目录
- 教程来源于尚硅谷
- 1. 简介
- 1.1 概述
- 1.2 特性
- 2. 存储结构
- 2.1 数据文件(data files)
- 2.2 表快照(Snapshot)
- 2.3 清单列表(Manifest list)
- 2.4 清单文件(Manifest file)
- 2.5 查询流程分析
- 3. 与Flink集成
- 3.1 环境准备
- 3.1.1 安装Flink
- 3.1.2 启动Sql-Client
- 3.2 语法
教程来源于尚硅谷
1. 简介
1.1 概述
Iceberg是一个面向海量数据分析场景的开放表格式(Table Format)。表格式(Table Format)可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件(orc, parquet)之上。这一点与Hive有点类似,hive也是基于HDFS存储、MR/SPARK计算引擎,将数据组织成一种表格式,提供Hive Sql对数据进行处理。
但iceberg与hive还是有很大的不同,iceberg具有以下很多特性。
1.2 特性
-
实时流批一体
Iceberg上游组件将数据写入完成后,下游组件及时可读,可查询,可以满足实时场景。相对于kafka实现了存储层的持久化,但相对地会比kafka的实时性低。并且Iceberg结合Flink等计算引擎提供了流/批读接口、流/批写接口。可以在同一个流程里, 同时处理流数据和批数据,大大简化了ETL链路。 -
模式演化
Iceberg保证模式演化(Schema Evolution)是没有副作用的独立操作流程, 一个元数据操作, 不会涉及到重写数据文件的过程。
在表中Iceberg 使用唯一ID来定位每一列的信息。新增一个列的时候,会新分配给它一个唯一ID, 并且绝对不会使用已经被使用的ID。
使用名称或者位置信息来定位列的, 都会存在一些问题, 比如使用名称的话,名称可能会重复, 使用位置的话, 不能修改顺序并且废弃的字段也不能删除。 -
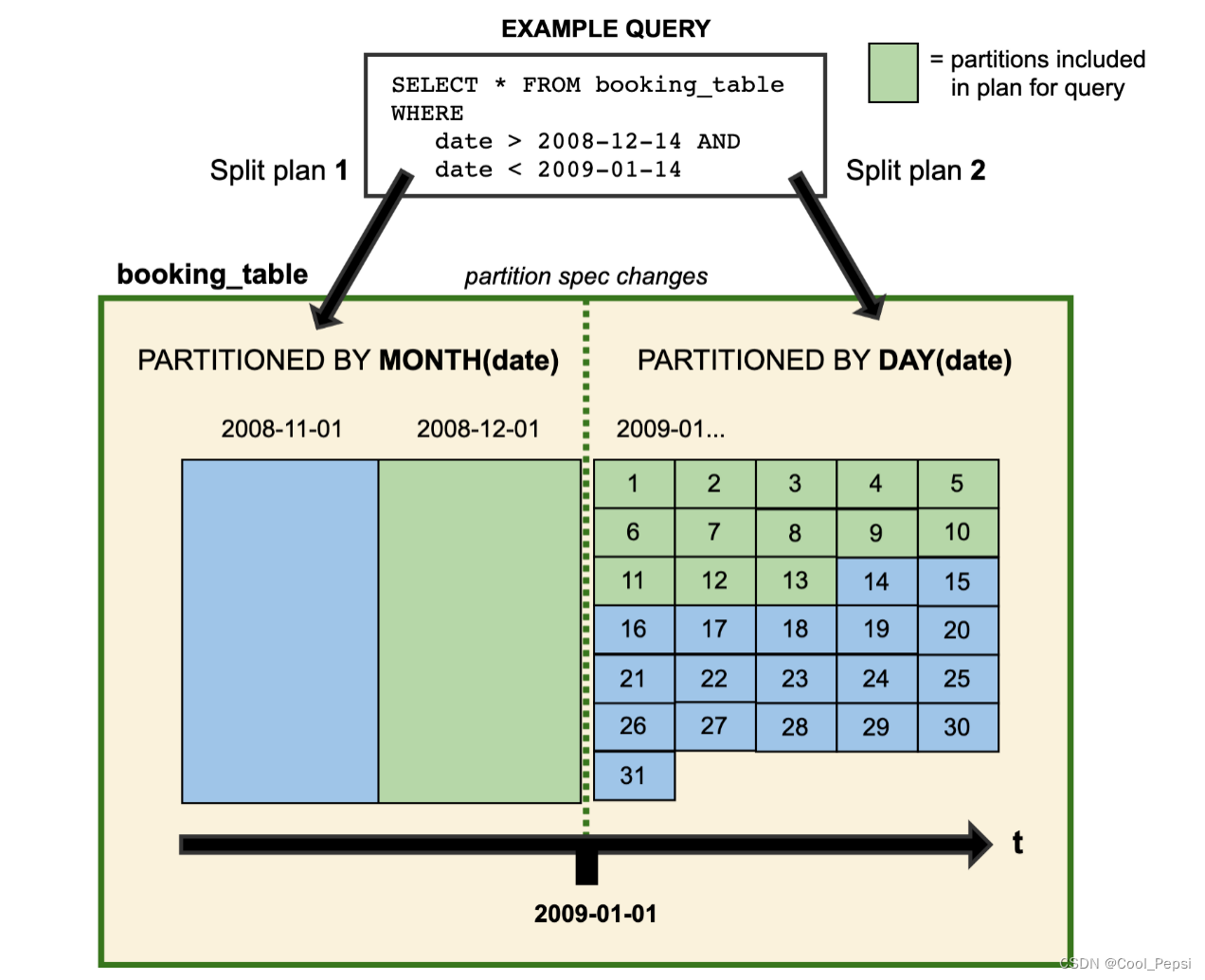
分区演化
Iceberg可以在一个已存在的表上直接修改,因为Iceberg的查询流程并不和分区信息直接关联。
当我们改变一个表的分区策略时,对应修改分区之前的数据不会改变, 依然会采用老的分区策略,新的数据会采用新的分区策略,也就是说同一个表会有两种分区策略,旧数据采用旧分区策略,新数据采用新新分区策略, 在元数据里两个分区策略相互独立,不重合。
-
隐藏分区
Iceberg的分区信息并不需要人工维护, 它可以被隐藏起来. 不同其他类似Hive 的分区策略, Iceberg的分区字段/策略(通过某一个字段计算出来),可以不是表的字段和表数据存储目录也没有关系。在建表或者修改分区策略之后,新的数据会自动计算所属于的分区。在查询的时候同样不用关系表的分区是什么字段/策略,只需要关注业务逻辑,Iceberg会自动过滤不需要的分区数据。 -
时间旅行(Time Travel)
Iceberg提供了查询表历史某一时间点数据镜像(snapshot)的能力。 -
支持事务(ACID)
Iceberg通过提供事务(ACID)的机制,使其具备了upsert的能力并且使得边写边读成为可能,从而数据可以更快的被下游组件消费。通过事务保证了下游组件只能消费已commit的数据,而不会读到部分甚至未提交的数据。 -
