目录
一、MyBatis实现多表映射
1.1 实体类设计
1.2 一对一关系实现案例
1.3 对多配置实现案例
1.4 设置自动映射与n张表关联映射
二、MyBatis实现分页功能
2.1 mybatis插件工作原理
2.2 引入插件与插件的使用
三、逆向工程插件
3.1 什么是逆向工程
3.2 MyBatisX插件导入与使用
一、MyBatis实现多表映射
1.1 实体类设计
设计实体类首先需要知道实体类之间的关系,实体类一般关系如下:
一对一:夫妻之间的关系
一对多|多对一:教师与学生之间的关系
多对多:教师与学生之间的关系
一对一案例(订单与用户):
public class Customer {private Integer customerId;private String customerName;}public class Order {private Integer orderId;private String orderName;private Customer customer;// 体现的是对一的关系} 一对多案例(用户与订单):
public class Customer {private Integer customerId;private String customerName;private List<Order> orderList;// 体现的是对多的关系
}
public class Order {private Integer orderId;private String orderName;private Customer customer;// 体现的是对一的关系}
//查询客户和客户对应的订单集合 不要管!多表结果实体类设计小技巧:
对一,属性中包含对方对象
对多,属性中包含对方对象集合
只有真实发生多表查询时,才需要设计和修改实体类,否则不提前设计和修改实体类!
无论多少张表联查,实体类设计都是两两考虑!
在查询映射的时候,只需要关注本次查询相关的属性!例如:查询订单和对应的客户,就不要关注客户中的订单集合!
1.2 一对一关系实现案例
使用上述关系,用户与订单关系
在数据库中创建两张表代码如下:
CREATE TABLE `t_customer` (`customer_id` INT NOT NULL AUTO_INCREMENT, `customer_name` CHAR(100), PRIMARY KEY (`customer_id`) );CREATE TABLE `t_order` ( `order_id` INT NOT NULL AUTO_INCREMENT, `order_name` CHAR(100), `customer_id` INT, PRIMARY KEY (`order_id`) ); INSERT INTO `t_customer` (`customer_name`) VALUES ('c01');INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o1', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o2', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o3', '1'); 注意:
实际开发时,一般在开发过程中,不给数据库表设置外键约束。 原因是避免调试不方便。 一般是功能开发完成,再加外键约束检查是否有bug。
实体类中创造上述两个对应的类与接口。
接口如下:
public interface OrderMapper {
// 根据id查询订单与用户的信息public Order selectOrderWithCustomer(Integer orderId);
}
而实现这个功能的sql语句如下:
select * from t_customer c join t_order oon c.customer_id = o.customer_idwhere order_id = 1
