1、简介
在本单元中,将学习以下内容:
- 使用遥感传感器捕获的不同类型的能量。
- 如何构建 JavaScript 字典和列表以选择单个栅格波段。
- 如何可视化多波段和单波段栅格的不同组合。
2、背景
在您探索如何将 Google 地球引擎和遥感数据集成到您的研究中时,视觉解释图像的能力是一项重要的技能。虽然许多算法旨在自动提取和分类图像,但在模式和特征识别方面,计算机根本不如人脑先进。这意味着您经常需要手动识别图像中的要素,不仅是为您自己,而且为您的顾问、项目合作伙伴或其他利益相关者。在 Google 地球引擎中有效传达这些信息的能力最终取决于您可视化和解释栅格数据集的能力。尽管您在这些系列的学习单元中的学习环境是 Google Earth Engine 界面,
被动与主动数据收集
光学传感器依赖于收集反射的太阳能,被描述为“被动”。很多时候,来自无源传感器的数据将被格式化为多波段栅格,允许不同的组合。这些组合使我们能够突出景观中的环境特征。相比之下,发射和测量自身能量的传感器(例如 LiDAR、SAR)通常被称为“有源”。在 Google 地球引擎中,您不会找到来自主动传感器的大量原始数据。相反,衍生产品(例如数字高程图)很容易获得,但通常缺乏被动收集图像的多波段结构。
有源和无源传感器通常具有不同的任务目标和相关的数据产品 - 作为 Google 地球引擎用户,您可以为独特的生态应用程序操纵他们的数据。
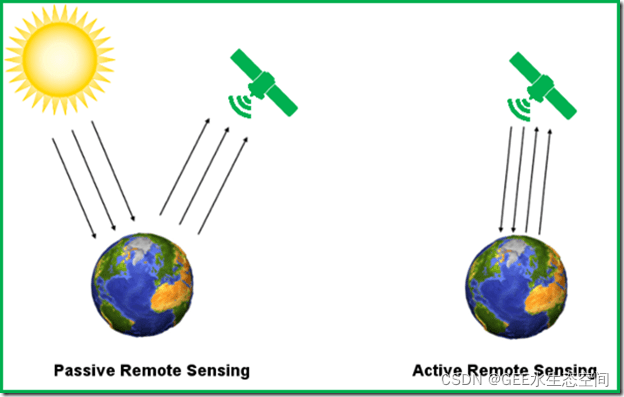
从天基传感器收集被动与主动数据的可视化。图片来源:GrindGIS。
电磁波谱
为了更深入地了解被动收集的图像,讨论电磁波谱 (EMS) 是一个好主意。从广义上讲,EMS 是能量波长的范围。在遥感的背景下,我们会遇到这种能量的一小部分,这些能量在从太阳发出后,由于大气中的窗户而通过特定范围过滤吸收能量很少的地方。在这些窗口内是我们通常在遥感中使用的波长。多年来,已经发现特定的波长范围与物理环境的元素相对应,例如植被、水和人造物体。在本单元中,您将找到一些操作这些波长以突出显示栅格数据和感兴趣区域中的特征的方法。这些方法详细参见 第6单元

广泛的电磁能量和形式的例子。请注意,该光谱的可见部分非常窄!图片来源:美国宇航局。
3、可视化多个波段
Google Earth Engine 可以通过多种方式定义可视化参数。第一个是在脚本中,我们可以在其中创建一个字典对象。即使您在编程上下文中不熟悉字典,但对于物理字典的概念来说,这个概念是熟悉的。例如,当您在物理词典中查找一个单词时,会有一段文字解释该单词。类似地,JavaScript 中的字典对象包含由冒号 (:) 分隔的“键”和“项目”对。在 Google 地球引擎中,您的“项目”通常是引号(“字符”)或数字(1.0)。请参阅下面的代码片段以获取几个示例。
// This is a dictionary object. It has a key and an item.
var dictionary_one = {key: 'item', term: 'value'};
var dictionary_two = {first_key: 1.1, second_key: 2.2, third_key: 3.3};
print(dictionary_one,"dict1");
print(dictionary_two, "dict2");// Occasionally, dictionary items can be lists. Lists are simply containers for multiple items.
