目录
一、安装requests库
二、发送HTTP请求
三、解析HTML页面
四、处理HTTP响应和异常
五、使用代理和会话管理
六、使用多线程或多进程提高效率
七、数据存储和处理
八、注意事项和总结
在当今的数字化世界中,数据已经成为了一种宝贵的资源。而网络爬虫程序则是从互联网上自动收集和整理这些数据的重要工具。在各种爬虫框架和库中,Python的requests库以其简洁直观的API和强大的功能,成为了网络爬虫编程的热门选择。

本文将介绍如何使用requests库进行HTTP爬虫编程,包括发送HTTP请求、解析HTML页面、处理HTTP响应和异常处理等。我们将通过代码示例和详细解释来展示这些功能的使用方法和技巧。
一、安装requests库
在开始编写爬虫程序之前,我们首先需要安装requests库。可以通过Python的包管理器pip来安装:
pip install requests
二、发送HTTP请求
使用requests库发送HTTP请求非常简单。下面是一个基本的示例:
import requests url = 'http://example.com'
response = requests.get(url)在上面的代码中,我们使用requests.get()函数发送一个GET请求到指定的URL,并将返回的响应对象保存在response变量中。可以通过response.status_code检查请求的状态码,确保请求成功。
除了GET请求,requests库还支持其他HTTP方法,如POST、PUT和DELETE等。下面是一个使用requests.post()函数发送POST请求的示例:
python
import requests url = 'http://example.com/post'
data = {'key': 'value'}
response = requests.post(url, data=data)在这个示例中,我们使用requests.post()函数发送一个POST请求到指定的URL,并传递一个字典对象作为请求体。可以在response对象中检查响应的状态码和文本内容。
三、解析HTML页面
在爬虫程序中,解析HTML页面是收集数据的关键步骤之一。requests库本身并不提供HTML解析功能,但我们可以结合其他库如BeautifulSoup或lxml来解析HTML页面。下面是一个使用BeautifulSoup解析HTML页面的示例:
from bs4 import BeautifulSoup
import requests url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')在上面的代码中,我们首先使用requests.get()函数发送GET请求到指定的URL,并获取响应对象。然后,我们使用BeautifulSoup将响应的文本内容解析为HTML树状结构。最后,我们可以在soup对象中搜索和提取HTML元素。例如,可以使用soup.find()函数查找第一个符合条件的元素:
element = soup.find('div', {'class': 'example'})
还可以使用BeautifulSoup的其他方法如find_all()和select()来查找多个符合条件的元素或使用CSS选择器来查找元素。另外,lxml库也是一个强大的HTML解析库,可以与requests库一起使用来解析HTML页面。
四、处理HTTP响应和异常
在使用requests库发送HTTP请求时,可能会遇到各种不同的响应状态码和异常情况。为了确保爬虫程序的稳定性和健壮性,我们需要正确处理这些响应和异常。
首先,我们可以使用try-except语句块来捕获和处理requests库可能抛出的异常。例如,如果请求失败并返回一个错误状态码,requests库会抛出一个HTTPError异常。我们可以使用try-except语句块来捕获这个异常并采取相应的处理措施。下面是一个示例:
import requests url = 'http://example.com'
response = requests.get(url) try: response.raise_for_status() # 如果状态码不是200, 抛出HTTPError异常
except requests.exceptions.HTTPError as err: print(f"HTTP error occurred: {err}")除了HTTPError异常,requests库还提供了其他类型的异常,如Timeout、TooManyRedirects等。我们可以根据具体的需求来捕获和处理这些异常。
另外,如果需要处理一些特定的响应状态码,我们可以使用response对象的status_code属性来检查响应的状态码。例如,如果需要检查响应是否成功,可以使用response.status_code == 200来检查状态码是否为200。
