Flink DataStream API的基本使用
文章目录
- 前言
- 1. 基本使用方法
- 2. 核心示例代码
- 3. 完成工程代码
- pom.xml
- WordCountExample
- 测试验证
- 4. Stream 执行环境
- 5. 参考文档
前言
Flink DataStream API主要用于处理无界和有界数据流 。
无界数据流是一个持续生成数据的数据源,它没有明确的结束点,例如实时的交易数据或传感器数据。这种类型的数据流需要使用Apache Flink的实时处理功能来连续地处理和分析。
有界数据流是一个具有明确开始和结束点的数据集,例如一个文件或数据库表。这种类型的数据流通常在批处理场景中使用,其中所有数据都已经可用,并可以一次性处理。
Flink的DataStream API提供了一套丰富的操作符,如map、filter、reduce、aggregations、windowing、join等,以支持各种复杂的数据处理和分析需求。此外,DataStream API还提供了容错保证,能确保在发生故障时,应用程序能从最近的检查点(checkpoint)恢复,从而实现精确一次(exactly-once)的处理语义。
1. 基本使用方法
-
创建执行环境:
每一个Flink程序都需要创建一个
StreamExecutionEnvironment(执行环境),它可以被用来设置参数和创建从外部系统读取数据的流。final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); -
创建数据流:
你可以从各种数据源中创建数据流,如本地集合,文件,socket等。下面的代码是从本地集合创建数据流的示例:
DataStream<String> dataStream = env.fromElements("hello", "flink"); -
转换操作:
Flink提供了丰富的转换操作,如
map,filter,reduce等。以下代码首先将每个字符串映射为其长度,然后过滤出长度大于5的元素:DataStream<Integer> transformedStream = dataStream.map(s -> s.length()).filter(l -> l > 5); -
数据输出:
Flink支持将数据流输出到各种存储系统,如文件,socket,数据库等。下面的代码将数据流输出到标准输出:
transformedStream.print(); -
执行程序:
将上述所有步骤放在main函数中,并在最后调用
env.execute()方法来启动程序。Flink程序是懒加载的,只有在调用execute方法时才会真正开始执行。env.execute("Flink Basic API Usage");
2. 核心示例代码
使用Flink DataStream API构建一个实时Word Count程序,它会从一个socket端口读取文本数据,统计每个单词的出现次数,并将结果输出到标准输出。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCountExample {public static void main(String[] args) throws Exception {// 1. 创建执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建数据流,从socket接收数据,需要在本地启动一个端口为9000的socket服务器DataStream<String> textStream = env.socketTextStream("localhost", 9000);// 3. 转换操作DataStream<Tuple2<String, Integer>> wordCountStream = textStream.flatMap(new LineSplitter()) // 将文本行切分为单词.keyBy(0) // 按单词分组.sum(1); // 对每个单词的计数求和// 4. 数据输出wordCountStream.print();// 5. 执行程序env.execute("Socket Word Count Example");}// 自定义一个FlatMapFunction,将输入的每一行文本切分为单词,并输出为Tuple2,第一个元素是单词,第二个元素是计数(初始值为1)public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<>(word, 1));}}}
}
3. 完成工程代码
下面是一个基于Apache Flink的实时单词计数应用程序的完整工程代码,包括Pom.xml文件和所有Java类。
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>flink-wordcount-example</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><properties><flink.version>1.13.2</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build>
</project>
WordCountExample
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCountExample {public static void main(String[] args) throws Exception {// 1. 创建执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建数据流,从socket接收数据,需要在本地启动一个端口为9000的socket服务器DataStream<String> textStream = env.socketTextStream("localhost", 9000);// 3. 转换操作DataStream<Tuple2<String, Integer>> wordCountStream = textStream.flatMap(new LineSplitter()) // 将文本行切分为单词.keyBy(0) // 按单词分组.sum(1); // 对每个单词的计数求和// 4. 数据输出wordCountStream.print();// 5. 执行程序env.execute("Socket Word Count Example");}// 自定义一个FlatMapFunction,将输入的每一行文本切分为单词,并输出为Tuple2,第一个元素是单词,第二个元素是计数(初始值为1)public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<>(word, 1));}}}
}
现在,你可以使用Maven编译并运行这个程序。在启动程序之前,你需要在本地启动一个端口为9000的Socket服务器。这可以通过使用Netcat工具 (nc -lk 9000) 或者其他任何能打开端口的工具实现。然后,你可以输入文本行,Flink程序会统计每个单词出现的次数,并实时打印结果。
测试验证
用py在本地启动一个socket服务器,监听9000端口,
python比较简单实现一个socket通信 。写一个Python来验证上面写的例子。
import socketserver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(("localhost", 9000))
server_socket.listen(1)print("Waiting for connection...")
client_socket, client_address = server_socket.accept()
print("Connected to:", client_address)while True:data = input("Enter text: ")client_socket.sendall(data.encode())
运行Flink程序和Python socket服务器,然后在Python程序中输入文本, 会看到Flink程序实时统计每个单词出现的次数并输出到控制台。
4. Stream 执行环境
开发学习过程中,不需要关注。每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
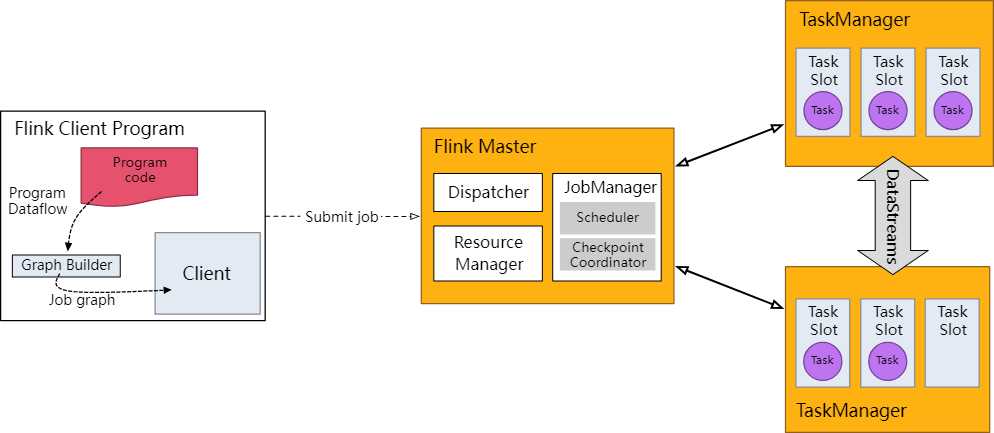
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
注意,如果没有调用 execute(),应用就不会运行。
Flink runtime: client, job manager, task managers
此分布式运行时取决于你的应用是否是可序列化的。它还要求所有依赖对集群中的每个节点均可用。
5. 参考文档
https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/learn-flink/datastream_api/