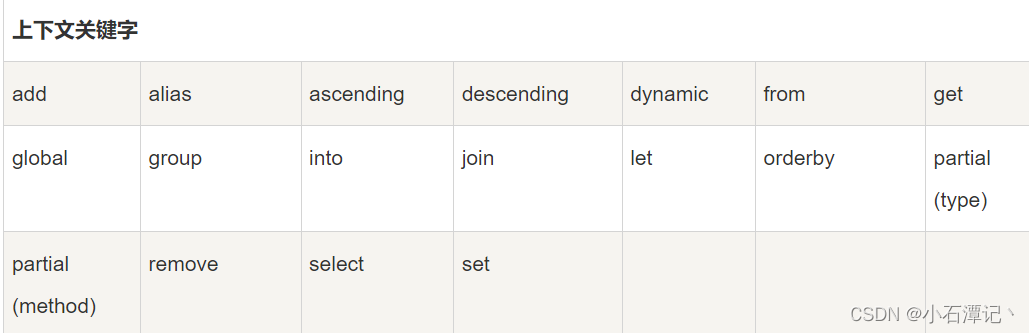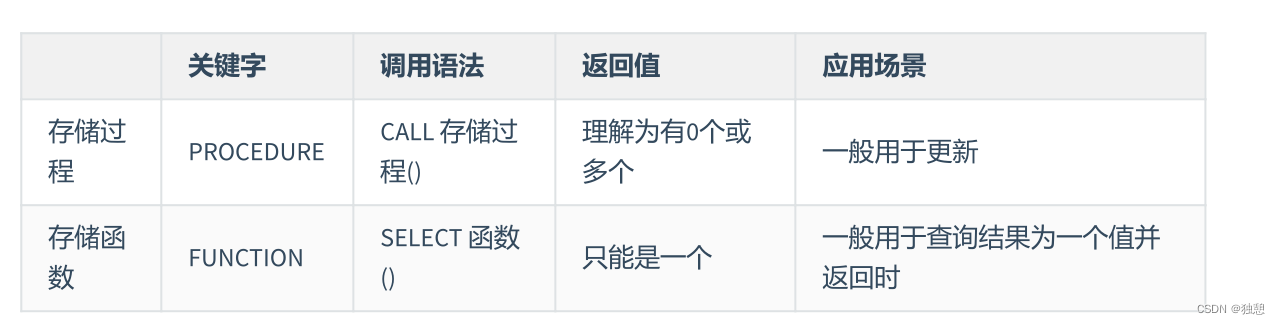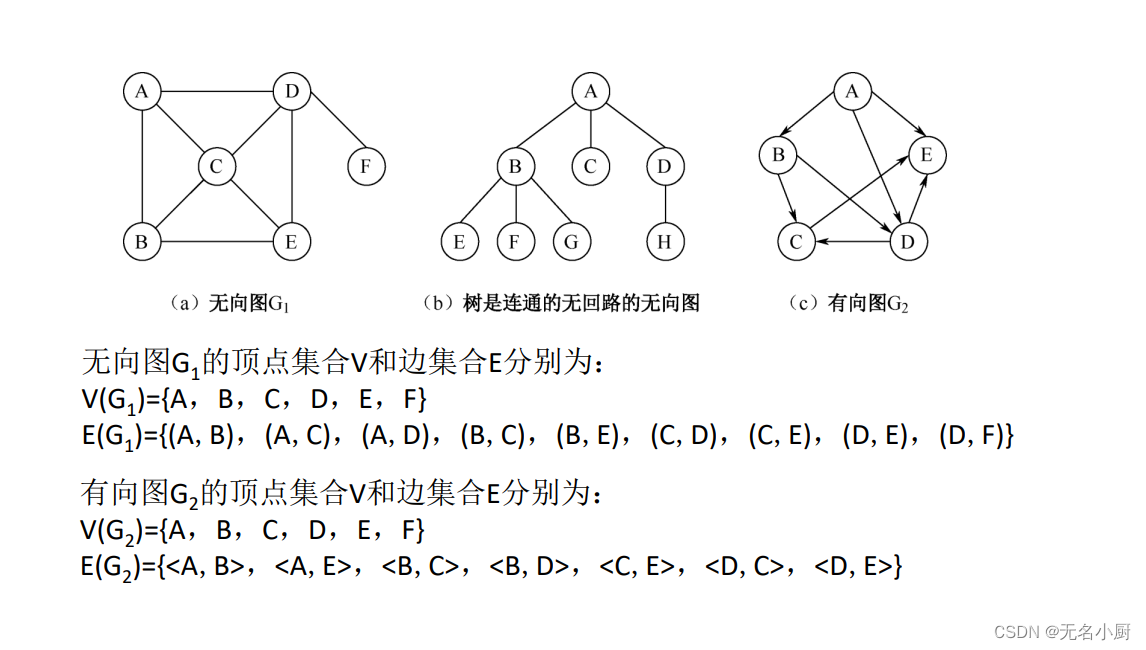
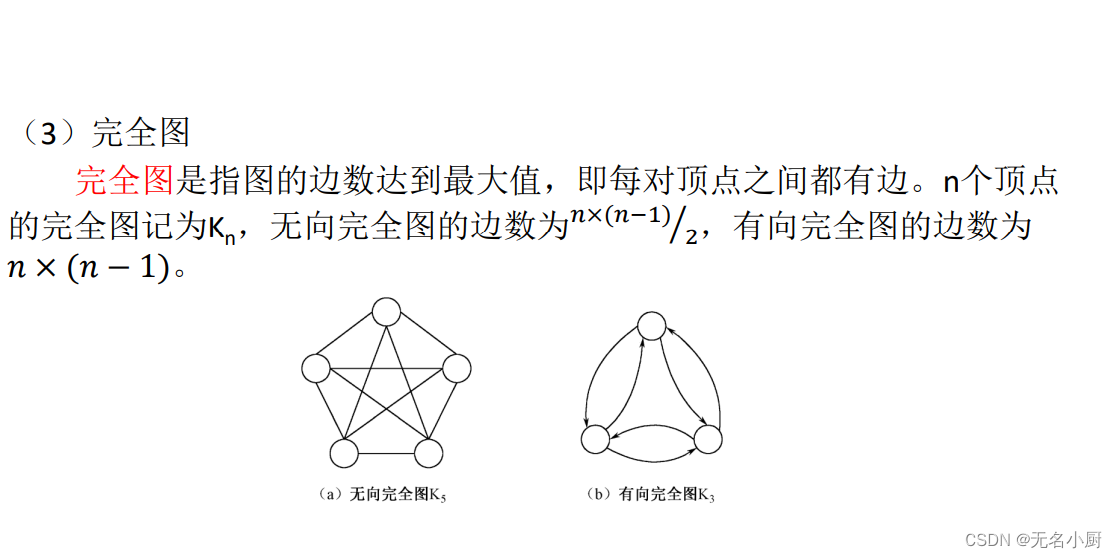
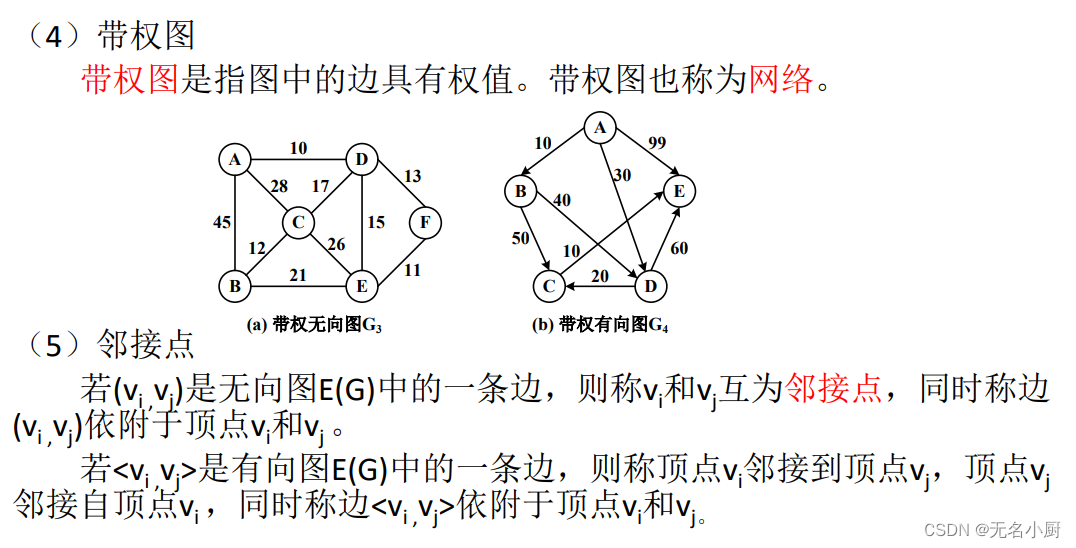
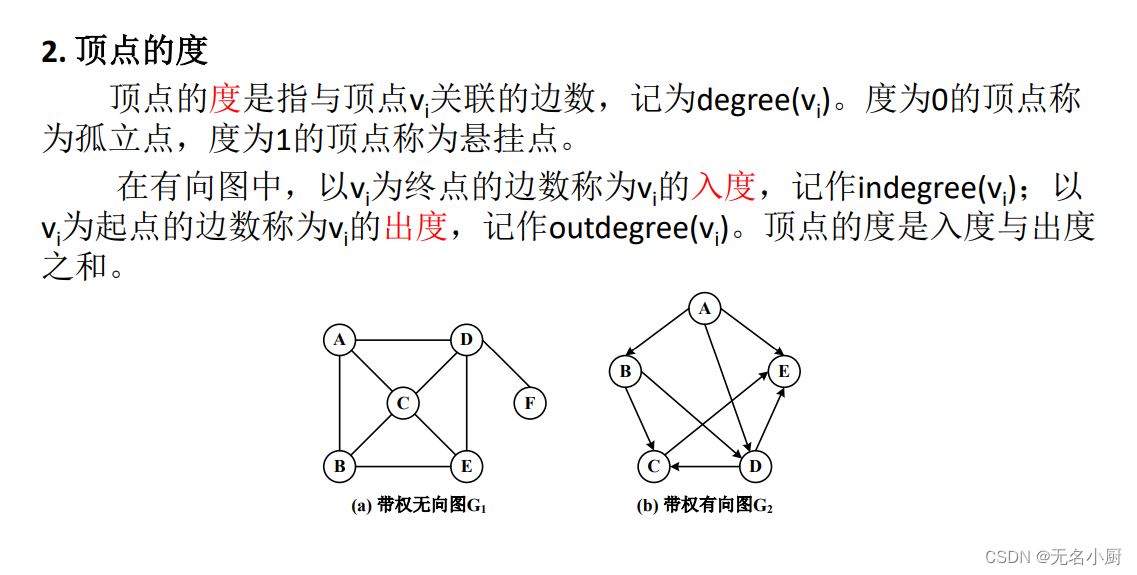