五、使用代理和会话管理
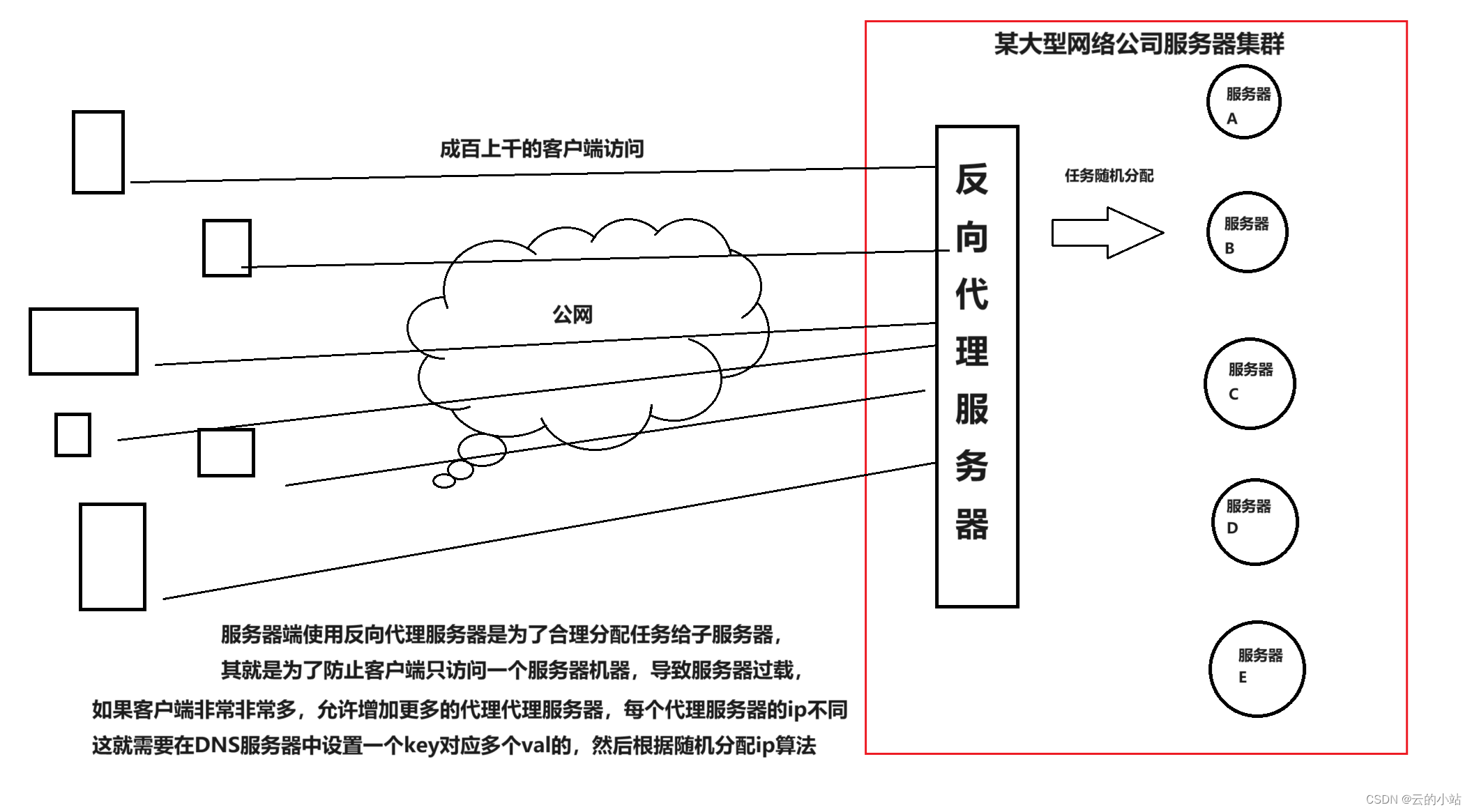
在使用爬虫程序进行大规模数据采集时,代理IP和会话管理是非常重要的技术手段。通过使用代理IP,可以避免被目标网站封禁IP地址;通过使用会话管理,可以模拟真实的浏览器行为,提高爬虫程序的隐蔽性。
requests库提供了方便的代理设置和会话管理功能。下面是一个使用代理的示例:
import requests proxies = { 'http': 'http://10.10.1.10:3128', 'https': 'http://10.10.1.10:1080',
}
response = requests.get('http://example.com', proxies=proxies)在上面的代码中,我们通过设置proxies字典来指定HTTP和HTTPS的代理地址。还可以使用requests库提供的HTTPAdapter类来管理代理池。
会话管理可以通过requests库的Session对象实现。下面是一个使用会话管理的示例:
import requests session = requests.Session()
response = session.get('http://example.com')在上面的代码中,我们创建了一个Session对象,并使用它来发送请求。Session对象可以保持多个HTTP请求之间的状态,使得会话管理和模拟浏览器行为更加方便。
六、使用多线程或多进程提高效率
在进行大规模数据采集时,如何提高爬虫程序的效率是一个重要的问题。使用多线程或多进程可以充分利用计算机的多个核心和多核CPU的并行计算能力,从而提高爬虫程序的效率。
requests库本身并不是线程安全的,因此我们需要使用线程或进程来隔离每个请求。下面是一个使用多线程的示例:
import threading
import requests def fetch_data(url): response = requests.get(url) # 处理响应数据 urls = ['http://example.com', 'http://example.net', 'http://example.org']
threads = []
for url in urls: thread = threading.Thread(target=fetch_data, args=(url,)) thread.start() threads.append(thread) # 等待所有线程完成
for thread in threads: thread.join()在上面的代码中,我们定义了一个fetch_data函数来发送HTTP请求和处理响应数据。然后,我们创建了一个多线程的爬虫程序,每个线程都独立地发送一个HTTP请求。最后,我们使用join()方法等待所有线程完成。
除了多线程,还可以使用多进程来提高爬虫程序的效率。可以使用Python标准库中的multiprocessing模块来创建多进程。需要注意的是,多进程通常比多线程更耗费资源,因此需要根据具体情况来选择适合的方案。
七、数据存储和处理
爬虫程序收集到的数据需要进行存储和处理。常见的存储方式包括文件、数据库和云存储等。可以根据具体的需求和数据量来选择适合的存储方式。例如,可以使用CSV或Excel格式将数据保存到本地文件,也可以将数据保存到MySQL或MongoDB等数据库中。
在处理数据方面,可以使用Python的pandas库来进行数据清洗、分析和可视化等操作。还可以使用BeautifulSoup库来解析HTML数据并提取有用的信息。另外,可以使用Scrapy框架来进行更复杂的网页爬取和数据提取操作。
八、注意事项和总结
在使用爬虫程序时,需要注意以下几点:
1、遵守法律法规和道德准则,不要侵犯他人的合法权益。
2、尊重目标网站的使用条款和服务协议,不要进行恶意攻击或滥用服务。
3、合理使用代理IP和会话管理,避免被封禁或影响他人使用体验。
4、注意数据的准确性和完整性,及时处理异常情况或数据质量问题。
5、注意代码的可维护性和可扩展性,方便日后维护和升级。
总之,使用requests库可以轻松地发送HTTP请求并提取有用的信息。通过结合多线程或多进程等技术手段,可以构建高效、稳定的爬虫程序来满足不同的需求。但需要注意遵守法律法规和道德准则,合理使用技术手段,共同维护良好的网络环境和社会秩序。
![[HNCTF 2022 WEEK2]easy_include 文件包含遇上nginx](https://img-blog.csdnimg.cn/a4620a440a544e31a3ef3575a8661dd0.png)