目录
- 一、前言
- 二、CNN可视化解释器
- 1. 卷积层工作原理
- 三、详细步骤说明
- 1. 数据集准备
- 2.DataLoader
- 3. 搭建模型CNN
- 3.1 设置设备
- 3.2 搭建CNN模型
- 3.3 设置loss 和 optimizer
- 3.4 训练和测试循环
- 4. 模型评估和结果输出
一、前言
在上一篇笔记《【Pytorch】整体工作流程代码详解(新手入门)》中介绍了Pytorch的整体工作流程,本文继续说明如何使用Pytorch搭建卷积神经网络(CNN模型)来给图像分类。
其他相关文章:
深度学习入门笔记:总结了一些神经网络的基础概念。
TensorFlow专栏:《计算机视觉入门系列》介绍如何用TensorFlow框架实现卷积分类器。
二、CNN可视化解释器
卷积分类器,是通过将导入的图片,一层层筛选、过滤、学习图形的特征,最后实现对输入数据的分类、识别或预测。
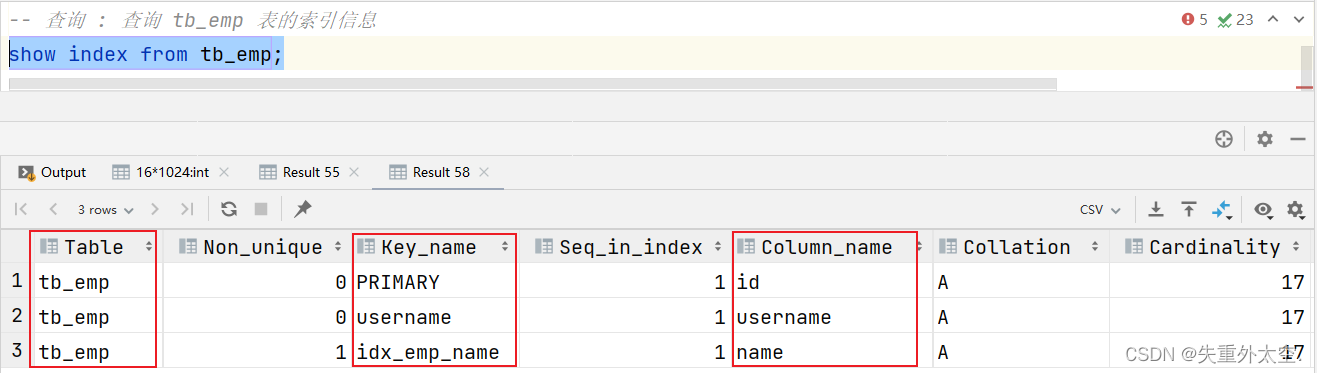
下面是github上一个CNN可交互的可视化解释器( 链接在此)。
从上面的全局图可见,CNN模型由多个卷积层和池化层交替堆叠而成,图片被进行了不同的处理,每一层都被提取出了不同的特征,最终将每个单元的输出汇总,输出分类。
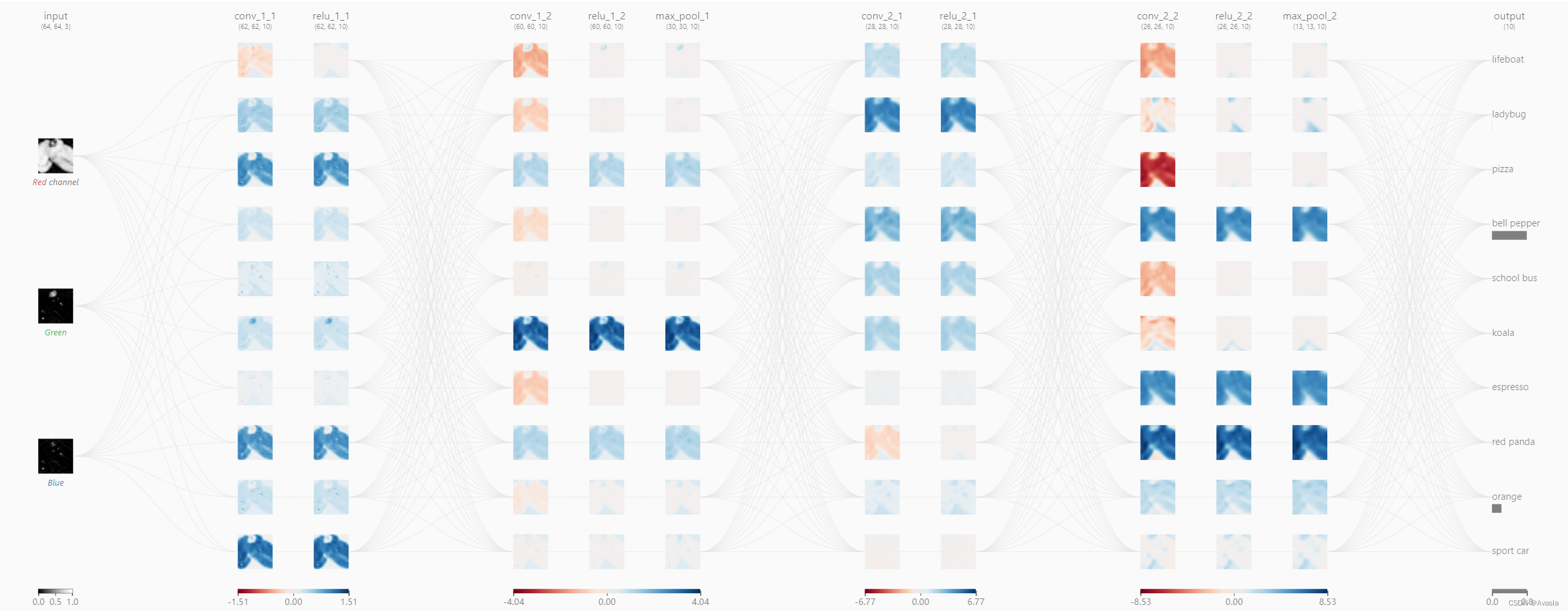
1. 卷积层工作原理
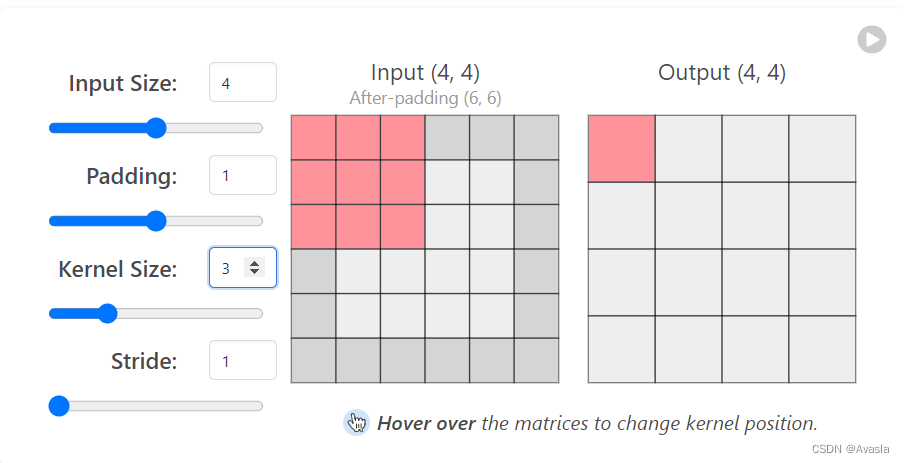
相当于是有一个滤镜格子(叫做卷积核或者滤波器),从左到右、从上至下地扫描整个输入图层,并生成新的图层。