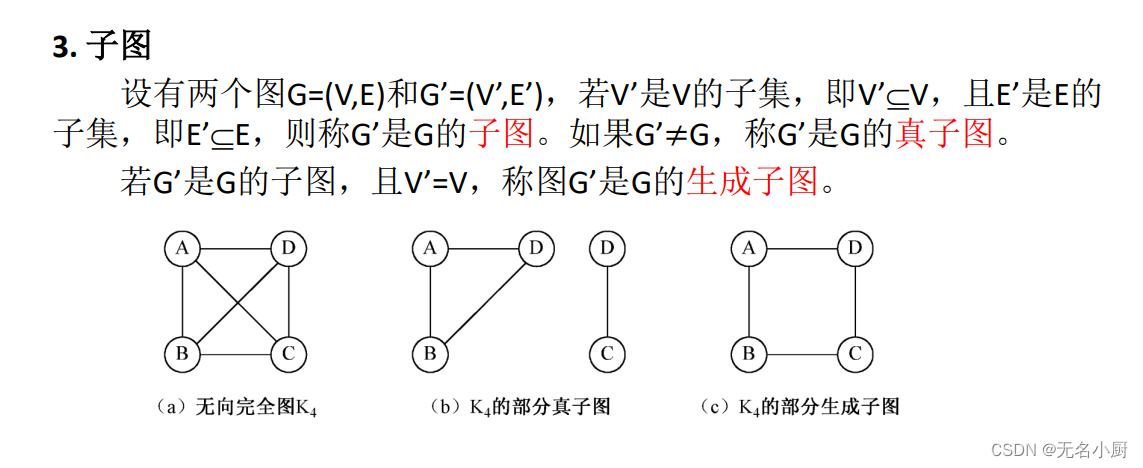
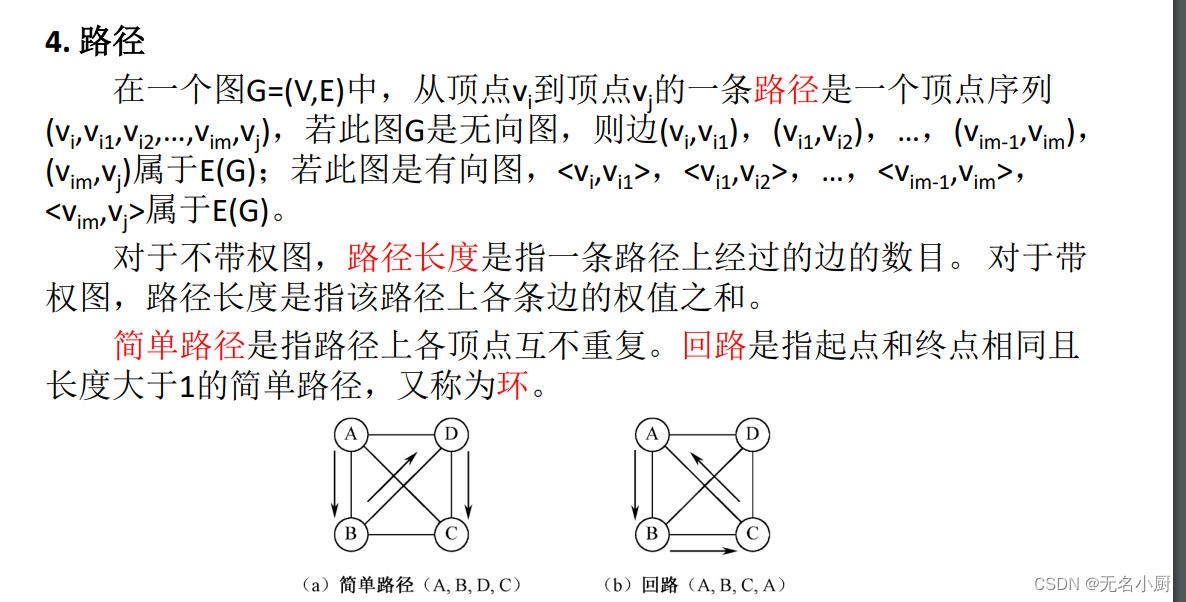
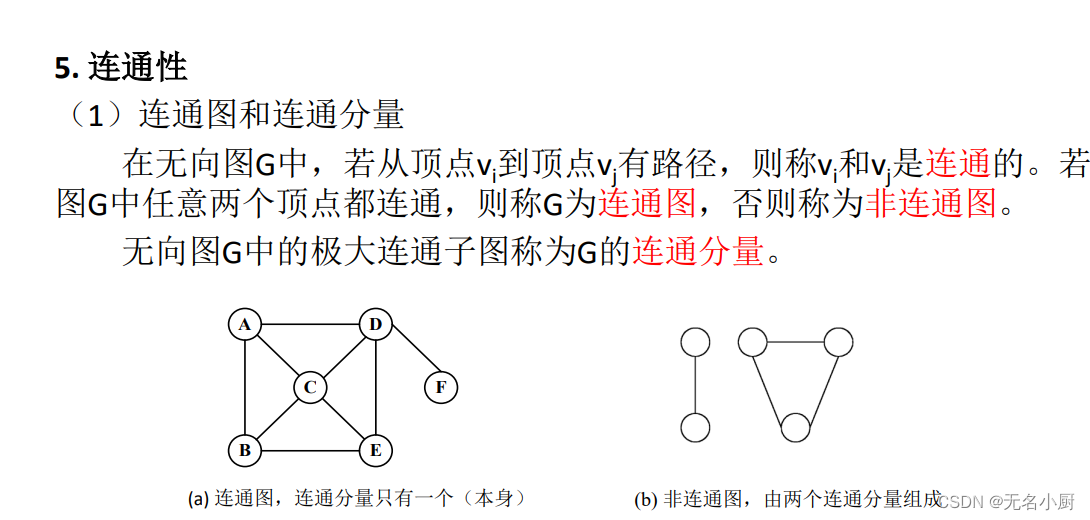
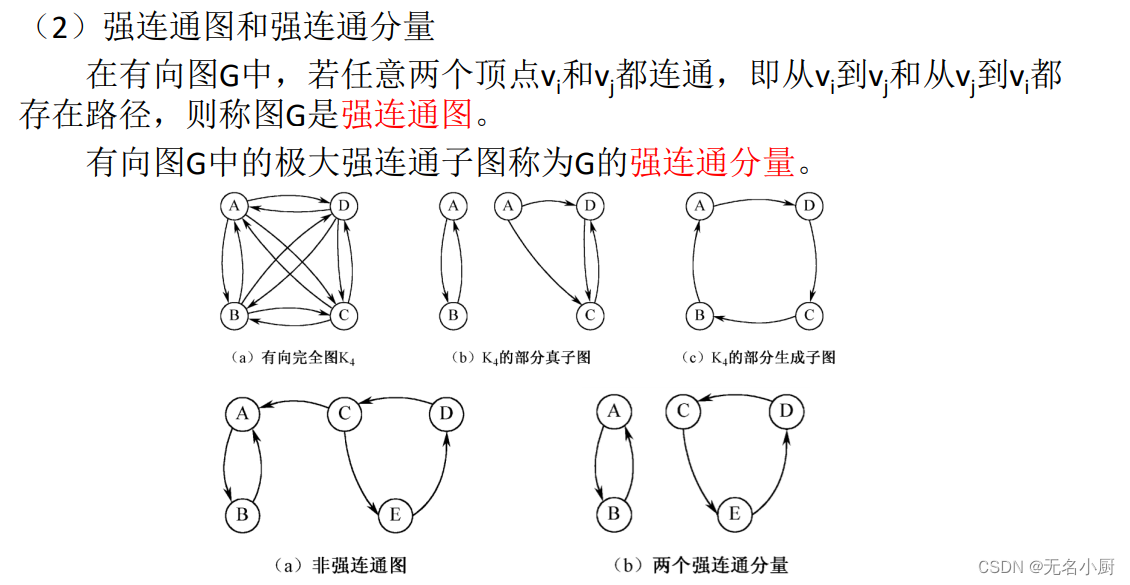