var dictionary_with_list = {key: ['item1', 'item2', 'item3']};
print(dictionary_with_list, "dictList");
3.1真彩色 (TCI)
在本单元中,我们将使用许多数据集。在本节中,我们将导入 Landsat 8 表面反射率集合。我们将首先使用真彩色图像 (TCI) 来调查和解释加拿大蒙特利尔的景观。使用下面的代码应该会产生如下所示的图像。我们在新闻和网上遇到的许多基于空间的图像都是 TCI。通过使用 Google Earth Engine 中的 TCI,我们可以利用自己的经验和常识识别来对物体进行识别和分类。使用以下代码启动一个新脚本以生成如下所示的 TCI。
// Load the Landsat image collection.
var ls8 = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR");// Filter the collection by date and cloud cover.
var ls8 = ls8
.filterDate('2017-05-01','2017-09-30')
.filterMetadata('CLOUD_COVER','less_than', 3.0);// There are a number of keys that you can use in a visParams dictionary.
// Here, we are going to start by defining our 'bands', 'min', 'max', and 'gamma' values.
// You can think of 'gamma' essentially as a brightness level.
var ls_tci = {bands: ['B4','B3','B2'], min: 0, max: 3000, gamma: 1.4};Map.setCenter(-73.755, 45.5453, 11);
Map.addLayer(ls8, ls_tci, 'True Color');

可视化 2017 年加拿大蒙特利尔上空 Landsat 8 表面反射率数据的真彩色图像。
3.2彩色红外(CI)
将下面的代码附加到我们的脚本中,我们可以将 TCI 与彩色红外 (CI) 进行比较。使用 CI,我们可以开始区分土地覆盖类别(即森林覆盖与农田)以及类别内的条件,例如区域较深红色的更活跃的植被。再次单击运行以查看类似于下图的图像。
// Add the Color Infrared visualization.
var ls_ci = {bands: ['B5','B4','B3'], min: 0, max: 3000, gamma: [0.7, 1, 1]};
Map.addLayer(ls8, ls_ci, 'Color Infrared');

用彩色红外图像替换我们的真彩色图像,以识别加拿大蒙特利尔和周边陆地区域的活跃植被和水道区域。
3.3伪色 1 和 2 (FC1/FC2)
再一次,如果我们将下面的代码附加到我们的脚本中,我们可以将两个额外的假彩色合成 (FC1) 与我们的其他多波段图像进行比较。在水体中,对短波和长波红外波长的吸收率很高。因此,这些图像中的水体会显得很暗,而真彩色图像中一些茂密的植被也会显得很暗。FC1 中的波段组合还应突出灰色/紫色的密集城市发展区域,而休耕农田将显示为浅棕色。再次单击运行,您的地图窗口应与下图类似。
// Add the False Color 1 visualization.
var ls_fc1 = {bands: ['B6','B5','B4'], min: 0, max: 4000, gamma: 0.9};
Map.addLayer(ls8, ls_fc1, 'False Color 1');// Add the False Color 2 visualization.
var ls_fc2 = {bands: ['B7','B6','B4'], min: 0, max: 3000, gamma: 0.9};
Map.addLayer(ls8, ls_fc2, 'False Color 2');


我们使用两个不同(但相关)的假彩色图像对加拿大蒙特利尔的最终描绘,突出了农业和城市地区以及水道之间的差异。
4、可视化单波段
当我们使用来自单波段源的栅格数据时,我们将需要使用不同的地图可视化技术:调色板。调色板是我们可以在 Google 地球引擎中传达连续或分类数据的方式,但在使用调色板时了解我们的最小值和最大值很重要。请记住,我们可以通过单击“检查器”选项卡来采样值。
在共享您的数据时,如果您的受众可能是色盲,检查并查看您选择的调色板是否仍然可以解释通常是明智的。两个很好的资源是Color Brewer,您可以在其中看到不同的调色板创意,以及Colblinder,您可以在其中模拟不同的色盲条件如何影响颜色感知。
4.1连续数据
为了了解如何有效地使用调色板来解释连续数据,我们将使用来自 Landsat 的 Gross Primary Productivity 栅格。初级生产力总值在此定义为“生态系统中植物捕获的碳量”的量度。使用以下代码启动一个新脚本,以可视化美国华盛顿州喀斯喀特山脉东坡的数据。对我们来说方便的是,数据集已经过滤掉了水体和大气效应。运行脚本,您应该会看到如下图所示的图像。
通过使用这个特定的调色板,我们可以开始挑选土地管理活动。强烈的几何和/或线性特征可以指示森林采伐和农业等活动,而不规则形状通常可以是保护区(即国家森林或荒野地区)。
// Load and select the Gross Primary Production (GPP) image collection.
var dataset = ee.ImageCollection('UMT/NTSG/v2/LANDSAT/GPP').filter(ee.Filter.date('2018-05-01', '2018-10-31'));
var gpp = dataset.select('GPP');// Build a set of visualization parameters and add the GPP layer to the map.
var gppVis = {min: 0.0,max: 500.0,palette: ['ffffe5','f7fcb9','d9f0a3','addd8e','78c679','41ab5d','238443','005a32']};Map.setCenter(-120.9893, 47.2208, 10);
Map.addLayer(gpp, gppVis, 'GPP');
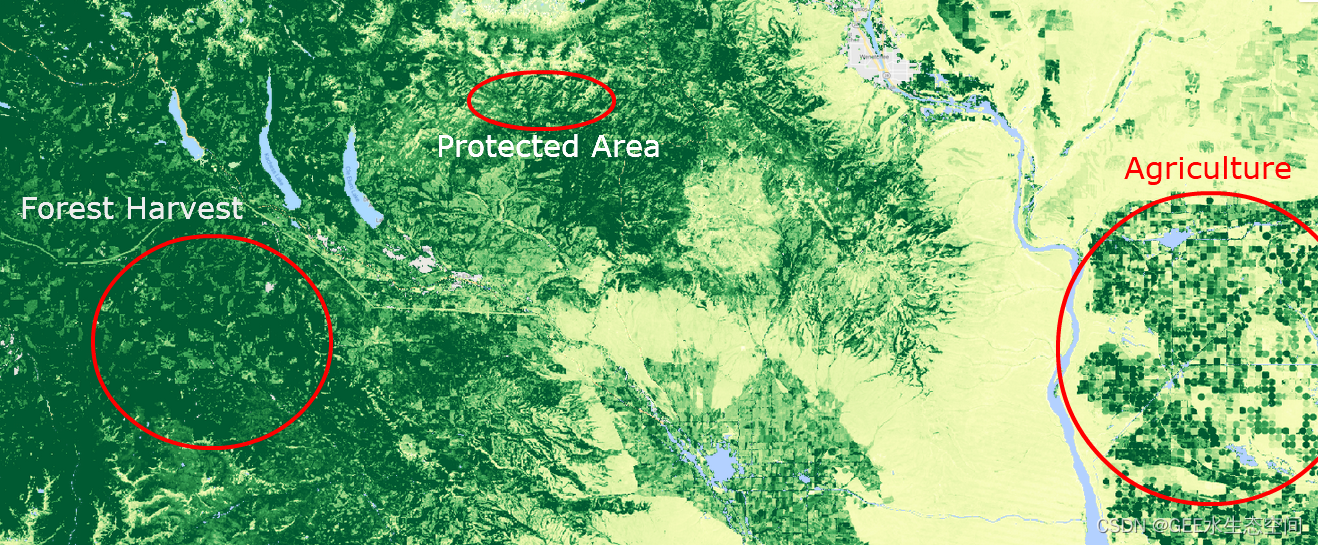
可视化美国华盛顿州喀斯喀特山脉东坡的总初级生产力(来自 Landsat 数据),其中多种土地用途以红色突出显示。
4.2分类数据
我们还可以使用调色板来突出显示分类数据。如果我们想在研究区域创建森林/非森林掩膜,我们可以使用国家土地覆盖数据集NLCD以深绿色突出显示所有森林类别。NLCD 中有许多土地覆盖类别,但为了简化此示例,我们仅在东部瀑布的同一区域使用“落叶林”、“常绿林”和“混交林”。再次启动一个新脚本并粘贴下面的代码。您应该会看到类似于下图的结果图像。
// Load the NLCD image collection and select the land cover layer.
