0 Abstract
- 普遍认为,LLM涌现出来的few-shot learning能力是超大参数模型独有的(>100B)【emergent abilities】;
- 作者认为,小模型(<10B)可以将这些能力从大模型(>100B)蒸馏下来【GPT3.5 -> T5】;
- 大模型具有强大的建模能力,但是它们需要处理各种各样的任务;小模型虽容量有限,但集中在特定任务上,模型可以达到不错的效果【model specialization】;
- 文章采用的测试任务是模型的multi-step math reasoning能力,并提供关于【微调数据格式】、【起始模型checkpoint】和【新的模型选择方法】的全面讨论。
1 Introduction
-
大模型在CoT的加持下,可以很好地解决数学推理等问题,而这种能力只有模型参数到达一定数量时才涌现出来
-
大模型在强大的同时,但哪里获得微调>100B模型的算力?如果小模型也能获得CoT加持是非常理想的,但是有研究指出,在小规模模型上使用CoT甚至会有负面影响
-
普遍认为让小模型从CoT中获益是非常困难的,但文章假设:将小模型运用于专有任务,也可以达到很好的modeling performance,而非聚焦于模型的通用能力
-
文章方法:从GPT3.5(175B)上将其CoT reasoning的能力蒸馏到FlanT5(11B)上。(FlanT5是基于T5小模型,经过CoT指令微调得到的,它具有CoT的通用能力,但相较大模型差得多)
-
文章的发现与贡献:
- 通过实验证明,当小模型专有化时,也可以得到跟大模型类似的CoT scaling curve;
- 详细描述了如何将模型的泛化能力转移到专有能力;
- 现有方法通常在同一数据集的val set选择模型,而本文在多个不同的math reasoning dataset做选择以防止over-fitting,提高模型的OOD能力。
2 Background
- LLM ability:现有范式是训练base model -> tuning,并且发现了CoT中模型随着scale增大的涌现能力;
- 专门化模型:对于大模型,不必权衡不同任务的表现。而小模型由于容量有限,需要舍弃通用能力,常见做法是通过特定的data微调,但是这种方法通常没有OOD能力(即出现了over-fitting);
- 本文关注的重点是【模型专门化过程中的能力权衡,即在目标任务上的泛化能力,确保模型的in-distribution and OOD performance】,而不是蒸馏或者数据增强;
- 相关工作:FlanT5(小模型CoT通用能力)、Huang et al.(大模型在CoT上的微调)
3 Specializing Multi-Step Reasoning
-
Dataset:在GSM8K数据集上微调,但是在MultiArith, ASDiv, SVAMP上validation,并且在BigBench Hard上测试模型在专有任务的泛化能力;
![[图片]](https://img-blog.csdnimg.cn/8accdc3b73bd49c3a959ceefddc028b1.png)
-
Model:T5和FlanT5作为基础模型,code-davinci-002【OpenAI的一个基础模型,适用于纯代码补全任务,隶属于GPT系列】生成蒸馏/专有数据;
![[图片]](https://img-blog.csdnimg.cn/a29fc04ac57542e6ad8fab852372d517.png)
3.1 Distillation from Code-Davinci-002
-
采用Code-Davinci-002生成训练所需要的微调数据集,主要有以下四种format:
![[图片]](https://img-blog.csdnimg.cn/14cd38faeb2a43539f707e062451a5c5.png)
-
通过这四种数据格式,作者可以探索以下问题:
- 上下文信息对模型性能的影响是什么?
- CoT提示是否有助于提高模型性能?
- 模型是否可以在没有任何提示或上下文的情况下执行任务?
-
训练时让teacher和student的输出分布用KL散度进行衡量(仅存储分布的top-5节约内存,因为top-5的概率之和已经接近于1)
3.2 Aligning tokenizers by dynamic programming
- 由于GPT和T5所采用的tokenizer不同,需要解决两者分布的misalignment。
- 使用动态规划来解决alignment问题【复杂】:
![[图片]](https://img-blog.csdnimg.cn/07fa2f3d3dc842b1856dce9df4a17cea.png)
4 Experiments
- 实验目的:可以提升小模型数学CoT性能的scale curve的程度,以及它的代价是多少?