7 图的存储
(1)图的邻接矩阵存储

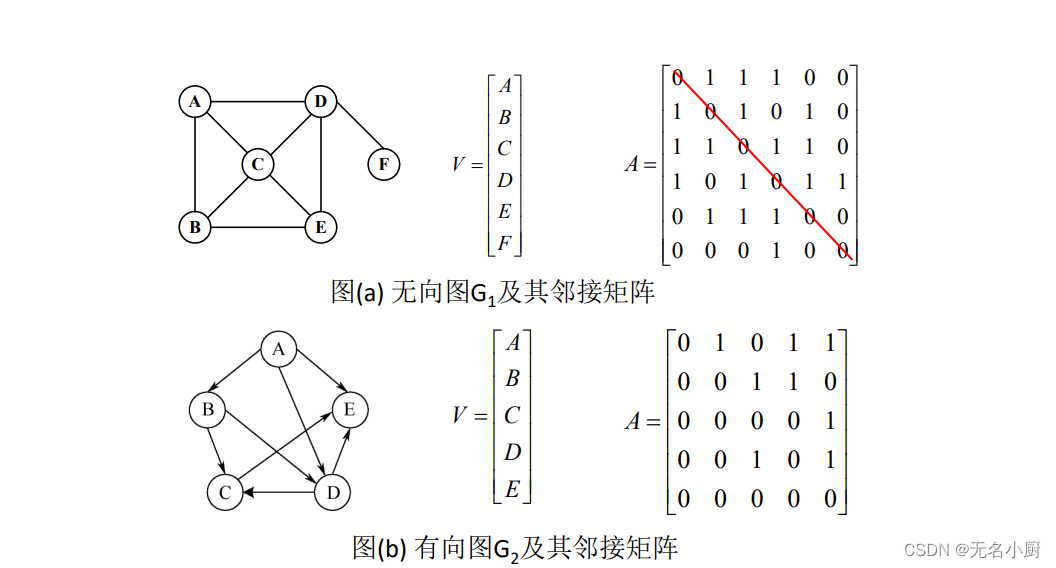
对于无向图,邻接矩阵第i行/列上非零元素个数是顶点vi的度。
对于有向图,邻接矩阵第i行上非零元素个数是顶点vi的出度,第i列
上非零元素个数是顶点vi的入度。
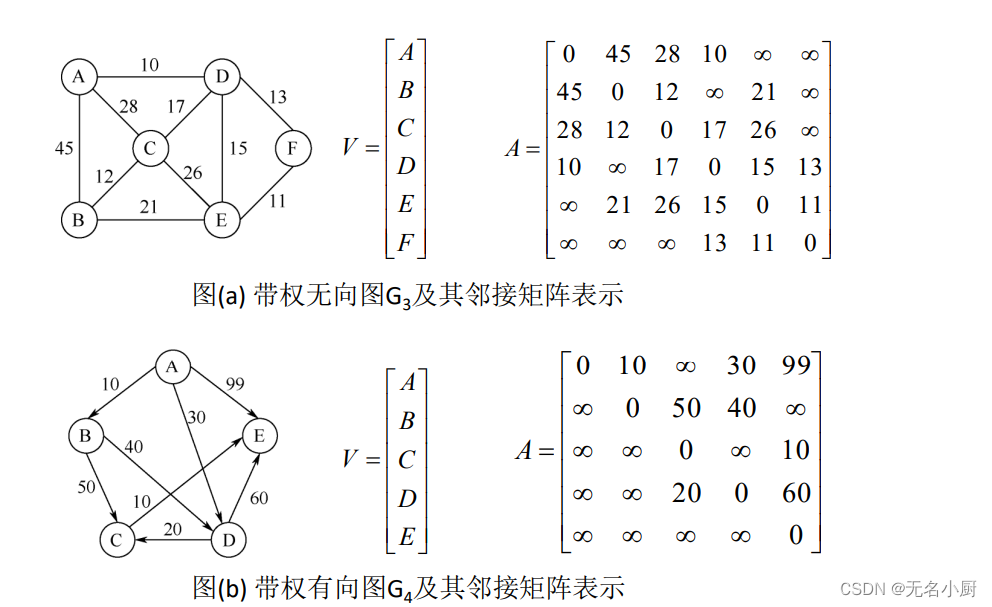
对于带权有向图有边则存储权值,无边存储无穷符号,0代表节点相等
邻接矩阵存储图的性能分析:
时间上:判断两顶点间是否右边、获取或设置边的权值等操作花费的时间是O(1)插入或删除元素,需要移动大量元素,效率很低
空间上:不管顶点间是否右边,邻接矩阵中都要占用一个存储单元,存储空间大小为n*n,
(2)图的邻接表存储


有向图的邻接表,每条边只存储一次,根据边的方向,分为邻接表(点在边单链表作为起点),逆邻接表(点在边单链表作为终点)
一个图的邻接表表示不唯一,这是因为,边单链表结点的链接次序取决于建立邻接表的算法以及边的输入次序
7 图的遍历
定义:是指从图中任意一个顶点出发,沿着图中的边前行,到达并访问图中的所有顶点,且每个顶点仅被访问一次
(1)深度优先搜索(Depth First Search,DFS)
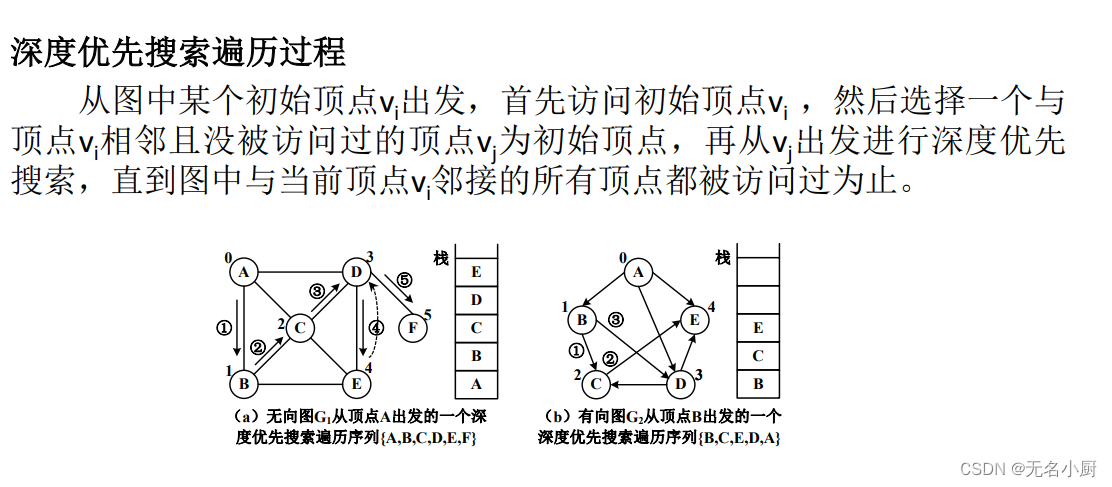