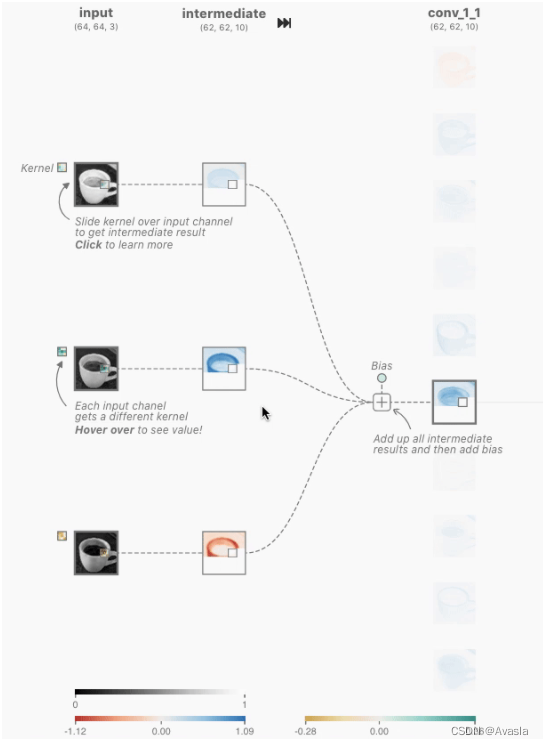
整个过程中会压缩数据,如下图所示,将一个3*3 的图形,压缩成一个格子。
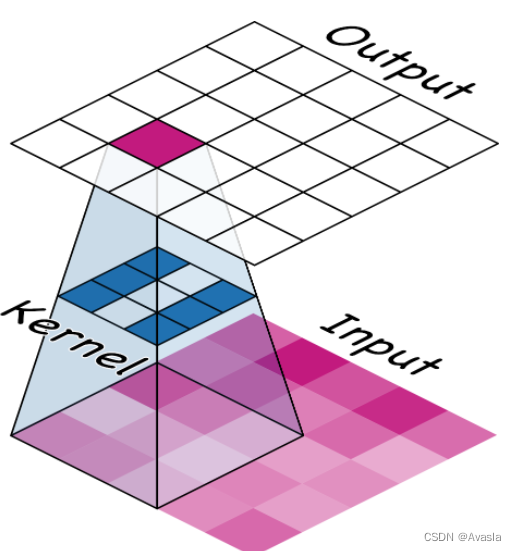
参数说明
Input输入数据,中间是一个44的格子
Padding, 外面加的一圈格子,加一个单元。
Kernel Size卷积核大小:这里是33 ,左手边的红格子
Stride 步长:卷积核每次走多少格子
三、详细步骤说明
1. 数据集准备
import torch
from torch import nn
import torchvision
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
print(f"Pytorch version:{torch.__version__}\n torchvision version:{torchvision.__version__}")

数据集介绍:
FashionMNIST是torchvision自带的一个图像数据集,用于机器学习和计算机视觉的训练和测试。它包含了10个不同类别的服装物品的灰度图像,包括T恤、裤子、套衫、裙子、外套、凉鞋、衬衫、运动鞋、包和短靴。每张图片的分辨率是28x28像素。
train_data=datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=None
