文章目录
- 图像增强
- 图像色彩增强
- 问题
- 可视化比较
- 难点
- 色彩空间大,难以准确表征?
- 不同场景差异大,难以自适应?
- 计算量大,但应用场景往往实时性要求高?
- 方法
- 传统方法
- 深度学习
- 逐像素预测
- 3D LUT
- 模仿ISP
- 个人思考
- 批判性看待论文工作
- 速度快
- 效果好
- 大模型
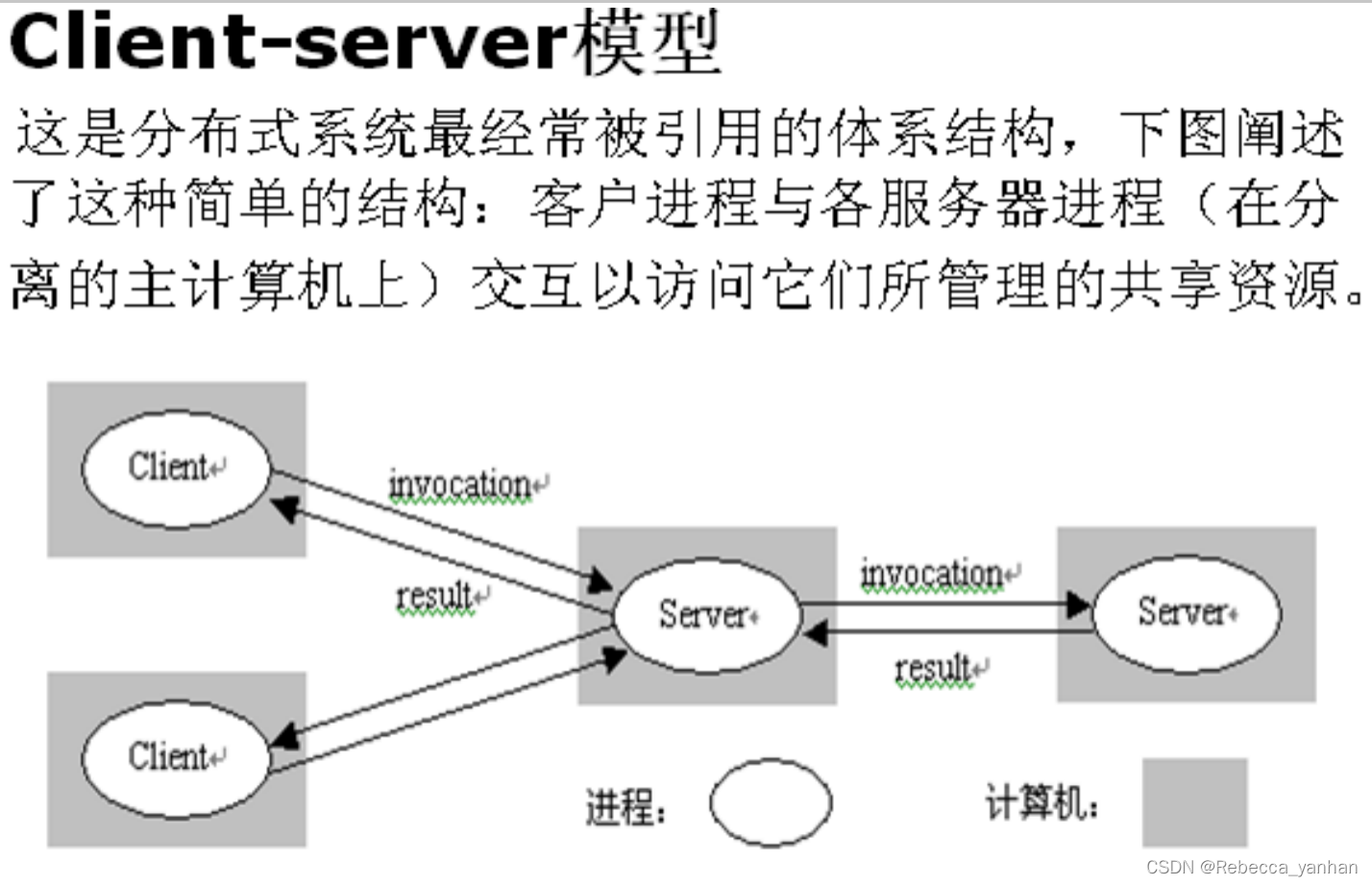
图像增强
图像增强是一个非常大的领域,包含去噪,去雾,超分辨率,去模糊,低光照增强,重建等都属于
图像增强!
但我要讨论的方向更具体是:图像色彩增强,区别于低光照增强和水下图像增强!
图像色彩增强
图像色彩增强针对图像色彩进行调整优化,有的文章叫做——图像润色(image retouching),无法去噪,无法在极低光照情况恢复(这种低光照恢复往往伴随着大量噪声,因为颜色已经完全丢失,或大部分丢失,难度更大)。
图像色彩增强的主要评价数据集是:MIT5K,HDR++和PPR10K,有的论文中说是image retouching,也有论文说image enhancement,本质都是对颜色空间的调整优化,使其更符合人类视觉感知!