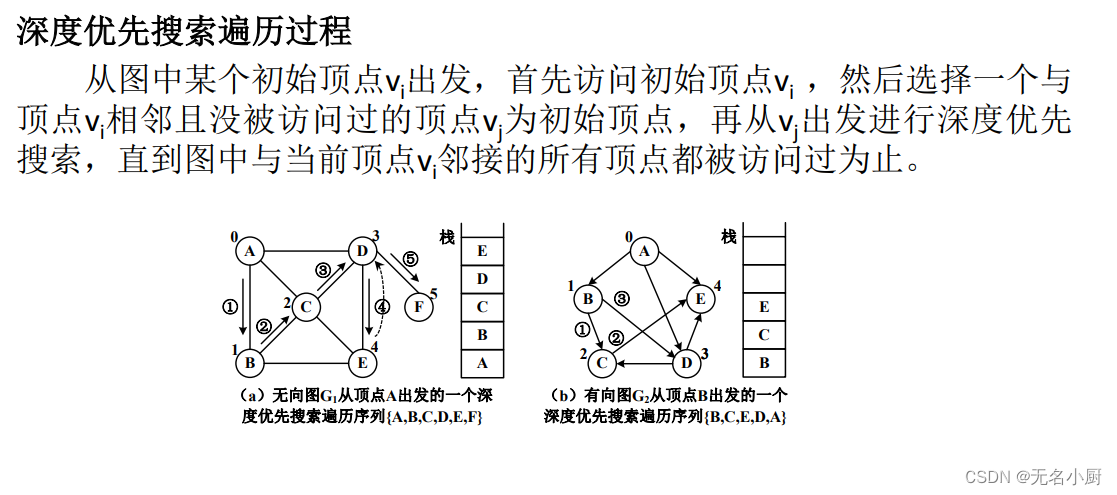
连通图与非连通图的深度优先遍历实现
//从顶点vi出发的一次深度优先搜索,遍历一个连通分量;visited指定访问标记数组private void depthfs(int i, boolean[] visited){System.out.print(this.getVertex(i)+" "); //访问顶点vivisited[i] = true; //设置访问标记for (int j=this.next(i,-1); j!=-1; j=this.next(i,j)) //j依次获得vi的所有邻接顶点序号if(!visited[j]) //若邻接顶点vj未被访问depthfs(j, visited); //从vj出发的深度优先搜索遍历,递归调用}public void DFSTraverse(int i) //非连通图的深度优先搜索遍历,从顶点vi出发{boolean[] visited=new boolean[this.vertexCount()]; //访问标记数组,元素初值为false,表示未被访问int j=i;do{ if (!visited[j]) //若顶点vj未被访问。若i越界,Java将抛出数组下标序号越界异常{System.out.print("{ ");this.depthfs(j, visited); //从顶点vj出发的一次深度优先搜索System.out.print("} ");}j = (j+1) % this.vertexCount(); //在其他连通分量中寻找未被访问顶点} while (j!=i);System.out.println();}
(2) 广度优先搜索(Breadth First Search,BFS)

广度优先搜索遍历算法实现
//从顶点vi出发的一次广度优先搜索,遍历一个连通分量,使用队列private void breadthfs(int i, boolean[] visited) {System.out.print(this.getVertex(i) + " "); //访问顶点vivisited[i] = true; //设置访问标记LinkedQueue<Integer> que = new LinkedQueue<Integer>(); //创建链式队列que.add(i); //访问过的顶点vi序号入队while (!que.isEmpty()) //当队列不空时循环{i = que.poll(); //出队for (int j = next(i, -1); j != -1; j = next(i, j)) //j依次获得vi的所有邻接顶点if (!visited[j]) //若顶点vj未访问过{System.out.print(this.getVertex(j) + " "); //访问顶点vjvisited[j] = true;que.add(j); //访问过的顶点vj序号入队}}}public void BFSTraverse(int i) //非连通图的广度优先搜索遍历,从顶点vi出发{boolean[] visited = new boolean[this.vertexCount()]; //访问标记数组int j=i;do{ if (!visited[j]) //若顶点vj未被访问{System.out.print("{ ");breadthfs(j, visited); //从vj出发的一次广度优先搜索System.out.print("} ");}j = (j+1) % this.vertexCount(); //在其他连通分量中寻找未被访问顶点} while (j!=i);System.out.println();}
7 最小生成树
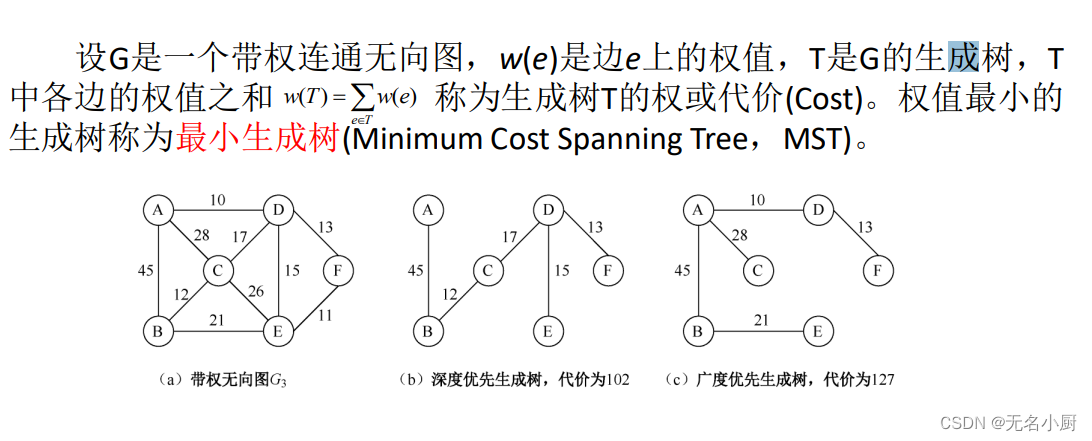
最小的生成树的概念可以应用到许多实际问题中。例如,以尽可能低的造价建造若干条高速公路,把n个城市联系在一起,就是一个最小生成树问题。
最小生成树的构造方法
(1)Prim算法