)test_data=datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),target_transform=None
)#数据集查看
image, label = train_data[0]
# image, label #查看第一条训练数据
image.shape #查看数据的形状
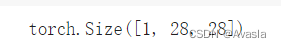
图像张量的形状是[1, 28, 28],或者说:[颜色=1,高度=28,宽度=28]
# 查看类别
class_names = train_data.classes
class_names

#图形可视化
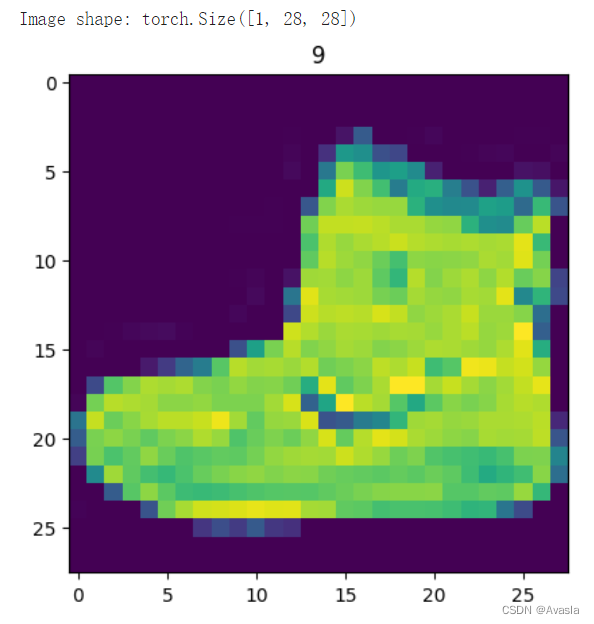
import matplotlib.pyplot as plt
image, label = train_data[0]
print(f"Image shape: {image.shape}")
plt.imshow(image.squeeze())
plt.title(label);
2.DataLoader
from torch.utils.data import DataLoader# 设置批处理大小超参数
BATCH_SIZE = 32# 将数据集转换为可迭代的(批处理)
train_dataloader = DataLoader(train_data,batch_size=BATCH_SIZE, # 每个批次有多少样本?shuffle=True # 是否随机打乱?