# 其中order_id结果为方法中查询的参数id可以看到结果如下:

下一步需要实现结果集对应,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--此处的namespace修改为对应的接口全类名-->
<mapper namespace="com.alphamilk.mapper.OrderMapper">
<!-- 接口中业务方法public Order selectOrderWithCustomer(Integer orderId);--><resultMap id="orderInfoById" type="com.alphamilk.pojo.Order">
<!-- 设置主键--><id column="order_id" property="orderId"/>
<!-- 设置一般属性与列表对应--><result column="order_name" property="orderName"/><result column="customer_id" property="customerId"/>
<!-- 通过association标签进行关联其中property填入对象属性名javaType填入对象类型
--><association property="customer" javaType="com.alphamilk.pojo.Customer">
<!-- customer的主键--><id column="customer_id" property="customerId"/><result column="customer_name" property="customerName"/></association></resultMap><select id="selectOrderWithCustomer" resultMap="orderInfoById">
# 填入对应sql语句select * from t_customer c join t_order oon c.customer_id = o.customer_idwhere order_id = #{id}</select>
</mapper>列表结果与实体集之间的对应如下:
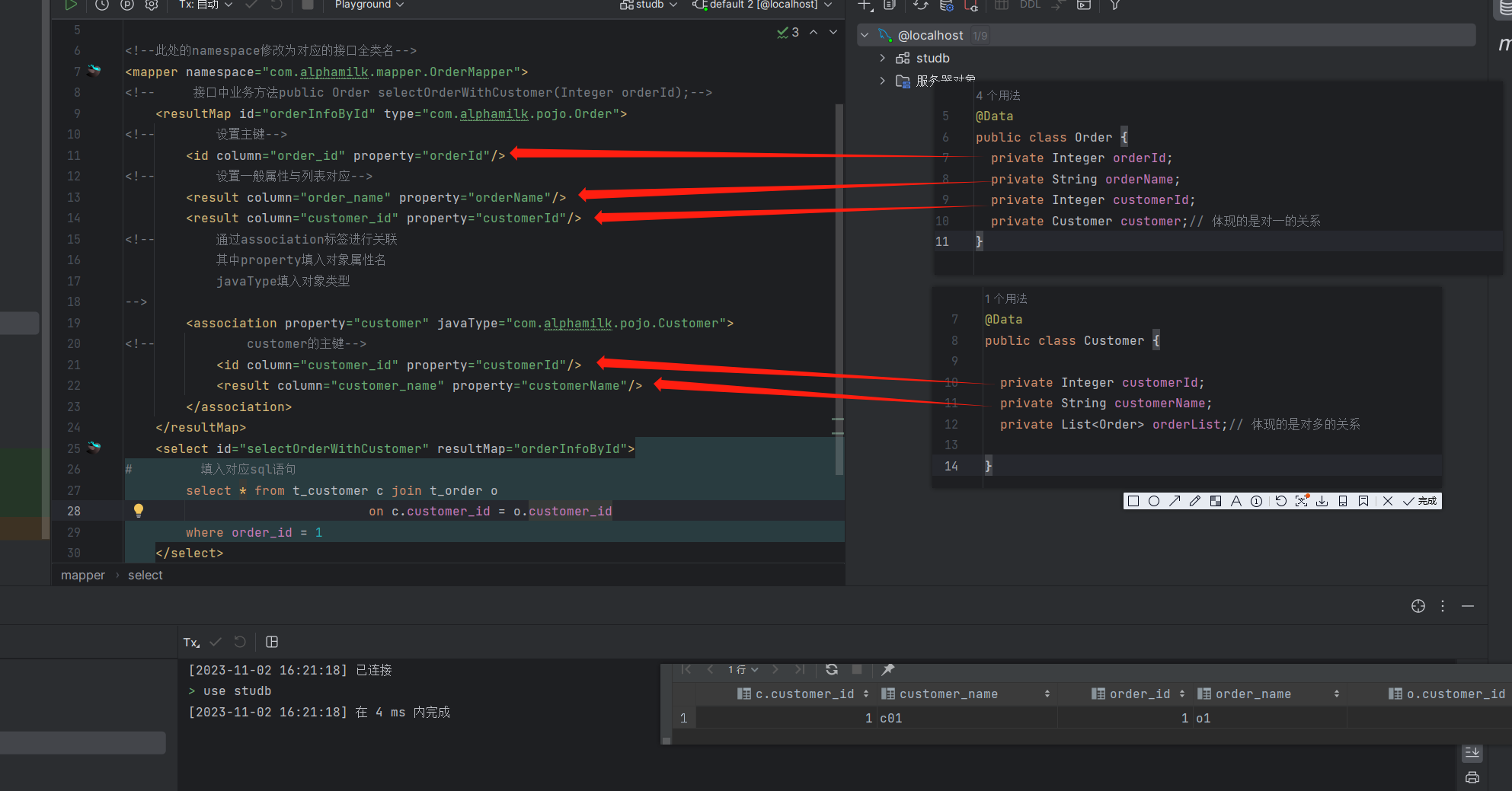
注意:做完这些后需要在mybatis配置中将对应的mapper文件导入其中
<mappers>
<!-- 此处的mapper标签使用配置里的UnderGraduate.xml的路径-->
<!-- <mapper resource="mappers/UnderGraduateMapper.xml"/>--><mapper resource="mappers/OrderMapper.xml"/></mappers>进行测试:
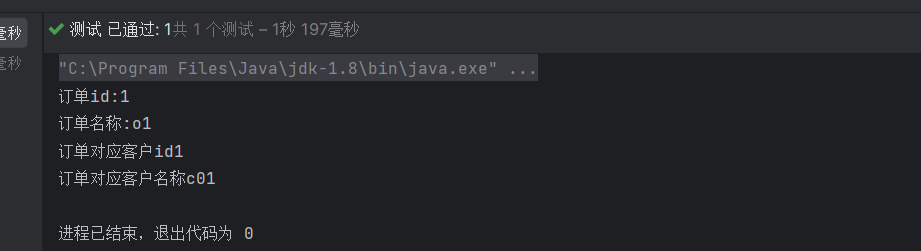
public class CRUDTEST {private SqlSession session;@BeforeEachpublic void init() throws IOException {session = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml")).openSession();}@Testpublic void Test() throws IOException {OrderMapper mapper = session.getMapper(OrderMapper.class);Order order = mapper.selectOrderWithCustomer(1);System.out.println("订单id:"+order.getOrderId());System.out.println("订单名称:"+order.getOrderName());System.out.println("订单对应客户id"+order.getCustomerId());System.out.println("订单对应客户名称"+order.getCustomer().getCustomerName());}@AfterEachpublic void clear(){session.commit();session.close();}