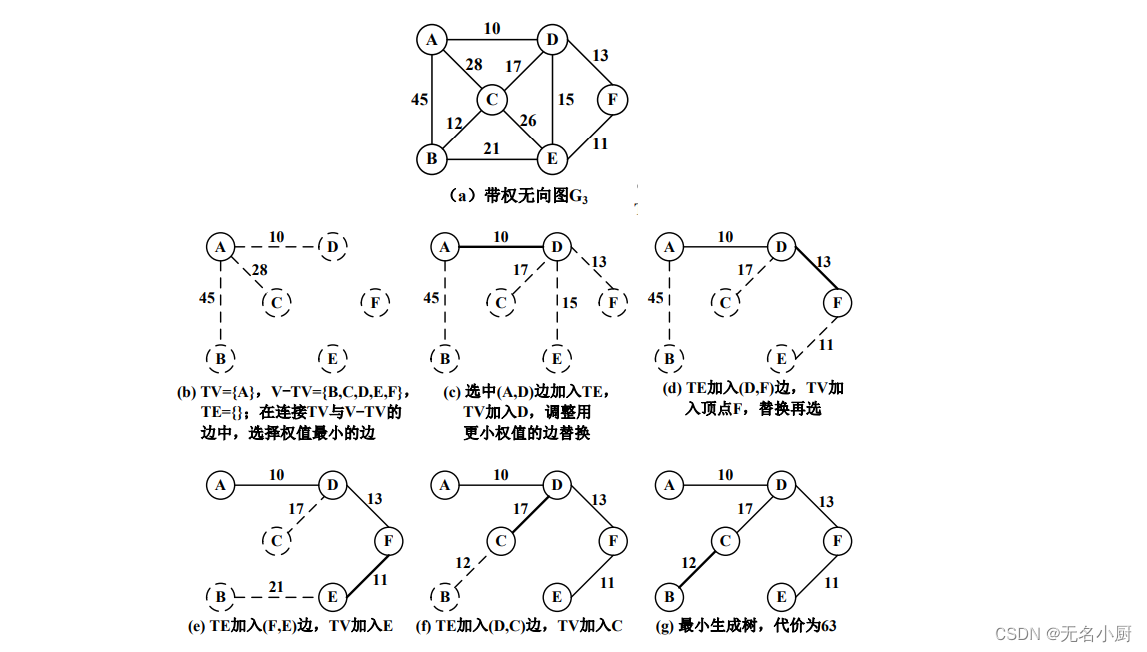

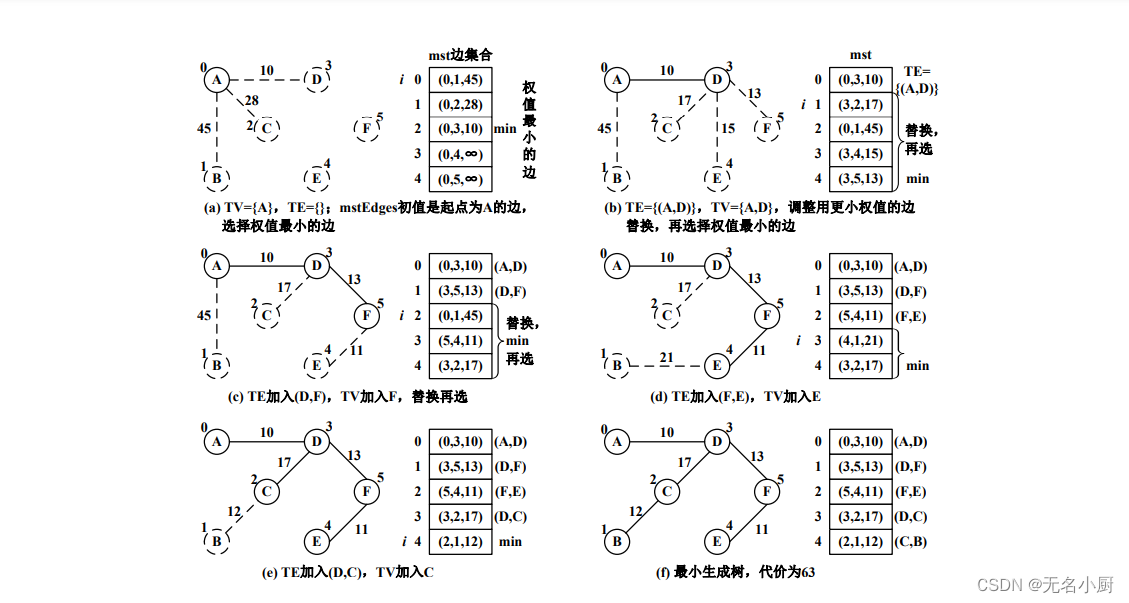
// Prim算法实现
public void minSpanTree(){Triple[] mst = new Triple[vertexCount()-1]; //最小生成树的边集合,边数为n-1for (int i=0; i<mst.length; i++) //边集合初始化,从顶点v0出发构造mst[i]=new Triple(0,i+1,this.weight(0,i+1)); //保存从v0到其他各顶点的边for (int i=0; i<mst.length; i++) //选择n-1条边,每趟确定一条权值最小的边{int minweight=mst[i].value, min=i; //最小权值及边的下标for (int j=i+1; j<mst.length; j++) //在i~n-1范围内,寻找权值最小的边if (mst[j].value < minweight) //若存在更小权值,则更新最小值变量{minweight = mst[j].value; //最小权值min = j; //保存当前权值最小边的序号}Triple edge = mst[min]; //将权值最小的边(由min记得)交换到第i个元素,表示该边加入TE集合if (min!=i){mst[min] = mst[i];mst[i] = edge;}//将i+1~n-1的其他边用权值更小的边替换int tv = edge.column; //刚并入TV的顶点for (int j=i+1; j<mst.length; j++){int v = mst[j].column; //原边在V-TV中的终点int weight = this.weight(tv,v);if (weight<mst[j].value) //若(tv,v)边比第j条边的权值更小,则替换mst[j] = new Triple(tv,v,weight);}}System.out.print("\n最小生成树的边集合:");int mincost=0;for (int i=0; i<mst.length; i++) //输出最小生成树的边集合和代价{System.out.print(mst[i]+" ");mincost += mst[i].value;}System.out.println(",最小代价为"+mincost);}
(2))Kruskal算法
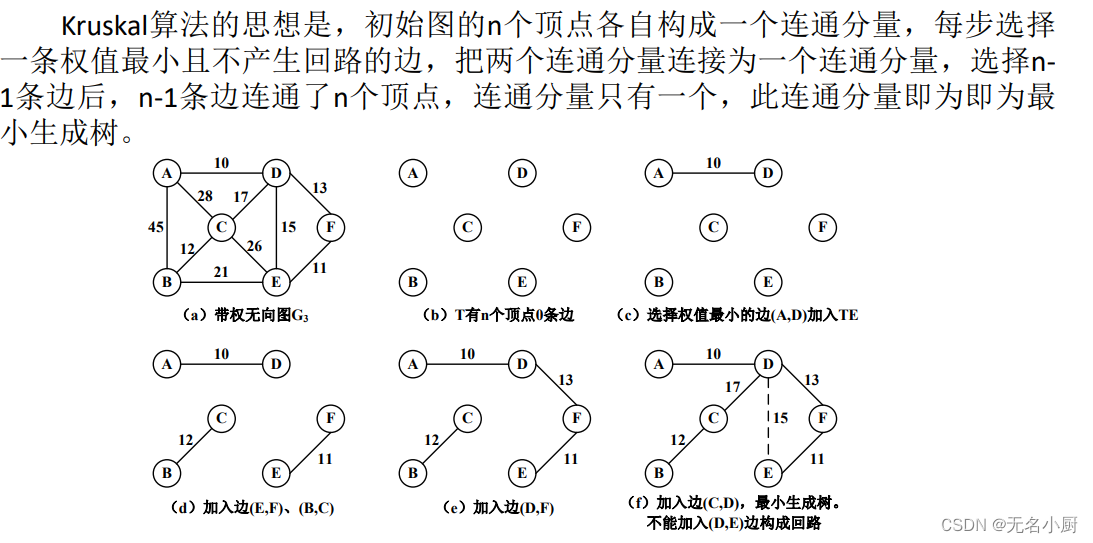


Kruskal算法实现
在这里插入代码片// edges为排序顺序表,从小到达存储各边,最小生成树的边存储在mst数组中public void minSpanTree(SortedSeqList <Triple> edges, Triple[] mst ){int[] parent=new int[vertexCount()]; //parent表示顶点的父母,parent[i]=-1表示顶点i没有父母int i, j, vp1, vp2;for(i=0;i<vertexCount();i++) //初始化parent数组,每个顶点各自构成一个连通分量parent[i]=-1;i=0;j=0;while(i<edges.size()&&j<vertexCount()-1) //依次选取权值较小的边{ vp1=find(parent,edges[i].row); //查找顶点的父母vp2=find(parent,edges[i].column);if (vp1!=vp2) //选中的边两个顶点位于不同的连通分量{ parent[vp2]=vp1; //合并两个连通分量mst[j]=edges.element[i];j++;}i++;}}//查找顶点的父母,即顶点所在的集合public static int find(int[] parent, int v){int t;t=v;while(parent[t]>=0)t=parent[t];return t;}7 图最短路径
设G=(V,E)是一个带权图,若G中从顶点vi到vj的一条路径(vi,⋯,vj),其路径长度dij是所有从vi到vj路径长度的最小值,则(vi,⋯,vj)是从vi到vj的最短路径,vi称为源点,vj称为终点。
最短路径算法
(1)求单源最短路径——Dijkstra算法
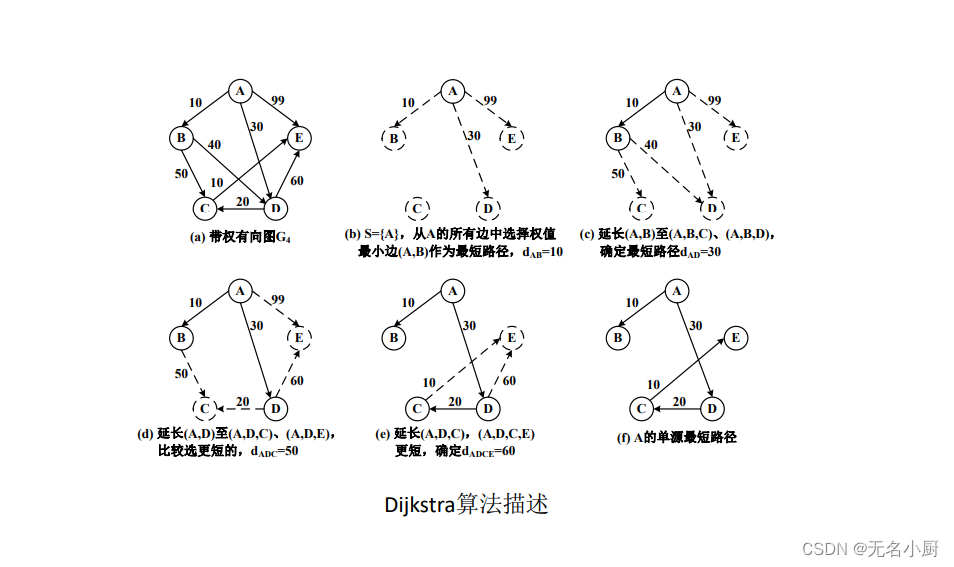
Dijkstra算法描述:
设S是已求得最短路径的顶点集合,初始S={vi},V-S是剩余顶点集合,算法重复执行以下操作:
• 从V-S中选取一个距离vi最短的顶点vj ,把vj加入到S中;
• 判断vi到V-S中顶点vk的距离dik,经过顶点vj是否比原来更短,若更短则
修改dik=dij+wjk。
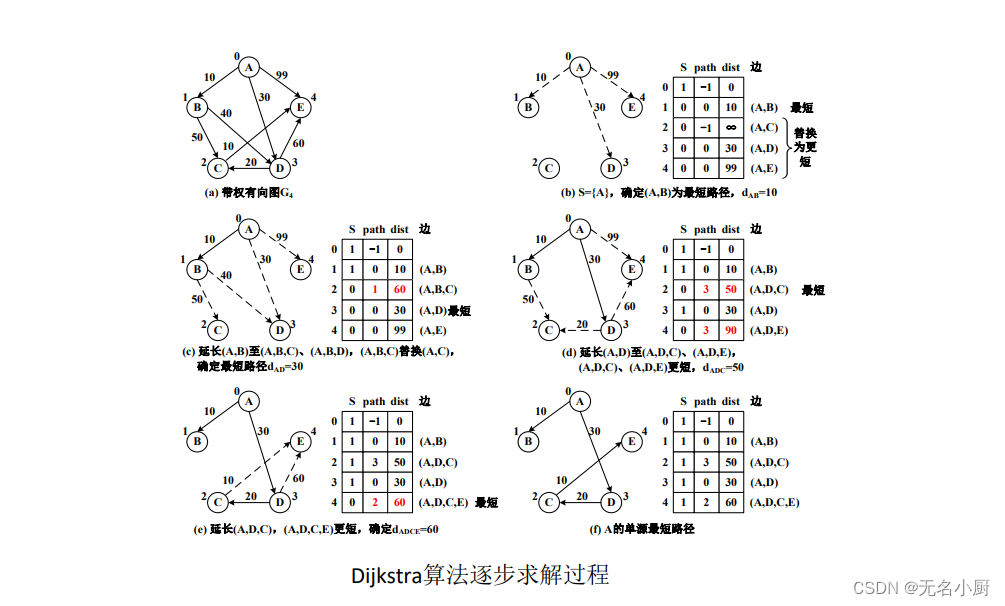
算法实现
算法使用三个数组来实现:
• s数组表示集合S,若s[i]=1,则顶点vi ∈ 𝑆,否则vi∈ 𝑉 − 𝑆。
• dist数组保存最短路径长度。
• path数组保存最短路径上该顶点的前驱。

