
WSC:由Winograd Schema Challenge组织发布,是一个代词消除歧义,包含约285个问题条数据,来源于专家编写。
下载地址(https://huggingface.co/datasets/winograd_wsc)
5.4 文本蕴含
这个任务要求模型确定一个文本是否蕴含另一个文本。
推荐数据集:
GLUE的RTE子集
5.5 情感分析
情感分析任务旨在确定文本的情感倾向。
推荐数据集:
GLUE的SST-2 子集
06
其他
6.1 真实性评估
这个任务用于评估生成的回答的真实性。
推荐数据集:
Truthful-QA: 由University of Oxford&Open AI发布,是一个评估生成回答的真实性的数据集,包含约817条数据,来源于作者自编。下载地址(https://huggingface.co/datasets/truthful_qa)
6.2 评估刻板印象
这个任务旨在评估模型是否持有或传递某些刻板印象。
推荐数据集:
ETHOS:由Aristotle University of Thessaloniki发布,是一个包含刻板印象的语句及未包含的语句,包含约二分类任务有998条评论,多分类有433条评论条数据,来源于YouTube和Reddit评论。
下载地址(https://huggingface.co/datasets/ethos)
StereoSet:由MIT、Intel AI、Facebook CIFAR AI Chair and McGill University发布,是一个包含刻板印象的语句及未包含的语句,包含约17000个句子条数据,来源于不同的文本来源。
下载地址(https://huggingface.co/datasets/stereoset)
6.3 多任务评估
多任务评估关注于同时评估模型在多个任务上的性能。
推荐数据集:
SuperGLUE:由AI2 & University of Washington发布,是一个一组NLP任务的基准,是GLUE的扩展,包含约不同任务有不同数据量条数据,来源于多个NLP数据集的集合。
下载地址(https://huggingface.co/datasets/super_glue/tree/main)
BIG-bench:BIG-bench由Google发布,是一个大规模语言模型评估基准。该数据集包含多个子任务,但总数不详。数据来源于不同的子任务来源。
下载地址(https://github.com/google/BIG-bench)
以上是基于不同NLP任务的数据集推荐。每个数据集都有其特定的特点和用途,研究者和开发者应根据自己的需求和研究目标选择合适的数据集。同时,随着NLP领域的不断进展,可能会有更多的数据集和任务出现,我们应持续关注并不断更新我们的知识库。
三
结论

数据集在自然语言处理领域中起到了至关重要的作用。无论是为了训练强大的模型,还是为了验证新的算法和策略,数据集都是不可或缺的资源。在本文中,我们介绍了43个NLP数据集,涵盖了从常识推理到问题回答的各种任务。每个数据集都有其独特的特点和应用场景,为研究者提供了丰富的选择。
但要注意,选择数据集不仅仅是根据其大小或者知名度。重要的是要确保数据集与研究或项目的目标相匹配。此外,数据集的质量、多样性和代表性也是需要考虑的关键因素。一个好的数据集应该能够为模型提供全面、均衡和有代表性的训练数据。
随着NLP领域的不断进展,我们预期未来还会有更多的数据集问世。而随着技术的进步,数据集的规模、质量和多样性也可能会得到进一步的提高。因此,研究者和开发者应始终保持警觉,关注最新的数据集和研究动态,确保他们的工作始终处于行业的前沿。
最后,我们鼓励读者深入探索上文提到的数据集,并挑战更多的NLP任务。希望这篇文章能为您提供一些有用的参考和启示,助您在NLP领域取得更大的成功。

欢迎关注微软 智汇AI 官方账号
一手资讯抢先了解




点击“阅读原文” | 了解更多 AI 赋能案例