}
总结(关键字):
关键词
在“对一”关联关系中,我们的配置比较多,但是关键词就只有:association和**javaType
1.3 对多配置实现案例
在案例中,客户与订单之间的关系是对多的,即一个客户有多个订单信息。现在业务需求是通过客户id查询所有客户信息与订单信息。
客户实体类设计
@Data
public class Customer {private Integer customerId;private String customerName;// 对多关系,只需要创建对应的链表即可,泛型使用对应类private List<Order> orderList;}业务方法对应的sql语言
select * from t_customer c join t_order owhere c.customer_id = 1;
业务对应的接口
public interface CustomerMapper {
//业务:根据客户id查询其订单public List<Customer> CUSTOMERAndOrder(Integer id);
}接口对应的映射实现
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--此处的namespace修改为对应的接口全类名-->
<mapper namespace="com.alphamilk.mapper.CustomerMapper"><!-- 自定义结果集-->
<resultMap id="customerAndOrder" type="com.alphamilk.pojo.Customer"><id column="customer_id" property="customerId"/><result column="customer_name" property="customerName"/><!-- 通过collection实现集合赋值--><collection property="orderList" ofType="com.alphamilk.pojo.Order"><id column="order_id" property="orderId"/><result column="order_name" property="orderName"/><result column="customer_id" property="customerId"/>
<!-- 注意:里面的customer不需要赋值--></collection>
</resultMap><!-- public Customer CUSTOMERAndOrder(Integer id);--><select id="CUSTOMERAndOrder" resultMap="customerAndOrder">select * from studb.t_customer c join studb.t_order owhere c.customer_id = #{id};</select>
</mapper>功能测试:
@Testpublic void Test() throws IOException {CustomerMapper mapper = session.getMapper(CustomerMapper.class);List<Customer> customers = mapper.CUSTOMERAndOrder(1);for (Customer customer :customers){List<Order> orderList = customer.getOrderList();System.out.println("用户"+customer.getCustomerName()+"订单信息如下");for (Order order : orderList){System.out.println(order);}}}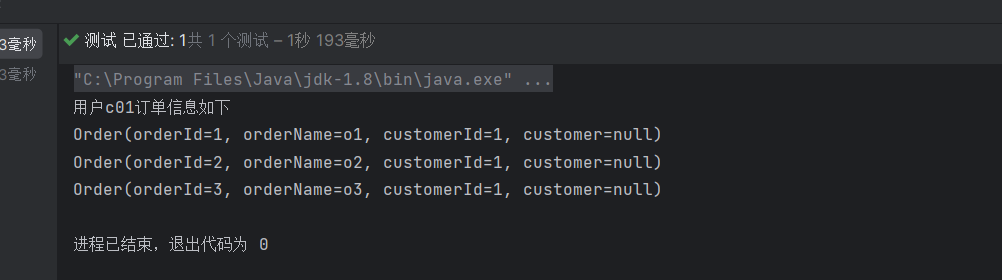
1.4 设置自动映射与n张表关联映射
在经过sql语句结果集的对应过程中可以发现,结果集的对应是一个十分重复且繁琐的工作(表单的属性十分多的情况下),那么有没有能够解放双手简化代码的方法呢?答案是肯定的。
在Mybatis-config设置中进行设置
<settings>
<!-- 设置自动映射,有没有嵌套都会自动帮我们进行映射result标签的属性与列--><setting name="autoMappingBehavior" value="FULL"/></settings>
下面介绍如何使用与注意事项
在设置好自动映射后,只需要设置好对应的主键即可正常运行。
上面两个案例,在开启自动映射后代码如下
对一映射关键代码如下:
<!-- 自定义结果集-->
<!-- 接口中业务方法public Order selectOrderWithCustomer(Integer orderId);--><resultMap id="orderInfoById" type="com.alphamilk.pojo.Order">
<!-- 设置order主键--><id column="order_id" property="orderId"/><association property="customer" javaType="com.alphamilk.pojo.Customer">
<!-- 设置customer的主键--><id column="customer_id" property="customerId"/></association></resultMap>注意:
直接使用自动映射有一个前提要求,那就是需要类中的属性名要与列表中的列名称一一对应才行。否则无法自动映射成功。如果在设计实体类和数据库名称不对应的情况下,可以通过起别名的方式进行自动映射。
数据库列名与类属性名不一致情况下的结果:

二、MyBatis实现分页功能
2.1 mybatis插件工作原理
问题引出:
由于前端页面的限制,如果返回的数据量十分庞大,前端可能无法进行数据有效展示,这时候就需要用到分页功能。
想要实现分页功能需要 了解mybatis与插件的工作机制。
程序员在写完sql语句后交给mybatis处理sql语句。而mybatis处理过程中可以引入插件,插件的作用就是可以在写过的sql语句上进行一些特殊的修改。分页插件就是对原本的sql语句进行修改。
想要实现sql语句实现分页功能,只需要使用关键字limit x , y( 其中x为偏移量,y为查询数量)如下案例:
SELECT * FROM your_table
LIMIT 20, 10
其中:x , y遵循以下等式(page 为页数,pageSize为页容量)
x = (page-1)*pageSize
y = pageSize
所以引入的插件,就是动态得帮助我们输入的sql语句上加上limit 对应的x , y.
但是请注意:
1.不需要自行添加limit结尾。
2.写的sql语句代码不能用“ ;” 结尾,因为插件会在分号后面加上limit关键字导致sql报错
2.2 引入插件与插件的使用
这里使用插件名称为pageHelper。
1.首先需要导入对应的依赖,依赖如下:
<!-- 实现mybatis分页插件--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.11</version></dependency>2.在Mybatis-config.xml里面进行配置插件
<plugins><plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 声明拦截的语言是mysql--><property name="helperDialect" value="mysql"/></plugin></plugins>3.插件使用
业务接口与实现的映射都按照原来即可,有区别的在于测试时候,如下案例代码
查询所有大学生信息:
// TODO:注意使用分页插件的sql语句不能以 分号(;)结尾!!!