)test_dataloader = DataLoader(test_data,batch_size=BATCH_SIZE,shuffle=False # 测试数据集不一定需要洗牌
)#打印结果
print(f"Dataloaders: {train_dataloader, test_dataloader}")
print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}")
print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}")
参数介绍:
shuffle:指对数据集进行随机打乱,以便在训练模型时以随机顺序呈现数据。这样做有助于提高模型的泛化能力并减少模型对输入数据顺序的依赖性。相反,对于测试数据集通常被设置为False,因为在评估模型性能时,我们希望保持数据的原始顺序,以便能够正确评估模型在真实数据上的表现。
train_features_batch, train_labels_batch = next(iter(train_dataloader))
train_features_batch.shape, train_labels_batch.shape

3. 搭建模型CNN
3.1 设置设备
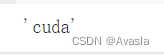
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
device
在GPU上跑。
3.2 搭建CNN模型
回顾一下CNN的参数设置:
in_channels:输入数据的通道数,对于二维卷积,表示输入图像或特征图的深度或通道数。out_channels:输出的通道数,即卷积核的数量。每个卷积核生成一个输出通道。kernel_size:卷积核的大小或滤波器的大小,用整数或元组表示,指定了卷积核的高度和宽度。kernel_size=3意味着卷积核的高度和宽度均为3。stride:卷积核滑动的步长,决定卷积核在输入数据上滑动的距离。stride=1表示卷积核在输入上每次滑动1个步长。padding:在输入数据周围填充0的层数。填充有助于保持输入和输出尺寸相同,特别是在卷积层之间传递信息时。这里的padding=1表示在输入数据周围填充一层0,以保持卷积操作后尺寸不变。
# Create a convolutional neural network
class FashionMNISTModelV2(nn.Module):def __init__(self, input_shape: int, hidden_units: int, output_shape: int):super().__init__()self.block_1 = nn.Sequential(nn.Conv2d(in_channels=input_shape,out_channels=hidden_units,kernel_size=3, stride=1,padding=1),nn.ReLU(),nn.Conv2d(in_channels=hidden_units,out_channels=hidden_units,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2) )self.block_2 = nn.Sequential(nn.Conv2d(hidden_units, hidden_units, 3, padding=1),nn.ReLU(),nn.Conv2d(hidden_units, hidden_units, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(in_features=hidden_units*7*7,out_features=output_shape))def forward(self, x: torch.Tensor):x = self.block_1(x)# print(x.shape)x = self.block_2(x)# print(x.shape)x = self.classifier(x)# print(x.shape)return x# 加入参数
torch.manual_seed(42)
model_2 = FashionMNISTModelV2(input_shape=1,hidden_units=10,output_shape=len(class_names)).to(device)
model_2

3.3 设置loss 和 optimizer
导入accurcay_fn辅助函数文件
import requests
from pathlib import Path# 从Learn PyTorch存储库中下载辅助函数(如果尚未下载)
if Path("helper_functions.py").is_file():print("helper_functions.py已存在,跳过下载")
else:print("正在下载helper_functions.py")# 注意:你需要使用"raw" GitHub URL才能使其工作request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")with open("helper_functions.py", "wb") as f:f.write(request.content)
创建loss、accuracy和optimizer
from helper_functions import accuracy_fn# 设置loss和optimizer
loss_fn = nn.CrossEntropyLoss() # this is also called "criterion"/"cost function" in some places
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1)
创建一个计时器
from timeit import default_timer as timer
