文章目录
- 一、概述
- 二、编译准备
- 2.1 升级 make
- 2.2 安装 Python3
- 三、编译 RedisBloom
- 四、测试 RedisBloom
- 五、应用场景
- 5.1 缓存击穿
- 5.2 缓存穿透
- 5.3 原理总结
- 六、存在的问题
如果您对Redis的了解不够深入请关注本栏目,本栏目包括Redis安装,Redis配置文件说明,Redis命令和数据类型说明,Redis持久化配置,Redis主从复制和哨兵机制,Redis Cluster(集群)配置,Redis Predixy 集群,Redis Twemproxy 集群,Redis Codis 集群。
一、概述
-
RedisBloom是Redis的一个模块,用于实现布隆过滤器和其他概率数据结构。它的主要作用是帮助你在Redis中实现高效的数据查找和去重操作,特别适用于处理大规模数据集。如果你需要进行高效的成员存在性检查、去重、计数或Top-K查询等任务,RedisBloom可以是一个有用的扩展。
-
具体来说,RedisBloom 提供以下功能和作用:
- 布隆过滤器(Bloom Filter):RedisBloom支持布隆过滤器,这是一种用于快速检查一个元素是否存在于一个集合中的数据结构。布隆过滤器可以高效地判断一个元素是否“可能存在”或“一定不存在”,而不需要实际存储元素本身。这在缓存和去重等场景中非常有用。
- Count-Min Sketch:RedisBloom还支持Count-Min Sketch,这是一种概率数据结构,用于估算某个事件发生的次数。这对于计数和监控任务非常有用。
- Top-K 数据:RedisBloom支持Top-K数据结构,可以用于确定集合中最常见的元素,或者最大的N个元素。
- HyperLogLog:尽管HyperLogLog不是RedisBloom的一部分,但它通常与RedisBloom一起使用,用于估算唯一元素的数量。
-
缓存击穿:缓存击穿是指当某个缓存键过期或不存在时,大量的请求同时涌入,导致请求直接落到数据库上,增加数据库的负载。
-
缓存穿透:缓存穿透是指恶意请求发送到缓存中查询一个不存在的键,导致大量的请求直接落到数据库上,增加数据库的负载。
-
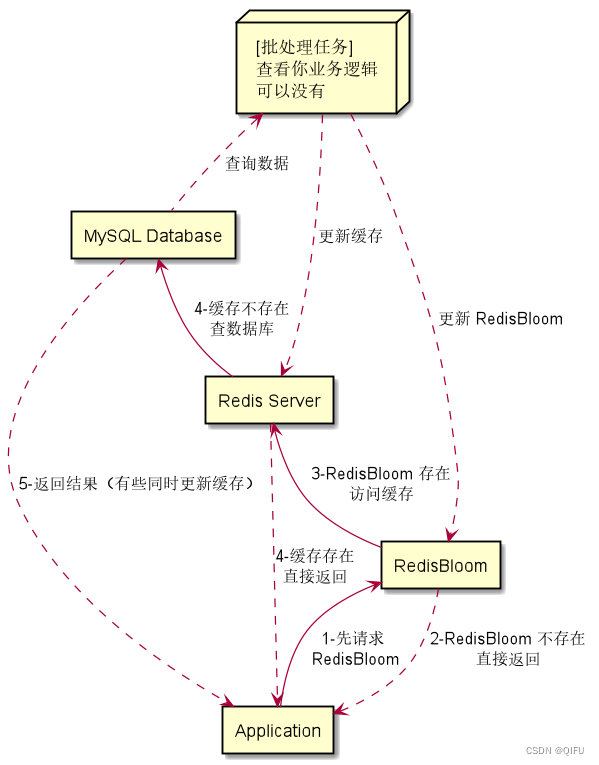
防止缓存击穿的实现逻辑:首先根据业务逻辑将已有数据同步到 RedisBloom,然后请求时先根据 RedisBloom 判断是否存,来处理击穿和穿透。但是使用RedisBloom有一个问题,就是只能增加,不能删除Key。
-
开源地址:RedisBloom
二、编译准备
- 以下CentOS 7中操作步骤
2.1 升级 make
-
编译 RedisBloom 需要 make 在 4.0 及以上,编译前请自行检查,不满足则先升级。如下我的是3.82则升级。
make --version# sudo yum update sudo yum install centos-release-scl -y sudo yum install devtoolset-7-make -y scl enable devtoolset-7 bash[root@yiqifu-redis RedisBloom]# make --version
GNU Make 3.82
Built for x86_64-redhat-linux-gnu
Copyright © 2010 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.[root@yiqifu-redis RedisBloom]# make --version
GNU Make 4.2.1
为 x86_64-redhat-linux-gnu 编译
Copyright © 1988-2016 Free Software Foundation, Inc.