代码实现
public void shortestPath(int i) //求带权图中顶点vi的单源最短路径,Dijkstra算法{int n = this.vertexCount(); //图的顶点数boolean[] vset = new boolean[n]; //已求出最短路径的顶点集合,初值全为falsevset[i] = true; //标记源点vi在集合S中。若i越界,Java抛出序号越界异常int[] dist = new int[n]; //最短路径长度int[] path = new int[n]; //最短路径的终点的前一个顶点for (int j = 0; j < n; j++) //初始化dist和path数组{dist[j] = this.weight(i, j);path[j] = (j != i && dist[j] < MAX_WEIGHT) ? i : -1;}for (int j = (i + 1) % n; j != i; j = (j + 1) % n) //寻找从vi到vj的最短路径,vj在V-S集合中{int mindist = MAX_WEIGHT, min = 0; //求路径长度最小值及其下标for (int k = 0; k < n; k++)if (!vset[k] && dist[k] < mindist) {mindist = dist[k]; //路径长度最小值min = k; //路径长度最小值下标}if (mindist == MAX_WEIGHT) //若没有其他最短路径则算法结束; 此语句对非连通图必需break;vset[min] = true; //确定一条最短路径的终点min并入集合Sfor (int k = 0; k < n; k++) //调整从vi到V-S中其他顶点的最短路径及长度if (!vset[k] && this.weight(min, k) < MAX_WEIGHT && dist[min] + this.weight(min, k) < dist[k]) {dist[k] = dist[min] + this.weight(min, k); //用更短路径替换path[k] = min; //最短路径经过min顶点}}System.out.print(this.getVertex(i) + "的单源最短路径:");for (int j = 0; j < n; j++) //输出顶点vi的单源最短路径if (j != i) {SinglyList<T> pathlink = new SinglyList<T>(); //路径单链表,记录最短路径经过的各顶点,用于反序pathlink.insert(0, this.getVertex(j)); //单链表插入最短路径终点vjfor (int k = path[j]; k != i && k != j && k != -1; k = path[k])pathlink.insert(0, this.getVertex(k)); //单链表头插入经过的顶点,反序pathlink.insert(0, this.getVertex(i)); //单链表插入最短路径起点viSystem.out.print(pathlink.toString() + "长度" + (dist[j] == MAX_WEIGHT ? "∞" : dist[j]) + ",");}System.out.println()}Dijkstra算法的时间复杂度为𝑂(𝑛2)
(2)求每对顶点间的最短路径——Floyd算法

Floyd算法过程描述
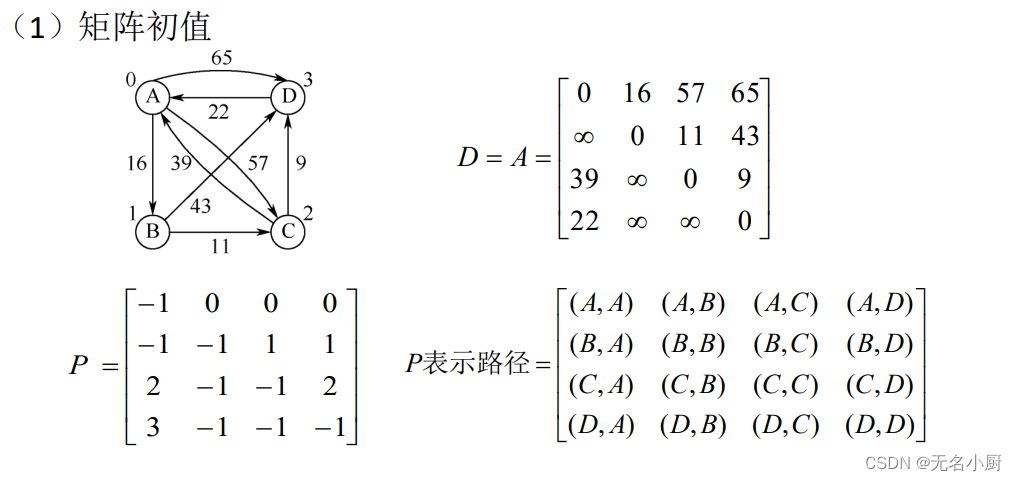

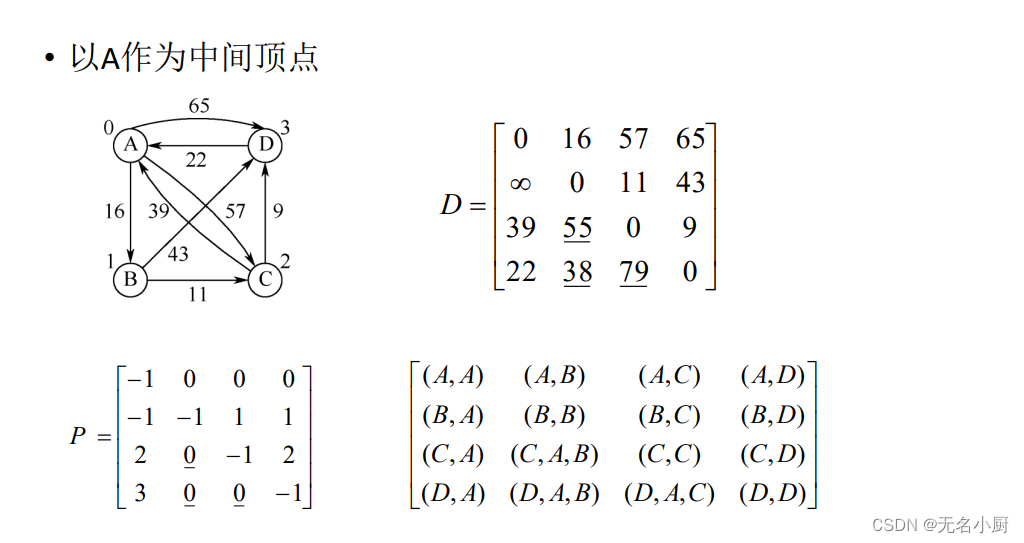
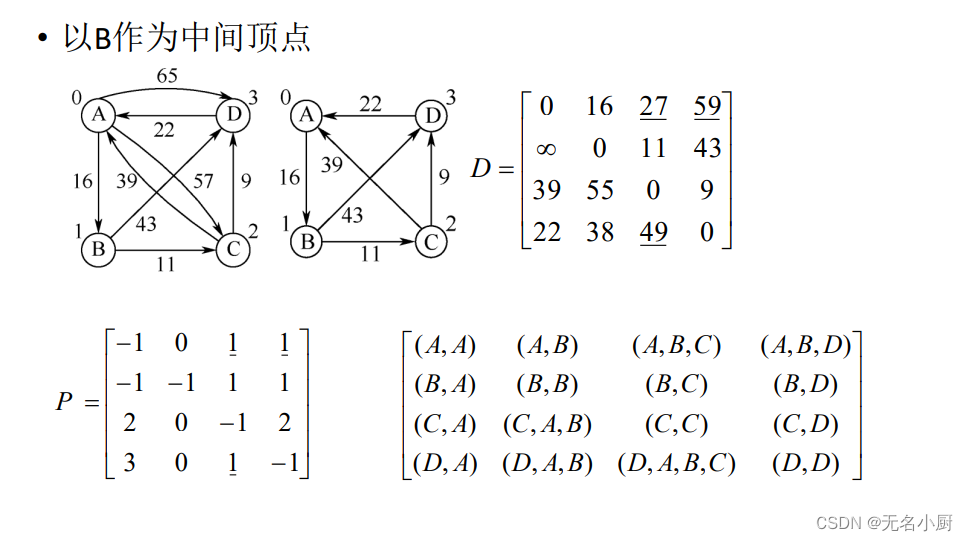
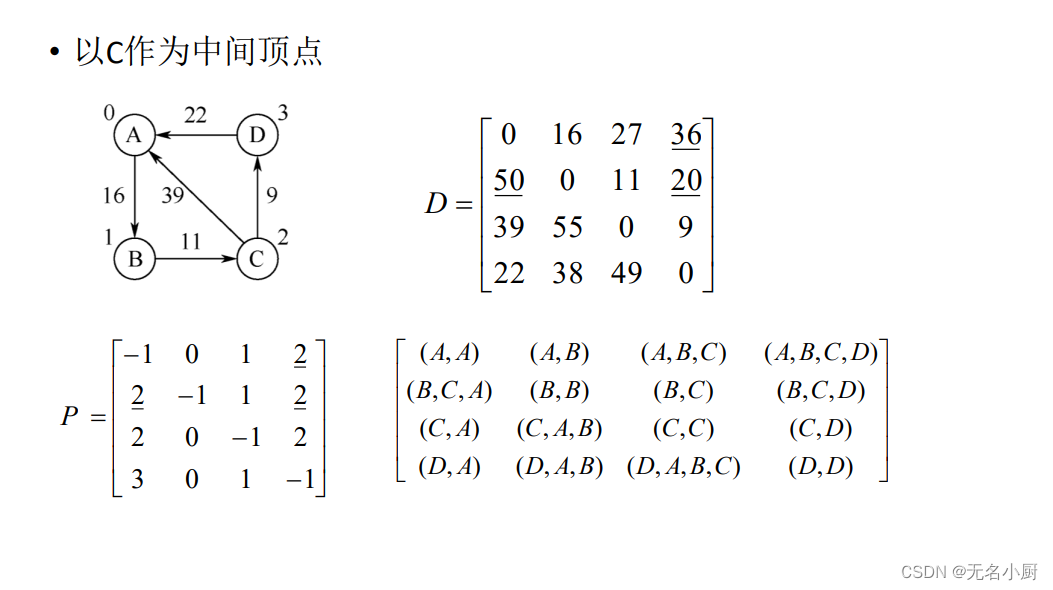