// 查询所有数据@Select("select * from undergraduate.undergraduate")public List<UnderGraduate> selectAll();使用插件测试代码:
@Testpublic void Test4() {UnderGraduateMapper mapper = session.getMapper(UnderGraduateMapper.class);// TODO:注意,如果想要进行两条查询语句进行分页,那么不能放在同一个分页区。需要重新启动!// 开启分页插件,第一次查询总条数PageHelper.startPage(1, Integer.MAX_VALUE);List<UnderGraduate> totalList = mapper.selectAll();PageInfo<UnderGraduate> totalPageInfo = new PageInfo<>(totalList);// 第二次查询,获取想要的分页信息,一般由前端提供,这里参数表明当前第1页,一页容量为2个大学生成员PageHelper.startPage(1, 2);List<UnderGraduate> list = mapper.selectAll();PageInfo<UnderGraduate> pageInfo = new PageInfo<>(list);// 输出信息System.out.println("list = " + list);System.out.println("total = " + totalPageInfo.getTotal());System.out.println("pages = " + pageInfo.getPages());System.out.println("hasNextPage = " + pageInfo.isHasNextPage());System.out.println("hasPreviousPage = " + pageInfo.isHasPreviousPage());}
注意:
需要在查询语句开始之前就开启pageHelper插件进行拦截即这段代码
PageHelper.startPage(1, Integer.MAX_VALUE);
三、逆向工程插件
3.1 什么是逆向工程
所谓逆向工程,举一个通俗的例子,根据一个人的影子来画出一个人大致的轮廓。这就是所谓的逆向。在Java工程中,由于数据库每一张表都要对于一个Java的实体类。而构造实体类又需要花费大量的时间,所以就有了逆向工程,根据一个数据库的表,反向创建对应的实体表。
在MyBatis中有一些插件就是实现数据库表单逆向创建实体类的功能,比如MyBatisX插件。在介绍MyBatisX插件的使用前,先介绍MyBatisX插件的工作原理。
- 数据库反向生成 XML 配置文件
MyBatisX 会通过 JDBC 连接到数据库,然后自动读取数据库中的表、字段、约束等信息,并按照指定的模板格式生成对应的XML配置文件。
- 解析 XML 配置文件并生成 Java 类
MyBatisX 会读取之前生成的XML配置文件,解析其中的信息,并使用 Velocity 等相关技术将其转换成Java类、Mapper接口、XML映射文件等相关代码。
- 将生成的代码写入磁盘并导入到项目中
MyBatisX 会将生成的 Java 代码、XML映射文件等写入到指定目录下,同时更新项目的配置文件,以便自动扫描并引入生成的代码。
总的来说,MyBatisX 的工作原理是利用反射机制和代码模板生成技术,通过数据库和 XML 配置文件的交互,实现自动生成 MyBatis 相关的映射文件、POJO 类等代码的功能。这样,可以避免手动编写繁琐的代码,提高开发效率和代码质量。
3.2 MyBatisX插件导入与使用
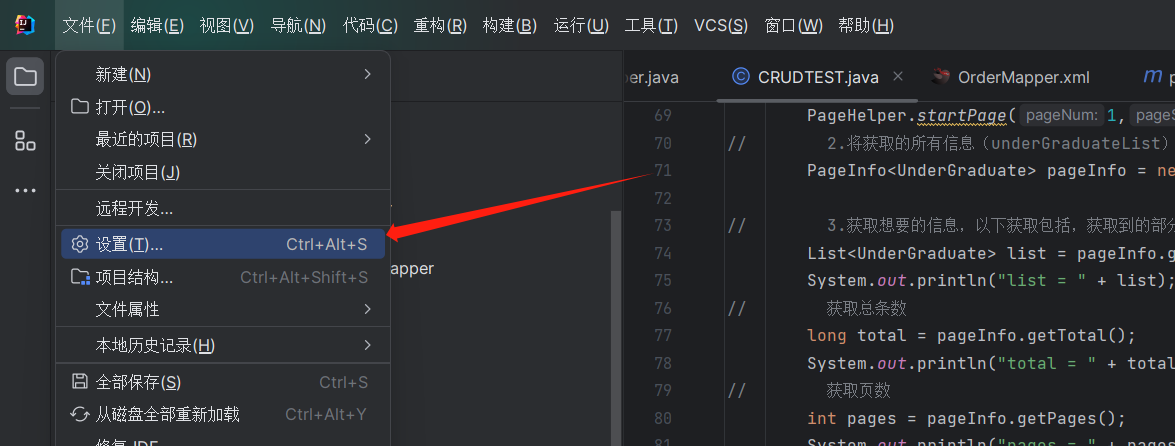
1.找到设置
2.找到插件,输入MybatisX,安装即可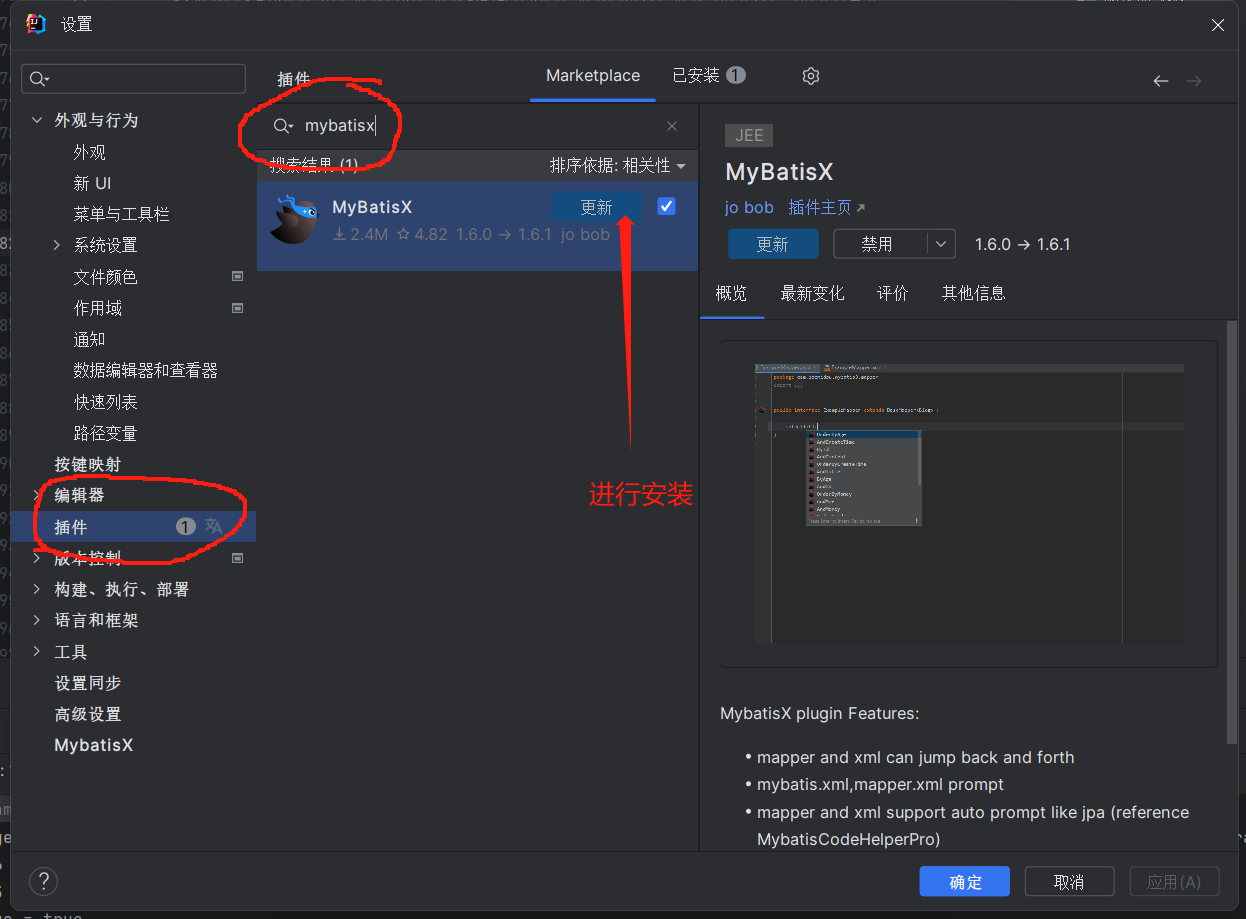
安装好了,那么如何使用呢?