4.1 Overall Performance Tradeoff
- 微调:使用GSM8K数据集让code-davinci-002生成40个CoT solutions,选择回答正确的进行微调;
- 测试:在GSM8K上测试in-distribution能力,在MultiArith, ASDiv, and SVAMP上测试OOD能力,在BigBench Hard上测试模型泛化能力;
- 结论小结:专有化的FlanT5在四个数据集均有大提升,但是在BBH损失了全部的CoT性能和大部分AO性能【这证明文章的假设:可以损失小模型的泛化能力来提升专有能力的性能,达到比肩大模型的效果】;
![[图片]](https://img-blog.csdnimg.cn/7a165f003c9844dcb27b9acf083abaea.png)
4.2 Scaling Behavior of Smaller Models’ CoT Ability
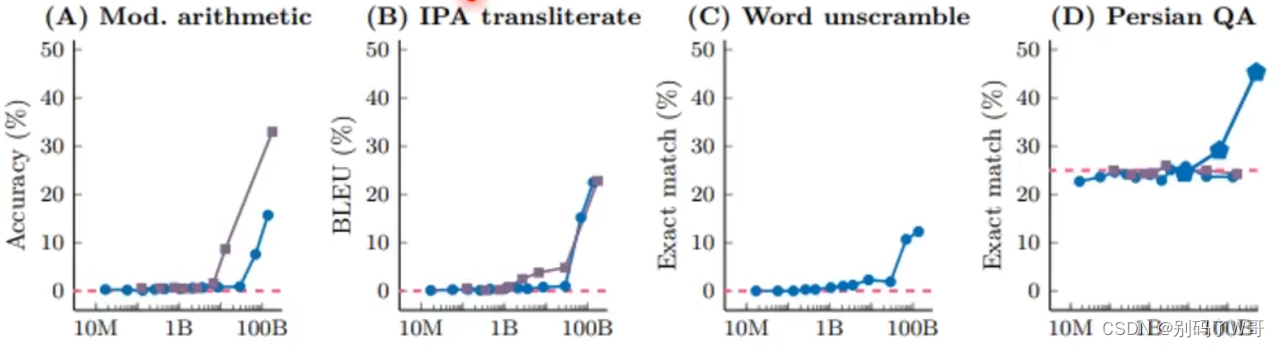
- 普遍认为,小模型的scale curve是平坦的,如同A图左边的部分;
- 文章指出,小模型(T5和FlanT5)可以在CoT tuning后呈现log-linear的scale curve,推翻“大模型涌现”这个说法【在tuning之前,小模型只是因为模型能力不足,导致中间步骤推理出错进而导致完全错误的结论,而不是代表小模型完全没有解决问题的能力,只是才scale足够大才涌现】;
- 经过CoT指令微调的FlanT5在专有化后,性能提升相较于raw T5有更大提升。
![[图片]](https://img-blog.csdnimg.cn/9502061ca9d849598ae63f65d05dc4bd.png)
4.3 Specialization Process and Generalization Behaviors
- 蒸馏初期,模型就会失去CoT和大部分AO能力,而后专有能力波动提升;
- 在专有能力中,in-distribution和OOD能力是波动的,建议根据实际应用选择checkpoint;
![[图片]](https://img-blog.csdnimg.cn/2b9669b248344163b0760af92e1145eb.png)
![[图片]](https://img-blog.csdnimg.cn/62a390d6fbd44e9abb0451f4dd08815e.png)
4.4 Further Design Choices Analysis
-
蒸馏训练中,使用distribution match策略更优;
![[图片]](https://img-blog.csdnimg.cn/b9923645793147aeaf528d28f0d1b7bb.png)
-
训练中,如果使用in-context learning训练,模型在测试时同时具有in-context和zero-shot能力;而如果只使用zero-shot训练,模型将损失几乎所有的in-context能力,这就是为什么文章需要混合不同format的数据。
![[图片]](https://img-blog.csdnimg.cn/0601ba6aca2847ba8121f25b1db52cb7.png)