Floyd算法实现
//AbstractGraph<T>类声明以下shortestPath()成员方法,对于邻接矩阵或邻接表表示的图,都可以调用执行public void shortestPath() //求带权图每对顶点间的最短路径及长度,Floyd算法{int n=this.vertexCount(); //图的顶点数Matrix path=new Matrix(n), dist=new Matrix(n); //最短路径及长度矩阵,初值为0for (int i=0; i<n; i++) //初始化dist、path矩阵for (int j=0; j<n; j++){ int w=this.weight(i,j);dist.set(i,j,w); //dist初值是图的邻接矩阵path.set(i,j, (i!=j && w<MAX_WEIGHT ? i : -1));}for (int k=0; k<n; k++) //以vk作为其他路径的中间顶点for (int i=0; i<n; i++) //测试每对从vi到vj路径长度是否更短if (i!=k)for (int j=0; j<n; j++)if (j!=k && j!=i && dist.get(i,j) > dist.get(i,k)+dist.get(k,j)) //若更短,则替换{dist.set(i, j, dist.get(i,k)+dist.get(k,j));path.set(i, j, path.get(k,j));}System.out.println("\n每对顶点间的最短路径如下:");for (int i=0; i<n; i++){for (int j=0; j<n; j++)if (i!=j)System.out.print(toPath(path,i,j)+"长度"+(dist.get(i,j)==MAX_WEIGHT ? "∞" : dist.get(i,j))+",");System.out.println();}}7 拓扑排序

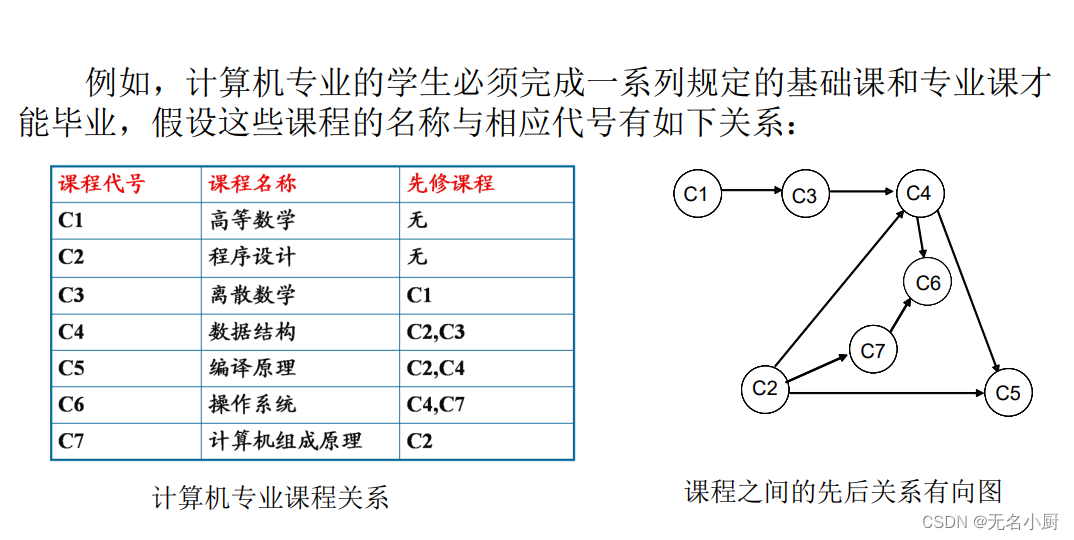
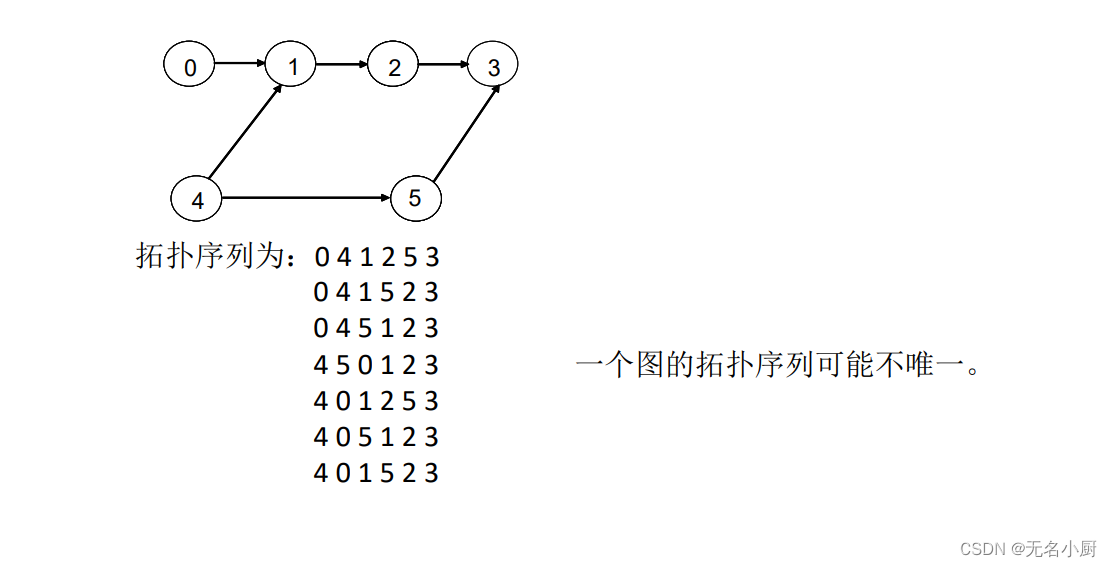
拓扑排序的基本思想:
(1)从有向图中选择一个没有前驱(即入度为0)的顶点并且输出它;
(2)从网中删去该顶点,并且删去从该顶点发出的全部有向边;
(3)重复上述两步,直到剩余的网中不存在没有前驱的顶点为止