var dataset = ee.ImageCollection('USGS/NLCD');
var landcover = dataset.select('landcover');// Values from 41-43 represent explicitly defined forest types.
var landcoverVis = {min: 41.0,max: 43.0,palette: ['black','green', 'green','green','black'],opacity: 0.75
};Map.setCenter(-120.9893, 47.2208, 10);
Map.addLayer(landcover, landcoverVis, 'Landcover');

森林与非森林区域的简单二元可视化,同样位于喀斯喀特山脉的东坡,使用国家土地覆盖数据集类。
我们将在第9单元中再次处理分类数据。
5、结论
在本单元中,我们讨论了被动和主动遥感之间的差异,以及电磁光谱和构成我们所知的可见光的窄条。我们还回顾了 JavaScript 字典和列表的结构,以及如何使用它们来选择单个栅格波段。利用这些知识,我们采用了多种方法来可视化多波段和单波段图像,以有效地传达土地覆盖、土地利用和植被状态的差异。
6、单元3 的完整代码
// This is a dictionary object. It has a key and an item.
var dictionary_one = {key: 'item', term: 'value'}
var dictionary_two = {first_key: 1.1, second_key: 2.2, third_key: 3.3}
print(dictionary_one,"dict1");
print(dictionary_two, "dict2");// Occasionally, dictionary items can be lists. Lists are simply containers for multiple items.
var dictionary_with_list = {key: ['item1', 'item2', 'item3']};
print(dictionary_with_list, "dictList");// Load the Landsat image collection.
var ls8 = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR");// Filter the collection by date and cloud cover.
var ls8 = ls8
.filterDate('2017-05-01','2017-09-30')
.filterMetadata('CLOUD_COVER','less_than', 3.0);// There are a number of keys that you can use in a visParams dictionary.
// Here, we are going to start by defining our 'bands', 'min', 'max', and 'gamma' values.
// You can think of 'gamma' essentially as a brightness level.
var ls_tci = {bands: ['B4','B3','B2'], min: 0, max: 3000, gamma: 1.4};Map.setCenter(-73.755, 45.5453, 11);
Map.addLayer(ls8, ls_tci, 'True Color');// Add the Color Infrared visualization.
var ls_ci = {bands: ['B5','B4','B3'], min: 0, max: 3000, gamma: [0.7, 1, 1]};
Map.addLayer(ls8, ls_ci, 'Color Infrared');// Add the False Color 1 visualization.
var ls_fc1 = {bands: ['B6','B5','B4'], min: 0, max: 4000, gamma: 0.9};
Map.addLayer(ls8, ls_fc1, 'False Color 1');// Add the False Color 2 visualization.
var ls_fc2 = {bands: ['B7','B6','B4'], min: 0, max: 3000, gamma: 0.9};
Map.addLayer(ls8, ls_fc2, 'False Color 2');// Load and select the Gross Primary Production (GPP) image collection.
var dataset = ee.ImageCollection('UMT/NTSG/v2/LANDSAT/GPP').filter(ee.Filter.date('2018-05-01', '2018-10-31'));
var gpp = dataset.select('GPP');// Build a set of visualization parameters and add the GPP layer to the map.
var gppVis = {min: 0.0,max: 500.0,palette: ['ffffe5','f7fcb9','d9f0a3','addd8e','78c679','41ab5d','238443','005a32']};Map.setCenter(-120.9893, 47.2208, 10);
Map.addLayer(gpp, gppVis, 'GPP');// Load the NLCD image collection and select the land cover layer.
var dataset = ee.ImageCollection('USGS/NLCD');
var landcover = dataset.select('landcover');// Values from 41-43 represent explicitly defined forest types.
var landcoverVis = {min: 41.0,max: 43.0,palette: ['black','green', 'green','green','black'],opacity: 0.75
};Map.setCenter(-120.9893, 47.2208, 10);
Map.addLayer(landcover, landcoverVis, 'Landcover');