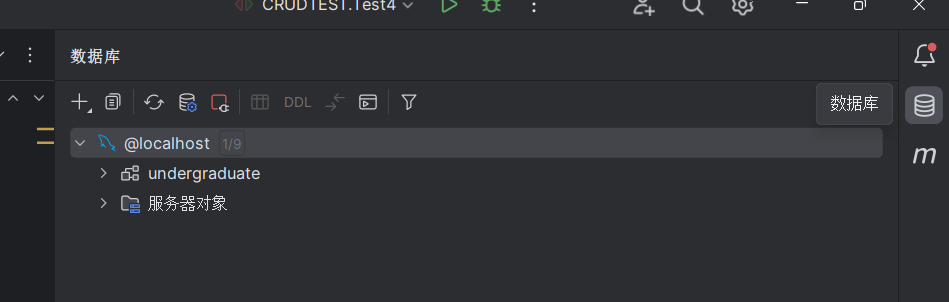
1.首先需要idea连接上mysql数据源,在idea右侧数据库中进行连接,如果已经连接上数据库则可以跳过。
2.如果没有连接上数据库,则在栏中添加MySQL数据库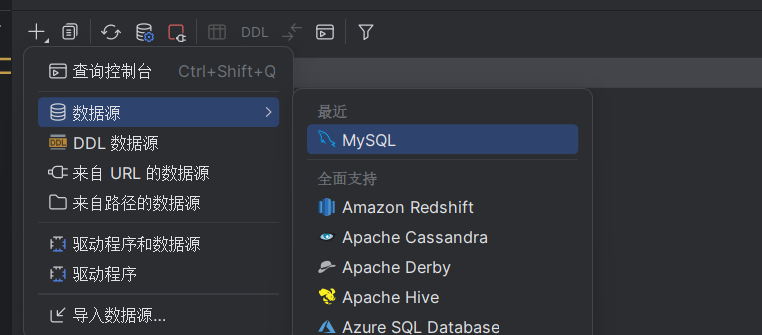
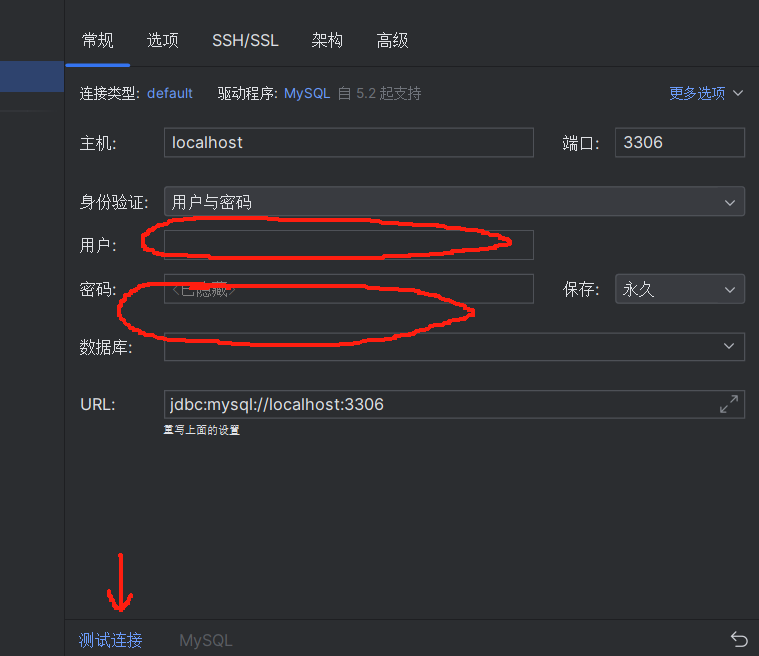
填写对应用户与密码后测试连接,若提示连接成功即可
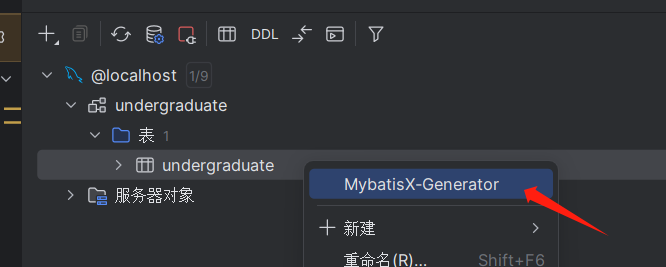
 3.连接好后选择对应架构之后,在架构对应的表下右键即可看到插件
3.连接好后选择对应架构之后,在架构对应的表下右键即可看到插件
选择图中勾选选项,最后进行finish即可创建对应的实体类。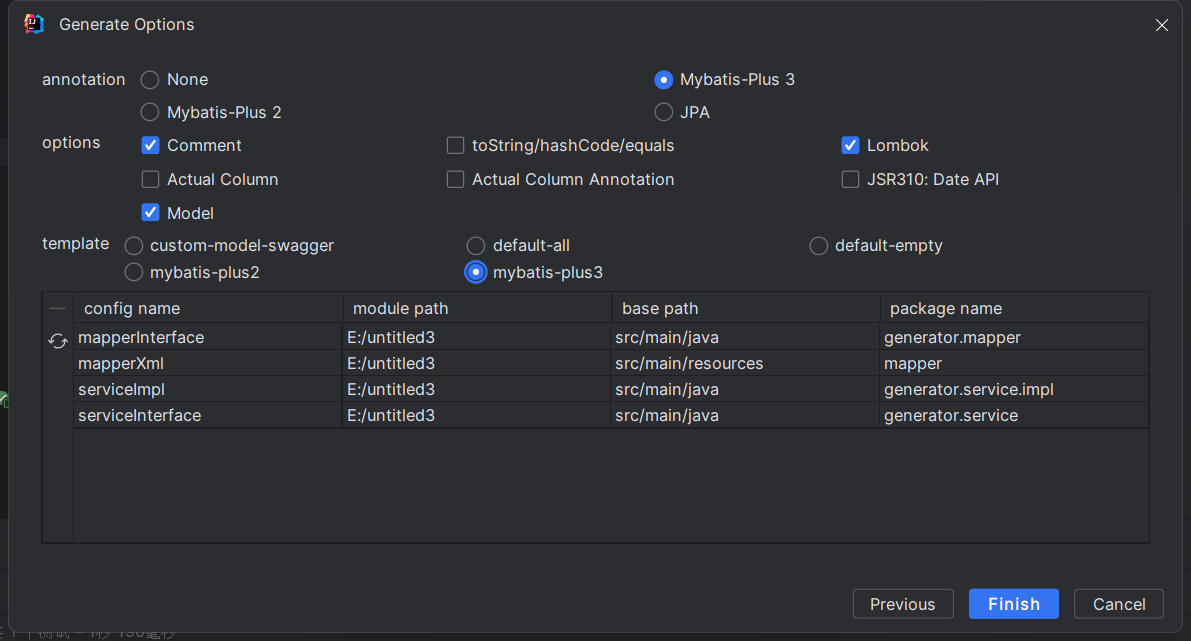





![[PyTorch][chapter 60][强化学习-2-有模型学习2]](https://img-blog.csdnimg.cn/e2940d3688c4468fba7cd927f4c1782e.png)