许可证:GPLv3+:GNU 通用公共许可证第 3 版或更新版本http://gnu.org/licenses/gpl.html。
本软件是自由软件:您可以自由修改和重新发布它。
在法律允许的范围内没有其他保证。
2.2 安装 Python3
-
编译 RedisBloom 还需要 Python3,请检查安装。
python3 --versionyum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make libffi-devel -y wget https://www.python.org/ftp/python/3.8.16/Python-3.8.16.tgz tar -zxvf Python-3.8.16.tgz cd Python-3.8.16# 指定编译文件的存放目录(安装目录) # --prefix=/usr/local/python3.8 # 指定openssl包编译,否则pip install组件的时候,会无法下载https的组件 # --with-openssl=/usr/bin/openssl ./configure --prefix=/usr/local/python3.8 make && make install/usr/local/python3.8/bin/python3 -m venv ~/penv source ~/penv/bin/activate# 切换版本 # sudo alternatives --install /usr/bin/python python /usr/bin/python2 50 # sudo alternatives --install /usr/bin/python python /usr/bin/python3 60 ## sudo alternatives --config python[root@yiqifu-redis RedisBloom]# python --version
Python 2.7.5[root@yiqifu-redis RedisBloom]# python --version
Python 3.8.6
三、编译 RedisBloom
-
依次执行以下命令
yum install git cmake -y git clone --recursive https://github.com/RedisBloom/RedisBloom.git cd RedisBloom./sbin/setup bash -l make
四、测试 RedisBloom
-
将编译 RedisBloom 文件拷贝到指定位置
mkdir /opt/redis6/module cp ./bin/linux-x64-release/redisbloom.so /opt/redis6/module/ -
启动带RedisBloom模块的Redis
redis-server --port 6360 --loadmodule /opt/redis6/module/redisbloom.so或者在 redis.conf 文件中配置: loadmodule /opt/redis6/module/redisbloom.so
有关Redis配置文件请参考这里
-
使用客户端测试
[root@yiqifu-redis ~]# redis-cli -p 6360 127.0.0.1:6360> bf.add aaa 111 (integer) 1 127.0.0.1:6360> bf.exists aaa 111 (integer) 1127.0.0.1:6360> bf.madd bbb 222 ccc 333 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6360> bf.mexists bbb 222 ccc 333 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6360>
五、应用场景
5.1 缓存击穿
-
缓存击穿是指当某个缓存键过期或不存在时,大量的请求同时涌入,导致请求直接落到数据库上,增加数据库的负载。
-
为了防止缓存击穿,可以采用以下步骤:
-
当缓存键过期时,立即在RedisBloom布隆过滤器中添加该键。布隆过滤器是一种高效的数据结构,可以用来快速判断某个元素是否存在于集合中,而不需要实际的存储。这样可以避免对数据库的重复查询。
-
在请求过来时,首先检查请求的键是否存在于RedisBloom布隆过滤器中。如果该键不存在于布隆过滤器中,可以立即返回缓存未命中的响应,避免对数据库的直接查询。这样可以避免不必要的负载。
-
5.2 缓存穿透
-
缓存穿透是指恶意请求发送到缓存中查询一个不存在的键,导致大量的请求直接落到数据库上,增加数据库的负载。
-
为了防止缓存穿透,可以采用以下步骤:
-
在请求到来时,首先检查请求的键是否存在于RedisBloom布隆过滤器中。如果该键不存在于布隆过滤器中,可以立即返回缓存未命中的响应,避免对数据库的直接查询。这样可以过滤掉恶意请求。
-
如果请求的键存在于布隆过滤器中,继续查询缓存。如果缓存未命中,可以返回缓存未命中的响应。这样可以避免对数据库的不必要查询。
-
5.3 原理总结
-
提前把数据使用(bf.add、bf.madd)都添加布隆过滤器,访问时使用(bf.exists、bf.mexists)在布隆过滤器中判断是否在存,如果不存直接返回没有记录。如果存在才查询缓存或者数据库。
-
通过使用RedisBloom布隆过滤器,您可以在处理请求之前快速过滤掉一些无效的请求,从而减轻数据库的负载。这种方法结合了布隆过滤器的高效性和Redis的缓存机制,可以有效地防止缓存击穿和缓存穿透问题。
-
请注意,布隆过滤器是一个概率数据结构,存在一定的误判率。因此,在设计实际系统时,需要根据实际情况调整布隆过滤器的参数,以平衡误判率和内存消耗。
六、存在的问题
-
如果您使用的是普通的布隆过滤器,它通常只支持添加元素而不支持删除。当数据确定删除时,可以采取以下方法处理:
-
过期时间:在添加缓存时,可以为每个缓存键设置一个过期时间。当缓存键过期后,系统会自动将其从缓存中删除。这种方式可以在一定程度上解决数据删除的问题,但是需要根据实际情况设置合适的过期时间。
-
定期刷新:定期刷新是指定期性地删除过期的缓存键。您可以设置一个定时任务,定期扫描布隆过滤器中的所有键,将已过期的键从布隆过滤器中删除。这样可以确保布隆过滤器中不会保留已删除的键,但是需要额外的维护工作和计算资源。
-
-
调整布隆过滤器的参数和误判率,请考虑以下几点:
-
布隆过滤器的容量:布隆过滤器的容量需要根据预期的数据量进行合理的估计。如果容量设置过小,会增加误判率;如果容量设置过大,会增加内存消耗。根据实际场景和资源限制,选择合适的容量。
-
哈希函数的数量:布隆过滤器使用多个哈希函数来确定元素在位数组中的位置。哈希函数的数量会影响误判率和性能。较多的哈希函数可以降低误判率,但也会增加计算开销。在设计中,需要平衡误判率和性能需求,选择适当的哈希函数数量。
-
误判率容忍度:根据系统的需求和可接受的误判率,调整布隆过滤器的参数。误判率是在设置合适的容量和哈希函数数量的前提下,根据实际情况进行调整的指标。较低的误判率会增加内存消耗和计算开销,而较高的误判率可能导致缓存命中率下降。
-

![【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]](https://img-blog.csdnimg.cn/img_convert/7d4a81ef947b615bdc05f5a4d4087c34.jpeg)