def print_train_time(start:float,end:float,device:torch.device=None):total_time=end-startprint(f"Train time on {device}: {total_time:.3f} seconds")return total_time
3.4 训练和测试循环
def train_step(model: torch.nn.Module,data_loader: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,optimizer: torch.optim.Optimizer,accuracy_fn,device: torch.device = device):train_loss, train_acc = 0, 0model.to(device)for batch, (X, y) in enumerate(data_loader):X, y = X.to(device), y.to(device)y_pred = model(X)loss = loss_fn(y_pred, y)train_loss += losstrain_acc += accuracy_fn(y_true=y,y_pred=y_pred.argmax(dim=1))optimizer.zero_grad()loss.backward()optimizer.step()train_loss /= len(data_loader)train_acc /= len(data_loader)print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")def test_step(data_loader: torch.utils.data.DataLoader,model: torch.nn.Module,loss_fn: torch.nn.Module,accuracy_fn,device: torch.device = device):test_loss, test_acc = 0, 0model.to(device)model.eval() # put model in eval mode# Turn on inference context managerwith torch.inference_mode():for X, y in data_loader:X, y = X.to(device), y.to(device)test_pred = model(X)test_loss += loss_fn(test_pred, y)test_acc += accuracy_fn(y_true=y,y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels)test_loss /= len(data_loader)test_acc /= len(data_loader)print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
torch.manual_seed(42)from timeit import default_timer as timer
train_time_start_model_2 = timer()epochs = 3
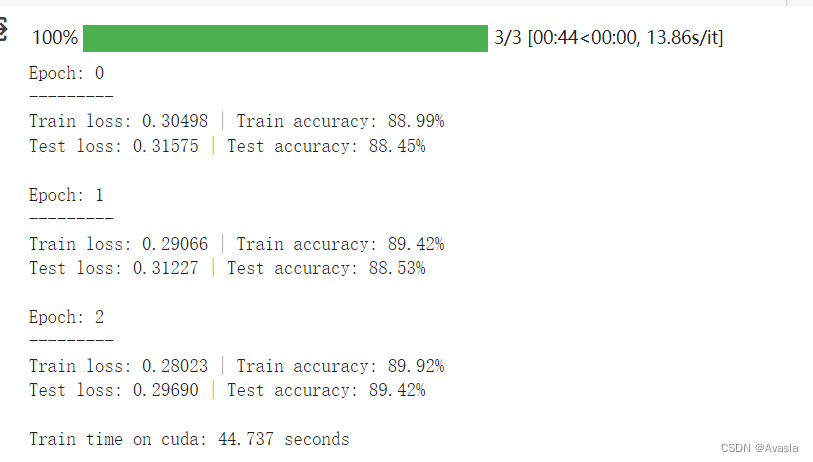
for epoch in tqdm(range(epochs)):print(f"Epoch: {epoch}\n---------")train_step(data_loader=train_dataloader,model=model_2,loss_fn=loss_fn,optimizer=optimizer,accuracy_fn=accuracy_fn,device=device)test_step(data_loader=test_dataloader,model=model_2,loss_fn=loss_fn,accuracy_fn=accuracy_fn,device=device)train_time_end_model_2 = timer()
total_train_time_model_2 = print_train_time(start=train_time_start_model_2,end=train_time_end_model_2,device=device)
4. 模型评估和结果输出
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,data_loader: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,accuracy_fn,device: torch.device = device): #注意loss, acc = 0, 0model.eval()with torch.inference_mode():for X, y in data_loader:#注意设备转移X, y = X.to(device), y.to(device)y_pred = model(X)loss += loss_fn(y_pred, y)acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1))loss /= len(data_loader)acc /= len(data_loader)return {"model_name": model.__class__.__name__, "model_loss": loss.item(),"model_acc": acc}model_2_results = eval_model(model=model_2,data_loader=test_dataloader,loss_fn=loss_fn,accuracy_fn=accuracy_fn
)
model_2_results
模型输出结果: