前言
在日常生活中,无论是网络配置、文件整理、web开发还是工具,时常用到Python写些脚本。
这次主要是分享下异步编程的经验,就拿获取girlypic的图片举例吧,也希望能给一些同学带来思考。
- 使用
argparse而不是os.args,这个库能够优雅地获取命令行参数,不再需要os.args判断个数或者类型。 - 使用
pathlib而不是os.path,这个库能够高效地处理各种文件操作,创建、修改、删除、路径拼接等。 - 使用
logging而不是print,个人更加习惯用日志的方式打印信息。 - 使用
aiohttp而不是requests,当你决定用异步的方式发送网络请求时,就用这个库吧。 - 使用
aiofiles而不是open,当你决定用异步的方式读写文件时,就用这个库吧。 - 使用
lxml,这个库能够使用Xpath语法帮助我们解析html内容。 - 使用
asyncio.create_task而不是for循环,当一组任务不是顺序相关时,不必循环await执行,通过创建任务的方式异步执行。 - 使用类型提示,标注变量的类型,方便IDE检索。
以上是常用的库或者提示,没有好坏之分,主要是看个人的习惯,一旦一处异步,那就处处异步。
Python版本
当前稳定版本是:3.10.11
Python依赖
aiohttp==3.8.6
aiofiles==23.2.1
lxml==4.9.3Python源码
import asyncio
import logging
import argparse
from pathlib import Pathimport aiohttp
import aiofiles
from lxml import etreelogger = logging.getLogger()
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(formatter)
logger.addHandler(console)PROXY = "http://127.0.0.1:10808"
SAVE_FOLDER = Path("Downloads")
PICTURE_HOST = "https://girlygirlpic.com"
PICTURE_GATHER = PICTURE_HOST + "/ax/"
PICTURE_SEARCH = PICTURE_HOST + "/sx/"
PICTURE_URL = '//div[@class="post-media-body"]//a[@class="figure-link os-lightbox-activator"]/@href'
ALBUM_NAMES = '//div[@class="post-content-body"]/h4[@class="post-title entry-title"]/a[@class="on-popunder"]'
HEADER = {"Origin": PICTURE_HOST,"Connection": "close","Cookie": "_user_language=Cn","X-Requested-With": "XMLHttpRequest","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0"
}async def download_picture(url: str, save_folder: Path) -> None:async with aiohttp.ClientSession() as session:try:async with session.get(url, proxy=PROXY, headers=HEADER) as response:picture_name = url[url.rfind("/") + 1:]async with aiofiles.open(save_folder / picture_name, "wb") as handle:async for chunk in response.content.iter_chunked(1024):await handle.write(chunk)except Exception as exception:logger.error(f"{exception} [URL] {url}")async def parse_album(url: str, save_folder: Path) -> None:album_id = url[url.rfind("/") + 1:]header = {**HEADER, **{"Referer": url}}async with aiohttp.ClientSession() as session:requests_body = {"album_id": album_id}async with session.post(PICTURE_GATHER, json=requests_body, proxy=PROXY, headers=header) as response:html_content = await response.text()image_href = etree.HTML(html_content).xpath(PICTURE_URL)logger.info(f"{len(image_href):03d} photos of album [{save_folder.name}]")task_list = [asyncio.create_task(download_picture(pic_url, save_folder)) for pic_url in image_href]await asyncio.wait(task_list) if len(task_list) > 0 else Nonelogger.info(f"album saved [{save_folder.name}]")async def get_albums(name: str) -> None:async with aiohttp.ClientSession() as session:requests_body = {"search_keys_tag": name}async with session.post(PICTURE_SEARCH, json=requests_body, proxy=PROXY, headers=HEADER) as response:html_content = await response.text()album_content = etree.HTML(html_content).xpath(ALBUM_NAMES)logger.info(f"{len(album_content):03d} albums about {name}")task_list = []for album in album_content:href = album.get("href")text = album.textsave_folder = SAVE_FOLDER / name / textsave_folder.mkdir(parents=True) if not save_folder.exists() else Nonetask_list.append(asyncio.create_task(parse_album(href, save_folder)))await asyncio.wait(task_list) if len(task_list) > 0 else Noneasync def main(names: [str]) -> None:await asyncio.wait([asyncio.create_task(get_albums(name)) for name in names])logger.info("done")if __name__ == "__main__":parser = argparse.ArgumentParser(description="download pictures")parser.add_argument("name", type=str, nargs='+', help="girls name list")args = parser.parse_args()asyncio.run(main(args.name))其中PICTURE_HOST就是域名,需要科学访问,所以PROXY自己配置吧。
运行方法很简单:python main.py xxxx xxxx xxxx,其中xxxx为姓名,多个人名按照空格隔开。
获取完毕后会在当前创建一个Downloads目录,图片会按照姓名以及相册名归类在里面。
运行结果
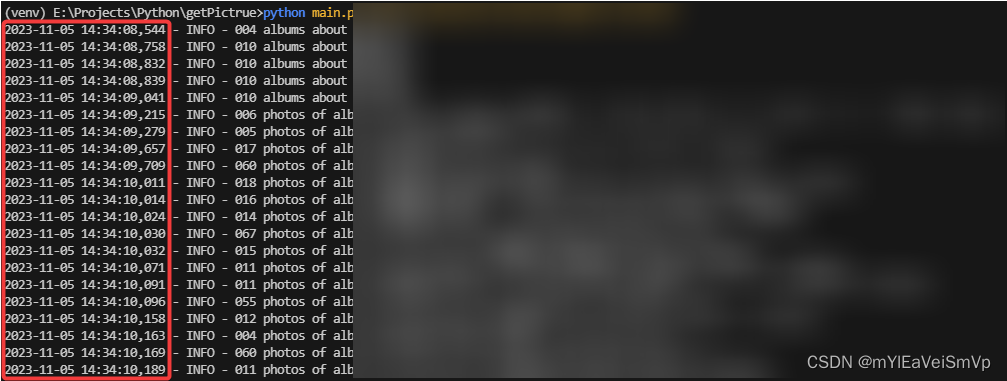
这就是异步的魅力,同步的方式只能一次发送一个请求,然后阻塞在网络IO上,异步则会在这种情况下让出CPU资源执行其他的代码。
效果图不方便放,大家可以自己试试
图片过多,访问过于频繁时,请求有可能会被BAN,所以可以适当地延迟下载任务,由于是异步,就不要用
time.sleep()了,而是要用asyncio.sleep()。
![[量化投资-学习笔记006]Python+TDengine从零开始搭建量化分析平台-MACD](https://img-blog.csdnimg.cn/a18d7d7ca1434c2c9fcf30a2da2f7072.png#pic_center)