文件级数据管理
Iceberg的元数据里面提供了每个数据文件的一些统计信息,比如分区信息、各字段最大值,最小值,Count计数等等。因此,查询SQL的过滤条件除了常规的分区,列过滤,甚至可以下推到文件级别(hive只能定位到目录级别,因为分区是以目录的形式存在的),大大加快了查询效率。
2. 存储结构
2.1 数据文件(data files)
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾。
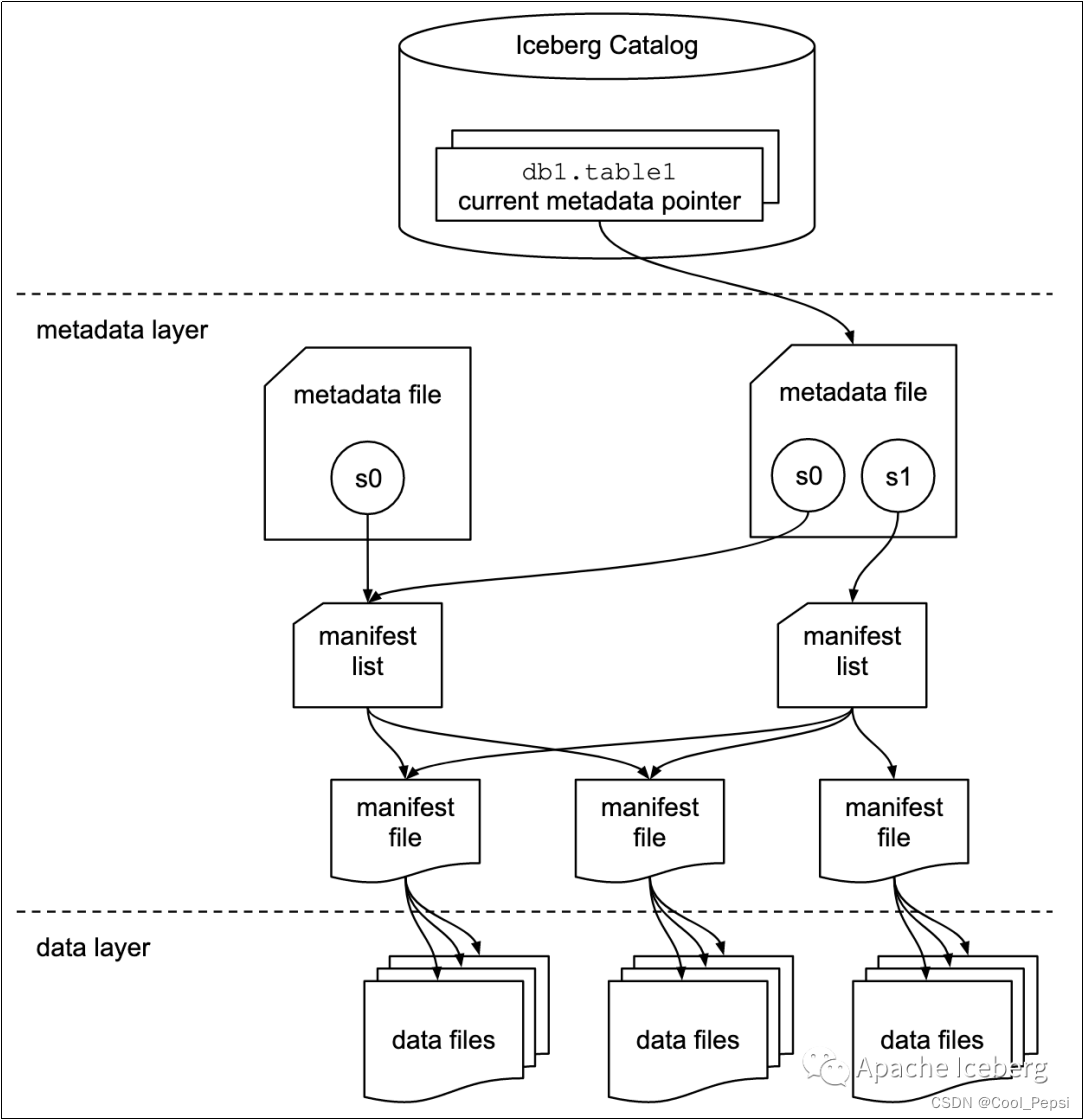
2.2 表快照(Snapshot)
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。data files是存储在不同的manifest files里面,manifest files是存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
2.3 清单列表(Manifest list)
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
2.4 清单文件(Manifest file)
Manifest file也是一个元数据文件,它列出组成快照(snapshot)的数据文件(data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
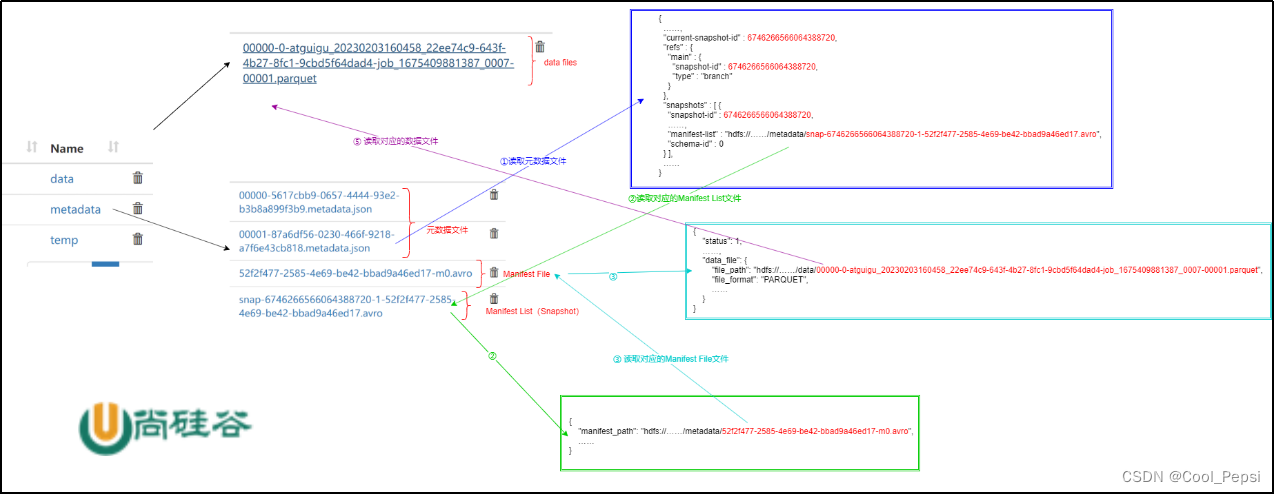
2.5 查询流程分析
- 读取元数据文件 .metadata.json,获取当前最新的快照信息,知道对应的manifest-list路径
- 读取manifest-list,获取多个manifest-flie信息路径
- 读取manifest-flie,获取具体数据文件的位置
- 读取数据文件
3. 与Flink集成
3.1 环境准备
3.1.1 安装Flink
| Flink 版本 | Iceberg 版本 |
|---|---|
| 1.11 | 0.9.0 – 0.12.1 |
| 1.12 | 0.12.0 – 0.13.1 |
| 1.13 | 0.13.0 – 1.0.0 |
| 1.14 | 0.13.0 – 1.1.0 |
| 1.15 | 0.14.0 – 1.1.0 |
| 1.16 | 1.1.0 – 1.1.0 |
| 下载对应环境的jar包 |
tar -zxvf flink-1.16.0-bin-scala_2.12.tgz -C /opt/module/
配置环境变量
sudo vim /etc/profile.d/my_env.sh
---------------------------------------------------------
export HADOOP_CLASSPATH=`hadoop classpath`
---------------------------------------------------------
source /etc/profile.d/my_env.sh
拷贝iceberg的jar包到Flink的lib目录
cp /opt/software/iceberg/iceberg-flink-runtime-1.16-1.1.0.jar /opt/module/flink-1.16.0/lib
3.1.2 启动Sql-Client
1)修改flink-conf.yaml配置
vim /opt/module/flink-1.16.0/conf/flink-conf.yamlclassloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4state.backend: rocksdb
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://localhost:8020/ckps
state.backend.incremental: true
2)local模式
vim /opt/module/flink-1.16.0/conf/workers
#表示:会在本地启动3个TaskManager的 local集群
localhost
localhost
localhost
启动
/opt/module/flink-1.16.0/bin/start-cluster.sh/opt/module/flink-1.16.0/bin/sql-client.sh embedded
3.2 语法
- 创建数据库
CREATE DATABASE iceberg_db;
USE iceberg_db;
- 创建表
CREATE TABLE `hive_catalog`.`default`.`sample` (id BIGINT COMMENT 'unique id',data STRING
);
1)创建分区表
CREATE TABLE `hive_catalog`.`default`.`sample` (id BIGINT COMMENT 'unique id',data STRING
) PARTITIONED BY (data);
Apache Iceberg支持隐藏分区,但Apache flink不支持在列上通过函数进行分区,现在无法在flink DDL中支持隐藏分区。
2)使用LIKE语法建表
LIKE语法用于创建一个与另一个表具有相同schema、分区和属性的表。
CREATE TABLE `hive_catalog`.`default`.`sample` (id BIGINT COMMENT 'unique id',data STRING
);CREATE TABLE `hive_catalog`.`default`.`sample_like` LIKE `hive_catalog`.`default`.`sample`;
- 修改表
1)修改表属性
ALTER TABLE `hive_catalog`.`default`.`sample` SET ('write.format.default'='avro');
2)修改表名
ALTER TABLE `hive_catalog`.`default`.`sample` RENAME TO `hive_catalog`.`default`.`new_sample`;
- 删除表
DROP TABLE `hive_catalog`.`default`.`sample`;
- INSERT INTO
INSERT INTO `hive_catalog`.`default`.`sample` VALUES (1, 'a');
INSERT INTO `hive_catalog`.`default`.`sample` SELECT id, data from sample2;
- INSERT OVERWRITE
仅支持Flink的Batch模式
SET execution.runtime-mode = batch;INSERT OVERWRITE sample VALUES (1, 'a');INSERT OVERWRITE `hive_catalog`.`default`.`sample` PARTITION(data='a') SELECT 6;
- UPSERT
当将数据写入v2表格式时,Iceberg支持基于主键的UPSERT。有两种方法可以启用upsert。
注意:当前虽然支持了upsert,但是做法并不优雅:例如之前是(1,’a’),插入了一条(1,’b’),是把(1,’a’)标记deleted,再新增一个数据文件,所以其实是有两个数据文件的产生,在实际生产中如果比较频繁地进行upsert是会有性能问题的。
缓解措施:调大checkpoint间隔、定时执行合并小文件&快照过期等操作
1)建表时指定
CREATE TABLE `hive_catalog`.`test1`.`sample5` (`id` INT UNIQUE COMMENT 'unique id',`data` STRING NOT NULL,PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
2)插入时指定
INSERT INTO tableName /*+ OPTIONS('upsert-enabled'='true') */
插入的表,format-version需要为2。
OVERWRITE和UPSERT不能同时设置。在UPSERT模式下,如果对表进行分区,则分区字段必须也是主键。
- Batch模式查询
SET execution.runtime-mode = batch;
select * from sample;
- Streaming模式查询
SET execution.runtime-mode = streaming;
SET table.dynamic-table-options.enabled=true;
SET sql-client.execution.result-mode=tableau;#从当前快照读取所有记录,然后从该快照读取增量数据
SELECT * FROM sample5 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;#读取指定快照id(不包含)后的增量数据
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
注意:如果是无界数据流式upsert进iceberg表(读kafka,upsert进iceberg表),那么再去流读iceberg表会存在读不出数据的问题。如果无界数据流式append进iceberg表(读kafka,append进iceberg表),那么流读该iceberg表可以正常看到结果。