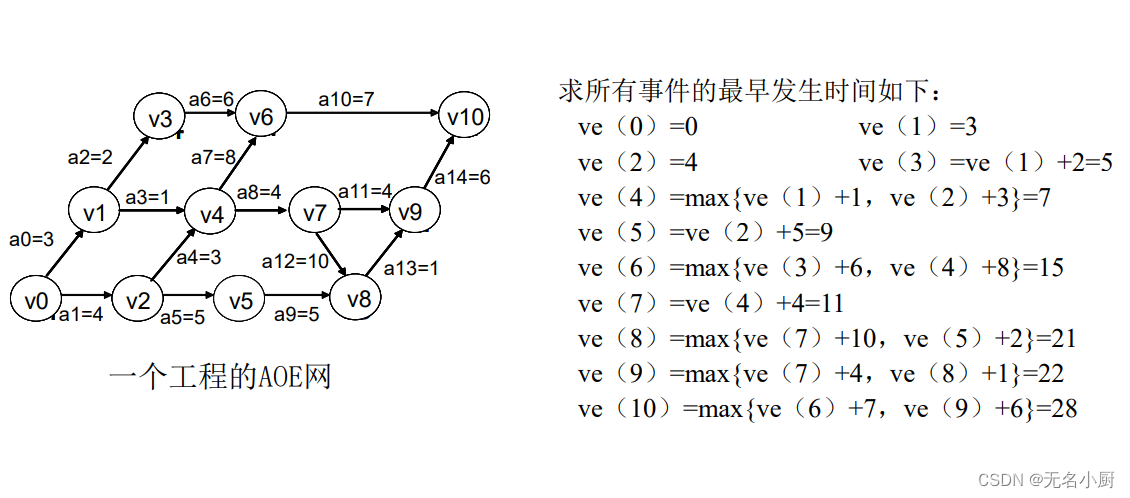
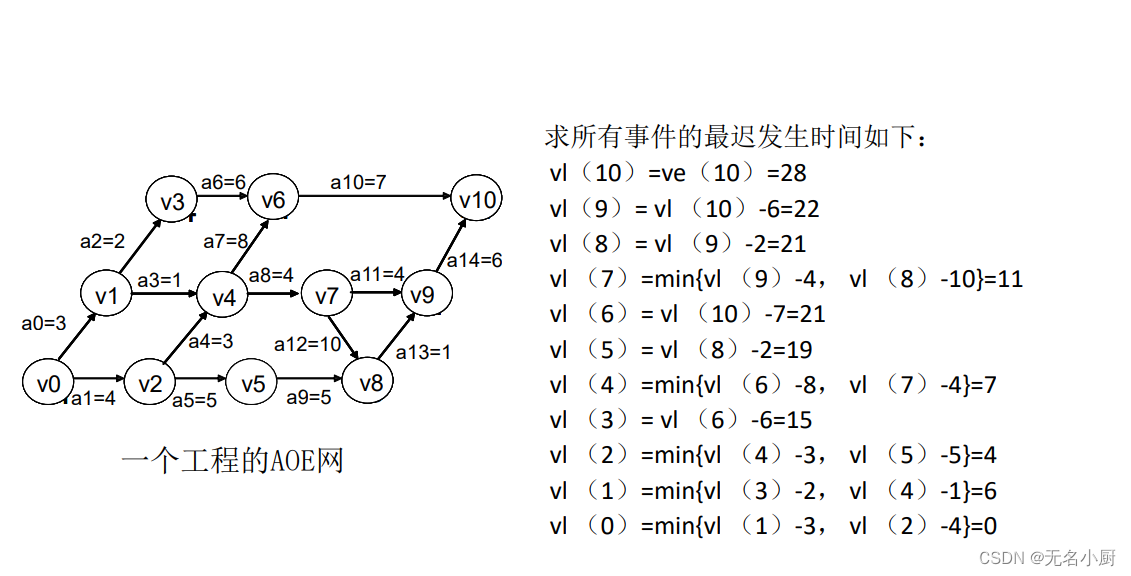
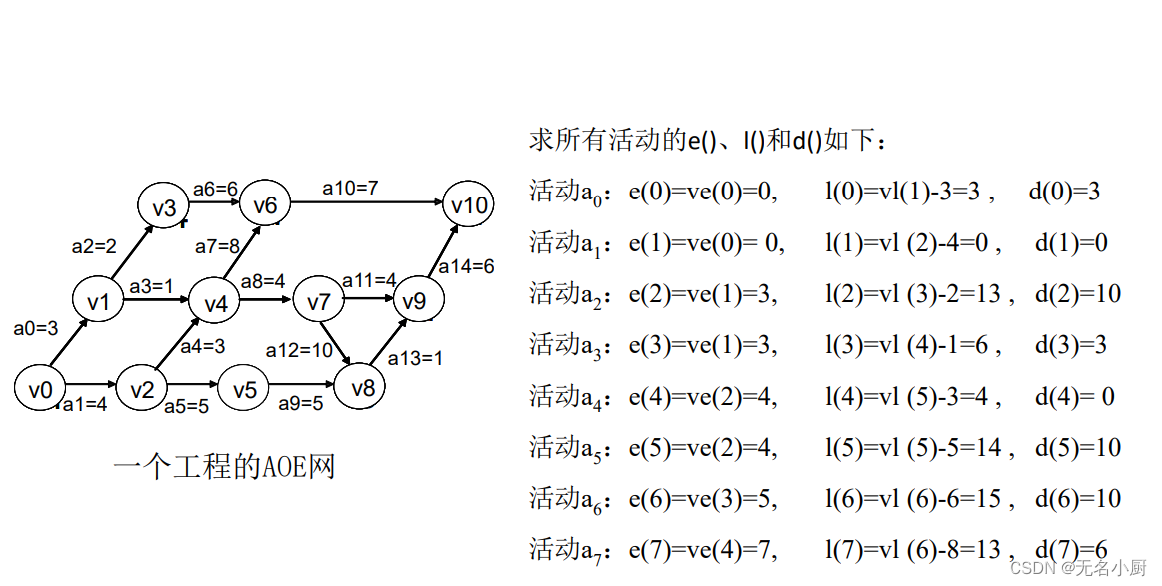
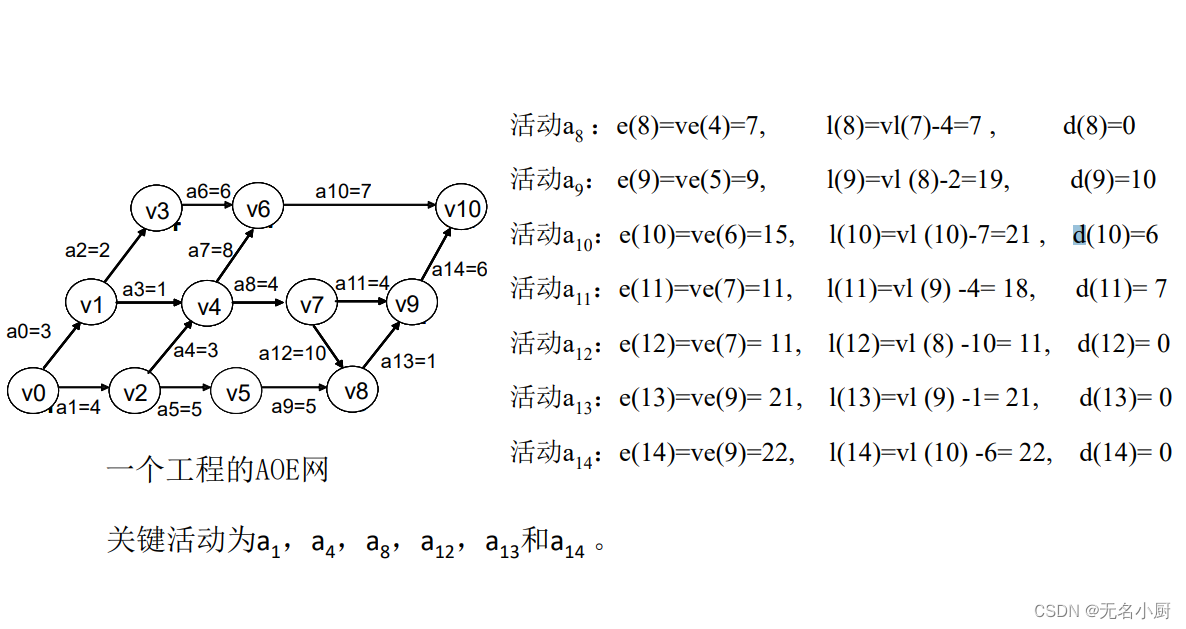
8.关键路径

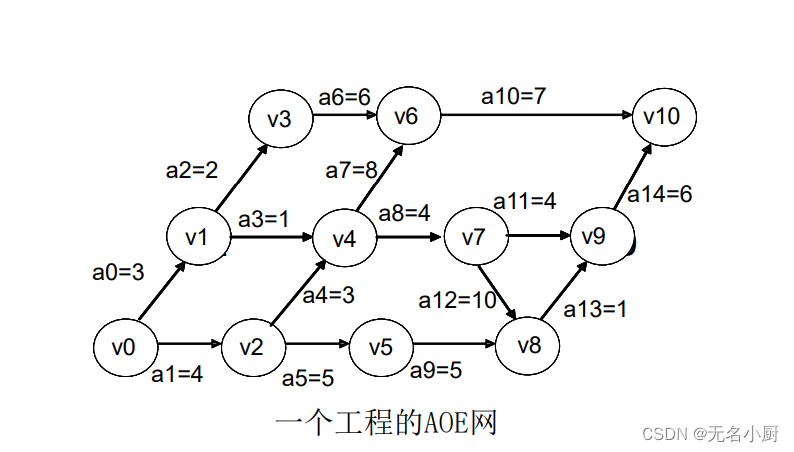 、
、



一个活动ai的最晚开始时间l(i)和其最早开始时间e(i)的差额d(i)=l(i)-e(i)是该活动完成的时间余量。它是在不增加完成整个工程所需的总时间的情况下,活动可以拖延的时间。当一活动的时间余量为零时,说明该活动必须如期完成,否则就会拖延完成整个工程的进度。所以称l(i)-e(i)=0,即l(i)=e(i)的活动ai是关键活动。
求关键路径的过程如下:
(1)求AOE网中所有事件的最早发生时间ve()。
(2)求AOE网中所有事件的最迟发生时间vl () 。
(3)求AOE网中所有活动的最早发生时间e () 。
(4)求AOE网中所有活动的最迟发生时间l () 。
(5)计算AOE网中所有活动的最晚时间与最早时间的差d () 。
(6)找出所有d ()为0的活动构成关键路径。