其中MIT5K数据集是包含低光照处理的,训练和测试图光照降低,有A/B/C/D/E五个专家调色,一般方法都使用C标签进行训练和比较;HDR也是训练图片亮度和色彩都降低;
PPR10K主要是针对人像精修图片,进行精细化的色彩、亮度和曝光的调整,同时数据集中加入了人像的mask用于指导优化训练。
问题
本质上:模型优化调整图片的颜色,亮度和曝光,能让图片和专家的调色结果更加一致!
图像色彩增强还有一个额外的任务,图像色调调整image tone,色调的调整一般使用16bit图片进行训练和XYZ空间评价;
所以训练图片的格式也有区别:润色任务使用sRGB图像格式训练,主要专注色彩和亮度调整,使用C专家标记和PSNR,SSIM,Eab进行评价;色调调色任务使用16bitS的图片进行训练;
可视化比较

上图分别是sRGB, XYZ空间和gt图片。
原始图像的色彩和亮度都很低,人们的视觉主观感受很差;
中间这张的色调也不好,整体呈现灰蒙蒙和青色,影响对图像中物体的观感!
最右边这张专家标记图片的亮度、色彩和色调都很棒,能清楚看到山丘、草堆,沙石和天空,主观感受也更舒适,用PSNR和SSIM评价结果,前两者的结果很差!
难点
色彩空间大,难以准确表征?
色彩空间是一个庞大的空间数量,不同颜色组合成255x255x255的颜色空间,如果进行逐一统计和建立映射关系,复杂度非常高。
本质上,图像色彩映射是一个复杂度高、非线性和结果多样性的过程!需要模型能够准确映射颜色空间高维度和大数量的颜色关系,构建出高效表征的映射关系。
不同场景差异大,难以自适应?
对于不同场景图片中,同一个颜色会有多种映射结果,这也给色彩映射带来极大的难度和挑战!
不仅要求模型能够适应不同场景的差异映射关系,还要适应同一色彩的不同场景自适应映射;
色彩映射的结果需要自然、符合人类视觉机制,这其实是难度非常大的。
计算量大,但应用场景往往实时性要求高?
图像增强根据其方法不同,计算方式也不同,计算量差距较大。
传统的方法直接计算色彩映射矩阵,使用较少的参数实现色彩映射,计算量小;
但深度模型后的GAN生成网络和FCN逐像素预测的网络模型,计算量大,训练复杂,限制了实用性;
基于颜色迁移函数拟合的深度学习,通过预测少量的映射函数,能达到计算量小、效果好!
方法
传统方法
使用线性或者非线性方程拟合颜色映射关系。
最典型的是:曲线色彩映射图,2D lut;
- Color Transfer Using Probabilistic Moving Least Squares
- Example-Based Image Color and Tone Style Enhancement
- Learning Photographic Global Tonal Adjustment with a Database of Input / Output Image Pairs
深度学习
色彩映射方程拟合
zero-DCE(比较经典的方法,多级拟合和2D曲线映射)
CSNet——CSRNet-Conditional Sequential Modulation for Efficient Global image Retouching
逐像素预测
GAN-based
- 《DPE-Deep Photo Enhancer Unpaired Learning for Image Enhancement from Photographs with GANs》
- 《MIEGAN Mobile Image Enhancement via A Multi-Module Cascade Neural Network》
- 《Unpaired Image Enhancement with Quality-Attention Generative Adversarial Network》
3D LUT
adaptive 3D LUT(最早用3D LUT,效果好速度快,代码可复现)
AdaInt (改进3D LUT的采样间隔,基于Open MM框架,代码无法完全复现, CVPR2023)
SeqLUT (多个3D 和2D 结合,使用模型减枝减少参数,ECCV2023)
4D LUT (提取语义特征,和3D LUT结合,arixv)
模仿ISP
全局参数估计和局部像素映射
You Only Need 90K Parameters to Adapt Light: a Light Weight Transformer for Image Enhancement and Exposure Correction (BMVC2022, 代码中关于MIT5K的论文结果无法复现)
个人思考
批判性看待论文工作
看了不少论文,虽然都生成自己方法效果好,速度快,但实际代码效果并不都是理想的!
阅读论文和代码复现,既要通过经验来判断,也要批判性看待和甄别。
并不是都要追求SOTA,方法思路是合理的、新颖的就很不错。但不能宣称结果无法复现,只是为了中稿,白白浪费读者时间就不好了!!!
针对这些论文方法给出了自己的一些可能的研究方向思考:
速度快
轻量级模型。
不论是CNN,transformer,还是3D lut得学习权重设计,都需要参数少,计算快,满足实时性要求!
效果好
色彩映射,其实不需要太大的模型进行色彩表征,难点在于特定色彩,能参考当前图片场景和语义进行自适应映射调整,以满足不同色彩映射关系得实现!
比如3D LUT可以考虑当前图片得场景得到对应gammar值进行全局颜色映射之后得自适应增强结果。
后续方法根据3D LUT得不足,融合语义、颜色自适应间隔采样、和1D lut融合等方法,都是补充!
大模型
在无版权网站找到高质量、色彩好得图片,进行整体的、随机性亮度降低、曝光降低、颜色饱和度和色调的调整,构建海量数据集;
同时使用大模型进行训练和优化,最终得到高质量的图像增强结果。
大模型的潜力来弥补不同主观感受到差异性!
或者使用语言来进行约束,学习训练各种不同风格的增强,使用模型并提供promote来自适应调整增强结果,而不是只能靠单一的专家标记和得到固定的结果。